Vue生成AST算法的解析
在看vue源码的过程中,不只加深了对vue本身的理解,也理解了正则,以及各种设计模式。
博客大部分是从代码开始讲起,所以,我打算更细致的讲一讲这部分的思想。
首先我们要知道什么是AST,以及为什么要用AST生成虚拟dom。
AST是指抽象语法树(abstract syntax tree),或者语法树(syntax tree),是源代码的抽象语法结构的树状表现形式。Vue在mount过程中,template会被编译成AST语法树。
简单来说,在js中AST的表现形式是像下面的结构
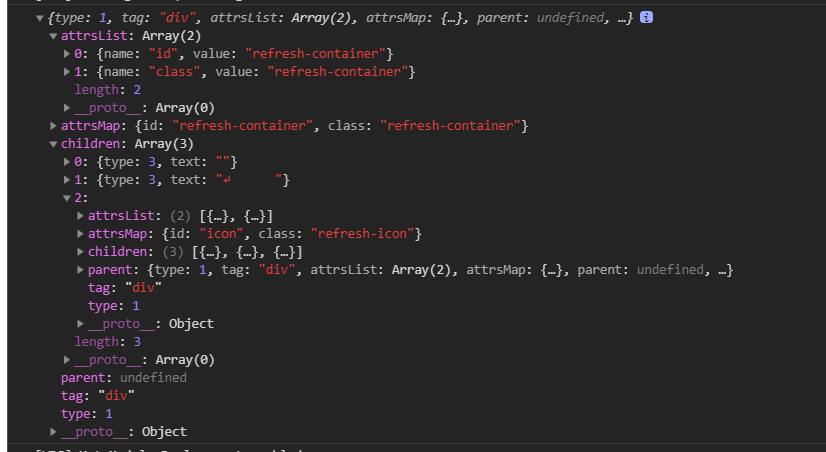
它是怎么来的呢? 是通过js中的类html字符串转换而来的,所以我们的任务就变成了把类html转换成这种结构啦。 下面我先给出一串模板
const template = `
`#1
首先我们对这个字符串进行trim操作,去除两端的空格。然后我们要用判断这个字符串<的位置。这时候就分成了三个部分

我们从最简单的textStart = 0的情况开始
1.1
这时候又会有两种可能性

这一部分的结构讲完了, 再继续看看<0的情况
1.2
当textStart<0的时候,只有一种可能,这段html字符串已经没有标签或者注释了,即是纯文本。
1.3
当textStart > 0的时候,说明在标签或者注释之前含有文本(这里我们暂时不考虑文本中有<的情况,大家可以自己去尝试一下)
2
知道了所有的情况,我们来了解一下怎么处理这些情况。
2.1
对1.的情况,当匹配到标签的时候,比如我们要把它的tagName, id, class等等属性得到。设置两个栈。一个叫checkStack,用于与之后匹配到的结束标签进行比对。一个叫AstStack,用于辅助AST的建立。

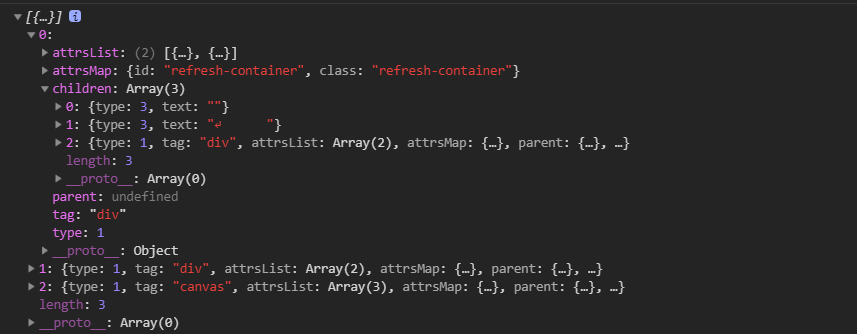
checkStack中单纯存放了tagName和attr,而AstStack中存放的是他的父元素和子元素,这些可以用于建立一个AST。
所以流程如下:
匹配到开始标签 --> 获得各种属性,创建一个match对象--> 推入checkStack中-->推入AstStack中 (这里先不讨论自闭和标签的情况,等会会用代码来详细讨论)
如果匹配到注释,不推入checkStack,具体流程如下:
匹配到注释开始 --> 获得注释所有的内容,并匹配到注释结束标签 --> 不推入checkStack --> 从AstStack中获取最后一个元素, 把该注释对象推入AstStack栈顶的children数组中
2.2
没有标签或注释,则会把该段纯文本推入AstStack栈顶元素的children中, 并不再遍历该段html,如果没有栈顶元素,则会报错
2.3
与2.2情况类似,只是还会继续遍历html
3
知道了流程和怎么处理,我们可以愉快的开始看代码啦!我们来看看精简版的,然后大家熟悉了流程可以再去看vue的源码
先来定义几个正则
const attribute = /^\s*([^\s"'<>\\/=]+)(?:\s*(=)\s*(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<>`]+)))?/
const ncname = '[a-zA-Z_][\\w\\-\\.]*'
const qnameCapture = `((?:${ncname}\\:)?${ncname})`
// 匹配开始标签开始部分
const startTagOpen = new RegExp(`^<${qnameCapture}`)
// 匹配开始标签结束部分
const startTagClose = /^\s*(\/?)>/
// 匹配结束标签
const endTag = new RegExp(`^<\/${qnameCapture}[^>]*>`)
// 匹配注释
const comment = /^')
console.log(commentEnd)
if (commentEnd >= 0) {
if (opt.comment) {
opt.comment(html.substring(4, commentEnd)) // 保存注释