Elasticsearch 原理解析(介绍)
介绍
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎.当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作:
分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
实时分析的分布式搜索引擎。
可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
基本概念
对应关系

{
"name" : "John",
"sex" : "Male",
"age" : 25,
"birthDate": "1990/05/01",
"about" : "Hello world",
"interests": [ "sports", "game" ]
}名词解析
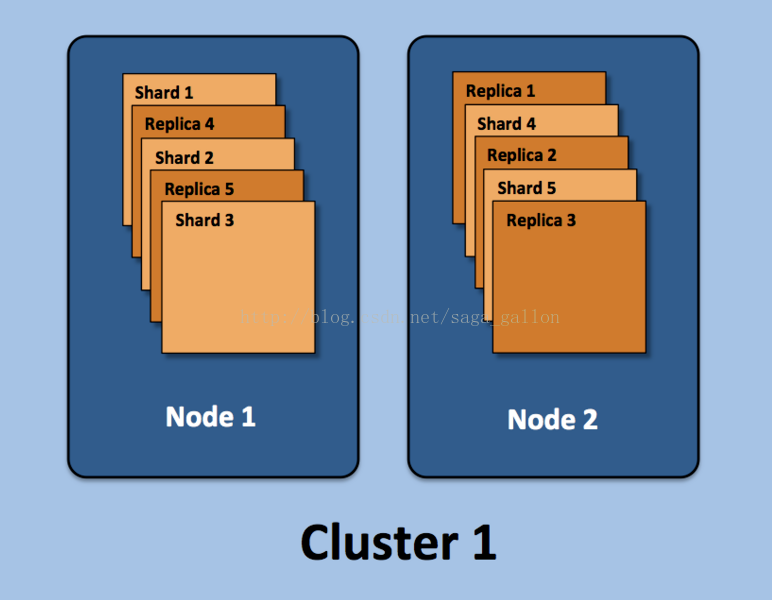
集群(cluster) : 由一个或多个节点组成, 并通过集群名称与其他集群进行区分 节点(node): 单个ElasticSearch实例 索引(index): 在ES中, 索引是一组文档的集合 分片(shard): 因为ES是个分布式的搜索引擎, 所以索引通常都会分解成不同部分, 而这些分布在不同节点的数据就是分片. ES自动管理和组织分片, 并在必要的时候对分片数据进行再平衡分配, 所以用户基本上不用担心分片的处理细节, 一个分片默认最大文档数量是20亿.副本(replica): ES默认为 一个索引创建5个主分片 , 并分别为其创建 一个副本分片 . 也就是说每个索引都由5个主分片成本, 而每个主分片都相应的有一个copy.
架构
集群
节点架构图:
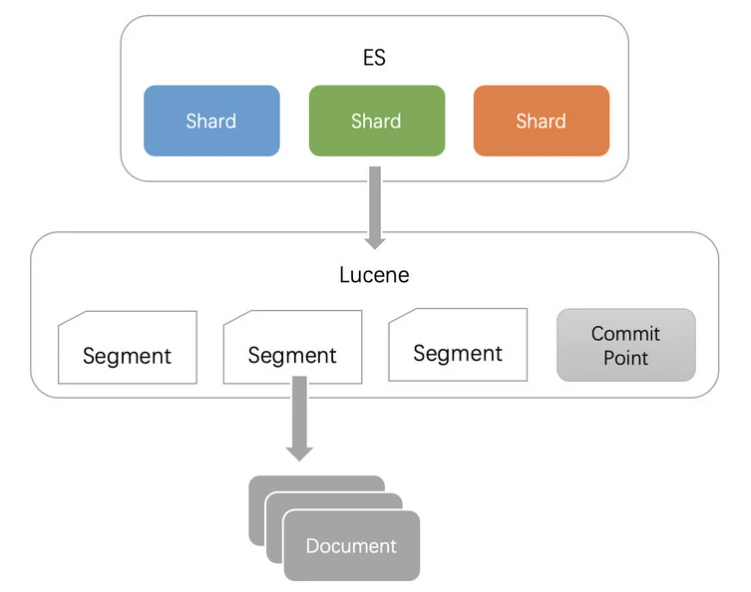
分片
每个分片本质上就是一个Lucene索引, 因此会消耗相应的文件句柄, 内存和CPU资源 每个搜索请求会调度到索引的每个分片中. 如果分片分散在不同的节点倒是问题不太. 但当分片开始竞争相同的硬件资源时, 性能便会逐步下降 每个搜索请求会遍历这个索引下的所有分片 ES使用词频统计来计算相关性. 当然这些统计也会分配到各个分片上. 如果在大量分片上只维护了很少的数据, 则将导致最终的文档相关性较差
流程
写入数据
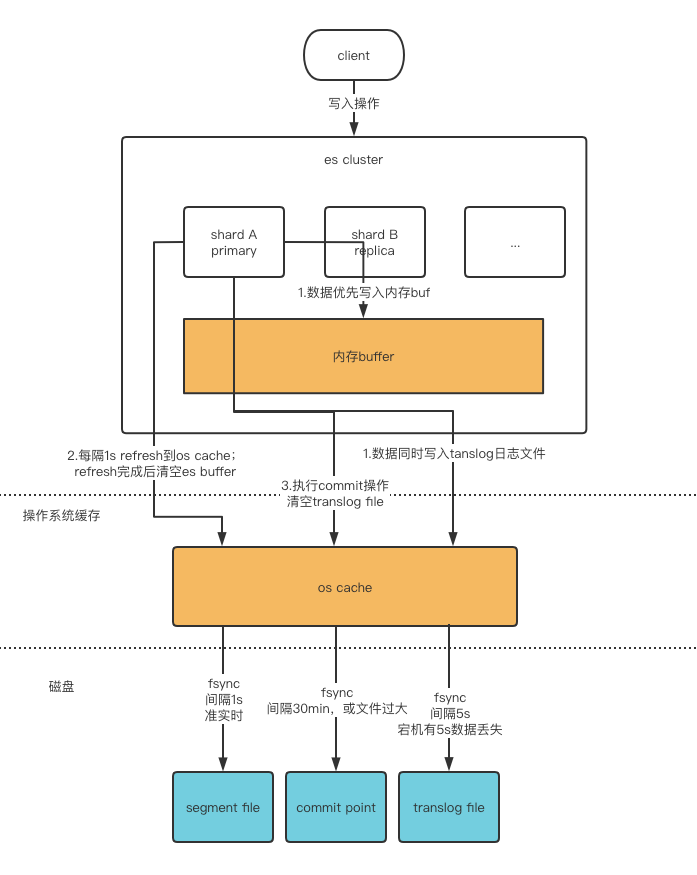
读取数据
搜索过程
索引
一切设计都是为了提高搜索的性能
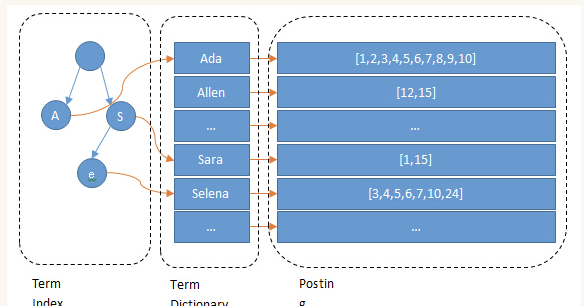
倒排索引


Posting List
Term dictionary
Term Index
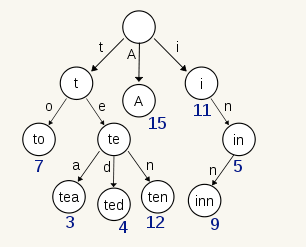
压缩技巧
Posting List压缩
Roaring bitmap(RBM)
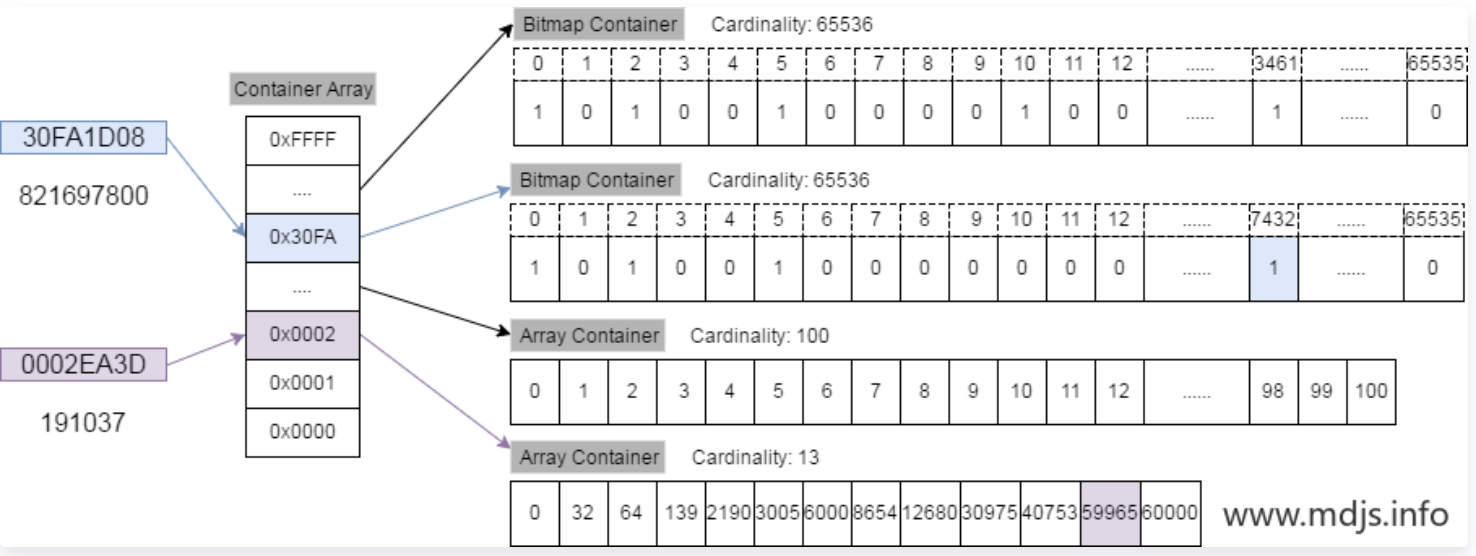
联合索引
利用跳表(Skip list)的数据结构快速做“与”运算,或者对最短的posting list中的每个id,逐个在另外两个posting list中查找看是否存在,最后得到交集的结果。 利用上面提到的bitset按位“与”直接按位与,得到的结果就是最后的交集。
总结
将磁盘里的东西尽量 搬进内存 , 减少磁盘随机读取 次数(同时也利用磁盘顺序读特性),结合各种奇技淫巧的 压缩 算法,用及其苛刻的态度使用内存。
注意事项
不需要索引的字段,一定要明确定义出来,因为默认是自动建索引的 同样的道理,对于String类型的字段,不需要analysis的也需要明确定义出来,因为默认也是会analysis的 选择有规律的ID很重要,随机性太大的ID(比如java的UUID)不利于查询 上面看到的压缩算法,都是对Posting list里的大量ID进行压缩的,那如果ID是顺序的,或者是有公共前缀等具有一定规律性的ID,压缩比会比较高;
注意事项2
拒绝大聚合 拒绝模糊查询 拒绝深度分野 ES获取数据时,每次默认最多获取10000条,获取更多需要分页,但存在深度分页问题,一定不要使用from/Size方式,建议使用scroll或者searchAfter方式。scroll会把上一次查询结果缓存一定时间(通过配置scroll=1m实现),所以在使用scroll时一定要保证search结果集不要太大。 拒绝多层嵌套,不要超过2层,避免内存泄漏 拒绝top》100的潮汛top查询是在聚合的基础上再进行排序,如果top太大,cpu的计算量和耗费的内存都会导致查询瓶颈