人工智能基础2 - DAY10
监督学习 & 无监督学习 & 强化学习
监督学习需要标记数据,而无监督学习则不用,主要是通过聚类分析来实现
除了监督学习与无监督学习以外,还有强化学习reinforcement learning,AlphaGo就是强化学习的代表作,但是强化学习在应用上暂时没有太多突出表现
目前工业界的应用,大多数采用的是监督学习
监督学习
可以分为回归问题和分类问题
回归问题:输出连续性变量,如:温度,身高,股价
分类问题:输出定性结果,如:好和坏,主题
特征与标签
例子:
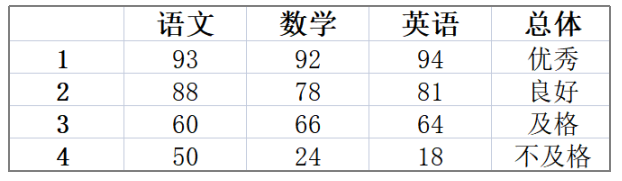
数据集Dataset包含了4个样本samples,每个样本拥有3个特征,分布是“语文”、“数学”、“英语”,和一个类别标签“总体”,标签分为了4种,所以这是个四分类的问题。
于是,数据集可以表示为
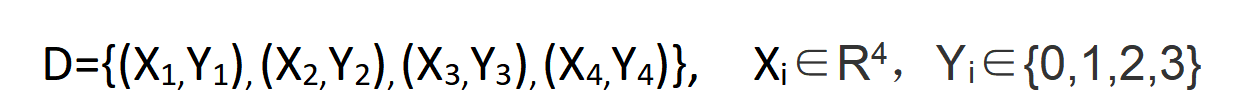
X叫做特征的向量,Y是标签,R
数据预处理
数据预处理往往是最重要的一步,以后再介绍。
数据可视化
数据可视化可以非常直观地把数据展示在二维或者三维空间当中。通过可视化,可以直观地观察到数据的分布特征,是否有异常值,特征值是否满足某一类分布的情况。但是,如果数据的特征维度很高,可视化化是不大合适的,因此,数据的降维是经常采用的方法,例如把20维降到2维或者3维的空间。最经典的一种降维方法叫做主成分分析PCA。
训练数据&测试数据
获得的数据分为训练数据和测试数据,顾名思义,训练数据用于训练模型,而测试数据用于测试模型的好坏。测试数据是不能用于训练模型当中的,仅用于测试。