又一个重量级的分布式链路分析的轮子
没错,强悍如斯,aws不仅自己做elasticsearch开源,连周边也做了,这次要说的就是分布式链路追踪分析功能。
这是Open Distro for Elasticsearch的一项新功能,使开发人员能够发现和解决分布式应用程序的性能问题。通过将跟踪数据添加到Open Distro for Elasticsearch现有的日志分析功能中,开发人员可以使用单一的解决方案来隔离性能问题的来源,并诊断其根本原因。OpenTelemetry是云原生计算基金会(CNCF)的一个项目,它提供了一套API、库、代理和收集器服务来捕获分布式跟踪,我们正在开放应用程序,使其能够被Open Distro for Elasticsearch监控,而不需要开发人员重新对其应用程序进行监控。
随着越来越多的应用程序转移到云端并转向分布式模型,故障排除对开发人员和IT运营部门来说变得越来越有挑战性。分布式应用可以由数百个共享服务组成,使每个服务都能独立扩展和发展。然而,用传统的方法来管理和监控分布式应用,依靠分析每个组件在自己的筒仓中的日志和指标,并不能提供端到端的可视性。由于无法快速识别性能和可用性问题的来源,导致问题解决时间过长,客户体验下降。
为了填补这一空白,今天许多开发人员使用Jaeger和Zipkin等开源工具来收集跟踪数据,这是一种专门的机器生成的数据形式,跟踪整个微服务架构的请求和响应。跟踪分析以Jaeger、Zipkin和OpenTelemetry SDKs的跟踪数据收集为基础,提供关于应用程序性能的新见解。例如,将类似的跟踪数据汇总到 "跟踪组",可以对关键的应用交易活动进行百分点性能监测(P80、P90、P95等),并从跟踪数据中创建 "服务地图",为开发人员提供服务性能和服务依赖性的实时视图。监测应用交易活动和服务性能可以帮助快速识别错误和异常延迟,有效地使开发人员能够 "大海捞针"。此外,在跟踪数据确定了问题的来源后,开发人员可以使用在日志事件中传播的跟踪标识符来排查和确定根本原因。
追踪分析的亮点
除了支持,Trace Analytics还支持与和 SDKs这两个流行的开源分布式跟踪系统的整合。Trace Analytics功能使用OpenTelemetry收集器等开源组件,还为Open Distro for Elasticsearch增加了新的开源组件,如Data Prepper和Kibana插件,下文将详细介绍。
Trace Analytics使用OpenTelemetry收集器作为收集跟踪数据的默认收集器,同时支持OpenTelemetry和OpenTracing标准。Trace Analytics支持与OpenTelemetry标准和OpenTracing标准兼容的应用SDK(如Jaeger和Zikpin)。
Trace Analytics 还与 AWS Distro for OpenTelemetry 集成,后者是 OpenTelemetry API、SDK 和代理/采集器的分布。它是OpenTelemetry组件的性能和安全分布,已经过生产使用的测试,并得到AWS的支持。客户可以使用AWS Distro for OpenTelemetry来收集多个监控解决方案的痕迹和指标,包括Open Distro for Elasticsearch和AWS X-Ray的痕迹,以及Amazon CloudWatch的指标。
Data Prepper是Open Distro for Elasticsearch的一个新组件,它从OpenTelemetry收集器接收跟踪数据,并对其进行聚合、转换和规范化,以便在Kibana中进行分析和可视化。关于如何为跟踪分析配置Data Prepper的细节,可以在中找到。
新的Trace Analytics Kibana插件可以在所有相关的跟踪和跨度执行的瀑布式图表中查看每个单独的跟踪,这使得很容易识别每个跟踪的所有服务调用、每个服务和每个跨度中花费的时间,以及每个跨度的有效载荷内容,包括错误。
跟踪分析Kibana插件还将跟踪数据汇总到跟踪组视图和服务地图视图中,以便在跟踪数据上实现对应用性能的监控洞察。通过超越搜索和分析单个跟踪的能力,这些功能使开发人员能够主动识别应用程序的性能问题,而不仅仅是在问题发生时做出反应。关于如何配置的细节可以在Trace Analytics Kibana插件的Readme中找到。
使用示例应用程序入门
让我们来了解一下安装Docker镜像的步骤,该镜像包含一个用OpenTelemetry SDK检测的样本应用程序,并使用Trace Analytics监控应用程序的性能。
提前准备:
Git
Docker - any above version 18.06.0+
第一步: 下载 Data Prepper
git clone https://github.com/opendistro-for-elasticsearch/Data-Prepper.git
第二步: 切换到 目录
cd Data-Prepper/examples/trace-analytics-sample-app
第三步: 启动
docker-compose up -d 注意:这一步耗时比较久
第四步:访问示例应用程序
示例应用程序的Docker也启动了Elasticsearch和Kibana,因此需要大约5分钟的时间来实现一切。该示例应用程序有简单的界面。可访问http://localhost:8089/。
第5步:连接到Trace Analytics Kibana插件以查看结果
访问Trace Analytics Kibana插件,网址是http://localhost:5601/app/opendistro-trace-analytics。这一步将要求提供Kibana用户名和密码,默认设置为admin/admin。一旦通过验证,你应该看到主仪表板,并有链路和服务的附加菜单。
仪表盘选项卡显示了由追踪组汇总的所有追踪的摘要。每个追踪组代表所有共享一个共同的API端点和API操作名称的追踪。每个跟踪组显示所选时间范围内的延迟范围,以及平均延迟、24小时延迟趋势缩略图、错误率和跟踪计数。通过点击蓝色的字段,你可以通过选定的属性(如时间范围、百分位数性能或跟踪组名称)过滤这个视图。
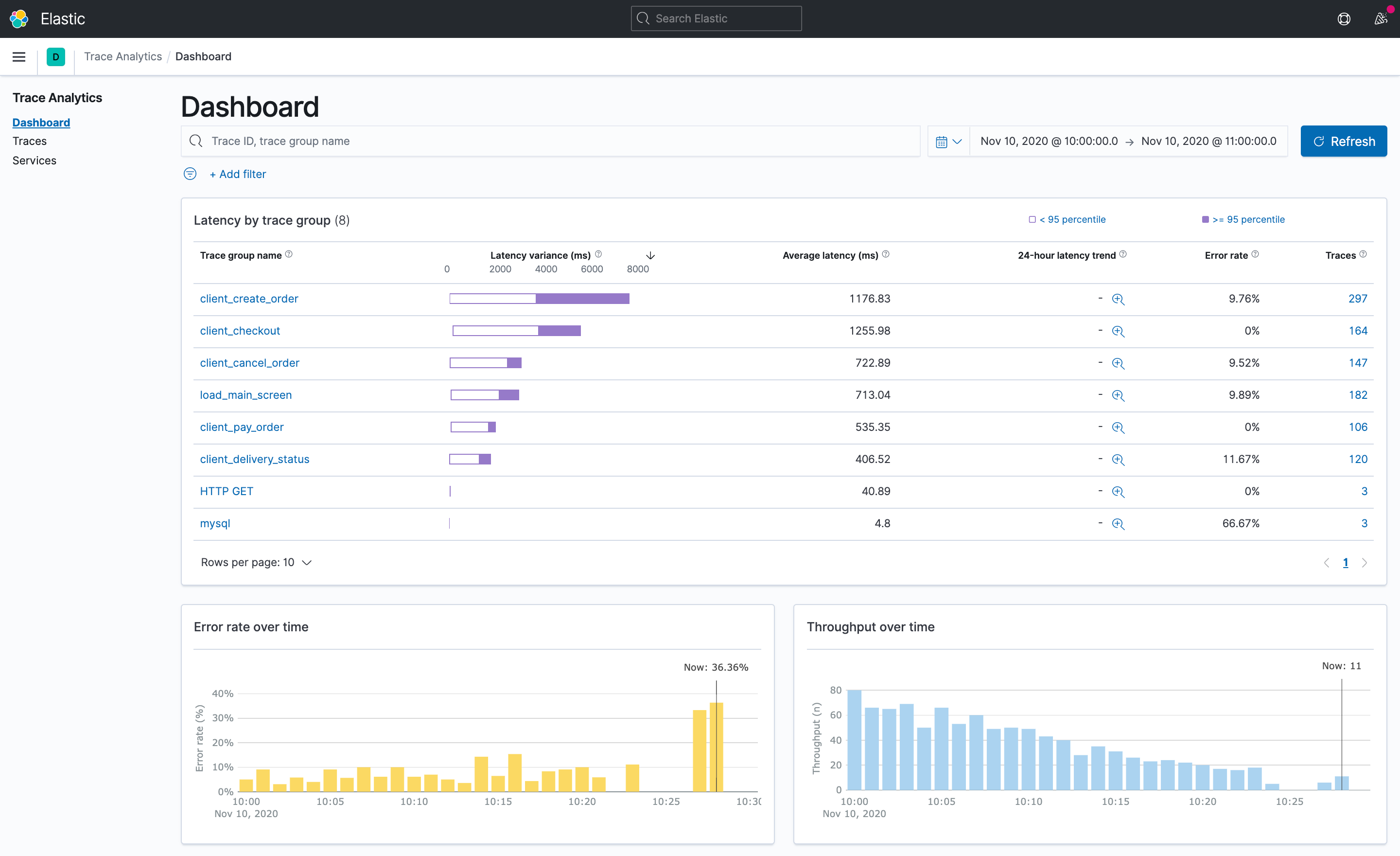
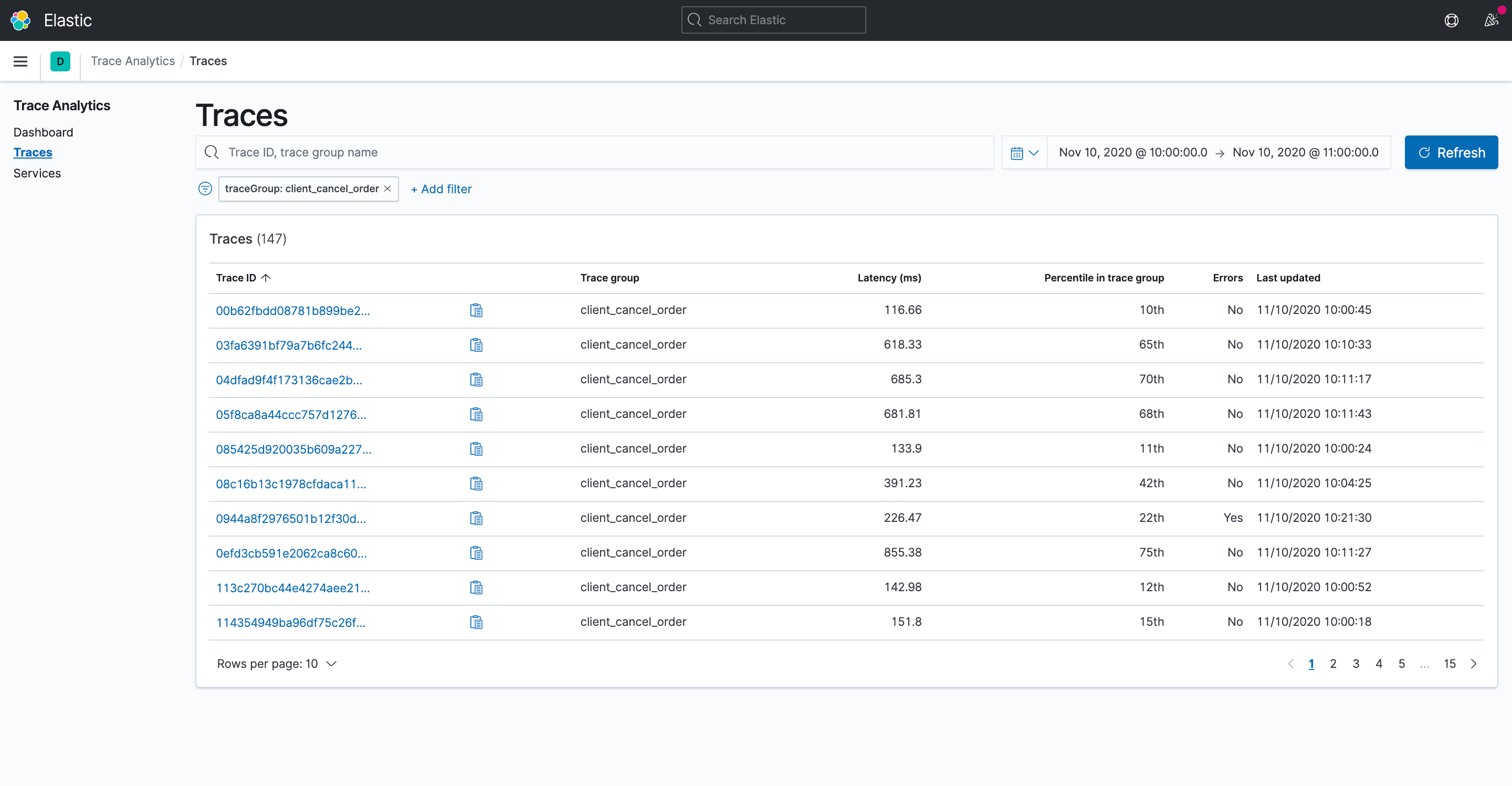
选择跟踪计数可以深入到跟踪选项卡,看到所有被选中的跟踪的列表。通过点击任何一列标题,如追踪ID和延迟,可以对该追踪列表进行排序。
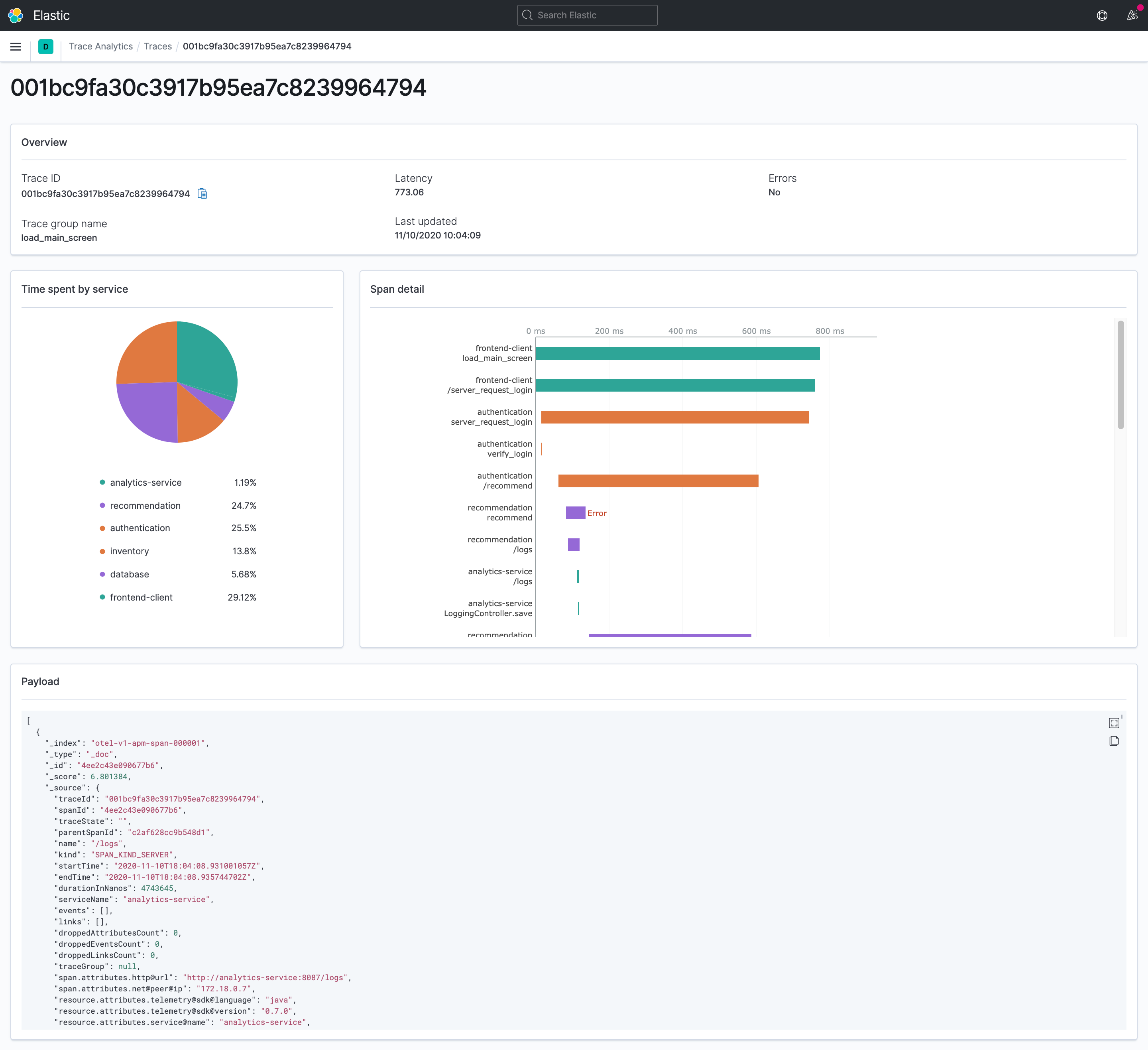
点击一个跟踪ID,你就可以钻进跟踪执行性能的详细视图。你可以看到一个服务性能视图和一个追踪的瀑布性能视图。
服务性能视图显示在跟踪执行路径中每个服务所花费的总时间。例如,对同一服务的多次调用所花费的时间被汇总,以总结在该服务中花费的总时间。
瀑布式性能视图按照执行顺序显示所有跟踪和跨度的性能细节。
服务选项卡有一个所有服务的表格视图,以及一个从所有跟踪数据的信息汇总而建立的相互连接的服务的网络图视图。在服务图视图中,你可以选择延迟、错误率和吞吐量的按钮,以查看每个服务在选定时间范围内的这些性能属性。
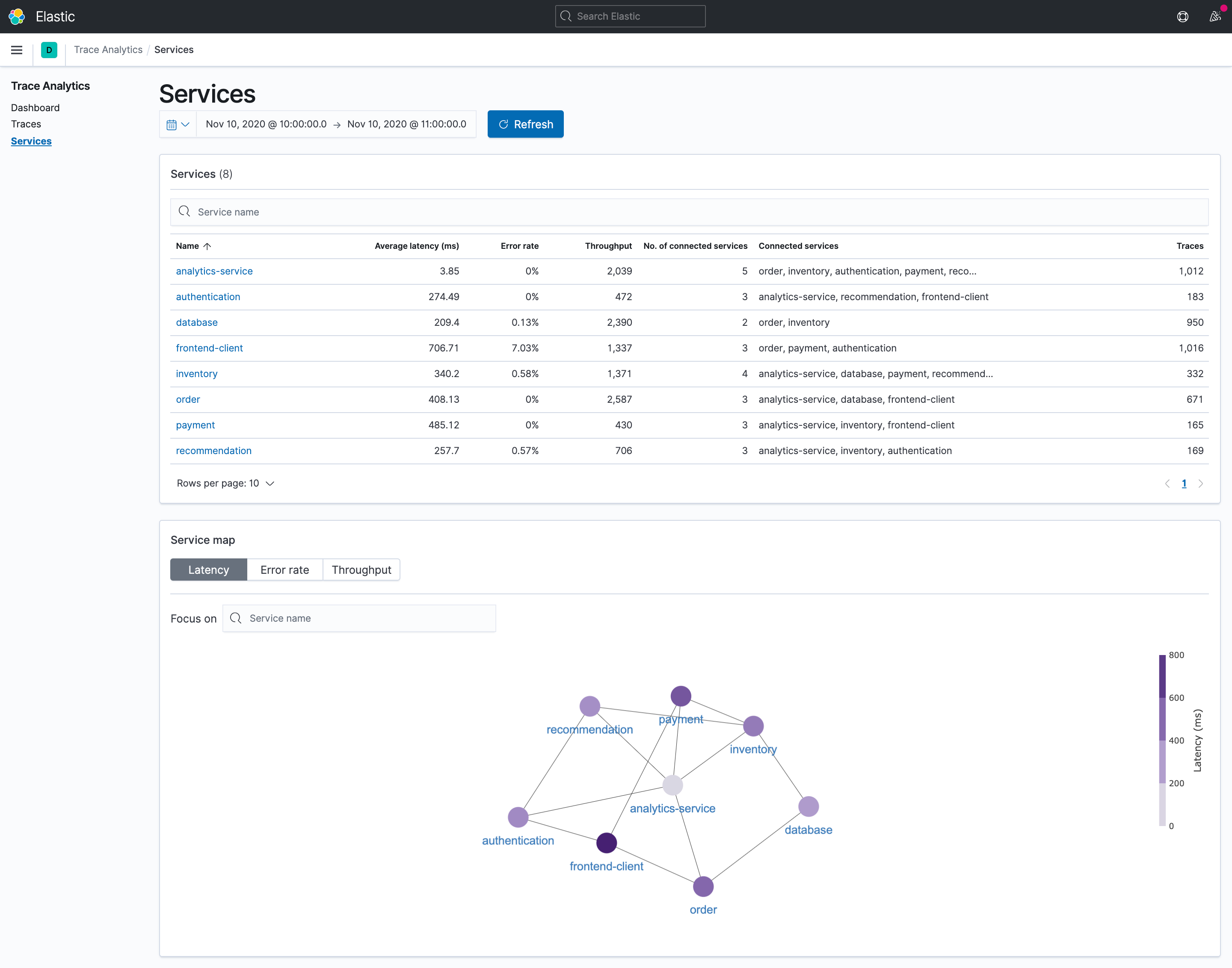
对于上面这个示例应用程序,我们看到Trace Analytics如何帮助识别作为Trace Group的关键事务执行路径,监测其性能以识别离群(如P95性能)跟踪实例,并深入这些实例以识别服务瓶颈。追踪标识符也可用于搜索服务节点上的日志事件,以找到根本原因。服务地图中的应用程序的端到端视图也有助于识别关键服务的上游和下游依赖关系,以进一步加速识别根本原因。
最后总结一下
在这篇文章中,我们介绍了Trace Analytics,并通过一个例子说明了如何使用OpenTelemetry SDK来发送跟踪数据到Open Distro for Elasticsearch。通过OpenTelemetry,开发者可以使用开源的OpenTelemetry API和SDK对他们的应用程序进行一次检测,并将跟踪数据发送到Open Distro for Elasticsearch或他们选择的任何监控后端。跟踪分析使开发人员和IT操作人员能够发现和修复分布式应用中的性能问题,从而加快问题的解决时间。
