实战中学习浏览器工作原理 — 之 HTTP 请求与解析
我是三钻,一个在《技术银河》中等你们一起来终生漂泊学习。
点赞是力量,关注是认可,评论是关爱!下期再见 👋!
前沿
浏览器工作原理是一块非常重要的内容,我们经常看到的 、 或者一些讲解CSS属性的时候,都会用到一些浏览器工作原理的知识来讲解。理论化学习浏览器工作原理,效果不是很大,而且很枯燥,所以这里我们从零开始用 来实现一个浏览器。
通过自己实现一遍简单的浏览器,我们会对浏览器的基本原理有更为深刻的理解。

浏览器基础渲染流程
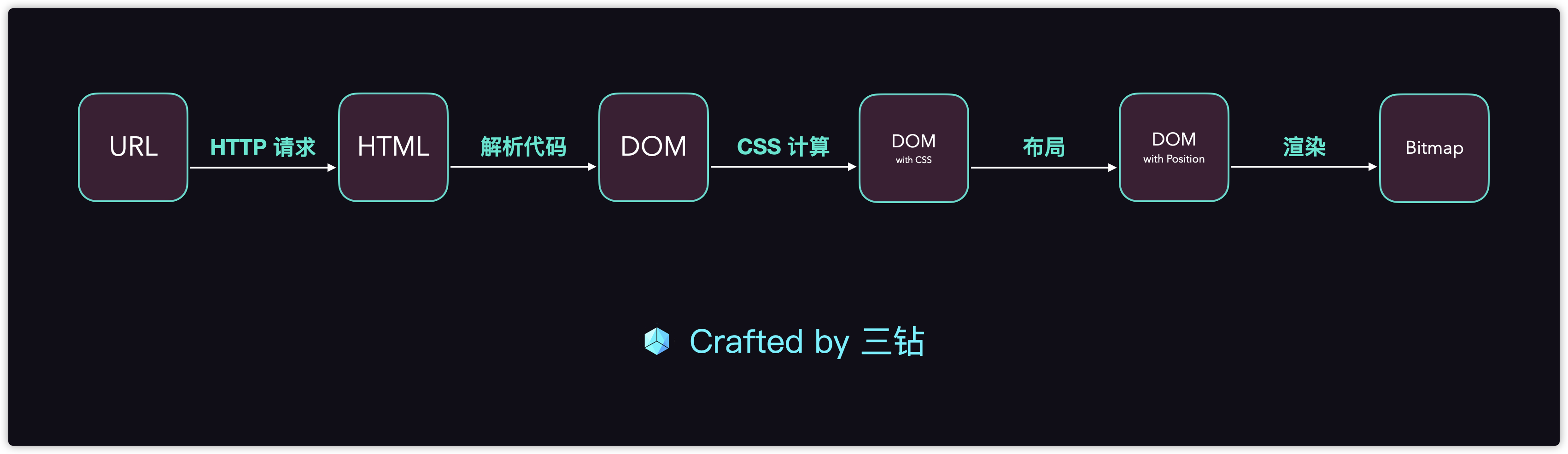
首先浏览器是由5个步骤完成的整体渲染
我们从URL访问一个网页,经过浏览器的解析和渲染后成为了Bitmap
最后通过我们的显卡驱动设配出去画面,让我们看到完成的页面
这是一个浏览器的渲染流程
这里我们只实现一个简单的基础流程,但是真正的浏览器还包含了很多功能,比如历史等等
我们主要需要完成的是从 URL 请求到 Bitmap 页面展示的整个流程就可以了。
浏览器流程:
有限状态机去处理字符串
因为这个处理字符串是整个的浏览器里面贯穿使用的技巧,如果不会用这个状态机,后面实现和读浏览器实现的代码会非常吃力。所以这里我们先讲讲什么是有限状态机。
每一个状态都是一个机器
每个机器都是互相解耦,强有力的抽象机制
在每一个机器里,我们可以做计算、存储、输出等
所有的这些机器接受的输入是一致的
状态机的每一个机器本身没有状态,如果我们用函数来表达的话,它应该是纯函数(无副作用)
无副作用指的是:不应该再受外部的输入控制,输入是可以的
每一个机器知道下一个状态
每一个机器都有确定的下一个状态(Moore)
每一个机器根据输入决定下一个状态(Mealy)
JavaScript 中如何实现
Mealy 状态机:
// 每个函数是一个状态
function state (input) { // 函数参数就是输入
// 在函数中,可以自由地编写代码,处理每个状态的逻辑
return next; // 返回值作为下一个状态
}
/** ========= 以下是调试 ========= */
while (input) {
// 获取输入
state = state(input); // 把状态机的返回值作为下一个状态
}以上代码我们看到,每一个函数是一个状态
然后函数的参数是输入
这个函数的返回值就是下一个状态,也就意味着下一个返回值一定得是一个状态函数
状态机理想的实现方式:一系列返回状态函数的一批状态函数
调用状态函数的时候,往往会用一个循环来获取输入,然后通过 ,来让状态机接收输入来完成状态切换
型状态机,返回值一定是根据 返回下一个状态
型状态机,返回值是与 没有任何关系,都是固定的状态返回
不使用状态机处理字符串
我们首先了解一下,在不使用状态机的情况下来实现一些字符串的处理方式:
第一问题:在一个字符串中,找到字符“a”
function match(string) {
for (let letter of string) {
if (letter == 'a') return true;
}
return false;
}
console.log(match('I am TriDiamond'));第二个问题:不准使用正则表达式,纯粹用 JavaScript 的逻辑实现:在一个字符串中,找到字符“ab”
「直接寻找 和 ,都找到时返回」
/**
* 直接寻找 `a` 和 `b`,都找到时返回
* @param {*} string 被匹配的字符
*/
function matchAB(string) {
let hasA = false;
for (let letter of string) {
if (letter == 'a') {
hasA = true;
} else if (hasA && letter == 'b') {
return true;
} else {
hasA = false;
}
}
return false;
}
console.log( matchAB('hello abert'));第三个问题:不准使用正则表达式,纯粹用 JavaScript 的逻辑实现:在一个字符串中,找到字符“abcdef”
方法一:「使用暂存空间,移动指针来检测」
/**
* 使用暂存空间,移动指针来检测
* @param {*} match 需要匹配的字符
* @param {*} string 被匹配的字符
*/
function matchString(match, string) {
const resultLetters = match.split(''); // 需要匹配的字符拆解成数组来记录
const stringArray = string.split(''); // 把被匹配的字符串内容也拆解成数组
let index = 0; // 匹配字符串的指针
for (let i = 0; i <= stringArray.length; i++) {
// 因为要保证字符的绝对匹配,如 “ab” 不能是 "abc",不能是 "a b"
// 所以这里需要两个字符必须是有顺序的关系的
if (stringArray[i] == resultLetters[index]) {
// 如果找到一个字符是吻合的,就 index + 1 找下一个字符
index++;
} else {
// 如果下一个字符不吻合,就重置重新匹配
index = 0;
}
// 如果已经匹配完所有的字符了,直接可以返回 true
// 证明字符中含有需要寻找的字符
if (index > resultLetters.length - 1) return true;
}
return false;
}
console.log('方法1', matchString('abcdef', 'hello abert abcdef'));方法二:「使用 和匹配字符的长度来截取字符,看是否等于答案」
/**
* 通用字符串匹配 - 参考方法2(使用substring)
* @param {*} match 需要匹配的字符
* @param {*} string 被匹配的字符
*/
function matchWithSubstring(match, string) {
for (let i = 0; i < string.length - 1; i++) {
if (string.substring(i, i + match.length) === match) {
return true;
}
}
return false;
}
console.log('方法2', matchWithSubstring('abcdef', 'hello abert abcdef'));方法三:「逐个查找,直到找到最终结果」
/**
* 逐个查找,直到找到最终结果
* @param {*} string 被匹配的字符
*/
function match(string) {
let matchStatus = [false, false, false, false, false, false];
let matchLetters = ['a', 'b', 'c', 'd', 'e', 'f'];
let statusIndex = 0;
for (let letter of string) {
if (letter == matchLetters[0]) {
matchStatus[0] = true;
statusIndex++;
} else if (matchStatus[statusIndex - 1] && letter == matchLetters[statusIndex]) {
matchStatus[statusIndex] = true;
statusIndex++;
} else {
matchStatus = [false, false, false, false, false, false];
statusIndex = 0;
}
if (statusIndex > matchLetters.length - 1) return true;
}
return false;
}
console.log('方法3', match('hello abert abcdef'));使用状态机处理字符
这里我们使用状态机的方式来实现:在一个字符串中,找到字符“abcdef”
首先每一个状态都是状态函数
我们应该有一个开始状态和结束状态函数,分别问题 和
状态函数名字都代表当前状态的情况 就是已经匹配中 字符了,以此类推
每一个状态中的逻辑就是匹配下一个字符
如果匹配成功返回下一个状态函数
如果匹配失败返回开始状态
因为字符中最后一个是 字符,所以 成功后,可以直接返回 结束状态
这个结束状态,也被称为陷阱方法 (Trap),因为状态转变结束了,所以让状态一直停留在这里,知道循环结束
/**
* 状态机字符串匹配
* @param {*} string
*/
function match(string) {
let state = start;
for (let letter of string) {
state = state(letter); // 状态切换
}
return state === end; // 如果最后的状态函数是 `end` 即返回 true
}
function start(letter) {
if (letter === 'a') return matchedA;
return start;
}
function end(letter) {
return end;
}
function matchedA(letter) {
if (letter === 'b') return matchedB;
return start(letter);
}
function matchedB(letter) {
if (letter === 'c') return matchedC;
return start(letter);
}
function matchedC(letter) {
if (letter === 'd') return matchedD;
return start(letter);
}
function matchedD(letter) {
if (letter === 'e') return matchedE;
return start(letter);
}
function matchedE(letter) {
if (letter === 'f') return end(letter);
return start(letter);
}
console.log(match('I am abcdef'));问题升级:用状态机实现字符串“abcabx”的解析
这个问题与上面的区别在于"ab"有重复
所以我们分析的逻辑应该是:
第一次 “b” 后面是 "c",而第二次 “b” 后面就应该是 “x”
如果第二次的后面不是 “x” 的话就回到上一个判断状态函数
/**
* 状态机匹配字符串
* @param {*} string 被匹配的字符
*/
function match(string) {
let state = start;
for (let letter of string) {
state = state(letter);
}
return state === end;
}
function start(letter) {
if (letter === 'a') return matchedA;
return start;
}
function end(letter) {
return end;
}
function matchedA(letter) {
if (letter === 'b') return matchedB;
return start(letter);
}
function matchedB(letter) {
if (letter === 'c') return matchedC;
return start(letter);
}
function matchedC(letter) {
if (letter === 'a') return matchedA2;
return start(letter);
}
function matchedA2(letter) {
if (letter === 'b') return matchedB2;
return start(letter);
}
function matchedB2(letter) {
if (letter === 'x') return end;
return matchedB(letter);
}
console.log('result: ', match('abcabcabx'));HTTP 协议解析基础知识
ISO-OSI 七层网络模型
HTTP
组成:
应用
表示
会话
对应 node 的代码里,我们有熟悉的
TCP
组成:
传输
因为网页是需要可靠传输,所以我们只关心TCP
Internet
组成:
网络
有时候讲上网有两层意思
网页所在的应用层的协议(外网)—— 负责数据传输的是 Internet
公司内网,叫 Intranet
4G/5G/Wi-Fi
组成:
数据链路
物理层
为了完成对数据准确的传输
传输都是点对点的传输
必须有直接的连接才能进行传输
TCP与IP的基础知识
流
TCP层中传输数据的概念是 “流”
流是一种没有明显的分割单位
它只保证前后的顺序是正确的
端口
TCP 协议是被计算机里面的软件所使用的
每一个软件都会去从网卡去拿数据
端口决定哪一个数据分配给哪一个软件
对应 node.js 的话就是应用
包
TCP的传输概念就是一个一个的数据包
每一个数据包可大可小
这个取决于你整个的网络中间设备的传输能力
IP地址
IP根据地址去找到数据包应该从哪里到哪里
在 Internet 上的连接关系非常复杂,中间就会有一些大型的路由节点
当我们访问一个 IP 地址时,就会连接上我们的小区地址上,然后到电信的主干
如果是访问外国的话,就会再上到国际的主干地址上
这个IP地址是唯一的标识,连入 Internet 上的每一个设备
所以 IP 包,就是通过 IP 地址找到自己需要被传输到哪里
libnet/libpcap
IP 协议需要调用到 C++ 的这两个库
libnet 负责构造 IP 包并且发送
labpcap 负责从网卡抓取所有流经网卡的IP包
如果我们去用交换机而不是路由器去组网,我们用底层的 labpcap 包就能抓到很多本来不属于发给我们的IP包
HTTP
组成
Request 请求
Response 返回
相对于 TCP 这种全双工通道,就是可以发也可以收,没有优先关系
而 HTTP 特别的是必须得先由客户端发起一个 request
然后服务端回来一个 response
所以每一个 request 必定有一个对应的 response
如果 request 或者 response 多了都说明协议出错
HTTP请求 —— 服务端环境准备
在我们编写自己的浏览器之前,我们首先建立一个node.js服务端。
首先我们编写一个 的服务端:
const http = require('http');
http
.createServer((request, response) => {
let body = [];
request
.on('error', err => {
console.error(err);
})
.on('data', chunk => {
body.push(chunk.toString());
})
.on('end', () => {
body = Buffer.concat(body).toString();
console.log('body', body);
response.writeHead(200, { 'Content-Type': 'text/html' });
response.end(' Hello World\n');
});
})
.listen(8080);
console.log('server started');了解 HTTP Request 协议
在编写我们的客户端代码之前,我们需要先了解一下 HTTP 协议。
我们先来看看 HTTP 协议的 request 部分:
POST / HTTP/1.1
Host: 127.0.0.1
Content-Type: application/x-www-form-urlencoded
field1=aaa&code=x%3D1
HTTP 协议是一个文本型的协议,文本型的协议一般来说与二进制的协议是相对的,也意味着这个协议里面所有内容都是字符串,每一个字节都是字符串的一部分。
HTTP 协议的第一行叫做 ,包含了三个部分:
Method:例如 POST,GET 等
Path:默认就是 “/”
HTTP和HTTP版本:HTTP/1.1
然后接下来就是
Header的行数不固定
每一行都是以一个冒号分割了 格式
Headers是以空行进行结束
最后的一部分就是 部分:
这个部分的内容是以 来决定的
Content-Type 规定了什么格式,那么 body 就用什么格式来写
接下来我们就可以开始编写代码了!
实现 HTTP 请求
设计一个HTTP请求的类
content type 是一个必要的字段,要有默认值
body 是 KV 格式
不同的 content-type 影响 body 的格式
Request 类
class Request {
constructor(options) {
// 首先在 constructor 赋予需要使用的默认值
this.method = options.method || 'GET';
this.host = options.host;
this.port = options.port || 80;
this.path = options.path || '/';
this.body = options.body || {};
this.headers = options.headers || {};
if (!this.headers['Content-Type']) {
this.headers['Content-Type'] = 'application/x-www-form-urlencoded';
}
// 根据 Content-Type 转换 body 的格式
if (this.headers['Content-Type'] === 'application/json') {
this.bodyText = JSON.stringify(this.body);
} else if (this.headers['Content-Type'] === 'application/x-www-form-urlencoded') {
this.bodyText = Object.keys(this.body)
.map(key => `${key}=${encodeURIComponent(this.body[key])}`)
.join('&');
}
// 自动计算 body 内容长度,如果长度不对,就会是一个非法请求
this.headers['Content-Length'] = this.bodyText.length;
}
// 发送请求的方法,返回 Promise 对象
send() {
return new Promise((resolve, reject) => {
//......
});
}
}请求方法
/**
* 请求方法
*/
void (async function () {
let request = new Request({
method: 'POST',
host: '127.0.0.1',
port: '8080',
path: '/',
headers: {
['X-Foo2']: 'custom',
},
body: {
name: 'tridiamond',
},
});
let response = await request.end();
console.log(response);
})();Request 类中的 send 函数编写
Send 函数是一个 Promise 的形式
所以在 send 的过程中会逐步收到 response
最后把 response 构造好之后再让 Promise 得到 resolve
因为过程是逐步收到信息的,我们需要设计一个 ResponseParse
这样 Parse 可以通过逐步地去接收 response 的信息来构造 response 对象不同的部分
// 发送请求的方法,返回 Promise 对象
send() {
return new Promise((resolve, reject) => {
const parser = new ResponseParser();
resolve('');
});
}设计 ResponseParser
Receive 函数接收字符串
然后用状态机对逐个字符串进行处理
所以我们需要循环每个字符串,然后加入 函数来对每个字符进行处理
class ResponseParser {
constructor() {}
receive(string) {
for (let i = 0; i < string.length; i++) {
this.receiveChar(string.charAt(i));
}
}
receiveChar(char) {}
}了解 HTTP Response 协议
在接下来的部分,我们需要在代码中解析 HTTP Response 中的内容,所以我先来了解一下 HTTP Response 中的内容。
HTTP/1.1 200 OK
Content-Type: text/html
Date: Mon, 23 Dec 2019 06:46:19 GMT
Connection: keep-alive
Transfer-Encoding: chunked
26
Hello World0
首先第一行的 与 request line 相反
第一部分是 HTTP协议的版本:HTTP/1.1
第二部分是 HTTP 状态码:200 (在实现我们的浏览器,为了更加简单一点,我们可以把200以外的状态为出错)
第三部分是 HTTP 状态文本:OK
随后的部分就是 header 部分
HTML的 request 和 response 都是包含 header 的
它的格式跟 request 是完全一致的
最后是一个空行,用来分割 headers 和 body 内容的部分的
最后这里的就是 body 部分了
这里 body 的格式也是根据 Content-Type 来决定的
这里有一种比较典型的格式叫做 (是 Node 默认返回的一种格式)
Chunked body 是由一个十六进制的数字单独占一行
后面跟着内容部分
最后跟着一个十六进制的0,0之后就是整个 body 的结尾了
这个也是用来分割 body 的内容
实现发送请求
这里我们开始实战,通过实现 send 函数中的逻辑来真正发送请求到服务端。
设计支持已有的 connection 或者自己新增 connection
收到数据传给 parser
根据 parser 的状态 resolve Promise
通过以上思路,我们来实现代码:
// 发送请求的方法,返回 Promise 对象
send(connection) {
return new Promise((resolve, reject) => {
const parser = new ResponseParser();
// 先判断 connection 是否有传送过来
// 没有就根据,Host 和 port 来创建一个 TCP 连接
// `toString` 是把请求参数按照 HTTP Request 的格式组装
if (connection) {
connection.write(this.toString());
} else {
connection = net.createConnection(
{
host: this.host,
port: this.port,
},
() => {
connection.write(this.toString());
}
);
}
// 监听 connection 的 data
// 然后原封不动传给 parser
// 如果 parser 已经结束的话,我们就可以进行 resolve
// 最后断开连接
connection.on('data', data => {
console.log(data.toString());
parser.receive(data.toString());
if (parser.isFinished) {
resolve(parser.response);
connection.end();
}
});
// 监听 connection 的 error
// 如果请求出现错误,首先 reject 这个promise
// 然后断开连接,避免占着连接的情况
connection.on('error', err => {
reject(err);
connection.end();
});
});
}
/**
* 组装 HTTP Request 文本内容
*/
toString() {
return `${this.method} ${this.path} HTTP/1.1\r
${Object.keys(this.headers)
.map(key => `${key}: ${this.headers[key]}`)
.join('\r\n')}\r\r
${this.bodyText}`;
}实现 RequestParser 类
现在我们来具体实现 RequestParser类的代码。
Response 必须分段构造,所以我们要用一个 Response Parser 来 “装配”
ResponseParser 分段处理 Response Text,我们用状态机来分析文本结构
/**
* Response 解析器
*/
class ResponseParser {
constructor() {
this.state = this.waitingStatusLine;
this.statusLine = '';
this.headers = {};
this.headerName = '';
this.headerValue = '';
this.bodyParser = null;
}
receive(string) {
for (let i = 0; i < string.length; i++) {
this.state = this.state(string.charAt(i));
}
}
receiveEnd(char) {
return receiveEnd;
}
/**
* 等待状态行内容
* @param {*} char 文本
*/
waitingStatusLine(char) {
if (char === '\r') return this.waitingStatusLineEnd;
this.statusLine += char;
return this.waitingStatusLine;
}
/**
* 等待状态行结束
* @param {*} char 文本
*/
waitingStatusLineEnd(char) {
if (char === '\n') return this.waitingHeaderName;
return this.waitingStatusLineEnd;
}
/**
* 等待 Header 名
* @param {*} char 文本
*/
waitingHeaderName(char) {
if (char === ':') return this.waitingHeaderSpace;
if (char === '\r') return this.waitingHeaderBlockEnd;
this.headerName += char;
return this.waitingHeaderName;
}
/**
* 等待 Header 空格
* @param {*} char 文本
*/
waitingHeaderSpace(char) {
if (char === ' ') return this.waitingHeaderValue;
return this.waitingHeaderSpace;
}
/**
* 等待 Header 值
* @param {*} char 文本
*/
waitingHeaderValue(char) {
if (char === '\r') {
this.headers[this.headerName] = this.headerValue;
this.headerName = '';
this.headerValue = '';
return this.waitingHeaderLineEnd;
}
this.headerValue += char;
return this.waitingHeaderValue;
}
/**
* 等待 Header 行结束
* @param {*} char 文本
*/
waitingHeaderLineEnd(char) {
if (char === '\n') return this.waitingHeaderName;
return this.waitingHeaderLineEnd;
}
/**
* 等待 Header 内容结束
* @param {*} char 文本
*/
waitingHeaderBlockEnd(char) {
if (char === '\n') return this.waitingBody;
return this.waitingHeaderBlockEnd;
}
/**
* 等待 body 内容
* @param {*} char 文本
*/
waitingBody(char) {
console.log(char);
return this.waitingBody;
}
}实现 Body 内容解析器
最后我们来实现 Body 内容的解析逻辑。
Response 的 body 可能根据 Content-Type 有不同的结构,因此我们会采用子 Parser 的结构来解决问题
以 ChunkedBodyParser 为例,我们同样用状态机来处理 body 的格式
/**
* Response 解析器
*/
class ResponseParser {
constructor() {
this.state = this.waitingStatusLine;
this.statusLine = '';
this.headers = {};
this.headerName = '';
this.headerValue = '';
this.bodyParser = null;
}
get isFinished() {
return this.bodyParser && this.bodyParser.isFinished;
}
get response() {
this.statusLine.match(/HTTP\/1.1 ([0-9]+) ([\s\S]+)/);
return {
statusCode: RegExp.$1,
statusText: RegExp.$2,
headers: this.headers,
body: this.bodyParser.content.join(''),
};
}
receive(string) {
for (let i = 0; i < string.length; i++) {
this.state = this.state(string.charAt(i));
}
}
receiveEnd(char) {
return receiveEnd;
}
/**
* 等待状态行内容
* @param {*} char 文本
*/
waitingStatusLine(char) {
if (char === '\r') return this.waitingStatusLineEnd;
this.statusLine += char;
return this.waitingStatusLine;
}
/**
* 等待状态行结束
* @param {*} char 文本
*/
waitingStatusLineEnd(char) {
if (char === '\n') return this.waitingHeaderName;
return this.waitingStatusLineEnd;
}
/**
* 等待 Header 名
* @param {*} char 文本
*/
waitingHeaderName(char) {
if (char === ':') return this.waitingHeaderSpace;
if (char === '\r') {
if (this.headers['Transfer-Encoding'] === 'chunked') {
this.bodyParser = new ChunkedBodyParser();
}
return this.waitingHeaderBlockEnd;
}
this.headerName += char;
return this.waitingHeaderName;
}
/**
* 等待 Header 空格
* @param {*} char 文本
*/
waitingHeaderSpace(char) {
if (char === ' ') return this.waitingHeaderValue;
return this.waitingHeaderSpace;
}
/**
* 等待 Header 值
* @param {*} char 文本
*/
waitingHeaderValue(char) {
if (char === '\r') {
this.headers[this.headerName] = this.headerValue;
this.headerName = '';
this.headerValue = '';
return this.waitingHeaderLineEnd;
}
this.headerValue += char;
return this.waitingHeaderValue;
}
/**
* 等待 Header 行结束
* @param {*} char 文本
*/
waitingHeaderLineEnd(char) {
if (char === '\n') return this.waitingHeaderName;
return this.waitingHeaderLineEnd;
}
/**
* 等待 Header 内容结束
* @param {*} char 文本
*/
waitingHeaderBlockEnd(char) {
if (char === '\n') return this.waitingBody;
return this.waitingHeaderBlockEnd;
}
/**
* 等待 body 内容
* @param {*} char 文本
*/
waitingBody(char) {
this.bodyParser.receiveChar(char);
return this.waitingBody;
}
}
/**
* Chunked Body 解析器
*/
class ChunkedBodyParser {
constructor() {
this.state = this.waitingLength;
this.length = 0;
this.content = [];
this.isFinished = false;
}
receiveChar(char) {
this.state = this.state(char);
}
/**
* 等待 Body 长度
* @param {*} char 文本
*/
waitingLength(char) {
if (char === '\r') {
if (this.length === 0) this.isFinished = true;
return this.waitingLengthLineEnd;
} else {
// 转换十六进制长度
this.length *= 16;
this.length += parseInt(char, 16);
}
return this.waitingLength;
}
/**
* 等待 Body line 结束
* @param {*} char 文本
*/
waitingLengthLineEnd(char) {
if (char === '\n') return this.readingTrunk;
return this.waitingLengthLineEnd;
}
/**
* 读取 Trunk 内容
* @param {*} char 文本
*/
readingTrunk(char) {
this.content.push(char);
this.length--;
if (this.length === 0) return this.waitingNewLine;
return this.readingTrunk;
}
/**
* 等待新的一行
* @param {*} char 文本
*/
waitingNewLine(char) {
if (char === '\r') return this.waitingNewLineEnd;
return this.waitingNewLine;
}
/**
* 等待新的一行结束
* @param {*} char 文本
*/
waitingNewLineEnd(char) {
if (char === '\n') return this.waitingLength;
return this.waitingNewLineEnd;
}
}最后
这里我们就实现了浏览器的 HTTP Request 请求,HTTP Response 解析的过程的代码。
下一篇文我们来一起实现 HTTP 解析并且构建 DOM 树,然后进行 CSS 计算
