MapReduce的Join操作
0. 问题
假设我们有如下的两张表:
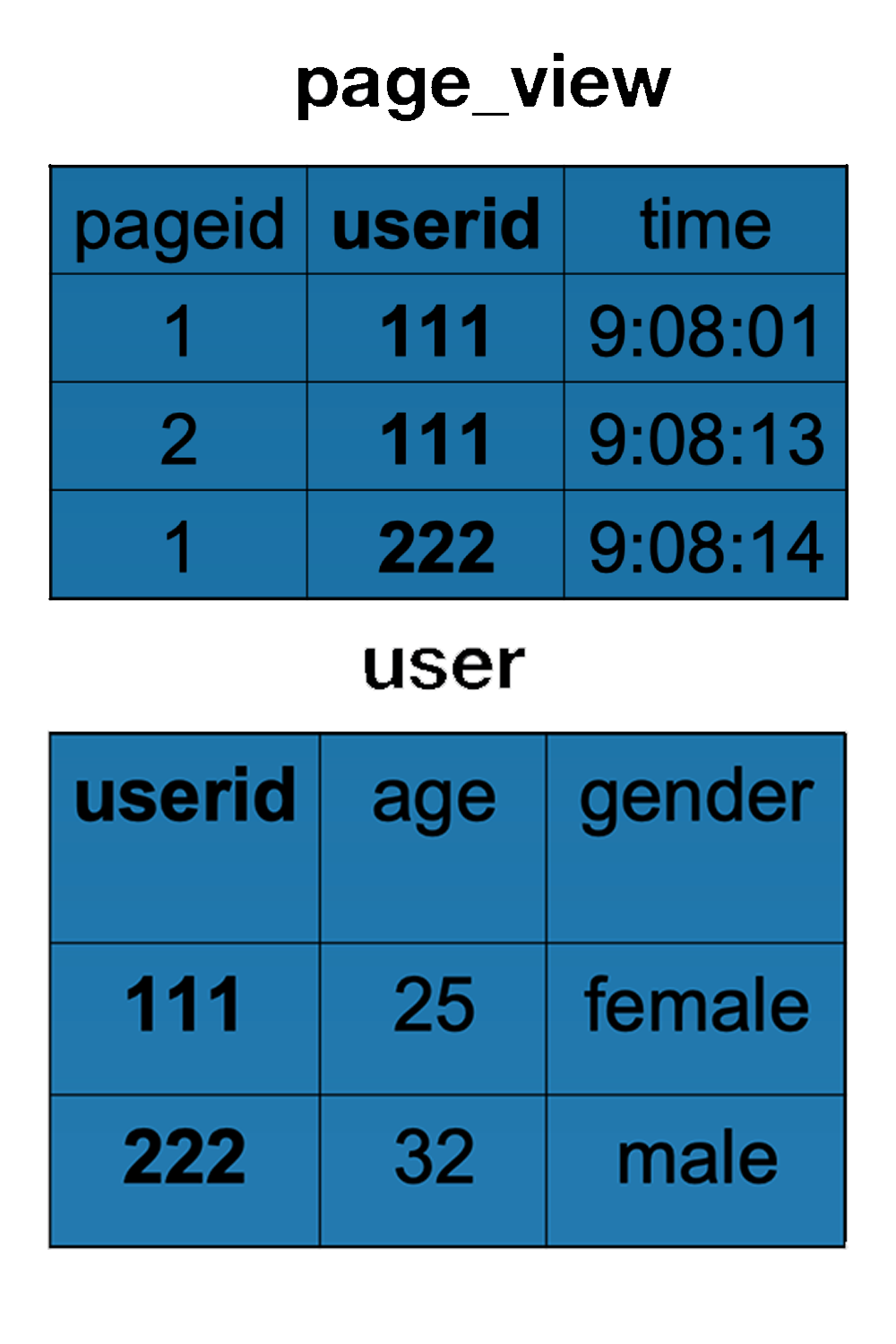
执行分析如下 HiveQL,生成的 MapReduce 执行程序,map 函数输入是什么?输出是什么,reduce 函数输入是什么?输出是什么?
INSERT OVERWRITE TABLE pv_users
SELECT pv.pageid, u.age
FROM page_view pv
JOIN user u
ON (pv.userid = u.userid);
1. 答案

map和reduce出入参示意图
map的输入
两张表对于map的输入都比较简单,key等于数据偏移量,我们并不关心。value等于表中每一行的数据,例如(1,111,9:08:01)或者(111,25,female)。
map的输出
我们通过解析value中将对数据进行加工,最后出来的结果为,key等于userid,value是一个组合值,由
reduce输入
将map输出的数据经过shuffle做排序和归并后作为reduce的输入,其中key为userid,value为相同userid的并集[
reduce输出
通过解析value,我们可分解出同一个userid中来自于page_view表中的pageid数据集合和user表中的age数据结合,例如userid为111的pageid集合[1,2]和age集合[25],将两个集合数据取笛卡尔乘积就可以获取到最终结果:例如[1,25],[2,25]。
1.1 划重点:
map过程需要将不同的表放入不同的value值中。
reduce过程需要为聚合好(同一个userid)的中做笛卡尔乘积(两次循环)
1.2 再优化:
shuffle是一个比较重的过程,针对两表Join这个操作,我们shuffle的原因是因为两张表的数据分布在不同的nameNode上,我们需要shuffle过程将相同userid数据聚合在一起汇聚为全量数据,然后在做笛卡尔积。
如果我们将两张表中任意一张表(通常是小表)数据存储于每一个nameNode的,这样在map操作是就可以直接进行笛卡尔积操作并数据结果的。这和我们分库分表之后使用元数据表解决多表Jion的思路类似,都是采用冗余数据的方式,从某种意义上说就是用空间换时间的方式。