链表最快的排序方法、Jupyter Notebook安装、Gremlin入门、python3 请求数据、John 易筋 ARTS 打卡 Week 25
1. Algorithm: 每周至少做一个 LeetCode 的算法题
笔者的文章:
题目
Given the head of a linked list, return the list after sorting it in ascending order.
Follow up: Can you sort the linked list in time and memory (i.e. constant space)?
Example 1:
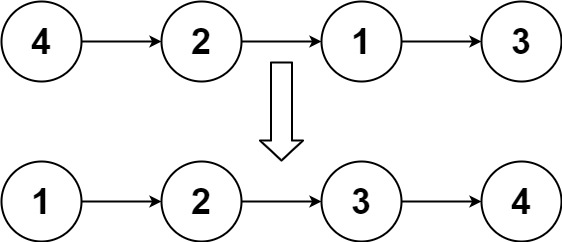
Input: head = [4,2,1,3]
Output: [1,2,3,4]Example 2:
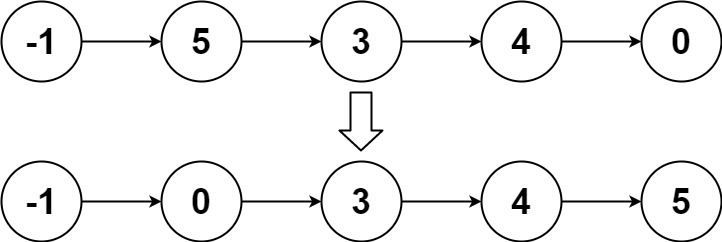
Input: head = [-1,5,3,4,0]
Output: [-1,0,3,4,5]Example 3:
Input: head = []
Output: []
Constraints:
The number of nodes in the list is in the range .
-105 <= Node.val <= 105解题思路
如果是数组,时间复杂度解法 比较多的选择,比如快速排序、分而治之再合并排序、堆排序等。但是在链表的世界里,只有分而治之的方法才是最快的。步骤如下:
这种接法有个弊端,因为是递归,也就是会有栈溢出的风险。可以加个计数器,如果深度大于10,000 则抛出异常处理。
# Definition for singly-linked list.
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
class SortList:
def sortList(self, head: ListNode) -> ListNode:
if head == None or head.next == None:
return head
mid = self.getMid(head)
left = self.sortList(head)
right = self.sortList(mid)
return self.merge(left, right)
def merge(self, left: ListNode, right: ListNode) -> ListNode:
result = ListNode()
dummy = result
while left and right:
if left.val < right.val:
dummy.next = left
left = left.next
else:
dummy.next = right
right = right.next
dummy = dummy.next
if left:
dummy.next = left
if right:
dummy.next = right
return result.next
def getMid(self, head: ListNode) -> ListNode:
oneStep = None
while head and head.next:
if oneStep == None:
oneStep = head
else:
oneStep = oneStep.next
head = head.next.next
oneStepNext = oneStep.next
oneStep.next = None
return oneStepNext
2. Review: 阅读并点评至少一篇英文技术文章
笔者博客:
说明
Gremlin是Apache TinkerPop的图形遍历语言。Gremlin是一个功能,数据流 语言,使用户能够简洁地表达复杂的遍历(或查询)的应用程序的性能曲线图。每个Gremlin遍历都由一系列(可能嵌套的)步骤组成。步骤对数据流执行原子操作。每一步都是map步骤(转换流中的对象),filter步骤(从流中移除对象)或sideEffect-step(计算有关流的统计信息)。Gremlin步骤库在这3个基本操作的基础上扩展,为用户提供了丰富的步骤集,用户可以编写这些步骤,以询问他们可能对Gremlin is Turing Complete数据有任何可能的疑问。
场景一
g.V().has("name","gremlin").
out("knows").
out("knows").
values("name")场景二
g.V().match(
as("a").out("knows").as("b"),
as("a").out("created").as("c"),
as("b").out("created").as("c"),
as("c").in("created").count().is(2)).
select("c").by("name")两个朋友创建的项目的名称是什么?
场景三
g.V().has("name","gremlin").
repeat(in("manages")).
until(has("title","ceo")).
path().by("name")场景四
g.V().has("name","gremlin").as("a").
out("created").in("created").
where(neq("a")).
groupCount().by("title")场景五
g.V().has("name","gremlin").
out("bought").aggregate("stash").
in("bought").out("bought").
where(not(within("stash"))).
groupCount().order(local).by(values,desc)场景六
g.V().hasLabel("person").
pageRank().
by("friendRank").
by(outE("knows")).
order().by("friendRank",desc).
limit(10)OLTP和OLAP遍历
Gremlin是根据“编写一次,随处运行”的哲学设计的。这意味着不仅所有启用TinkerPop的图形系统都可以执行Gremlin遍历,而且每个Gremlin遍历都可以评估为实时数据库查询或批处理分析查询。前者被称为在线事务处理Online transaction processing(OLTP),后者被称为在线分析过程Online analytical processing(OLAP)。Gremlin遍历机使这种通用性成为可能。这个基于图形的分布式虚拟机 了解如何协调多机图遍历的执行。而且,不仅执行可以是OLTP或OLAP,遍历的某些子集还可以执行OLTP,而其他子集则可以通过OLAP执行。好处是用户不需要学习数据库查询语言和特定于域的BigData分析语言(例如Spark DSL,MapReduce等)。Gremlin是构建基于图形的应用程序所需的全部,因为Gremlin遍历机将处理其余部分。

命令式和声明式遍历
Gremlin遍历可以用命令式(过程式),声明式(描述性)方式编写)方式,或同时包含命令式和声明式方面的混合方式。命令式Gremlin遍历告诉遍历者如何在遍历的每个步骤进行。例如,右边的命令式遍历首先在顶点处放置一个遍历器,表示Gremlin。然后,那个遍历者将自己分散到不是Gremlin自己的所有Gremlin合作者中。接下来,遍历者走到那些协作者的经理,最终被归类为经理姓名计数分布。这种遍历是必须的,因为它以一种明确的程序方式告诉遍历者“去这里然后去那里”。
g.V().has("name","gremlin").as("a").
out("created").in("created").
where(neq("a")).
in("manages").
groupCount().by("name")声明性Gremlin遍历不告诉遍历者执行行走的顺序,而是允许每个遍历者从一组(可能嵌套的)模式中选择要执行的模式。左侧的声明性遍历产生的结果与上面的命令性遍历相同。但是,声明性遍历具有一个附加的好处,即它不仅利用编译时查询计划程序(如命令遍历),而且还利用运行时查询计划程序根据每个模式的历史统计信息选择下一个要执行的遍历模式-支持那些倾向于减少/过滤最多数据的模式。
g.V().match(
as("a").has("name","gremlin"),
as("a").out("created").as("b"),
as("b").in("created").as("c"),
as("c").in("manages").as("d"),
where("a",neq("c"))).
select("d").
groupCount().by("name")用户可以选择任何方式编写遍历。但是,最终在遍历遍历时,并根据基础执行引擎(即OLTP图数据库或OLAP图处理器),将通过一组遍历策略来重写用户的遍历,这些策略将尽力确定最佳执行方式根据对图形数据访问成本以及底层数据系统的独特功能的理解(例如,从图形数据库的“名称”索引中获取Gremlin顶点)进行计划。Gremlin旨在为用户提供表达查询方式的灵活性,并为图形系统提供者提供灵活性,以针对支持TinkerPop的数据系统有效地评估遍历。
宿主语言嵌入
经典的数据库查询语言(例如SQL)被认为与最终在生产环境中使用它们的编程语言根本不同。因此,经典数据库要求开发人员以其本机编程语言以及数据库的相应查询语言进行编码。可以说“查询语言”和“编程语言”之间的差异不如我们所教。Gremlin统一了这种鸿沟,因为遍历可以使用任何支持函数组合和嵌套的编程语言编写(每种主要编程语言都支持)。这样,用户的Gremlin遍历将与应用程序代码一起编写,并受益于宿主语言及其工具(例如,类型检查,语法突出显示,点完成等)提供的优势。存在各种Gremlin语言变体,包括:Gremlin-Java,Gremlin-Groovy,Gremlin-Python, Gremlin-Scala等。

下面的第一个示例显示了一个简单的Java类。请注意,Gremlin遍历以Gremlin-Java表示,因此是用户应用程序代码的一部分。开发人员无需String用(但)另一种语言创建查询的表示形式,以最终将其传递String给图形计算系统并返回结果集。而是将遍历嵌入到用户的主机编程语言中,并与所有其他应用程序代码同等地位。使用Gremlin,用户不必面对下面第二个示例中所示的尴尬情况,这是整个行业中常见的反模式。
public class GremlinTinkerPopExample {
public void run(String name, String property) {
Graph graph = GraphFactory.open(...);
GraphTraversalSource g = graph.traversal();
double avg = g.V().has("name",name).
out("knows").out("created").
values(property).mean().next();
System.out.println("Average rating: " + avg);
}
}
public class SqlJdbcExample {
public void run(String name, String property) {
Connection connection = DriverManager.getConnection(...)
Statement statement = connection.createStatement();
ResultSet result = statement.executeQuery(
"SELECT AVG(pr." + property + ") as AVERAGE FROM PERSONS p1" +
"INNER JOIN KNOWS k ON k.person1 = p1.id " +
"INNER JOIN PERSONS p2 ON p2.id = k.person2 " +
"INNER JOIN CREATED c ON c.person = p2.id " +
"INNER JOIN PROJECTS pr ON pr.id = c.project " +
"WHERE p.name = '" + name + "');
System.out.println("Average rating: " + result.next().getDouble("AVERAGE")
}
}在幕后,Gremlin遍历将针对嵌入式图形数据库进行本地评估,通过网络将其序列化为远程图形数据库,或将其发送给OLAP处理器以进行集群范围的分布式执行。遍历源定义确定遍历在何处执行。一旦定义了遍历源,就可以类似于数据库连接的方式反复使用它。最终的效果是,用户“感觉”到他们的数据和遍历都位于应用程序中,并且可以通过其应用程序的本机编程语言进行访问。“查询语言/编程语言”划分由Gremlin桥接。
Graph graph = GraphFactory.open(...);
GraphTraversalSource g;
g = graph.traversal(); // local OLTP
g = traversal().withRemote(DriverRemoteConnection.using("localhost", 8182)) // remote
g = graph.traversal().withComputer(SparkGraphComputer.class); // distributed OLAP参考
https://tinkerpop.apache.org/gremlin.html
3. Tips: 学习至少一个技术技巧
笔者的文章:
说明
用Terminal,curl 获取请求, 如何转换为json获取的方式。
% curl -XPOST http://httpbin.org/post -H "Content-Type:application/json" -d '{"attribute":"value"}'
{
"args": {},
"data": "{\"attribute\":\"value\"}",
"files": {},
"form": {},
"headers": {
"Accept": "*/*",
"Content-Length": "21",
"Content-Type": "application/json",
"Host": "httpbin.org",
"User-Agent": "curl/7.71.1",
"X-Amzn-Trace-Id": "Root=1-5fa3c5b9-234bd20a68c850894926f9bf"
},
"json": {
"attribute": "value"
},
"origin": "58.251.16.218",
"url": "http://httpbin.org/post"
}
python 解决方案
python3 use curl to request data
先安装lib
$ python -m pip install urllib3import urllib3
import json
data = {'attribute': 'value'}
encoded_data = json.dumps(data).encode('utf-8')
r = http.request(
'POST',
'http://httpbin.org/post',
body=encoded_data,
headers={'Content-Type': 'application/json'}
)
json.loads(r.data.decode('utf-8'))['json']print result
{'attribute': 'value'}参考
https://urllib3.readthedocs.io/en/latest/user-guide.html
https://stackoverflow.com/questions/22366748/reading-json-files-from-curl-in-python/64694348#64694348
4. Share: 分享一篇有观点和思考的技术文章
笔者写的博客链接
Jupyter Notebook
2014年,Fernando Pérez宣布从IPython中衍生出一个名为Jupyter的项目。[2]IPython继续以Python shell和Jupyter内核的形式存在,而IPython Notebook和其他与语言无关的部分移到了Jupyter名下。[3][4]Jupyter是语言无关的,它的名称是对Jupyter支持的核心编程语言的引用,这些语言是Julia、Python和R,[5] 它支持几十种语言的执行环境(也就是内核),这些语言包括Julia、R、Haskell、Ruby,当然还有Python(通过IPython内核)。[6]
2015年,GitHub和Jupyter项目宣布Jupyter Notebook文件格式(.ipynb文件)在GitHub平台上可以原生渲染。
Jupyter Notebook(前身是IPython Notebook)是一个基于Web的交互式计算环境,用于创建Jupyter Notebook文档。Notebook一词可以通俗地引用许多不同的实体,主要是Jupyter Web应用程序、Jupyter Python Web服务器或Jupyter文档格式(取决于上下文)。Jupyter Notebook文档是一个JSON文档,遵循版本化模式,包含一个有序的输入/输出单元格列表,这些单元格可以包含代码、文本(使用Markdown语言)、数学、图表和富媒体,通常以“.ipynb”结尾扩展。
Jupyter Notebook文档可以通过Web界面中的“Download As”,通过nbconvert库或shell中的“jupyter nbconvert”命令行界面,转换为许多的开源标准输出格式(HTML、演示幻灯片、LaTeX、PDF、reStructuredText、Markdown、Python)。
为了简化Jupyter Notebook文档在Web上的可视化,nbconvert库是通过nbviewer 页面存档备份,存于互联网档案馆提供的一项服务,它可以获取任何公开可用的Notebook文档的URL,将其动态转换为HTML并显示给用户。
使用Anaconda 安装Jupyter Notebook

jupyter notebook
就会自动打开 网页:
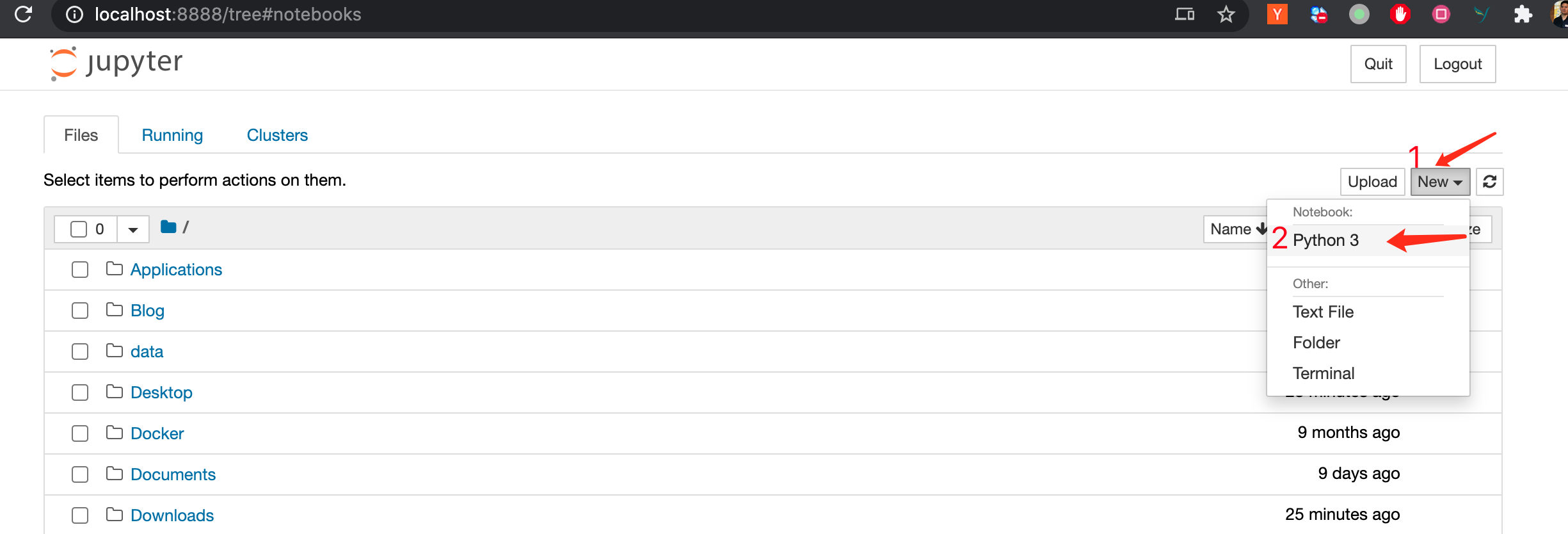
输入 , 运行 或者快捷键 , 即可输出结果。
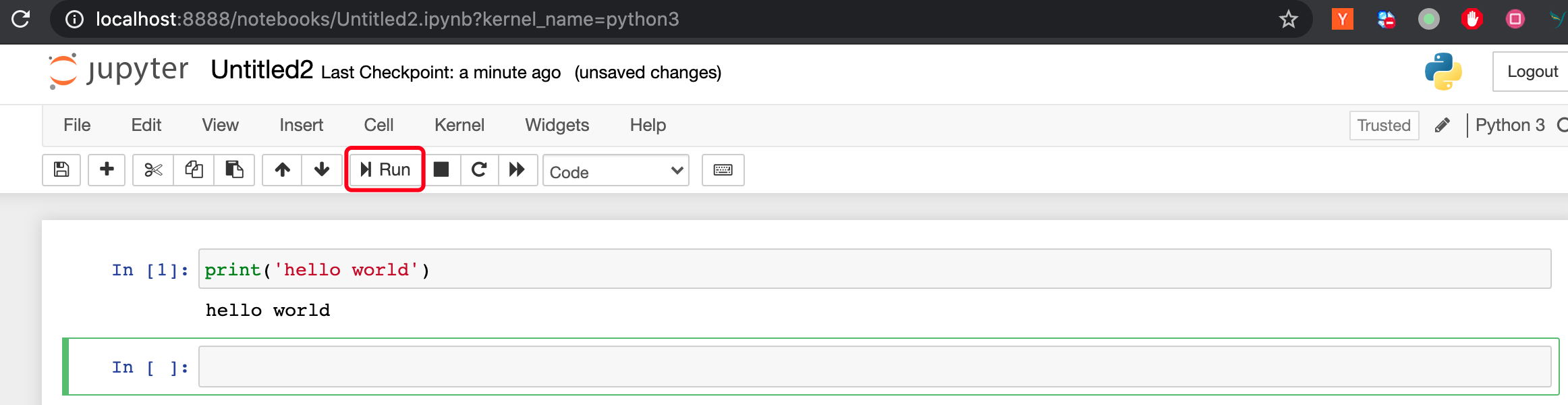
提醒关键词,可以用键
更多使用方法请参考 :
参考
https://zh.wikipedia.org/wiki/Jupyter
https://jupyter.readthedocs.io/en/latest/install/notebook-classic.html