3、深潜KafkaProducer核心架构
kafka producer 示例演示
按照国际惯例,先来一个 demo 示例,带同学们了解一下 kafka Producer 的基本使用,示例的具体代码如下:
public class ProducerDemo {
public static void main(String[] args) throws Exception {
Properties config = new Properties();
config.put("client.id", "ProducerDemo");
// 指定kafka broker集群的地址
config.put("bootstrap.servers", "localhost:9092");
// 配置kafka集群响应之前,需要有多少replica成功复制了该message,all表示整个ISR集合都复制完成
config.put("acks", "all");
// 指定message key和value的序列化器,它负责将KV序列化成字节数组
config.put("key.serializer", StringSerializer.class);
config.put("value.serializer", StringSerializer.class);
KafkaProducer producer = new KafkaProducer<>(config);
for (int i = 0; i < 10; i++) {
// 消息的value
long startTime = System.currentTimeMillis();
// 构造ProducerRecord对象,其中记录了该message的目标topic以及key和value
ProducerRecord record =
new ProducerRecord<>("test_topic", String.valueOf(i), "YangSizheng_" + startTime);
// 第二个参数是一个匿名的CallBack对象,当producer接收到kafka集群发来的ACK确认消息的时候,
// 会调用其onCompletion()方法完成回调
Future future = producer.send(record, new Callback() {
public void onCompletion(RecordMetadata metadata, Exception e) {
if (e != null)
System.out.println("Send failed for record:" + record + ", error message:" + e.getMessage());
}
});
// send()方法是异步发送message,返回的是一个Future对象。如果需要同步发送,可以调用其get()方法,
// 返回的RecordMetadata中包含了该message落到了哪个partition上,以及分配的offset多少
RecordMetadata recordMetadata = future.get();
System.out.println("partition:" + recordMetadata.partition()
+ ", offset:" + recordMetadata.offset());
}
}
}
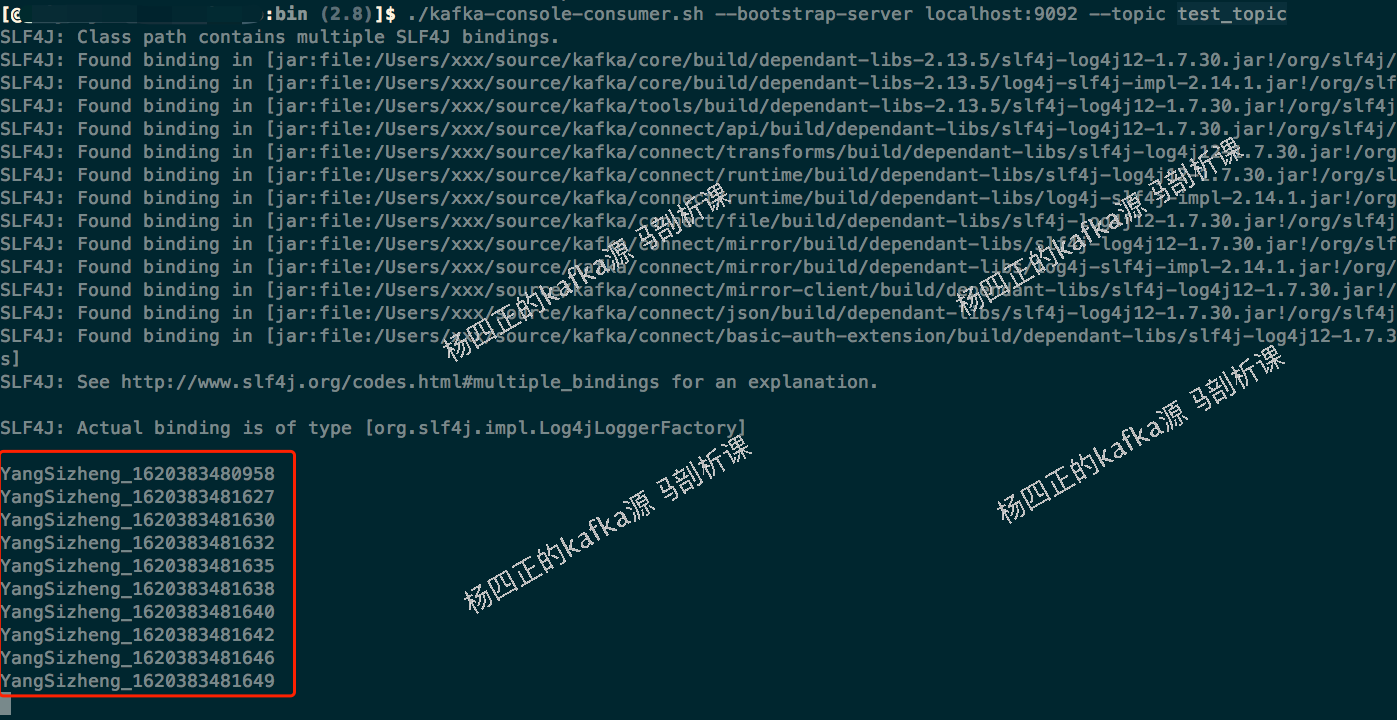
在执行 ProducerDemo 之前,我们执行命令启动命令行 consumer:
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test_topic
然后执行 ProducerDemo 可以在控制台看到如下输出:
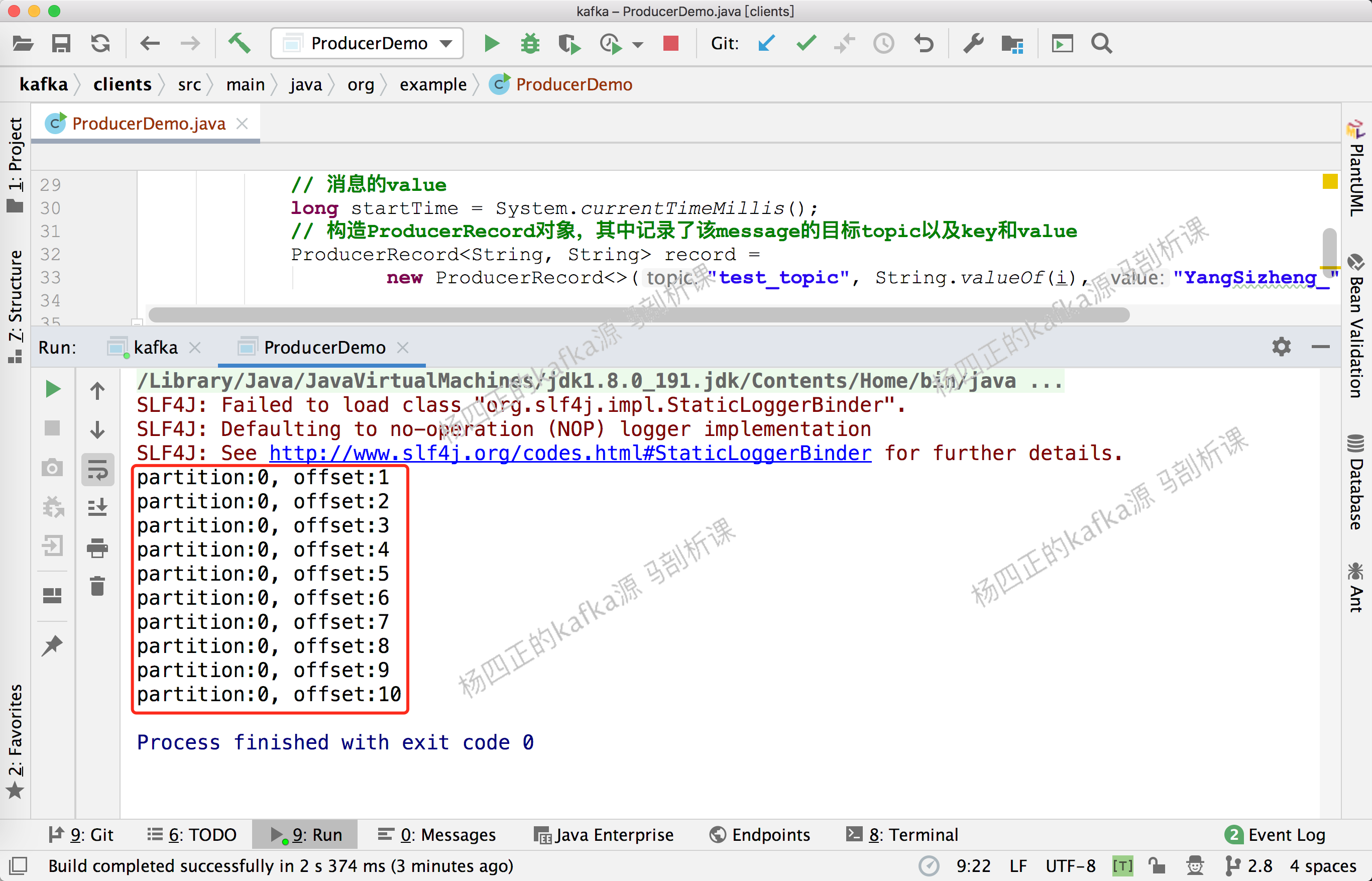
在 命令行中看到如下输出:
kafka producer 架构概述
了解了 kafka producer 的基本使用之后,我们开始深入 producer 的架构进行介绍,千言万语不及不急一张图,下图就是 kafka producer 的核心架构:
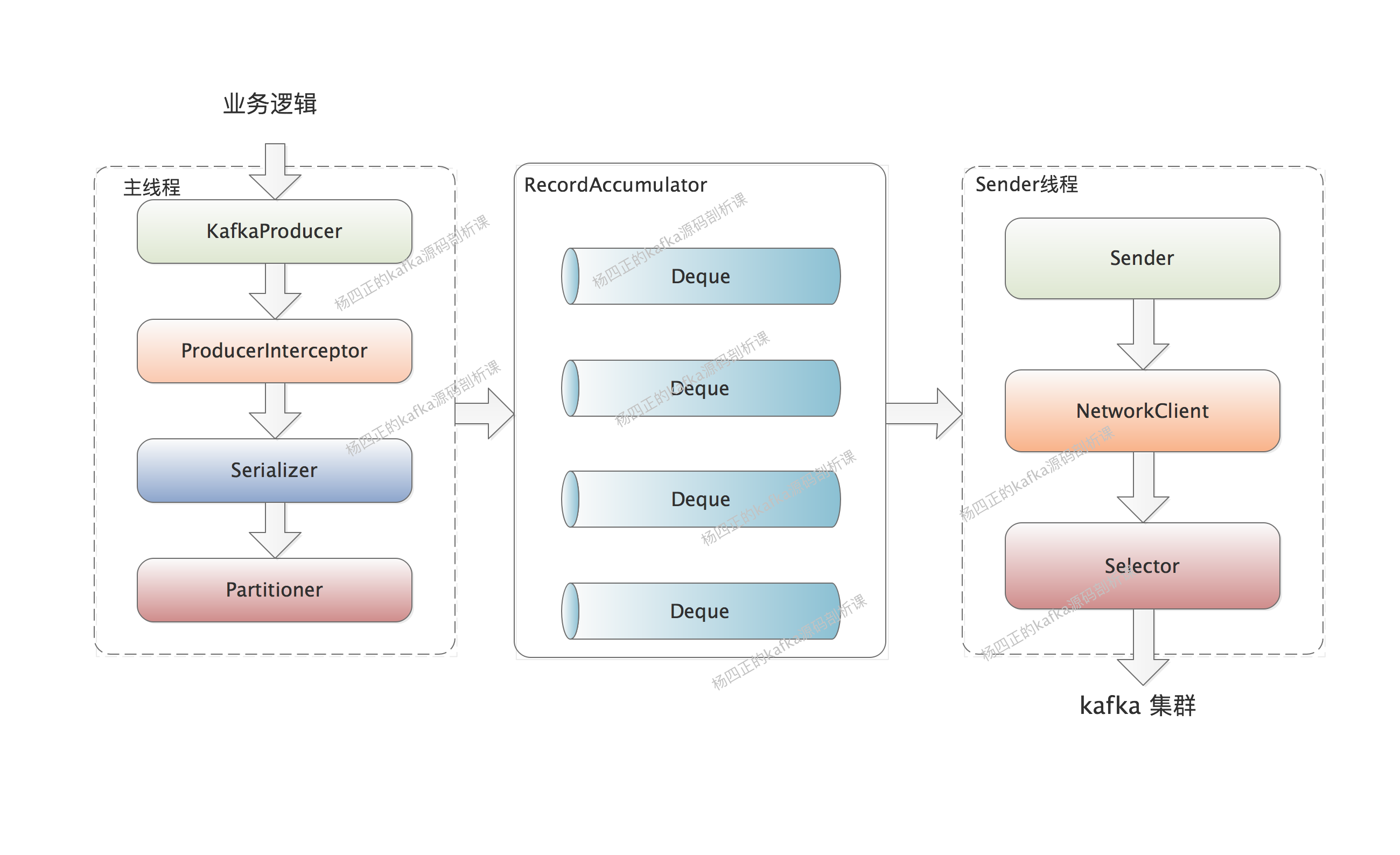
这里描述一下上图中涉及到的核心组件在,这里涉及到两个线程,一个是我们的业务线程(也就是图中的主线程),另一个是 Sender 线程,我们一个个来说。首先是主线程的逻辑:
下面来看 Sender 线程的逻辑:
KafkaProducer.send() 核心
介绍完 kafka producer 的核心架构和流程之后,我们开始深入分析 KafkaProducer.send() 方法,即主线程的核心逻辑,还是开局一张图,后面都好说:
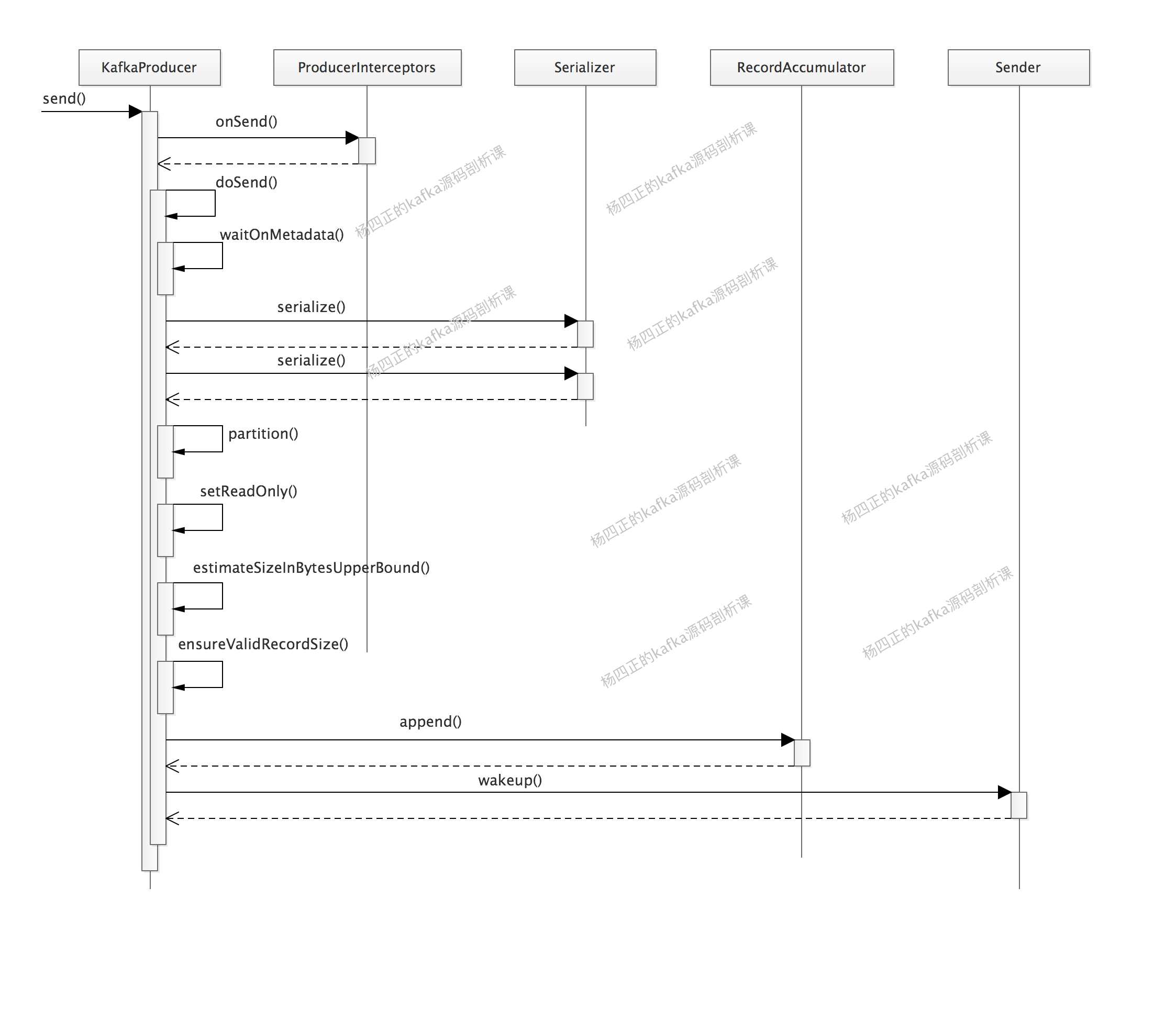
下面来描述一下 KafkaProducer.send() 方法的核心逻辑,也就是上图的核心步骤:
ProducerInterceptor
首先来看 ProducerInterceptors,其中维护了一个 ProducerInterceptor 集合,其 onSend()方法、onAcknowledgement()方法、onSendError()方法,实际上,是循环调用 ProducerInterceptor 集合的方法。我们可以通过实现 ProducerInterceptor 接口的 onSend() 方法来拦截或修改待发送的 message,也可以通过实现 onAcknowledgement()方法、onSendError()方法先于用户的 Callback,对kafka集群响应进行预处理。
Kafka Metadata
在我们通过 KafkaProducer 发送 message 的时候,我们只明确指定了 message 要写入哪个 topic ,并没有明确指定要写入的 partition。
但是同一个 topic 的 partition 可能位于 kafka 的不同 broker 上,所以 producer 需要明确的知道该 topic 下所有 partition 的元信息(即所在 broker 的 IP、端口等信息),这样才能与 partition 所在 broker 建立网络连接并发送 message。
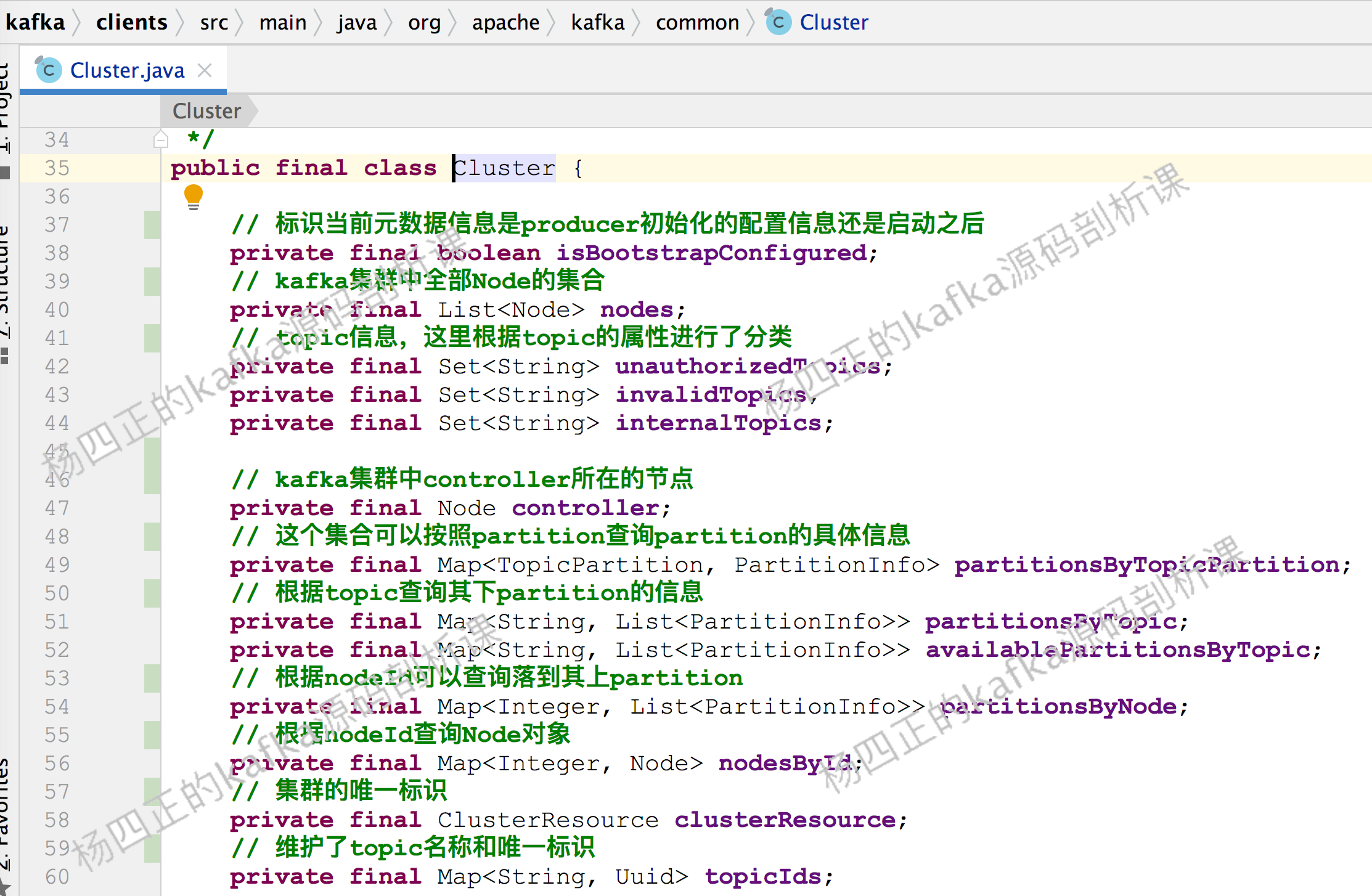
在 KafkaProducer 中,使用 Node、TopicPartition、PartitionInfo 三个类来记录 Kafka 集群元数据:
Node 表示 kafka 集群中的一个节点,其中维护了节点的 host、ip、port 等基础信息。
TopicPartition 用来抽象一个 topic 中的的一个 partition,其中维护 topic 的名称以及 partition 的编号信息。
PartitionInfo 用来抽象一个 partition 的信息,其中:
leader 字段记录了 leader replica 所在节点的 id
replica 字段记录了全部 replica 所在的节点信息
inSyncReplicas 字段记录了ISR集合中所有replica 所在的节点信息。
kafka producer 会将上述三个维度的基础信息封装成 Cluster 对象使用,下面是 Cluster 包含的信息:
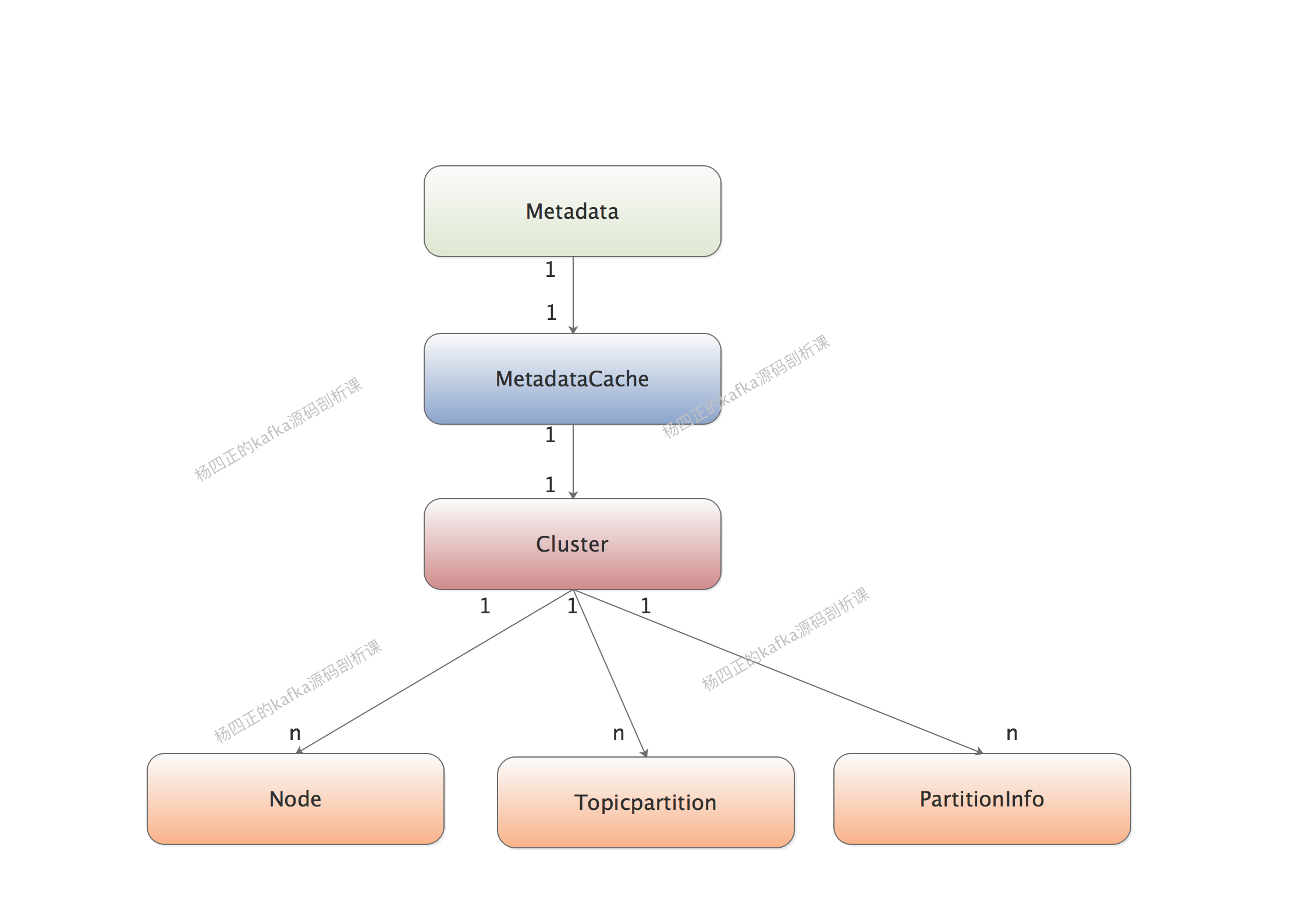
再向上一层,Cluster对象会被维护到Metadata中,Metadata同时还维护了Cluster的版本号、过期时间、监听器等等信息,如下图所示:

经过上面的分析,我们可以得到下面这张简图:
静态数据结构分析完了之后,我们来看 KafkaProducer.waitOnMetadata()方法是如何工作的:
private ClusterAndWaitTime waitOnMetadata(String topic, Integer partition, long nowMs, long maxWaitMs) throws InterruptedException {
// 获取MetadataCache当前缓存的Cluster对象
Cluster cluster = metadata.fetch();
if (cluster.invalidTopics().contains(topic))
throw new InvalidTopicException(topic);
// 更新ProducerMetadata的缓存
metadata.add(topic, nowMs);
// 从partitionsByTopic集合中获取目标topic的partition数量
Integer partitionsCount = cluster.partitionCountForTopic(topic);
// 要是没有目标topic的元数据存在,则直接返回ClusterAndWaitTime对象,无需下面的更新操作
if (partitionsCount != null && (partition == null || partition < partitionsCount))
return new ClusterAndWaitTime(cluster, 0);
long remainingWaitMs = maxWaitMs;
long elapsed = 0;
do {
// 更新ProducerMetadata缓存
metadata.add(topic, nowMs + elapsed);
// 更新获取当前updateVersion,并设置相应标识,尽快触发元数据更新
int version = metadata.requestUpdateForTopic(topic);
// 唤醒Sender线程,由Sender线程去完成元数据的更新
sender.wakeup();
try {
// 阻塞等待元数据更新,停止阻塞的条件是:更新后的updateVersion大于当前version,超时的话会直接抛出异常
metadata.awaitUpdate(version, remainingWaitMs);
} catch (TimeoutException ex) {
throw new TimeoutException(。。。);
}
cluster = metadata.fetch(); // 获取最新的Cluster
elapsed = time.milliseconds() - nowMs;
if (elapsed >= maxWaitMs) {
throw new TimeoutException(partitionsCount == null ?
String.format("Topic %s not present in metadata after %d ms.",
topic, maxWaitMs) :
String.format("Partition %d of topic %s with partition count %d is not present in metadata after %d ms.",
partition, topic, partitionsCount, maxWaitMs));
}
metadata.maybeThrowExceptionForTopic(topic);
remainingWaitMs = maxWaitMs - elapsed; // 计算元数据更新耗时
partitionsCount = cluster.partitionCountForTopic(topic); // 获取partition数
} while (partitionsCount == null || (partition != null && partition >= partitionsCount));
return new ClusterAndWaitTime(cluster, elapsed);
}
这里具体如何更新元数据,我们将在介绍 Sender 线程工作流程的时候,详细分析。
序列化器
分布式系统中各个节点相互通信,必然涉及到内存对象与字节流之间的转换,也就是序列化与反序列化。
kafka 中的序列化器接口是 Serializer,负责将对象转换成字节数组;反序列化器是 Deserializer 接口,负责将字节数组转换成内存中的对象。
下面展示了 Serializer 和 Deserializer 接口的实现类:


从上图中我们可以看出,kafka 自带了常用 Java 类型的 Serializer 实现和 Deserializer 实现,当然,我们也可以自定义Serializer和Deserializer实现来处理复杂类型。
下面我们以 StringSerializer 实现为例说明一下 Serializer 的核心实现:
partition选择
在 waitOnMetadata() 方法拿到最新的集群元数据之后,下面就要开始确定待发送的 message 要发送到哪个 partition 了。
如果我们明确指定了目标 partition,则以用户指定的为准,但是一般情况下,业务并不会指定 message 需要写入到哪个 partition,此时就会通过 Partitioner 结合 集群元数据计算出一个目标 partition。
下图展示了 Partitioner 接口的全部实现:
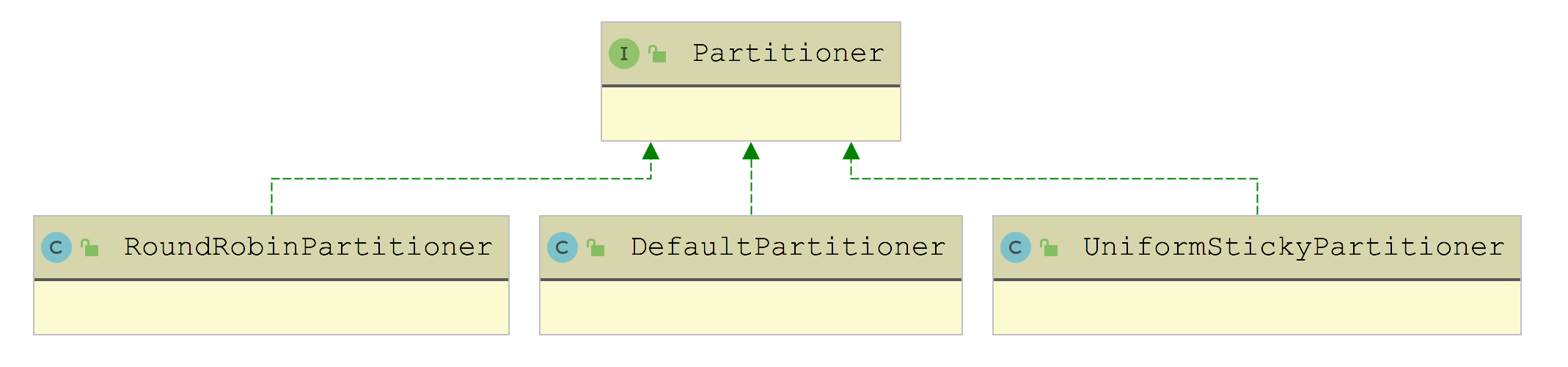
从名字也能看出,DefaultPartitioner 是默认实现,其中的 partition() 方法中:
这里解释一下 StickyPartitionCache 的功能。我们前面介绍整个 KafkaProducer 流程的时候说过,RecordAccumulator 是一个缓冲区,主线程发送的 message 会先进入 RecordAccumulator,然后 Sender 线程攒够了 message 的时候进行批量发送。
触发 Sender 线程批量发送堆积 message 的条件主要有两方面:
StickyPartitionCache 主要实现的是"黏性选择",就是尽可能的先往一个 partition 发送 message,让发往这个 partition 的缓冲区快速填满,这样的话,就可以降低 message 的发送延迟。我们不用担心出现 partition 数据量不均衡的情况,因为只要业务运行时间足够长,message 还是会均匀的发送到每个 partition 上的。
下面来看 StickyPartitionCache 的实现,其中维护了一个 ConcurrentMap(indexCache字段),key 是 topic,value 是当前黏住了哪个 partition。
在 partition() 方法中,StickyPartitionCache 会先从 indexCache 字段中获取黏住的 partition,如果没有,则调用 nextPartition() 方法向 indexCache 中写入一个。在 nextPartition() 方法中,会先获取目标 topic 中可用的 partition,并从中随机选择一个写入 indexCache。
最后,同学们可能问,什么时候更新黏住的 partition 呢?我们看一下 KafkaProducer.doSend()方法中,有这么一个片段:
// 尝试向RecordAccumulator中追加message
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, true, nowMs);
// 由于目标partition的当前batch没有空间了,需要更换一个partition,再次尝试
if (result.abortForNewBatch) {
int prevPartition = partition;
// 更换目标partition,同时也会更换StickyPartitionCache黏住的partition
partitioner.onNewBatch(record.topic(), cluster, prevPartition);
// 计算新的目标partition
partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
// 再次调用append()方法向RecordAccumulator写入message,如果该partition缓冲区中的batch也没有空间,
// 则创建新batch了,不会再次尝试了
result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, false, nowMs);
}
RecordAccumulator.append()方法我们后面分析。
UniformStickyPartitioner 这个 Partitioner 底层也是依赖 StickyPartitionCache 实现黏性发送的,不再展开介绍。
再来看 RoundRobinPartitioner 实现,从名字也可以看出,它是按照轮训的策略来计算目标 partition,其中也维护了一个 ConcurrentMap 集合(topicCounterMap字段),其中的 key 是 topic 的名称,value 是一个递增的 AtomicInteger。
在 RoundRobinPartitioner.partition() 方法中,会先查找目标 topic 的 partition 总数,然后自增上述 AtomicInteger 值并与 partition 总数取模,得到目标 partition 的编号。
总结
本课时我们首先介绍了 KafkaProducer 的基础使用,然后介绍了 KafkaProducer 的核心架构,最后介绍了 KafkaProducer.send() 方法中主线程的核心操作。
下一课时,我们将开始介绍 KafkaProducer 中 RecordAccumulator 相关的内容。
本课时的文章和视频讲解,还会放到:
微信公众号:

B 站搜索:杨四