Spark :: 源代码(前传)—Spark多线程 :: NettyRpcEnv.ask解读
背景
Spark中有很多异步处理的例子,每一个地方都值得好好去审视一番,对辅助理解spark的机理以及为自己写出优雅的代码都会有很大的帮助。
NettyRpcEnv.ask解读
RpcEnv作用
是的在spark中的唯一一个实现。是什么呢,可以先看一下它的class头信息
/**
* An RPC environment. [[RpcEndpoint]]s need to register itself with a name to [[RpcEnv]] to
* receives messages. Then [[RpcEnv]] will process messages sent from [[RpcEndpointRef]] or remote
* nodes, and deliver them to corresponding [[RpcEndpoint]]s. For uncaught exceptions caught by
* [[RpcEnv]], [[RpcEnv]] will use [[RpcCallContext.sendFailure]] to send exceptions back to the
* sender, or logging them if no such sender or `NotSerializableException`.
*
* [[RpcEnv]] also provides some methods to retrieve [[RpcEndpointRef]]s given name or uri.
*/
就是一句话,RPC的环境。在这里,最重要的2个操作莫过于
可以去注册
可以去异步获取
而和是什么呢,在这里不做详细赘述,其他的文章中会详细说明,简单来讲一下
简单回顾和
RpcEndpoint
众所周知,spark内部会有,等角色,他们之间的通信都采用利用Netty,在executor或者driver上并不是只启动1个Netty的服务,针对不同的功能会有多个Netty的RPC服务开启,利用不同的端口号进行区分。服务间通信后,通的“信”被很多种逻辑单元来处理,如,如等,这些都是工具级别的单元,而被抽象出来作为可插拔可扩展的大的逻辑功能模块在Spark中就叫做,它是用来处理从其他端发送或者端返回过来的的模块。本身是一个trait,它可以有多种的实现
RpcEndpointRef
spark之前的网络通信都是采用akka,改版后采用的是Netty,在akka中,如果一个两个节点间的通信是利用目的方的actorRef来进行的通信的,即AActor 希望发送消息到 BActor,需要BActorRef来发送消息。Spark的网络通信升级到Netty后,Endpoint就可以间接理解成原来的Actor,那么发送消息到另一个Actor的话,也需要的Ref,即。这个概念乍一看有点懵,试想,从A发送消息到B,能发送的前提是A先拥有了一个B的”引用“,这在普通的Http服务中貌似很不能被理解,我想访问某一台机器按说只需要知道对方的IP和Port不就OK了,现在还需要对方的一个“替身”?这是什么鬼?带着问题我们可以持续往下看即可,这里你只需要这样意识即可:
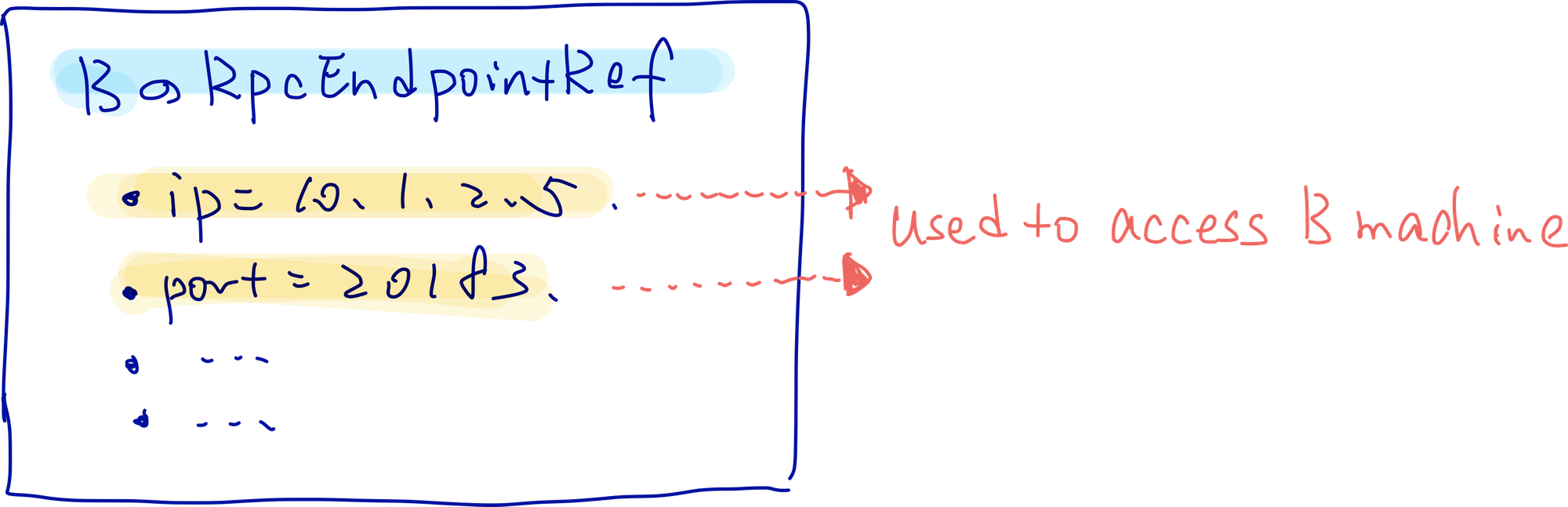
用来访问B machine的 你理解成就是B machine的IP和Port的一个被包装后的实例即可
图解和
图解一下
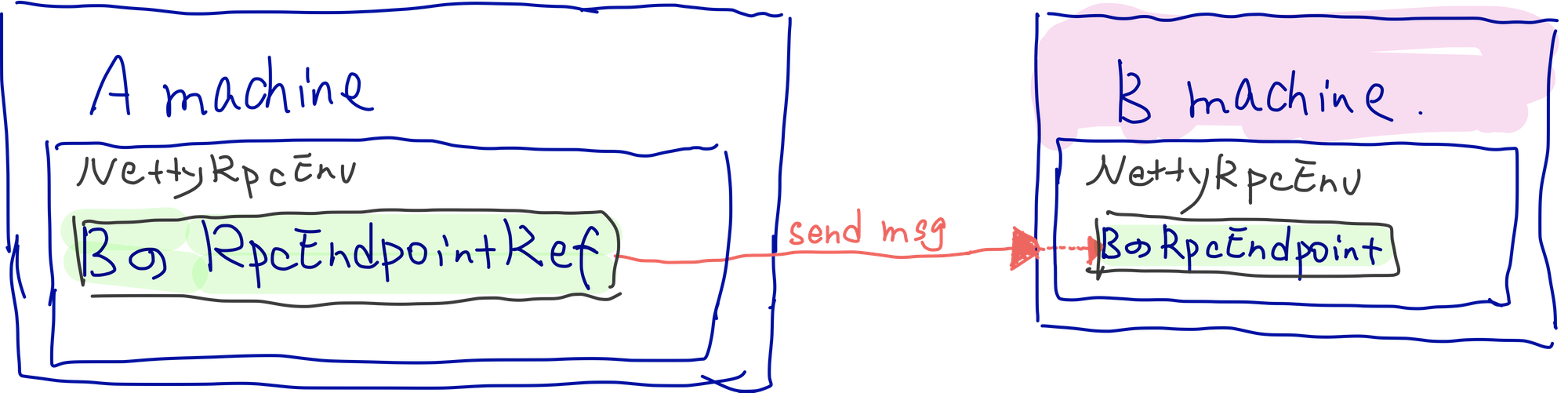
A machine可以是物理机可以是虚拟机,B machine可以是和A同一台物理机、虚拟机(端口号不同),也可以是不同的(在spark中甚至于有自己发给自己的msg,后续会讲)。那么从A发送消息到B的话,使用的是B的,通过它发送消息到B machine
【图1】要如何访问

【图2】内部的原理
【图3】B machine的RpcEndpointRef的实例是啥(简化版)
Driver和Executor
k,顾名思义——问。可能是打个招呼,看看在不在,询问一下,等等。这个就是NettyRpcEnv.ask的作用所在。为了讲NettyRpcEnv.ask的作用,还需要简单的串一下一下概念和流程
Driver线程和Executor进程
首先,需要明确两个事情,在yarn环境下
是在进程中执行的一个线程
严格来说,其实这个说法也不太正确,因为其实是在用户的class的时候,在形成上下文环境的一个产物,本身执行的其实是用户class线程,在这个线程中建立了以及等等,并且建立了的Netty的Service等等,与相互通信
则是一个个的进程,通过java命令在每一个节点上启动的
Yarn系列以及 是什么这里不做赘述,其他文章中会细讲。
其次,在这里只需要了解到,本身是一个协调调度节点,它可以去分配任务给,并且掌握着的情况,分配就是把
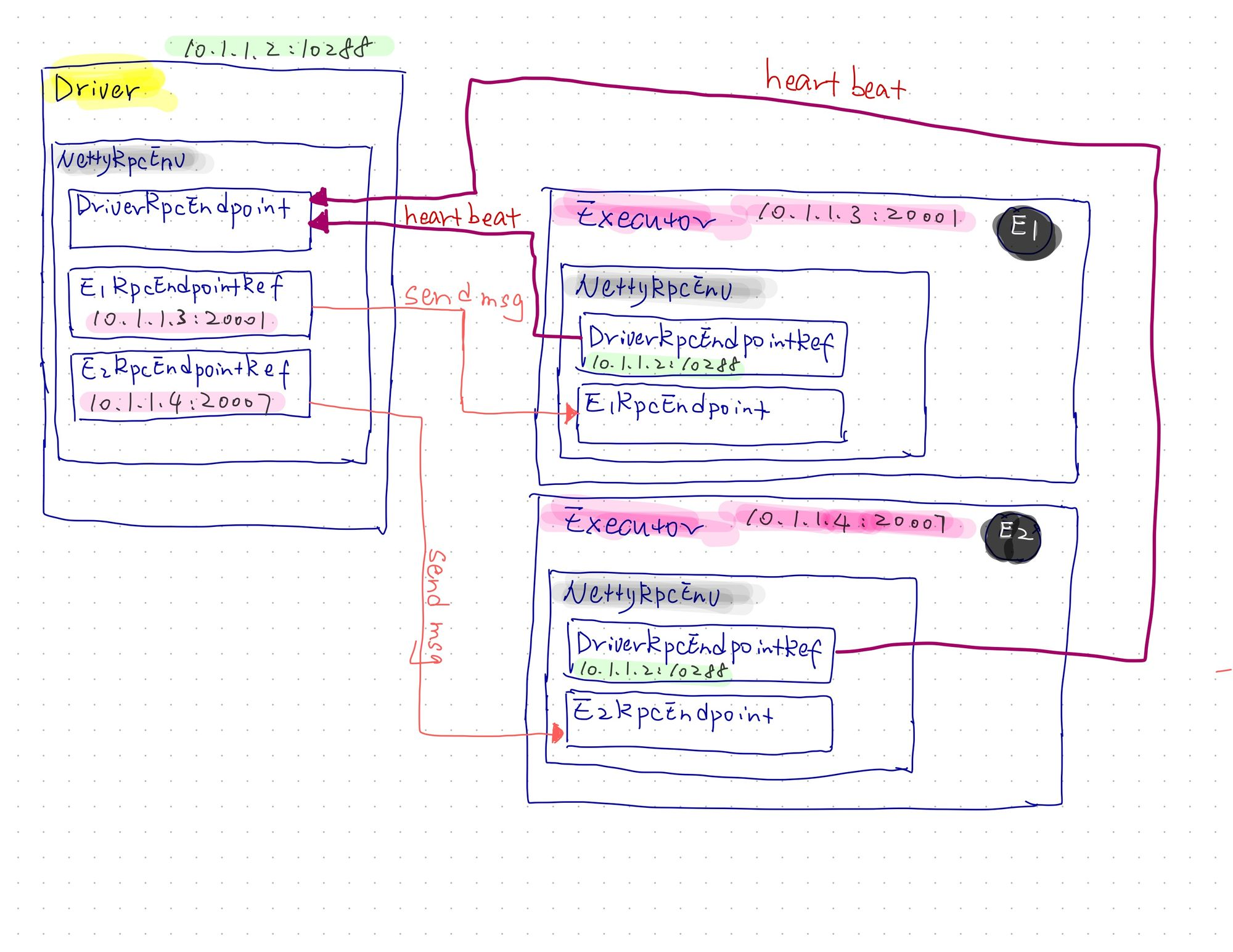
【图4】图解一下
举个栗子,1个和2个进行交互通信,手握2个(一个叫做E1,一个叫做E2)的,姑且简称为E1Ref和E2Ref,通过这2个Ref发送msg到E1节点和E2节点,这2个节点本身通过自身的来处理msg。而E1和E2本身还要定期起的向Driver汇报自身的情况,这里叫做heartbeat心跳,那么反过来则是利用各自内部掌握的来发送
heartbeat 到,而利用其自己的来处理heartbeat 的msg。所有节点的上面的组建则都在自身的中,也就是的实现。
举例:在RpcEnv中建立一个DriverRpcEndpointRef
背景
终于要说到本篇的内容了,
RpcEnv中为啥建立DriverRpcEndpointRef
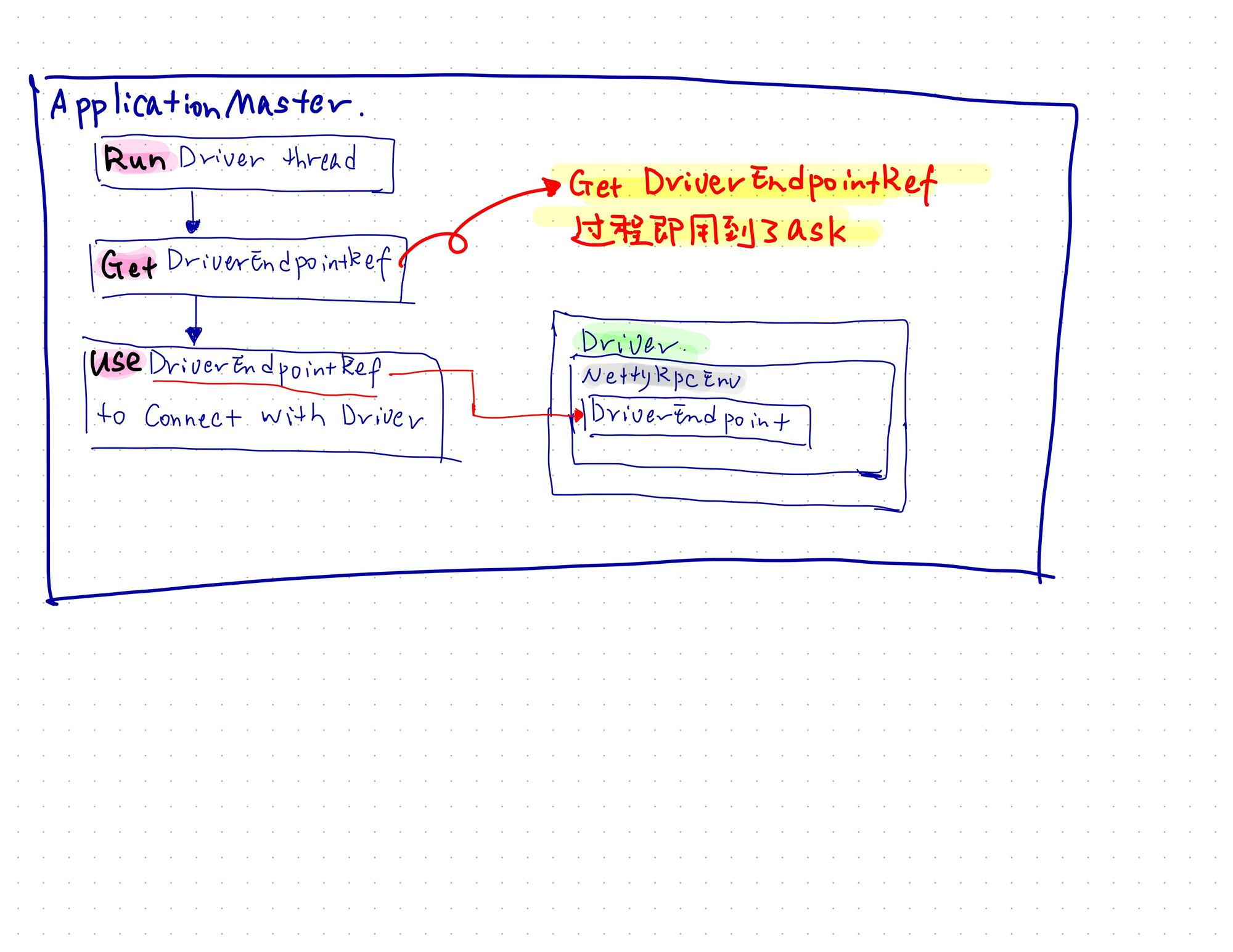
上面的【图4】介绍了一个Driver和和Executor之间通信的过程。其实,在中构建线程的时候,有一部分的通信是需要通过进行的,即利用发送msg给,做出处理并响应
【图5】图解一下
中启动【Run】Driver的线程后,从Driver线程中拿到了,
并且利用的方法【Get】到两个
后续通过【Use】这个去访问Driver的
有一点需要说明的是,的节点本身也是的节点,其实访问的按说是可以直接访问的(Spark源代码中没有这样实现,还是为了隔离和封装的更好,减少耦合,今后如果作为进程执行,不再上运行也会修改的较为简单),但是这里还是采用了Netty的Rpc访问方式
源代码
这部分代码在中,关注方法即可
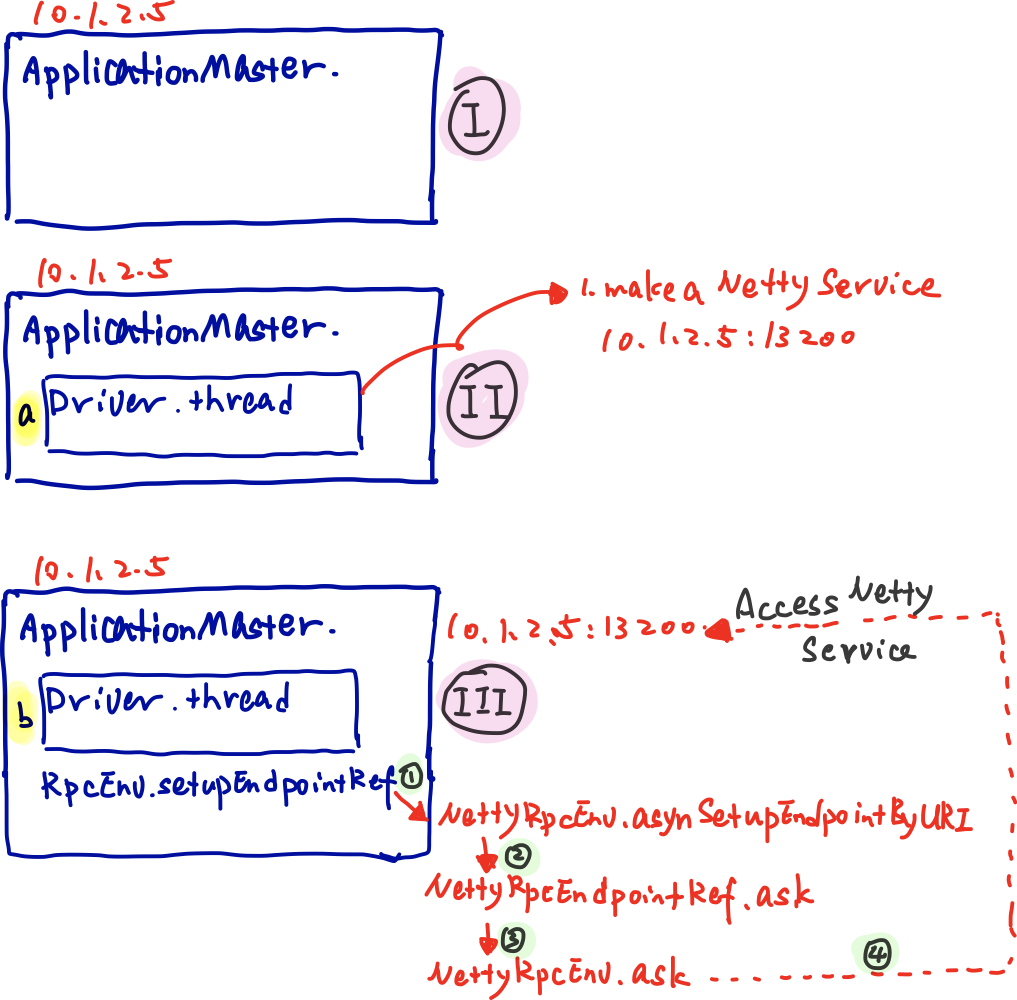
【图6】图解一下
(I) 有一台IP是10.1.2.5的服务器,启动了
(II) **a过程,**在这个节点上启动了Driver的线程,并且初始化了用户的class,并且在10.1.2.5节点上启动了一个Netty的serviec,IP和Port为10.1.2.5:13200
(III) b**过程,**在节点上继续调用
RpcEnv.setupEndpointRef ,目的是setup一个的到中,这个setup的过程就是去10.1.2.5:13200访问一下,如果服务通了,则构建出,这个“访问一下”即本文所述要用到的NettyRpcEnv.ask 的方法。可以看到调用顺序为
(ApplicationMaster.scala) rpcEnv.setupEndpointRef ↓
(NettyRpcEnv.scala) NettyRpcEnv.asyncSetupEndpointRefByURI ↓
(NettyRpcEndpointRef.scala) NettyRpcEndpointRef.ask ↓
(NettyRpcEnv.scala) NettyRpcEnv.ask — — — — ↓ (经过多个步骤,中间部分省略,其他文章会讲)
10.1.2.5:13200 的netty服务
代码如下
private def runDriver(): Unit = {
addAmIpFilter(None)
/*
这里,调用startUserApplication方法来执行用户的class,也就是我们的jar包,
invoke我们的main方法,从而启动了sparkContext,内部启动一系列的scheduler以及
backend,以及taskscheduler等等等等core的内容,其他篇章会详细讲解
*/
userClassThread = startUserApplication()
// This a bit hacky, but we need to wait until the spark.driver.port property has
// been set by the Thread executing the user class.
logInfo("Waiting for spark context initialization...")
val totalWaitTime = sparkConf.get(AM_MAX_WAIT_TIME)
try {
/*
这里,阻塞的等待SparkContext从Driver线程中返回回来
*/
val sc = ThreadUtils.awaitResult(sparkContextPromise.future,
Duration(totalWaitTime, TimeUnit.MILLISECONDS))
if (sc != null) {
rpcEnv = sc.env.rpcEnv
val userConf = sc.getConf
val host = userConf.get("spark.driver.host")
val port = userConf.get("spark.driver.port").toInt
registerAM(host, port, userConf, sc.ui.map(_.webUrl))
/*
**这里,上演了好戏,通过NettyRpcEnv的setupEndpointRef方法来获取到driverRef
这个里面其实是去ask一下Driver你在吗?是否存在这个Driver的服务,如果存在,则
返回OK,构建出Driver的Ref**
*/
val driverRef = rpcEnv.setupEndpointRef(
RpcAddress(host, port),
YarnSchedulerBackend.ENDPOINT_NAME)
createAllocator(driverRef, userConf)
} else {
// Sanity check; should never happen in normal operation, since sc should only be null
// if the user app did not create a SparkContext.
throw new IllegalStateException("User did not initialize spark context!")
}
resumeDriver()
userClassThread.join()
} catch {
case e: SparkException if e.getCause().isInstanceOf[TimeoutException] =>
logError(
s"SparkContext did not initialize after waiting for $totalWaitTime ms. " +
"Please check earlier log output for errors. Failing the application.")
finish(FinalApplicationStatus.FAILED,
ApplicationMaster.EXIT_SC_NOT_INITED,
"Timed out waiting for SparkContext.")
} finally {
resumeDriver()
}
}
解读NettyRpcEnv.ask
回顾Future
如何理解Future呢,从字面意思可以很好的理解,Future即未来,也是期货的意思。
说到期货,就充满了不确定性,因为毕竟没有发生,谁也不知道未来会怎样。所以,定义一个Future就是定义了一个不在现在这个时空(线程)发生的(未来)的另一个(另一个线程的)事件,相比java的鸡肋的Future,scala的Future可谓是非常优雅且完美,搜索我的博客可以看到针对scala的Future的详细介绍。
这里不从源代码的角度去构建Future和Promise的认知观念,会有其他的文章再做解释
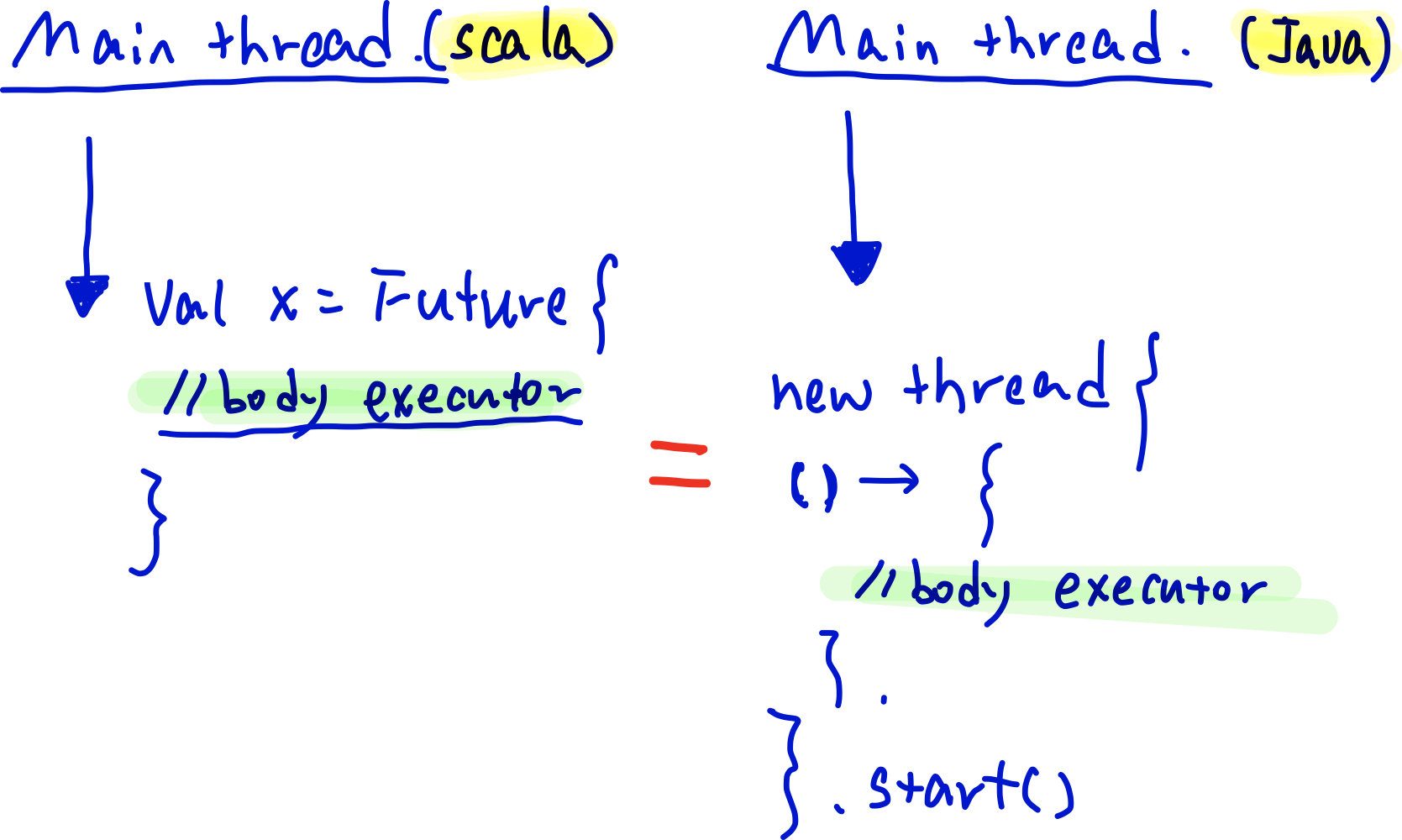
【图7】图解一下
在java中定义一个线程是右侧的做法,而在左侧的scala中,利用Future则优雅了很多
代码
import scala.concurrent.ExecutionContext.Implicits.global
import scala.concurrent.Future
/**
* 解读Future的基础
*/
object DocFutureTest {
def apply(): Unit = {
println("I am DocFutureTest")
}
def main(args: Array[String]): Unit = {
val sleeping = 3000;
val main_thread = Thread.currentThread().getName;
/*
定义另一个线程发生的事件
这个事件相当于java中的如下的代码块:
从整体的间接性上看,scala的更为优雅一些,直接一个Future可以包裹住左右需要处理的内容
后续如果需要进行异常处理的话还可以根据Success和Failture进行模式匹配
public class JavaThreading {
public static void main(String[] args) throws InterruptedException {
new Thread(
() -> System.out.println("这是一条发生在另一个叫做叫做" + Thread.currentThread().getName() + " 线程的故事")
).start();
System.out.println(Thread.currentThread().getName());
Thread.sleep(3000);
}
}
*/
var future_run = Future {
Thread.sleep(1000)
println("这是一条发生在另一个叫做叫做" + Thread.currentThread().getName +" 线程的故事")
}
// 主线程休息3000ms
// 如果不休息的话,main线程会先停止,导致上面的Future定义的thread还没有被执行到就结束了
Thread.sleep(sleeping)
println(s"$main_thread 线程休息 $sleeping 毫秒")
}
}
Future + callback(截取部分)
case class ExceptionError(error: String) extends Exception(error)
def main(args: Array[String]): Unit = {
val sleeping = 3000;
val main_thread = Thread.currentThread().getName;
// 定义另一个线程发生的事件
var future_run = Future {
Thread.sleep(1000)
prntln("这是一条发生在另一个叫做叫做" + Thread.currentThread().getName + " 线程的故事")
// 如果需要onFailure的话 则释放此句
// throw ExceptionError("error")
future_run onFailure {
case t => println("exception " + t.getMessage)
}
future_run onSuccess {
case _ => println("success")
}
注意点
定义了Future,则定义了需要执行的线程的执行体(body),那么执行也是立刻马上,类似于java定义了一个Thread,然后直接调用了一样
在Future中大量运用了scala的Try[],如果出现了异常,没有做的处理,那么可能看不到异常被抛出来,这点和java有较大区别
回顾Promise
从皮毛简单的说完了Future,那Promise又是什么呢?其实在Future的实现中包含了Promise的实现,也就是说没有Promise,Future是无法被运行的。从字面的理解,Promise是承诺,有了Future的未来的定义,那么需要给出一个确切的承诺才可以进行,否则都是空口无凭天马行空无法兑现的大话。
说到现在,包括看完以上的Future的介绍,很多人肯定还是懵b状态,因为我刚开始接触的时候也是这样,但我喜欢的就是用最直观的图和想象来描述一个抽象的问题,二话不说,继续上图
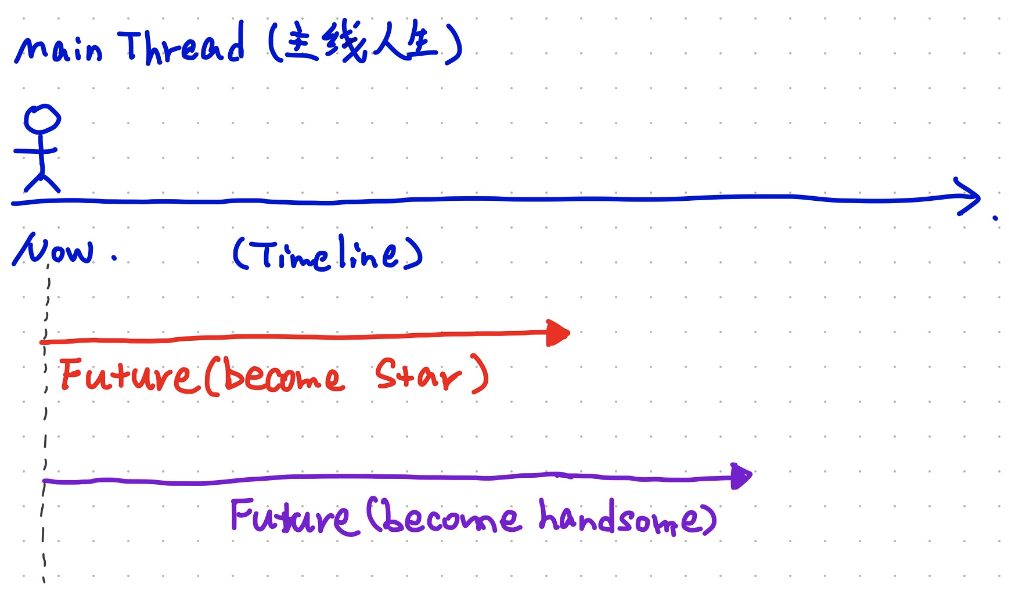
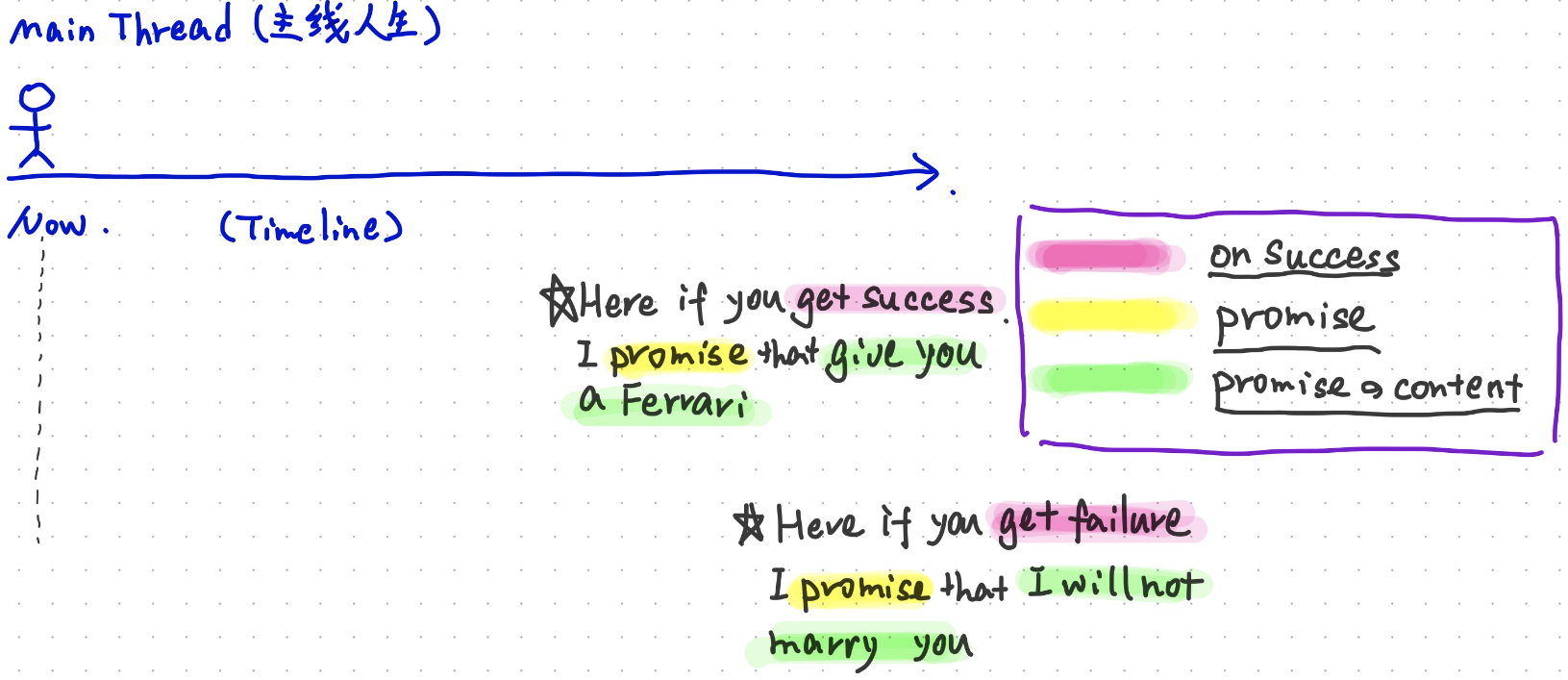
【图8】图解一下:
Future 与Promise 的关系Future的含义
主线人生是你的Main Thread,在spark中可能是某一个处理的Thread
在Now这个时刻,你开启了变成star之路(become star的Thread)
在Now这个时刻,你开启了变帅之路(become handsome的Thread)
一旦你开启这两条路,只要你的Main Thread没有结束,那么你可以一直持续的去走完这两个“之路”,直到
Success 或者Failure ,这就是Future,可以理解为,开启了一条新的轨迹
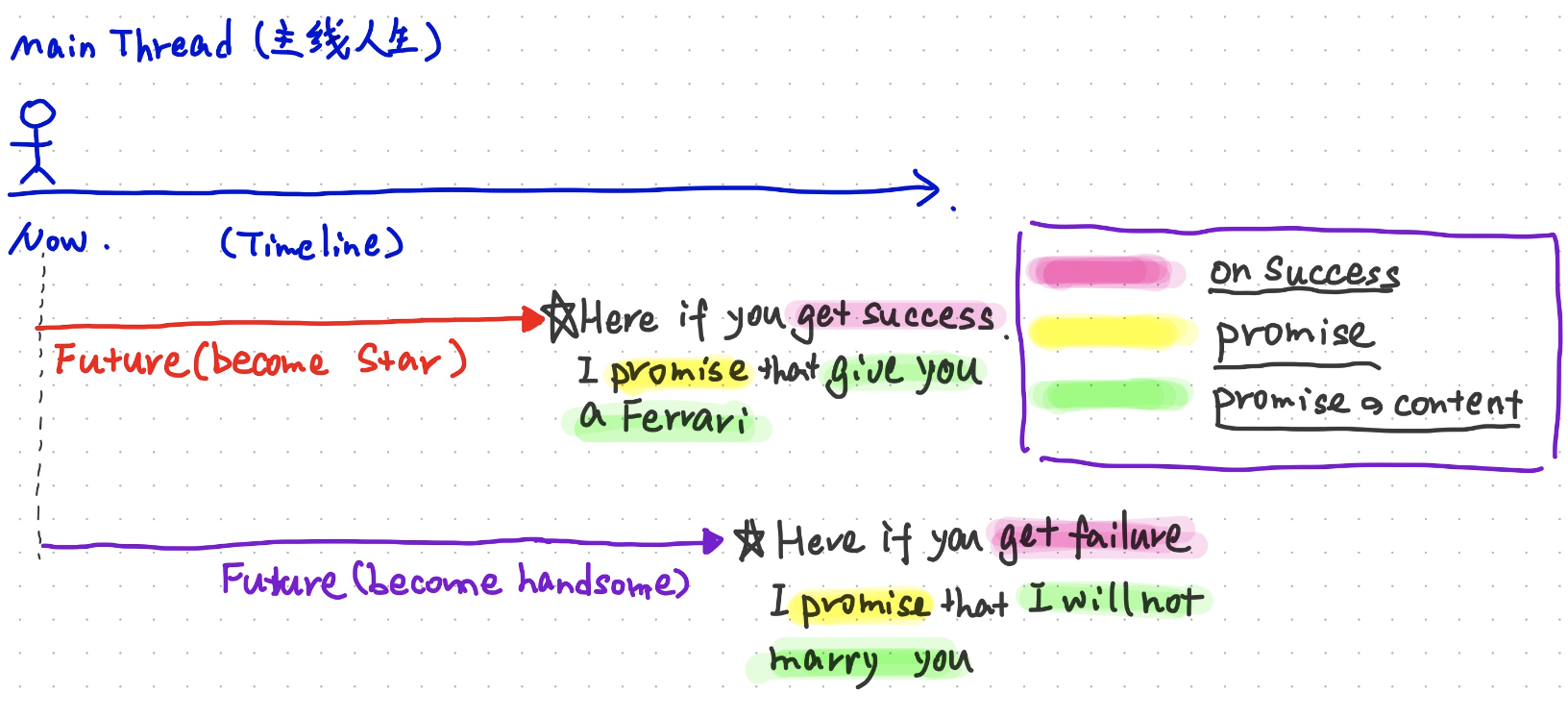
Promiose的含义
当你开启了两条新的“之路”的时候,我可以在你两条路的重点给你不同的承诺
当你success的完成了Future的时候,我promise你一个结果
当你failure的完成了Future的时候,我promise你另一个结果
Future与Promise的对比
Future是一条线,包含执行过程的一条线,按照Timeline要去走下去
Promise是一个点,一个被触发的点,想达到这个点必须又一个Future搭出一条路径才可以
上面两句话如何理解呢,你可以这么想,人生(Main Thread)是一个数轴,你如果希望按照timeline向着右侧一直前进就需要有一条连续的道路,这个“道路”就是一个Thread,也可以是Future定义出的道路,我们只能脚踏实地的通过道路走到目标终点,而不能直接跳到终点。Promise类似于一个milestone点,如果只有一个Promise,不定义出“道路”也就是不定义出一个Future(或Main Thread)的话,是无法实现这个Promise的。只定义了Promise,不去考虑直线路径(Future),无法实现,但只定义Future,不定义Promise(其实在Future中是内置了Default的Promise的)是可以直接执行Future的。如下图所示,开出了两张空头支票,没有定义具体的路线(Future 实现方式),那么这两个Promise是无法兑现的。
需要注意一点,这张图只是画出了定义了Promise,但是如果想对象这个Promise的话,是可以通过Promise中的方法来搭建出一个Future来执行的,与Future不同的是,Future只要定义了就可以马上执行,Promise定义了的话,必须要显式的触发“搭建Future”的操作才可以。
看看Promise不执行的代码
这里,我们定义了一个Promise,并且“承诺”在Promise对应的future结束后调用一个操作打印出一句话future:....
但我们执行以下语句的时候会发现什么都没有执行
import scala.concurrent.Promise
import scala.util.{Failure, Success}
object PromiseTest {
def main(args: Array[String]): Unit = {
import scala.concurrent.ExecutionContext.Implicits.global
val promise = Promise[String]
promise.future.onComplete(v => println("onComplete " + v))
promise.future.map(str => println("future: " + str + " ==> " + Thread.currentThread().getName))
promise.future.failed.foreach(e => println(e + " ==> " + Thread.currentThread().getName))
Thread.sleep(3000)
}
}
看看可以执行的代码
与上面代码唯一不同的就是,加入了的处理
代码细节在其他篇章我们具体看,这里你可以这样理解,加入和trySuccess,就是为达到Promise搭建了一条Future之路,并触发这条路开始执行(start)
至于trySuccess,tryComplete等具体的细节讲scala多线程的地方可以细说
在Future执行完毕后的callback处理,无论是
Success 还是Failure 都可以执行这个处理在之后对Future进行的继续的map处理
触发整个Future执行的trigger
import scala.concurrent.Promise
import scala.util.{Failure, Success}
object PromiseTest {
def main(args: Array[String]): Unit = {
import scala.concurrent.ExecutionContext.Implicits.global
val promise = Promise[String]
promise.future.onComplete(v => println("onComplete " + v))
promise.future.map(str => println("future: " + str + " ==> " + Thread.currentThread().getName))
promise.future.failed.foreach(e => println(e + " ==> " + Thread.currentThread().getName))
**promise.trySuccess("try success " + " --> " + Thread.currentThread().getName)**
Thread.sleep(3000)
}
}
ask的代码
其实,讲完了上面的所有的内容后,ask的代码感觉几句话就可以讲解完毕了。
ask本身返回的是Future,本身是异步处理
【图9】图解一下
一台10.1.1.1的client机器通过rpc访问一台10.1.1.2的Netty的service,当response正确返回后,在client机器中的中进行判断处理,并且调用listener的onSuccess方法,这个onSuccess方法则是下面的ask代码中定义的方法。在这个方法中本身又去执行了promise的tryComplete,从而触发了promise的future之路执行
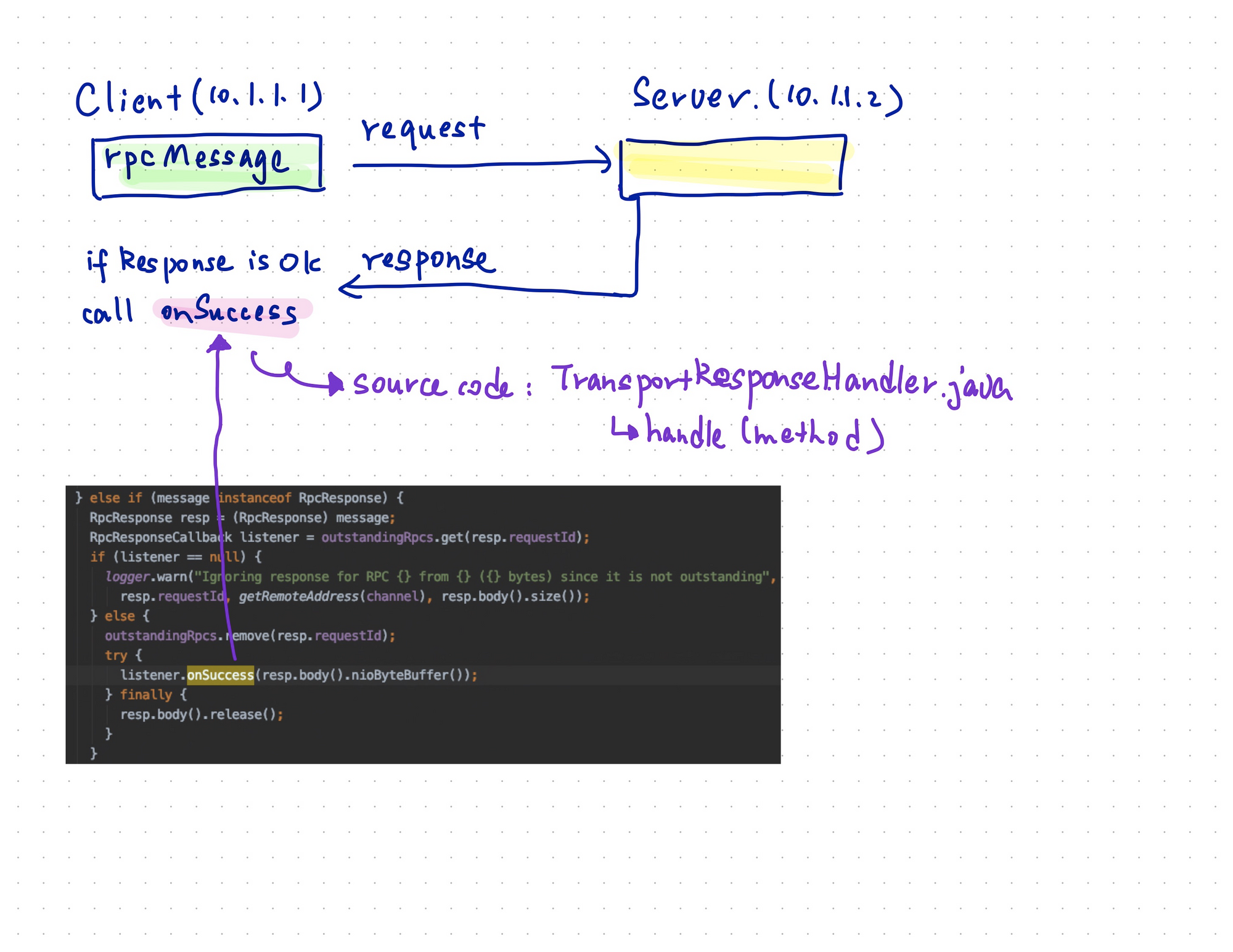
private[netty] def ask[T: ClassTag](message: RequestMessage, timeout: RpcTimeout): Future[T] = {
// 定义了一个Any的promise
val promise = Promise[Any]()
val remoteAddr = message.receiver.address
def onFailure(e: Throwable): Unit = {
if (!promise.tryFailure(e)) {
e match {
case e : RpcEnvStoppedException => logDebug (s"Ignored failure: $e")
case _ => logWarning(s"Ignored failure: $e")
}
}
}
/*
这里声明的onSuccess会被填充到RpcResponseCallback的onSuccess中,这个
RpcResponseCallback就是上面【图9】中的listener,当我们从Server端获取到response后
注意,获取的不是RpcFailure类型的response,则都会进入到【图9】的
else if (message instanceof RpcResponse) { 分支中
*/
def onSuccess(reply: Any): Unit = reply match {
case RpcFailure(e) => onFailure(e)
case rpcReply =>
/*
当返回的response是OK的没有问题后,onSuccess被callback,这里promise的trySuccess也
进行call操作,这里就是上面所说的,为了一个promise铺设了一条future,从而可以执行
这个Future的线程了
*/
if (!promise.trySuccess(rpcReply)) {
logWarning(s"Ignored message: $reply")
}
}
try {
if (remoteAddr == address) {
val p = Promise[Any]()
p.future.onComplete {
case Success(response) => onSuccess(response)
case Failure(e) => onFailure(e)
}(ThreadUtils.sameThread)
dispatcher.postLocalMessage(message, p)
} else {
val rpcMessage = RpcOutboxMessage(message.serialize(this),
onFailure,
(client, response) => **onSuccess**(deserialize[Any](client, response)))
postToOutbox(message.receiver, rpcMessage)
/*
如果是callback了Failure,则这里会被执行
*/
promise.future.failed.foreach {
case _: TimeoutException => rpcMessage.onTimeout()
case _ =>
}(ThreadUtils.sameThread)
}
val timeoutCancelable = timeoutScheduler.schedule(new Runnable {
override def run(): Unit = {
onFailure(new TimeoutException(s"Cannot receive any reply from ${remoteAddr} " +
s"in ${timeout.duration}"))
}
}, timeout.duration.toNanos, TimeUnit.NANOSECONDS)
/*
当promise的future执行后,会调用这里的onComplete方法
*/
promise.future.onComplete { v =>
timeoutCancelable.cancel(true)
}(ThreadUtils.sameThread)
} catch {
case NonFatal(e) =>
onFailure(e)
}
/*
利用RpcTimeout中的addMessageIfTimeout的偏函数再去模式匹配一下产生的Throwable内容
如果是RpcTimeoutException 则 直接throw这个ex
如果是TimeoutException 则包装成RpcTimeoutException后再throw出去
*/
promise.future.mapTo[T].recover(timeout.addMessageIfTimeout)(ThreadUtils.sameThread)
}
总结
本篇用小篇幅讲解了一下*o.a.s.rpc.netty.NettyRpcEnv.ask()*的方法,简单描述了一个spark的异步处理的小case,这个小case需要不少的先验知识点,可能突然间看到这里有点懵,学习需要融会贯通一点点的来积累才可以,如果不明白可以慢慢积累其他模块的知识再来这里看流水账会更有收获。