dubbo使用curator作为zk客户端优雅停机存在的问题
前言
在上一篇:在结尾的时候,我提出了解决这个问题可以采用优雅停机来解决,但是在后来的实践中我发现这个问题并没有办法解决,所以又进一步对curator代码进行了分析、得出了以下个人的总结与分析(以下内容仅个人理解与观点,如果有误欢迎评论留言指出)
为什么我之前会觉得优雅停机可以解决?
优雅停机核心实现代码如下:
@Configuration
@Order(2147483646) //DubboBootstrapApplicationListener中LOWEST_PRECEDENCE = 2147483647,这里相当于执行顺序在dubbo关闭之前
public class GracefullyShutdownListener implements ApplicationListener {
public GracefullyShutdownListener() {
DubboBootstrap.getInstance().unRegisterShutdownHook();
}
public void onApplicationEvent(ContextClosedEvent event) {
//指定休眠时间默认20秒
long timeSleepInMills = Long.parseLong(System.getProperty("dubbo.shutdown.sleepInMills", "20000"));
try {
Thread.sleep(timeSleepInMills);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
上一节中制造zk数据变更的代码如下:
public static void main(String[] args) throws Exception {
//zk 地址
String connectString = "localhost:2181";
// 连接时间 和重试次数
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);
CuratorFramework client = CuratorFrameworkFactory.newClient(connectString, retryPolicy);
client.start();
String path = "/dubbo/config/mapping/test";
//注意这里的i如果数值较小在sleep20期间变更全部被处理完了此时就不会报错
for (int i = 0; i < 1000; i++) {
client.create().creatingParentsIfNeeded().forPath(path + i, "init!".getBytes());
// client.delete().deletingChildrenIfNeeded().forPath(path + i);
}
}
通过上面代码来分析,我上次说优雅停机可以解决报错的原因就是因为我在20s之内处理完了1000个节点创建的事件。但是如果调大数值,让它在20s之内处理不完、那就无法解决报错。对应于生产情况来分析就是:如果在真正执行停机的时候,此时还有对应的zk事件需要处理,此时curator客户端就会报错。
这个问题是否可以解决?
这个目前在我这边得出的结论是无法解决,但是也没啥影响。(如果我这里讲的有误、有解决方案希望可以留言告诉我)下面通过源码分析来说明为啥是无法解决的。
org.apache.zookeeper.ClientCnxn.EventThread#run方法如下:
@Override
public void run() {
try {
isRunning = true;
while (true) {
//waitingEvents是存放zk事件的队列
Object event = waitingEvents.take();
if (event == eventOfDeath) {
wasKilled = true;
} else {
//处理事件核心方法
processEvent(event);
}
if (wasKilled)
//就算已经接收到eventOfDeath事件也要继续把队列处理完了
//按到执行顺序接收到waitingEvents事件的时候curator已经关闭了所有这里也会导致报错
synchronized (waitingEvents) {
if (waitingEvents.isEmpty()) {
isRunning = false;
break;
}
}
}
} catch (InterruptedException e) {
LOG.error("Event thread exiting due to interruption", e);
}
LOG.info("EventThread shut down for session: 0x{}",
Long.toHexString(getSessionId()));
}
根据代码可知zookeeper中有一个while(true)死循环来不断处理zk的数据变更,停止条件为接收到eventOfDeath。再来看看curator客户端是何时被close的。断点调试org.apache.curator.framework.imps.CuratorFrameworkImpl#close方法得到如下调用栈:
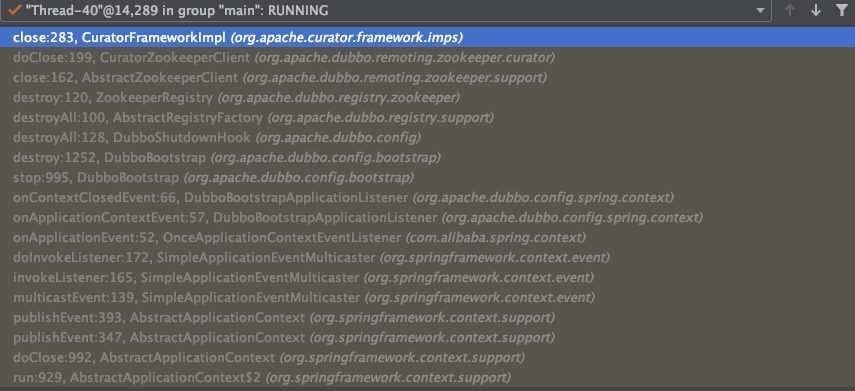
这里要说明的是在CuratorFrameworkImpl的close方法执行之前没有方法往上面zookeeper的waitingEvents中加入eventOfDeath事件,所以此时EventThread的run方法还是在后台持续执行的。再来看看CuratorFrameworkImpl的close方法是如何处理的:
@Override
public void close()
{
log.debug("Closing");
//先设置Curator客户端状态为关闭
if ( state.compareAndSet(CuratorFrameworkState.STARTED, CuratorFrameworkState.STOPPED) )
{
//此处省略无关代码。。。
listeners.clear();
unhandledErrorListeners.clear();
connectionStateManager.close();
//这里执行zookeeper的关闭,也就是里面会发送eventOfDeath事件
client.close();
namespaceWatcherMap.close();
}
}
下面进入上面代码的client.close();方法找到发送eventOfDeath的地方在org.apache.zookeeper.ClientCnxn的disconnect方法,此时调用栈如下:
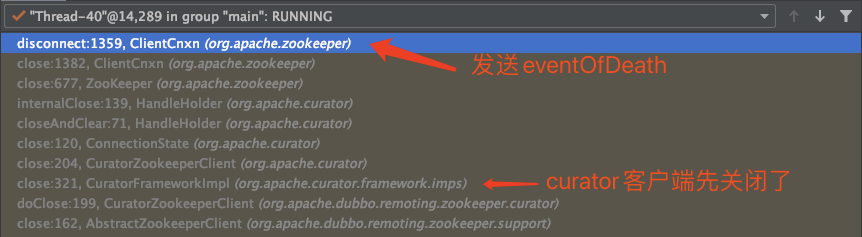
通过调用链以及代码可以看到curator是先把自己的CuratorFrameworkState设置为STOPPED然后zookeeper才发送eventOfDeath,那么在这个过程中就会存在时间差,此时org.apache.zookeeper.ClientCnxn.EventThread#run方法在处理事件的时候由于CuratorFrameworkState的状态为STOPPED就会报错,代码如下:
@Overridepublic GetChildrenBuilder getChildren(){ Preconditions.checkState(getState() == CuratorFrameworkState.STARTED, "instance must be started before calling this method");
return new GetChildrenBuilderImpl(this);}
所以按照代码的意思,这个报错就是无法避免的,可能是curator客户端实现不够优雅导致的,也不能算是一个bug。理由如下:
不能够先关闭zookeeper链接然后再关闭curator客户端吗?
按我的理解不能,因为你作为zk客户端,自己状态肯定要先改成stop表明要停止服务,此时才能关闭zk链接,肯定不能先关闭zk链接再把自己状态设置为stop,因为如果你先把zk链接关闭了,但是自身状态还是为STARTED,此时如果还有请求还是认为你处于可用状态,发起zk调用,但是由于zk关闭,所以照常会报错。并且关闭zk链接与关闭zk客户端无法是一个原子操作
这个报错会有啥影响吗?
这个报错没有啥影响,TreeCache内部实现中会捕获此类异常,然后仅仅是打印日志而已,并且更重要的是,TreeCache顾名思义只是一个类似缓存的东西,此时服务也准备关闭了,TreeCache的内容已经不重要了,重启的时候又会刷新一次
总结
这个问题按自己的理解目前并没有啥有效的解决方案,网上能查到的相关知识也寥寥无几,并且curator只是zookeeper的客户端,EventThread#run是在zookeeper包里的是zk的实现并不属于curator包的实现所以在不改zk实现的情况下目前我也想不出其它更好的实现了,可能curator开发者在写的时候已经考虑到了这种情况、并且综合考虑报错没啥影响,最优方案也只能那么实现。上面只是我个人对这个问题的思考,如果有误,欢迎评论指出~