聊聊事务与分布式系统-从零讲到通透
01 前言
本文核心是”事务“,由基础理论引出解决方案,也阐述了个人对分布式系统的理解。全文包含以下内容:
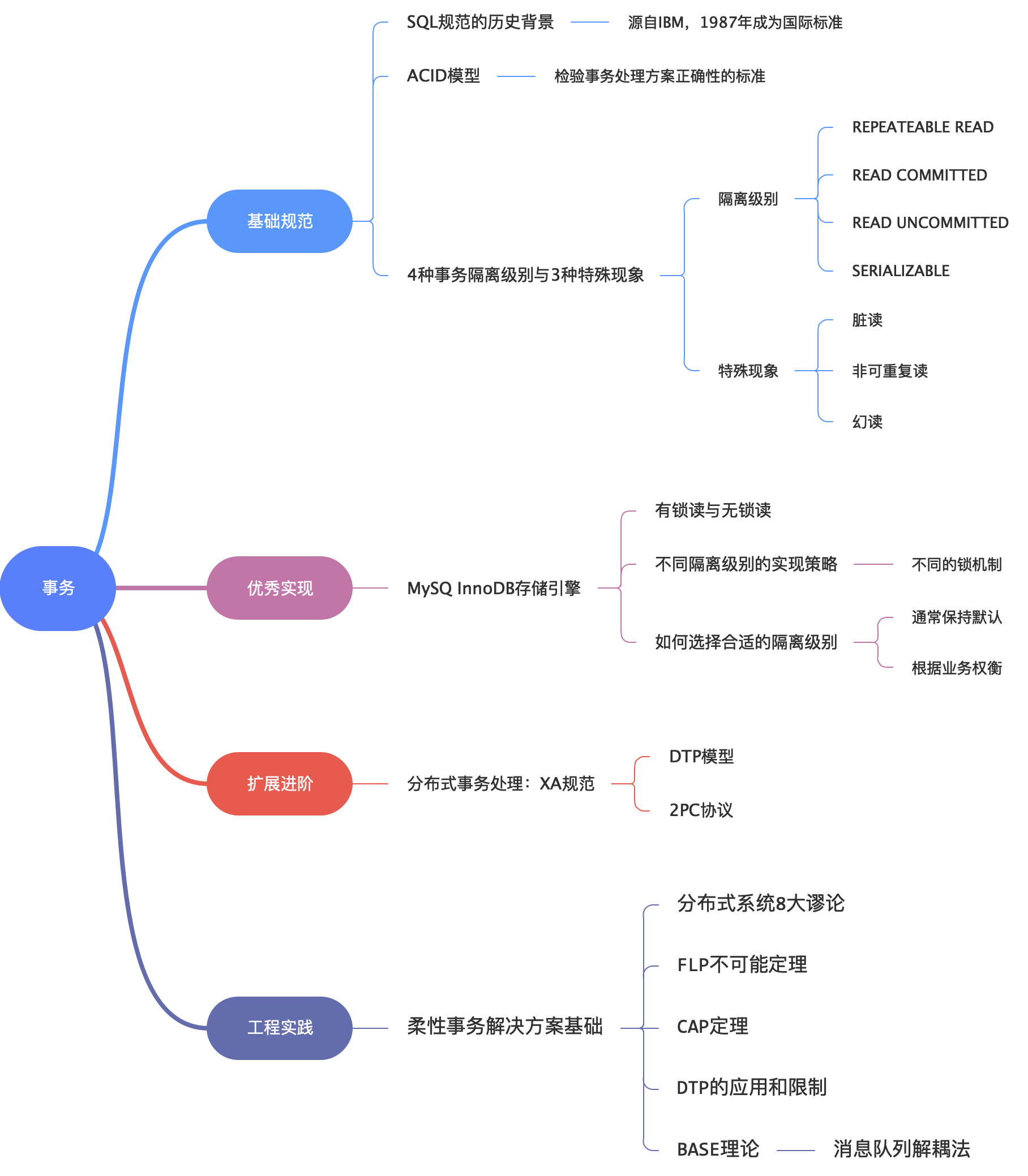
02 基础规范
SQL规范的历史背景
在讲事务之前先介绍下SQL(Structured Query Language)的历史,建立宏观认识。
在19世纪70年代,为了满足数据库查询的需要,SQL作为一门特定领域的语言横空出世。1986年,美国国家标准化学会(ANSI)基于IBM的实现将SQL核准为国家标准。仅在几个月之后的1987年,国际标准化组织(ISO)将其采纳为国际标准(ISO9075-1987)。
就像hotspot虚拟机是参照JVM规范进行实现一样,MySQL、Oracle等数据库的SQL也是基于SQL标准实现的。标准一共有九大部分,其第一部分:Framework,对事务进行了定义:
ACID模型
主流数据库基本都支持并发操作,
数据库作为存储组件,持久性是最基本的要求。在无并发的情况下,原子性就是一致性的保证。在并发情况下,原子性和隔离性共同保证了一致性。
事务隔离级别
与多线程并发操作共享数据同理,多个事务并发操作相同的数据时可能会发生一些无法预料的事。事务隔离是数据库处理的基础能力之一,在并发事务场景下,隔离显得尤为重要。在SQL标准的第二部分:Foundation,定义了4个事务隔离级别,
事务并发执行期间,不同隔离级别下可能会发生不同的现象:
三种现象出现的可能性不同,要根据业务的实际需求进行权衡,可以在事务执行之前显式地设置隔离级别。
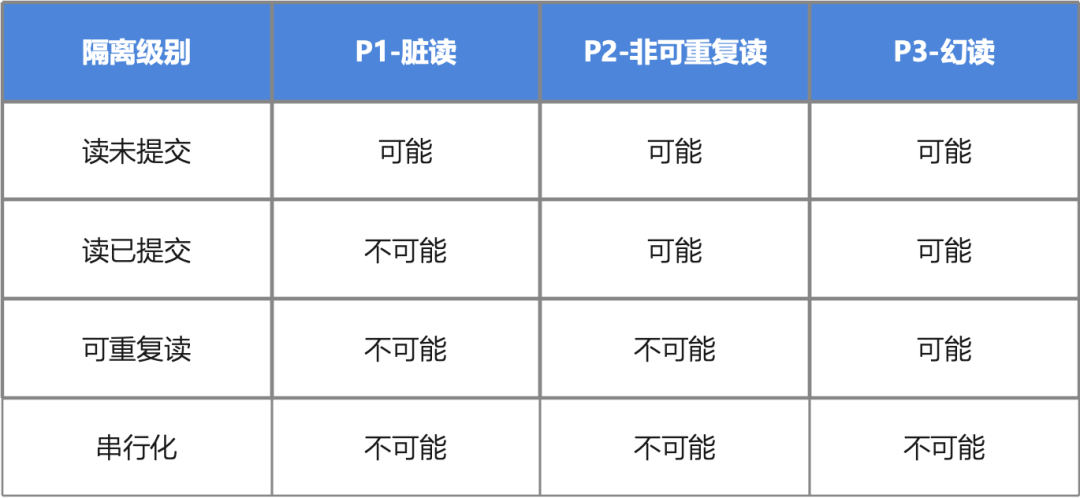
4种隔离级别的划分还是太抽象,怎么理解?P1/P2/P3三种现象出现的可能性为什么不同?
并发操作共享数据的安全问题是客观存在的,由多核CPU并发执行进程的基本原理所决定,这是SQL规范必须要考虑的问题。SQL规范是统一的国际标准,而对标准的实现则可以百花齐放,接下来以MySQL InnoDB的事务模型为例进行解析,相信你会有更深的理解。
03 优秀实现:InnoDB存储引擎
本文提到的MySQL特指5.7及以上版本。
无锁一致性读(Consistent Nonlocking Reads)
InnoDB使用多版本并发控制(MVCC)的方式向查询提供数据库在某个时间点的快照。在同一个事务中,查询可以看到快照时间点之前提交的数据,但不会看到未提交或者快照时间点之后才提交的数据。旧版本数据是不能被加锁的,其读取结果是通过undo日志在内存中构建出来的,读取过程中也不会设置任何锁,其它事务的锁设置也都会被忽略,称为无锁一致性读。例如最常见的SQL:
SELECT … FROM t1 WHERE …有锁读(Locking Reads)
与无锁一致性读对应的就是有锁读,InnoDB支持以下两种有锁读:
无论是共享锁还是排它锁,默认都是锁定索引区间范围,其它事务是无法在索引区间的缝隙中插入新数据的,此时不会出现脏读、幻读以及不可重复读。除非在查询时使用到了唯一索引,查询的结果只有唯一的一行,才会只锁定对应的索引记录。
不同事务隔离级别的实现策略
如何选择合适的隔离级别?
REPETABLE READ是默认的事务隔离级别,也是最常用的。你可以使用默认隔离级别保证较强的数据一致性,也可以使用READ COMMITTED、READ UNCOMMITTED弱化一致性。
04 扩展进阶
分布式事务
以上是对分布式事务比较通俗、便于理解的解释。当然,也有更加抽象、规范的标准。
X/Open DTP Model(X/Open分布式事务处理模型)
成立于1996年的The Open Group组织,以厂商中立的角色致力于标准的制定与推广,分布式事务处理模型就是由该组织制定,即:X/Open Distributed Transaction Processing Model,简称X/Open DTP Model或XA。
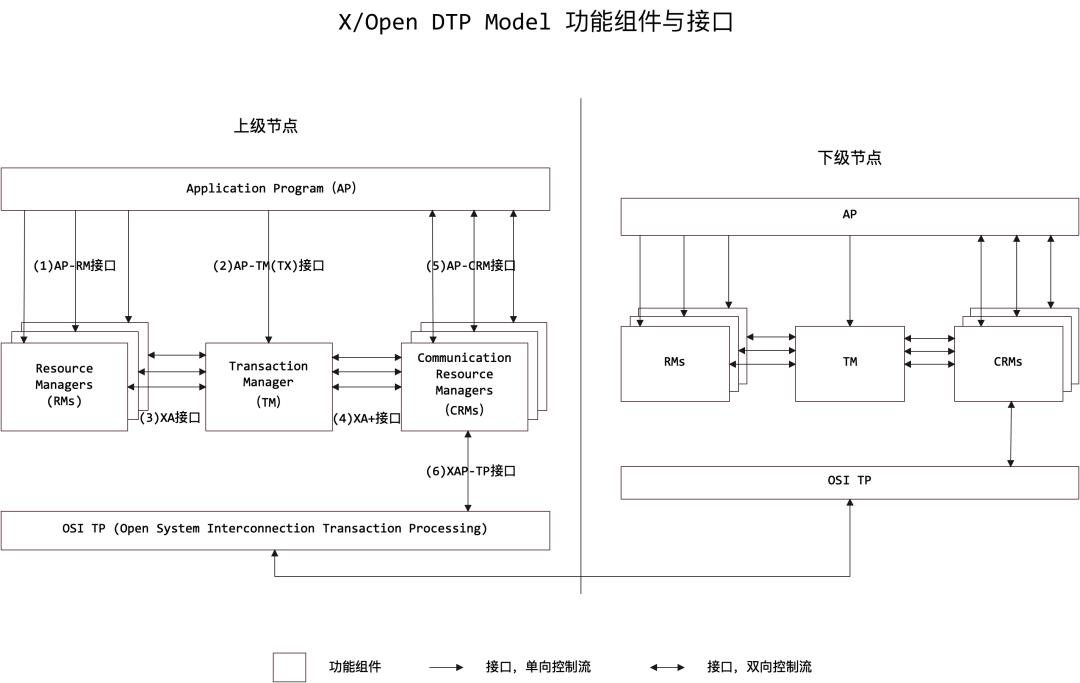
四种软件组件
六种组件间接口
两阶段提交协议
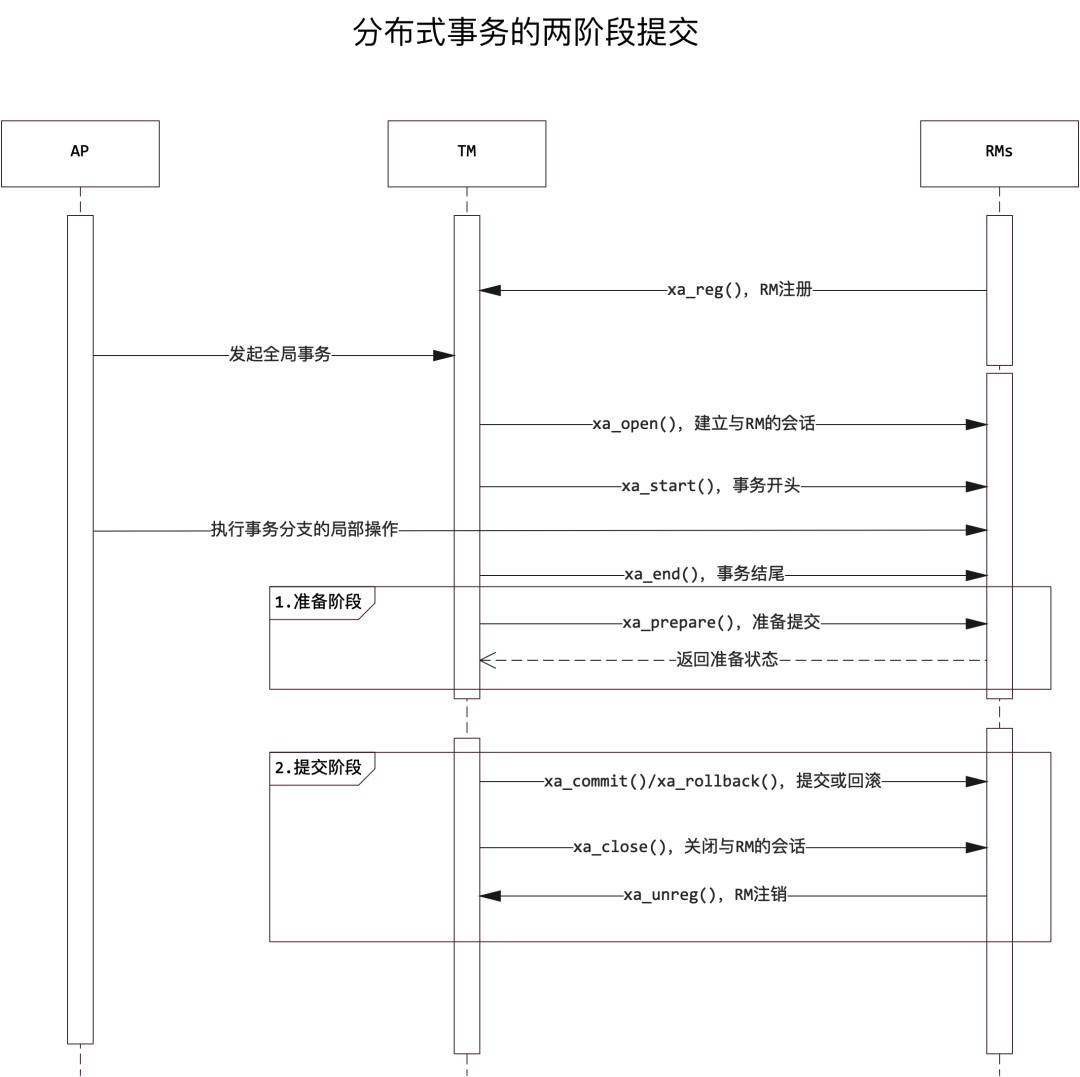
DTP模型中使用两阶段提交(Two-Phase Commit)进行事务的提交/回滚:
从发起事务到完成,一个RM最多要经历8次XA接口调用。要想完全实现DTP模型是非常有难度的,在实践中将会面临众多的问题。
05 工程实践
微服务架构的提出者Martin Flowler曾提出这样的忠告:
分布式系统8大谬论
最初由Sum Microsystems的创始人Peter Deutsch提出,1997年被Java之父James Gosling完善。之所以称之为谬论(错误的假设),是因为历史上的无数实践已经做出证明。
以上8点总结起来就是两个字:网络,而分布式系统必然有网络调用,网络问题值得我们在进行系统设计时好好斟酌。
FLP不可能定理
FLP取自Fischer、Lynch、Patterson三位科学家名字的首字母。1985年,三位科学家在一篇论文中(Impossibility of Distributed Consensus with One Faulty Process)提出并证明了该定理:
在实践中,我们如何从8大谬论和FLP不可能定理中自我拯救?既然干不掉它们,那就想办法共存。
DTP在单体架构下的应用
小概率的异常事件并不会使分布式失去应用价值。
对于单体架构的应用,事务的场景通常是一个应用程序访问一个数据库,且不存在远程调用,无需实现完整的DTP模型即可满足需求(仅仅实现一个AP、一个RM,用不上CRM和OSI TP)。
Spring是Java世界中流行的应用服务开发框架,对事务管理进行了统一抽象,提供了一致性的编程模型,可以支持不同的事务API,包括:JTA、JDBC、JMS、Hibernate、JPA、MyBatis等。使用Spring提供的编程模型可以有效屏蔽使用不同事务API时的差异,通过事务注解可实现无代码侵入的事务管理,帮助开发人员把精力集中在业务逻辑上。Atomikos是一个第三方的JTA实现,支持XA,可以集成到Spring工程中使用。Atomikos有免费和收费两个版本,只有收费版可以支持跨AP通信的分布式事务(Atomikos官方称之为Microservice Transactions)。
DTP在分布式架构下的限制
由于老板很努力,公司的业务蒸蒸日上,团队规模变得更大,对系统的稳定性、吞吐量、性能有了更高的要求,出现了多个AP访问多个RM的分布式事务场景。此时需要更好的解决方案(不想用收费版Atomikos,也不想依赖Atomikos)。于是行业内开始涌现出一些分布式事务解决方案(京东的JDTX、阿里的Seata),它们参考了DTP模型,但又不完全遵循标准的DTP,主要原因在
DTP模型完全满足ACID(前提是使用SERIALIZABLE隔离级别),是分布式事务的可选方案之一。但在当代,大多数互联网公司更愿意在一致性上做出一定程度的妥协,从而换取高并发,这一点可以参考CAP理论与BASE理论。
CAP定理
2000年,加州大学柏克莱分校的计算机科学家埃里克·布鲁尔在分布式计算原理研讨会(PODC)上提出猜想。2002年,麻省理工学院(MIT)的赛斯·吉尔伯特和南希·林奇发表了布鲁尔猜想的证明,使之成为一个定理。
在理论计算机科学中,
想象有两个节点,允许至少一个节点更新状态则会导致数据不一致,即丧失了C性质。如果为了保证数据一致性,将其中一个节点设置为不可用,那么又丧失了A性质。除非两个节点可以互相通信,才能既保证C又保证A,这又会导致丧失P性质。
BASE理论与柔性事务解决方案基础
2008年5月1号,eBay的架构师Dan Pritchett在ACM上发表了一篇文章,名为《BASE: An Acid Alternative: In partitioned databases, trading some consistency for availability can lead to dramatic improvements in scalability.》
BASE(basically available,soft state,eventually consistent)是ACID的替代方案,
Dan Pritchett在文章中给出了一个通用的不依赖2PC的分布式事务解决方案:
消息队列解耦法
BASE是CAP在长期实践中得出的普适性方案,大多数场景都能适用,是柔性事务解决方案的理论基础。分布式事务解决方案分为四种模式:AT、TCC、Saga、XA,XA模式在上文中已经讲过,很少被使用。在后续文章中,会对AT、TCC、Saga模式进行详细梳理。