站点可靠性工程之旅
SRE经过谷歌的实践和推广,已经被很多互联网公司所采用。如果想要实践SRE,成为SRE工程师,需要做好哪些方面的知识储备?本文介绍了SRE相关的技术,提供了大量有益的资源,有志于这一方向的同学可以以此作为技术发展路线图。原文:A Journey To The Site Reliability Engineering

很多组织都已经开始采用站点可靠性工程(SRE,Site Reliability Engineering)实践来代替传统的运维。LinkedIn上最新的工作搜索显示,全球范围内有超过19万个SRE工程师职位空缺。

如果你还不熟悉SRE,那么可以看看谷歌是如何描述的~
SRE是当你要求软件工程师设计一个运营团队时所发生的事情。
SRE由7个重要原则定义 --
运维是一个软件问题(Operations is a software problem)
按服务水平目标管理(Managed by Service Level Objectives)
尽量减少工作量(Work to minimize the toil)
把今年的工作自动化(Automate this year’s job away)
通过减少失败的代价来快速行动(Move fast by reducing the cost of failure)
与开发者分享所有权(Share ownership with the developers)
无论是什么职能或职位,都使用相同的工具(Use the same tooling, regardless of function or job title)
对于拥有运维支持、系统管理、基础架构、DevOps工程师等背景的人来说,SRE工程是一个很好的职业发展方向。
在本文中,我将提供各种资源,帮助你开始SRE工程师之旅。
掌握SLO的艺术(Mastering the Art of Service Level Objectives(SLOs))
为了旅程顺利,我们有必要从理解服务水平指标(SLIs, Service Level Indicators)和服务水平目标(SLOs, Service Level Objectives)的概念开始。
SLI: 服务 可靠性 的 可量化 度量
SLO: 为SLI设置 可靠性目标
有很多关于SLI和SLO的资源,但我建议通过SLO艺术工作坊来深入理解这一概念。
如果你是某个尝试采用SRE实践的组织的一员,那么我建议在组织内为有抱负的SRE开展这个工作坊。
工作坊旨在向你介绍如何以数据驱动、客观和以用户为中心的方式通过SLO和错误预算(Error Budgets)来度量和管理服务的可靠性。
工作坊可以指导我们选择正确的SLI,并通过案例帮助我们获得定义SLI/SLO的实践经验。
在学习的过程中,请保持开放的思维和新鲜的视角,因为我看到很多人认为SLI/SLO类似于他们使用的APM工具所做的基础设施监控,但事实并非如此!
云技术(Cloud Expertise)
根据Gartner的报告,超过75%的企业都有云优先战略。
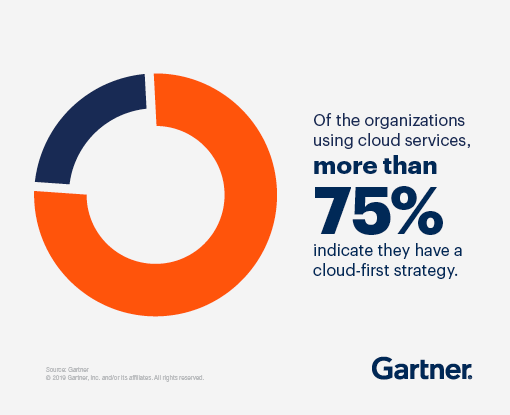
因此,熟悉AWS、GCP和Azure等云服务是非常必要的。
许多组织都在积极使用云技术进行应用程序现代化转型之旅,SRE被要求在这一转变过程中发挥重要作用。
在互联网上有很多像Udemy, PluralSight, Coursera, CloudGuru等网站来提升我们的知识储备。
基础设施即代码(Infrastructure as Code(IaC))
随着组织在云中迁移工作负载,高效、动态的管理基础设施的需求就更加突出了。因此,SRE应该拥有下面这样的IaC工具:
Terraform
Ansible
Chef
等等
即使所有云服务提供商都有自己的SDK/Shell来管理服务,使用IaC工具仍然有很多好处。
下面的内容引用自《Quickly Deploy Applications Using Terraform With Kubernetes on GCP》:
Terraform能够显示当前状态和期望状态之间的差异,这意味着一旦我们编辑了Terraform配置文件,就能看到将要做的改变。
Terraform不仅负责初始部署,还负责维护。我们可以使用命令轻松的创建、更新和删除跟踪的资源。
清理Terraform构建的所有东西非常容易。如果使用脚本,我们还必须编写一个清理脚本。但对于Terraform,可以简单的通过“terraform destry”命令来实现。
Terraform能够检查配置文件中声明的动作的顺序。这意味着,如果我们想运行基于Kubernetes的服务或部署,即使我们错误的声明了操作的顺序,Terraform仍然将首先创建集群。
你可以查看以下链接来了解关于这个主题的更多信息。
容器及容器编排平台(Containers & Container Orchraction Platforms)
由于SRE在应用程序部署中扮演着关键角色,所以了解容器和容器编排平台非常重要。
许多组织使用Docker和Kubernetes平台进行服务部署,可以在网上找到大量关于这个话题的资源。
这里有一些可以作为开始的链接:
持续集成及持续部署(Continuous Integration & Continous Deployment(CI/CD))
SRE需要将尽可能多的工作自动化,为应用程序提供适当的CI/CD流水线是快速交付的重要部分。许多组织使用下面这样的平台:
GitLab
GitHub
Azure DevOps
Jenkins
等等
因此,拥有建立CI/CD流水线的专业知识是一项基本技能。这些平台中有很多都支持免费服务,可以不用花一分钱就能自学。
这里有一些学习资源:
发布策略(Release Strategies)
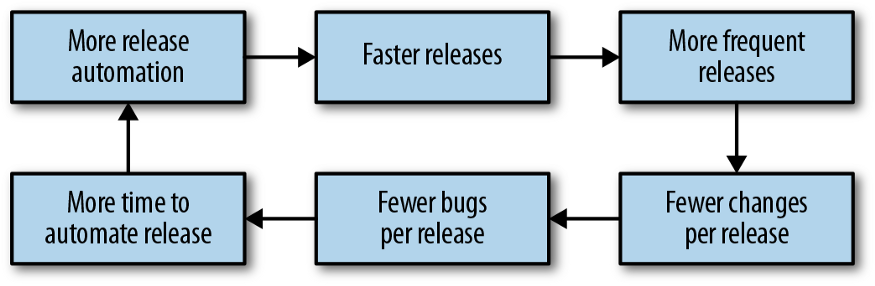
作为SRE角色的一部分,我们需要不断为用户部署新特性。这么做的同时,还需要确保在部署新特性时没有消耗错误预算(Error Budget),因此需要熟悉如下发布策略:
金丝雀发布
蓝绿发布
等等
熟悉特性标记(feature-flag)的开发策略将增加优势。如果使用像Kubernetes这样的容器编排平台,可以使用Kubernetes的定义文件描述这些策略。
在谷歌的SRE工作手册中深入介绍了金丝雀发布的过程。
事故响应和非指责的事后剖析(Incident Response & Blameless Postmortems)
随叫随到是SRE的另一个重要职责。因此,SRE需要对事故响应流程有非常好的理解。
PagerDuty事故响应课程涵盖了如下话题:
什么是事故?
事故级别
事故管理的各种角色
事故电话礼仪
等等
将事故响应过程记录下来是很重要的,因为如果人们知道事故发生时如何应对,就能更好的管理突发事故。
PagerDuty还有另一个关于如何在SRE团队中培养非指责文化的课程,其中提供了一些非常详细的模板,可以用来执行无指责的事后分析。
强烈推荐这两门课程。
安全(Security)
因为SRE负责整个应用,对应用安全性有基本的了解总是好的。
强烈建议你熟悉下面提到的概念:
对于自动化部署,SRE需要管理各种服务凭证,因此应该熟悉凭证管理工具,如HashiCorp Vault或云原生加密管理解决方案,如Azure密钥库、谷歌加密管理器等。
文档(Documentation)
SREs需要确保所有重要的文件都定期更新,易于遵循,因此应该专注于制作高质量的文档,比如:
运维操作手册(Operation Runbooks)
发布/回滚文档(Release & Rollback documents)
等等
谷歌提供免费的技术写作课程,建议大家在日常生活中学习并运用其中的原则,当然如果你有时间的话也可以报名参加有导师指导的培训课程。
灾难恢复测试/混沌工程(Disaster Recovery Testing / Chaos Engineering)
为了测试平台的健壮性,SRE还负责执行灾难恢复测试。谷歌将灾难恢复测试作为其健壮服务的一部分,《Weathering the Unexpected》是一篇关于谷歌DiRT项目的详细文章。
最近Netflix的混沌工程理念变得非常流行,我在《Why Every Software Developer Needs to Learn Chaos Engineering》里也写过关于混沌工程的内容。
非抽象大规模设计(Non-Abstract Large Scale Designs(NALSD))
当我们开始讨论大型、复杂、分布式系统时,谷歌已经设计了一个流程,可以帮助SRE发展评估、设计和衡量大型系统的能力。
NALSD过程包含了问题陈述、需求收集,以及帮助评估大规模系统对不同故障模式的容忍度的迭代系统设计。
谷歌还提供了一个工作坊,带领我们了解分布式消息队列(如pub/sub)的系统设计,并解释如何对其实现NALSD原则。
我个人从中学到了很多。
社区
为了更多的向他人学习,并了解行业最新动态,建议加入以下在线社区:
结论
总的来说,SRE工程流程非常有趣,并且正在被许多组织所采用。
References:
[1] A Journey To The Site Reliability Engineering:
[3] The Latest Cloud Computing Technology and Security:
[4] Quickly Deploy Applications Using Terraform With Kubernetes on GCP:
[10] PagerDuty Incident Response:
[13] Application Threat Modelling:
[15] Technical Writing Courses for Engineers:
[16] Best Practices When Documenting Your Code for Software Engineers:
[17] Weathering the Unexpected:
[18] Why Every Software Developer Needs to Learn Chaos Engineering:
你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。
微信公众号:DeepNoMind