每个程序员都应该知道的数字
中列出了“每个程序员都应该了解的数字(Numbers Everyone Should Know)”,对计算机各类操作的耗时做了大致估计。这些数字在很多地方被引用。

这些数字最早应该出现在 Peter Norvig 著名的博客 ,不过略有一些不同:
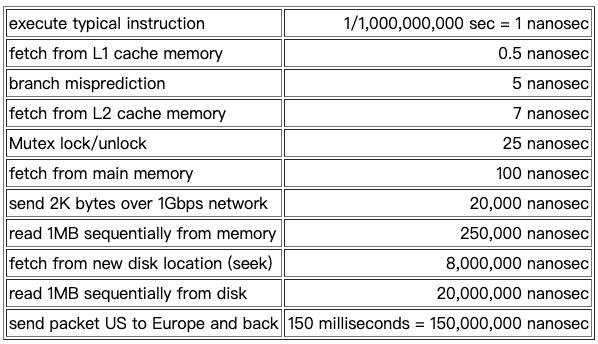
这些数字还准确吗?
这些数字大多是 2009 年给出的,虽然摩尔定律已经失效,但计算机发展到今天,这些数字确实有些过时。
但是,jeff dean 和 Peter Norvig 给出这些数字的重点在于它们之间的数量级和比例,而不是具体的数字。
对于今天的数字,伯克利大学有个,可以查看每年各个操作耗时的变化,根据网页的数据,总结每 10 年来的变化如下图:
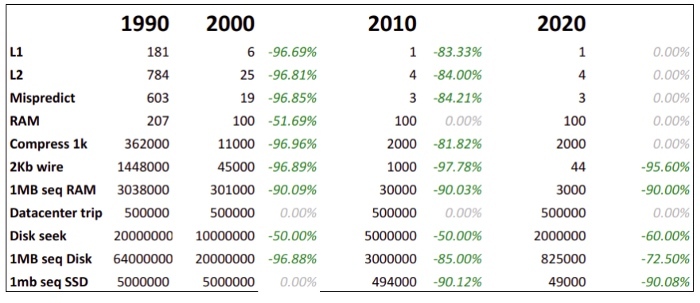
可以观察到:
网络传输速度有了质的飞跃;
同一数据往返和*
从美国发送到欧洲 *的耗时没有任何变化,原因可以理解,信号在光纤中是速度是不变的;2000 年以来,前两列的数值没有太大变化,但是内存、SSD 和机械硬盘顺序读取速度有了非常大的提升;
2020 年版本
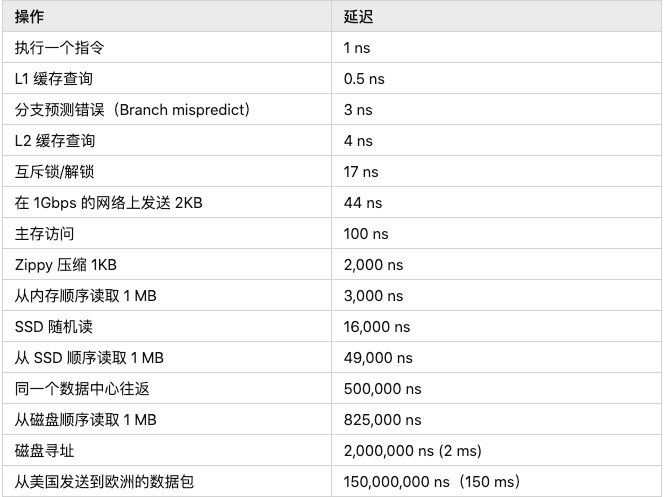
注:
1 ns = 10^-9 seconds
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
这些数字有什么作用?
对于 ns 为单位的时间我们可能没有什么概念,所以我们可以,来观察数量级的差距。
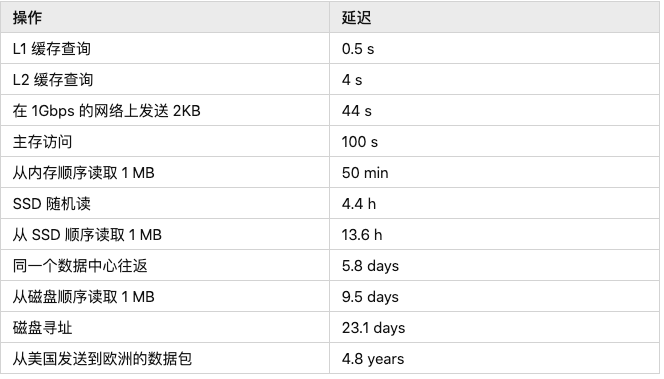
这样一来就非常明显了,L1 缓存查询相当于一次心跳,这样的话对于内存、网络、SSD 和机械硬盘之间的访问速度有了一个直观的对比:
内存:100 秒
SSD:4.4 小时
同一数据中心往返:5.8 天
机械硬盘寻址:23.1 天
了解这些数字有助于设计和比较不同的解决方案。可以看出,从远程服务器的内存中读数据要比直接从硬盘上读取要快的。
推广到一般的应用,这也意味着使用磁盘存储往往比使用数据库服务要慢(数据库通常已经把需要的数据放到了内存)。BTW,这些数字也被。
对于读取 1MB 数据,内存、SSD 和磁盘基本差了一个数量级:
内存: 50 分钟
SSD: 13.6 小时
磁盘: 9.5 天
尤其在设计存储引擎时,很多开源软件(Kafka、Leveldb、Rocksdb)都充分利用了存储介质顺序读、写速度远远快过随机读、写的特性,只做追加写操作来达到最佳性能。
延迟、带宽和吞吐之间有什么区别?
,延迟(Latency)、带宽(Bandwidth)和吞吐(Throughput)之间有什么区别?
最佳回答用水管来举例。

延迟表示通过管道需要花费的时间
带宽表示管道的宽度
每秒钟流过的水的数量就是吞吐
