简述 Linux I/O 原理及零拷贝(下) — 网络 I/O

2019年至今负责搜索算法的相关工作,擅长处理复杂的业务系统,对底层技术有浓厚兴趣。
简述
这已经是 Linux I/O 系列的第二篇文章。之前我们讨论了“磁盘 I/O 及磁盘 I/O 中的部分零拷贝技术”本篇开始讨论“Linux 网络 I/O 的结构”以及大家关心的零拷贝技术。
socket 发送和接收的过程
socket 是 Linux 内核对 TCP/UDP 的抽象,在这里我们只讨论大家最关心的 TCP。
TCP 如何发送数据

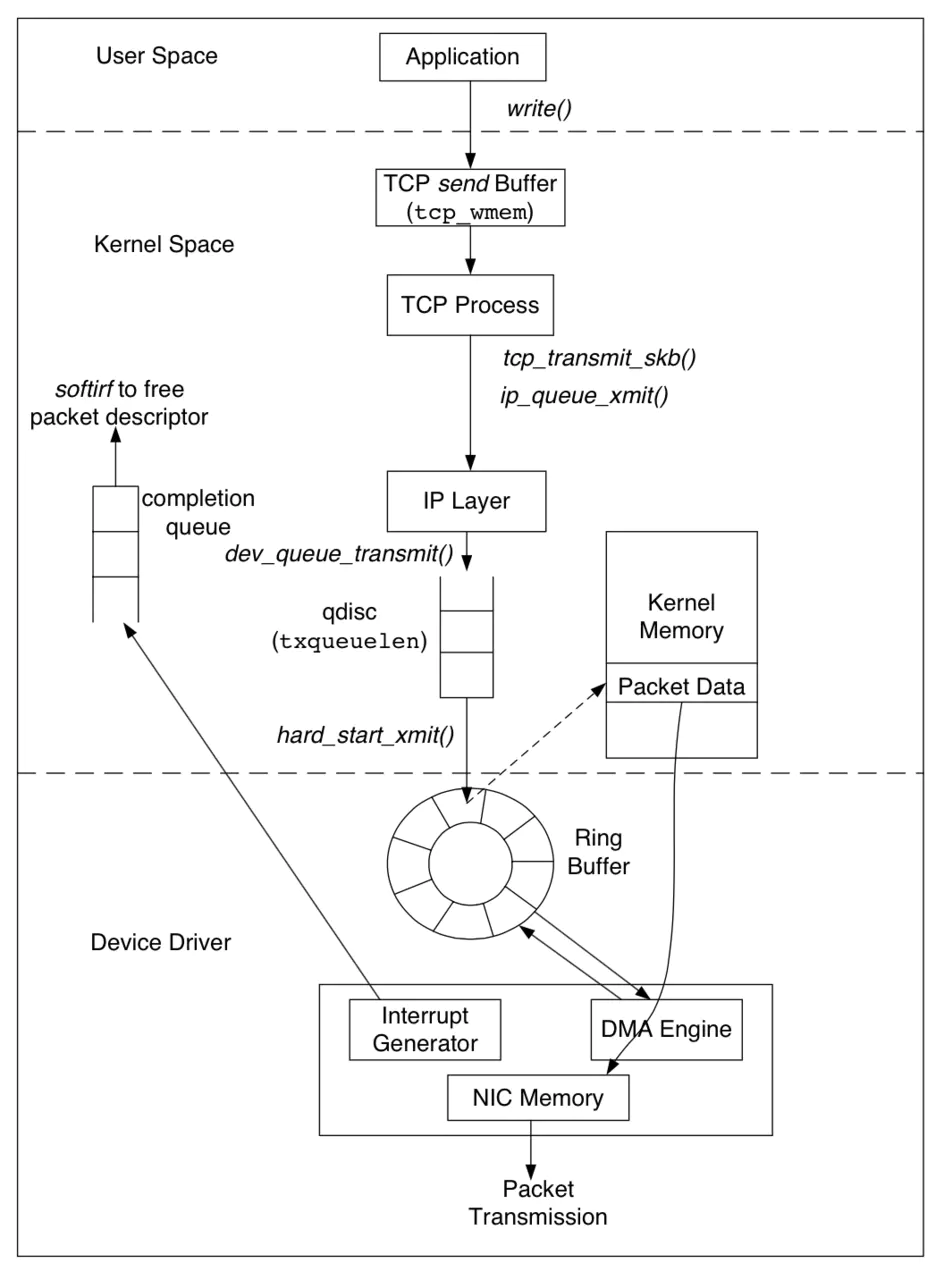
TCP 如何接收数据


(从下往上看)
1. 各层的关键结构
1.1 Socket 层的 Socket Buffer
套接字(socket)是一个抽象层,应用程序可以通过它发送或接收数据,可对其进行像对文件一样的打开、读写和关闭等操作。
那么数据写入到哪里了?又是从哪里读出来的呢?这就要进入一个抽象的概念“Socket Buffer”。
1.1.1 逻辑上的概念
Socket Buffer 是发送缓冲区和接收缓冲区的统称。
发送缓冲区
进程调用 send() 后,内核会将数据拷贝进入 socket 的发送缓冲区之中。不管它们有没有到达目标机器,也不管它们何时被发送到网络,这些都是TCP 协议负责的。
接收缓冲区
接收缓冲区被 TCP 和 UDP 用来缓存网络上来的数据,一直保存到应用进程读走为止。recv(),就是把接收缓冲区中的数据拷贝到应用层用户的内存里面,并返回。
1.1.2 SKB数据结构(线性buffer)
Socket Buffer 的设计应该符合两个要求
怎么才能做到呢?




1.1.3 总结(重要,关系到零拷贝的理解)
只在两种情况下创建 sk_buff:
数据只会拷贝两次:
1.1.4 误区
根据《Unix网络编程V1, 2.11.2》中的描述:
TCP 的 socket 中包含发送缓冲区和接收缓冲区。
UDP 的 socket 中只有一个接收缓冲区,没有发送缓冲区。
UDP 如果没有发送缓冲区,怎么实现多层协议之间的交换数据呢?
参考 man 手册:udpwmemmin 和 udprmemmin 不就是送缓冲区和接收缓冲区吗?
https://man7.org/linux/man-pages/man7/udp.7.html
1.2 QDisc
QDisc(排队规则)是 queueing discipline 的简写。位于 IP 层和网卡的 Ring Buffer 之间,是 IP 层流量控制(traffic control)的基础。QDisc 的队列长度由 txqueuelen 设置,和网卡关联。
内核如果需要通过某个网络接口发送数据包,它都需要按照为这个接口配置的Qdisc(排队规则)把数据包加入队列。然后,内核会尽可能多地从 Qdisc 里面取出数据包,把它们交给网络适配器驱动模块。
说白了,物理设备发送数据是有上限的,IP 层需要约束传输层的行为,避免数据大量堆积,平滑数据的发送。
1.3 Ring Buffer
1.3.1 简介
环形缓冲区 Ring Buffer,用于表示一个固定尺寸、头尾相连的缓冲区的数据结构,其本质是个 FIFO 的队列,是为解决某些特殊情况下的竞争问题提供了一种免锁的方法,可以避免频繁的申请/释放内存,避免内存碎片的产生。
本文中讲的 Ring Buffer,特指 NIC 的驱动程序队列(driver queue),位于 NIC 和协议栈之间。
它的存在有两个重要作用:

NIC (network interface card) 在系统启动过程中会向系统注册自己的各种信息,系统会分配 Ring Buffer 队列及一块专门的内核内存区用于存放传输上来的数据包。每个 NIC 对应一个R x.ring 和一个 Tx.ring。一个 Ring Buffer 上同一个时刻只有一个 CPU 处理数据。
Ring Buffer 队列内存放的是一个个描述符(Descriptor) ,其有两种状态:ready 和 used。初始时 Descriptor 是空的,指向一个空的 sk_buff,处在 ready 状态。当有数据时,DMA 负责从 NIC 取数据,并在 Ring Buffer 上按顺序找到下一个 ready 的 Descriptor,将数据存入该 Descriptor 指向的 sk_buff 中,并标记槽为 used。
Ring Buffer 可能被占满,占满之后再来的新数据包会被自动丢弃。为了提高并发度,支持多队列的网卡 driver 里,可以有多个 Rx.ring 和 Tx.ring。
1.3.2 Ring Buffer 误区
虽然名字中带 Buffer,但它其实是个队列,不会存储数据,因此不会发生数据拷贝。
2. 关于网络 I/O 结构的总结
3. 网络 I/O 中的零拷贝
3.1 DPDK
网络 I/O 中没有没有类似 Direct I/O 的技术呢?答案是 DPDK。
我们上面讲了,处理数据包的传统方式是 CPU 中断方式。网卡驱动接收到数据包后通过中断通知 CPU 处理,数据通过协议栈,保存在 Socket Buffer,最终用户态程序再通过中断取走数据,这种方式会产生大量 CPU 中断性能低下。
DPDK 则采用轮询方式实现数据包处理过程。DPDK 在用户态重载了网卡驱动,该驱动在收到数据包后不中断通知 CPU,而是通过 DMA 直接将数据拷贝至用户空间,这种处理方式节省了 CPU 中断时间、内存拷贝时间。
为了让驱动运行在用户态,Linux 提供 UIO(Userspace I/O)机制,使用 UIO 可以通过 read 感知中断,通过 mmap 实现和网卡的通讯。

3.1.1 DPDK 缺点
需要程序员做的事情太多,开发量太大,相当于程序员要把整个 IP 协议底层实现一遍。
4. 跨越磁盘 I/O 和网络 I/O 的零拷贝
通过三篇文章,我们了解了 Linux I/O 的系统结构和基本原理。对于零拷贝,网上的文章很多,我们只要简单解读一下就可以了。
*另外强调一下,下面的解读,掺杂大量个人观点,并不权威,需要读者自行判断真伪。当然,如有理解错误之处也欢迎指正。
4.1 read + write


网上的总结
4次上下文切换,2次 CPU 拷贝和2次 DMA 拷贝。
解读
4.2 mmap + write


网上的总结
4次上下文切换,1次 CPU 拷贝。针对大文件性能高,针对小文件需要内存对齐,所以浪费内存。
解读
补充
RocketMQ 选择了 mmap+write 这种零拷贝方式,适用于消息这种小块文件的数据持久化和传输。
4.3 sendfile


网上的总结
解读
补充
Kafka采用的是sendfile这种零拷贝方式,适用于系统日志消息这种高吞吐量的大块文件的数据持久化和传输。
4.3.1 sendfile,splice,tee 区别

sendfile
在内核态从 in_fd 中读取数据到一个内部 pipe,然后从 pipe 写入 out_fd 中;
in_fd 不能是 socket 类型,因为根据函数原型,必须提供随机访问的语义。
splice
类似 sendfile 但更通;
需要 fd_in 或者 fd_out 中,至少有一个是 pipe。
vmsplice
fd_in 必须为 pipe;
如果是写端则把 iov 部分数据挂载到这个 pipe 中(不拷贝数据),并通知 reader 有数据需要读取;如果是读端,则从 pipe 中 copy 数据到 userspace。
tee
需要 fd_in 和 fd_out 都必须为 pipe,从 fd_in pipe 中读取数据并挂载到 fd_out 中。
4.3.2 sendfile 是否可以用于 https 传输
我认为,基本上很难实现。http,https 在七层协议中,属于应用层,是在用户空间的。http 可以在用户空间写入 http 头信息,文件内容的拷贝由内核空间完成。https 的加密,解密工作是必须在用户空间完成的,除非内核支持,否则必须进行数据拷贝。
4.4 sendfile + DMA gather copy
传说中的,跨越磁盘 I/O 和网络 I/O 的零次 CPU 拷贝的技术。

网上的总结
在硬件的支持下,sendfile 拷贝方式不再从内核缓冲区的数据拷贝到 socket 缓冲区,取而代之的仅仅是缓冲区文件描述符和数据长度的拷贝,这样 DMA 引擎直接利用 gather 操作将页缓存中数据打包发送到网络中即可,本质就是和虚拟内存映射的思路类似。
解读
本人才疏学浅,认为这不太可能。DMA gather 是指 DMA 允许在一次单一的DMA处理中传输数据到多个内存区域,说白了就是支持批量操作,不会有太大差异。
Socket Buffer 结构是很复杂的,它担负着数据跨层传递的作用,如果传递过程中 Page Cache 中的数据被回收了怎么办?我觉得能说得过去的至少是图-14这种方式,而且内核需要有明确的 API 支持 socket_readfile。据我所知,Linux 并没有提供这种 API。

