使用Spark Mllib进行数据分析
本节内容主要是数据采集到大数据平台之后,然后通过算法模型对数据进行分析,得到分析结果。在教学分析时,采用了多种数据模型及算法。机器学习阶段主要采用监督式学习中的随机森林算法及非监督式学习中的K-mean算法。
1.1.1 S-T教学分析法
S-T法是应用于在教学过程中及教学活动中产生的数据进行分析,包括定量分析和定性评价[9]。因为S-T法只有两个维度,使得在分析时变得相对容易,减少模糊性,提高客观性以及可靠性。S就是对学生的行为分析,T就是对教师的行为进行分析。
在具体的行为中,T行为包括听觉和视觉两方面,听觉主要是教师的讲话行为,视觉包括教师板书、演示等。在本系统中,这些行为的具体表现是:教师课程上传、提问、教学评价、课程反馈等。S行为就是除T行为外的所有行为,在本系统的具体表现是:课堂笔记、课程考试、作业、话题讨论等。
S-T法的数据收集
在系统中通过教师和学生的数据上传,互动等,以一定的时间间隔,采集相应的数据组成样本点,根据这些数据样本的行为类别,转化成对应的S或T,构成S-T时序列数据,即S-T数据。
收集S-T时,需要定时采样,采样的间隔前期设置为2小时。对于采样的数据,必须包含时刻和行为的类别。
绘制S-T图
横轴表示T,纵轴表示S,纵横轴的长度表示行为时间。原点处表示时间为零,即起始数据。每堂课设定45分钟,则学生与教师可绘制如图4-10所示的网格图:
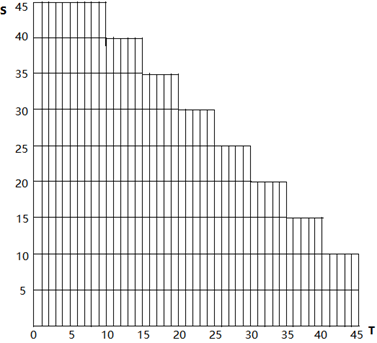
图4-10 S-T图
1.1.2 教学分析模型Rt和Ch
Rt和Ch模型是根据S-T教学分析法得到[10]。Rt表示T的行为占有率,在系统的表现为T所占的比例。
Rt=Nt/N
N:行为采样的总数。Nt:T的行为数量。
Ch表示行为转化率,即T行为与S行为之间的转化次数与总的行为采样数的比例。
Ch=(g-1)/N
g:连数,相同的行为的一个连续称为一个连数。
设采样数据的总数N为20,样本数据的顺序为:
S S T T T S S T S T S S T T T T S S T T
在总数N为20的情况下,样本序列如上所示时,Nt=11 ,则Rt=Nt/N=55%
在计算Ch时,需要计算出g,根据上述规则,g=10 , 则 Ch=(g-1)/N=45%
在一组Rt和Ch中,Rt和Ch相加始终为1,由此可得到它们的取值范围:
0≤Rt≤1,0≤Ch≤1
在这组模型中,两个模型的大小所表示的是:当Rt越大时,表示教师的活动越多,当Ch越大时,表示的是师生互动越多。
因此,可以将教学模式划分为5种:
讲授型:Rt的数值较大,Ch的数值较小(Rt≥0.6)
练习型:Rt的数值较小,Ch的数值较小(Rt≤0.2)
对话型:Rt的数值居中,Ch的数值较大(0.2≤Rt≤0.6,Ch≥0.6)
板书型:Rt的数值居中,Ch的数值较小(0.2≤Rt≤0.6,Ch≤0.3)
平衡型:Rt的数值居中,Ch的数值居中(0.3≤Rt/Ch≤0.6)
根据以上取值范围,可以得出Rt-Ch图4-11:
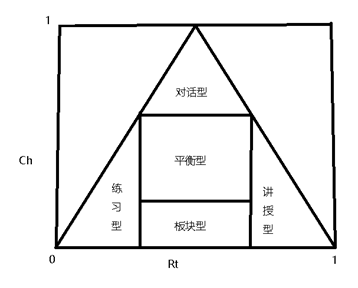
图 4-11 Rt-Ch图
依据图4-11可以做多方面的分析,对于不同的年级进行比较,对不同的教师进行比较,对某一位教师不同的时期进行比较。
1.1.3 TF-IDF
词频-逆向文件频率(TF-IDF)是一种在特征提取中非常重要的特征向量化的方法,他主要是用于文本挖掘中,可以体现出某个词语在一个文档或语料库中的重要程度[11]。在本系统中主要用于话题管理及笔记管理部分,生成知识点分布这一过程。
TF-IDF用于过滤文档中出现次数多但是含义并不重要的词,比如说在一篇文档中“的”、“我”、“这”等词语,在文档中出现次数非常多,但是它们并没有实际的意义,所以我们要过滤掉这些无意义的词。
TF表示的是一个词语在一篇文档中出现的频率,本系统中的话题管理部分,同学们会在此模块内进行课程讨论,系统首先会采集学生讨论的所有内容,然后发送到大数据平台,然后平台进行分词(使用Tokenizer类进行分词),而TF就是每个词语在整个文档中出现的频率。
TF=在某一类中词条w出现的次数/该类中所有词条出现的数目
IDF表示的是语料库中文档总数与词条w在语料库中出现的数目之比,IDF的目的就是过滤掉出现次数多但无意义的词语。
IDF=log(语料库中文档总数/(w在语料库中出现的数目+1)),分母加1的目的防止分母为零的情况。
TF-IDF=TF*IDF,也就是与一个词在文档中的出现次数成正比,与该词在整个语料库中的出现次数成反比,即在该类中出现次数较多但是在语料库中出现的次数较少的词证明是该类中比较重要有意义的词语。
TF-IDF在系统代码中的应用如下:
157 object TfIdf_1 {
158 def main(args: Array[String]): Unit = {
159 val spark: SparkSession = SparkSession.builder()
160 .appName("SparkMlilb")
161 .master("local[2]")
162 .getOrCreate()
163 spark.sparkContext.setLogLevel("WARN")
164 val sentenceData = spark.textFile("/usr/data/topic.txt")
165 .toDF("label", "sentence")
166 val tokenizer = new Tokenizer().setInputCol("sentence").setOutputCol("words")
167 val wordsData = tokenizer.transform(sentenceData)
168 val hashingTF = new HashingTF()
169 .setInputCol("words").setOutputCol("rawFeatures").setNumFeatures(20)
170 val featurizedData = hashingTF.transform(wordsData)
171 // alternatively, CountVectorizer can also be used to get term frequency vectors
172
173 val idf = new IDF().setInputCol("rawFeatures").setOutputCol("features")
174 val idfModel = idf.fit(featurizedData)
175 val rescaledData = idfModel.transform(featurizedData)
176 rescaledData.select("features", "label").take(3).foreach(println)
177 }
178 }
1.1.1 决策树算法构造教学模型
构建决策树包括三个步骤:
特征选择:选取的特征一定是能够有代表性的,根据前面分析的教学模型,选择用户的年龄、教授班级、Rt、Ch作为特征。
决策树生成:目前比较常用的算法有ID3和C4.5,因为特征个数不是太多,所以选择ID3作为决策树生成的算法。
决策树剪枝:主要作用防止模型的过拟合现象,在训练集中预测比较准确,但是在测试集中预测不准确,需要对决策树进行剪枝防止过拟合。
该教学模型因为特征较少,预测结果就五种,即上一小节提到的对话型、练习型、平衡型、板块型和讲授型。生成的决策树枝叶比较少,所以基本不会产生过拟合现象。当后期系统数据增多,可用的特征增多时,就需要考虑决策树生成算法是否需要使用C4.5,以及对决策树进行剪枝操作。
决策树算法详构建教学模型过程如下:
选定训练集,训练集
是输入实例,n为样本个数,X为类标记,i=1,2.....N;N为样本容量。该系统中构建决策树的目标是,根据给定的训练数据集(即业务系统中产生的数据)学习一个决策树算法的教学模型。
决策树是根据递归策略选择最优特征,将最优特征作为根节点,剩余所有的样本都位于根节点上。
决策树是监督式学习,样本集必须含有预测列的数据才能够使用决策树,此处数据使用2014石景山区教学设计大赛数据进行训练分析,如表4-2所示。
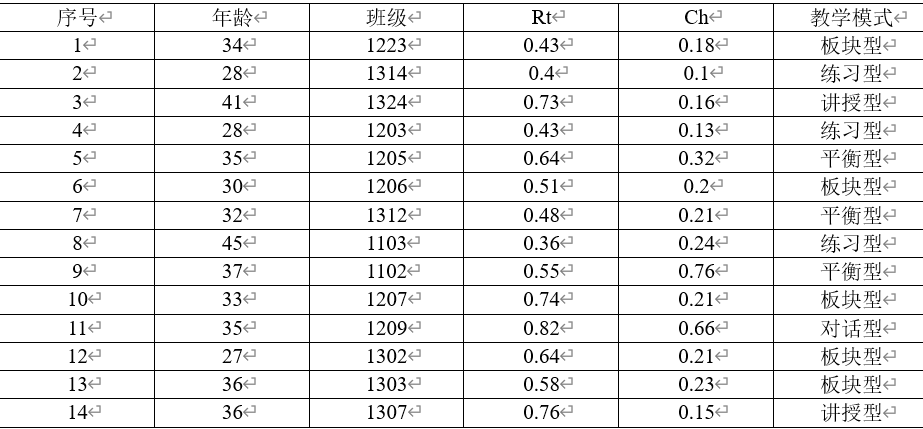
表4-2 教学设计大赛部分数据
根据上述数据,我们需要计算出根节点,需要用到“信息熵”的概念。香农在他的《信息论》中借用德国物理学家发明的“熵”的概念提出了“信息熵”的概念[12]。在物理学中“熵”通常是指物体能量的分布更加均匀,而香农首先定义了“信息”的概念:信息就是对不确定性的消除。因此,“信息熵”就表示事物不确定性的度量标准,可以根据数学中的概率计算,出现的概率越大,出现的机会就多,不确定性就小,即信息熵小。
根据数学中对数函数,可以得到一个不确定性函数公式:
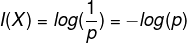
通过对单个取值的不确定性的期望E,就是作信息熵,即:
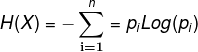
所以通过以上数据,构建出Rt的信息熵:
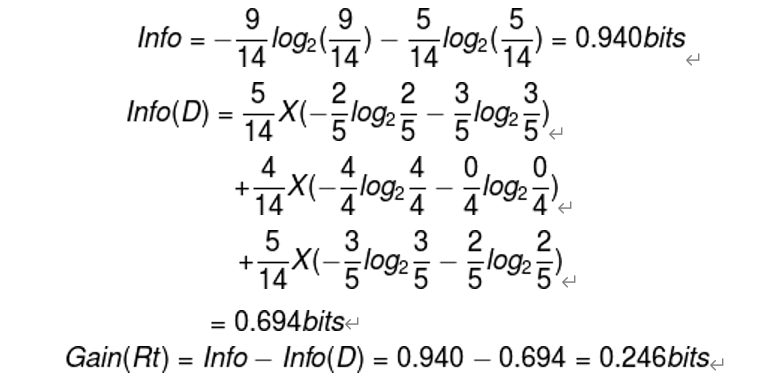
即Gain(Rt)=0.246。
类似的,Gain(age) =0.029, Gain(class) = 0.151, Gain(Ch)=0.148。
通过以上结论,Rt的基尼系数最大,即信息熵最大,所以选择Rt作为根节点。
构建教学模型在代码中的具体实现如下:
179 object TreeDemo {
180 def main(args: Array[String]) {
181 val conf = new SparkConf().setAppName("DecisionTree").setMaster("local")
182 val sc = new SparkContext(conf)
183 Logger.getRootLogger.setLevel(Level.WARN)
184 //训练数据
185 val data1 = sc.textFile("/usr/data/teacherMode1.txt")
186 //测试数据
187 val data2 = sc.textFile("/usr/data/teacherMode2.txt")
188 //转换成向量
189 val tree1 = data1.map { line =>
190 val parts = line.split(',')
191 LabeledPoint(parts(0).toDouble, Vectors.dense(parts(1).split(' ').map(_.toDouble)))
192 }
193 val tree2 = data2.map { line =>
194 val parts = line.split(',')
195 LabeledPoint(parts(0).toDouble, Vectors.dense(parts(1).split(' ').map(_.toDouble)))
196 }
197 //赋值
198 val (trainingData, testData) = (tree1, tree2)
199 //分类
200 val numClasses = 2
201 val categoricalFeaturesInfo = Map[Int, Int]()
202 val impurity = "gini"
203 //最大深度
204 val maxDepth = 5
205 //最大分支
206 val maxBins = 32
207 //模型训练
208 val model = DecisionTree.trainClassifier(trainingData, numClasses, categoricalFeaturesInfo,
209 impurity, maxDepth, maxBins)
210 //模型预测
211 val labelAndPreds = testData.map { point =>
212 val prediction = model.predict(point.features)
213 (point.label, prediction)
214 }
215 //测试值与真实值对比
216 val print_predict = labelAndPreds.take(15)
217 println("label" + "\t" + "prediction")
218 for (i <- 0 to print_predict.length - 1) {
219 println(print_predict(i)._1 + "\t" + print_predict(i)._2)
220 }
221 //树的错误率
222 val testErr = labelAndPreds.filter(r => r._1 != r._2).count.toDouble / testData.count()
223 println("Test Error = " + testErr)
224 //打印树的判断值
225 println("Learned classification tree model:\n" + model.toDebugString)
226 }
227 }
测试结果:
228 label prediction
229 0.0 0.0
230 1.0 1.0
231 1.0 1.0
232 1.0 1.0
233 3.0 3.0
234 2.0 2.0
235 2.0 2.0
236 1.0 1.0
237 4.0 4.0
238 0.0 0.0
239 Test Error = 0.0
240 Learned classification tree model:
通过结果可得真实值与预测值一致,Error为0
最终将结果保存到Hbase中,供可视化界面的展示使用。
1.1.1 K-Means算法构造知识图谱模型
在TF-IDF小节中已经对文档内容进行了分词以及词语的过滤操作,对这些词语使用K-Means算法进行聚类,K-Means算法属于非监督式学习,无标签类别类。K-几个聚类中心 Mean-均值,每次迭代的时候使用均值方式迭代。
详细构建过程如下:
(1)随机适当选择c个类的初始中心;
(2)在第k次迭代中,对任意一个样本,求其到c各中心的距离,将该样本归到距离最短的中心所在的类;
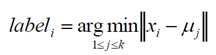
(3)利用均值等方法更新该类的中心值;
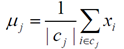
(4)对于所有的c个聚类中心,如果利用(2)(3)的迭代法更新后,聚类中心的值保持不变,则迭代结束,否则继续迭代。
终止条件:迭代次数/簇中心变化率/最小平方误差MSE。
因为算法模型计算的数据是向量,所以需要先对词语进行向量化,即Word2Vec,
word2vec是NLP领域的重要算法,它的功能是将word用K维的dense vector来表达,训练集是语料库,不含标点,以空格断句。
具体代码如下:
val spark: SparkSession = SparkSession.builder()
242 .appName("SparkMlilb")
243 .master("local[2]")
244 .getOrCreate()
245 spark.sparkContext.setLogLevel("WARN")
246 // 下面的数据为方便观察结果,使用的是测试数据,没有从文档中
247 // 导入词语,直接使用createDataFrame方法添加的词语
248 val documentDF = spark.createDataFrame(Seq(
249 "Hi I heard about Spark".split(" "),
250 "I wish Java could use case classes".split(" "),
251 "Logistic regression models are neat".split(" ")
252 ).map(Tuple1.apply)).toDF("text")
253
254 // 从单词到向量的映射
255 val word2Vec = new Word2Vec()
256 .setInputCol("text")
257 .setOutputCol("result")
258 .setVectorSize(3)
259 .setMinCount(0)
260 val model = word2Vec.fit(documentDF)
261 val result = model.transform(documentDF)
262 result.select("result").take(3).foreach(println)
结果:
263 [[0.03173386193811894,0.009443491697311401,0.024377789348363876]]
264 [[0.025682436302304268,0.0314303718706859,-0.01815584538105343]]
265 [[0.022586782276630402,-0.01601201295852661,0.05122732147574425]]
向量化之后使用K-Means算法对数据进行聚类。
K-Means算法在代码中的应用如下:
Val spark: SparkSession = SparkSession.builder().appName("SparkMLLibCarKMeansAnalysis").master("local[*]").getOrCreate()
267 spark.sparkContext.setLogLevel("WARN")
268 // * 2-准备数据
269 val datapath = "/usr/data/topicnote.txt"
270 val data1: DataFrame = spark.read.format("csv").option("header", "true").load(datapath)
271 data1.show(false)
272 data1.printSchema()
273 val data = data1.select(data1("sepal_length").cast("Double"),
274 data1("sepal_width").cast("Double"),
275 data1("petal_length").cast("Double"),
276 data1("petal_width").cast("Double"))
277 data.printSchema()
278 //sepal_length,sepal_width,petal_length,petal_width,class
279 // * 3-特征工程
280 //1-将经度和纬度数据整合为一起
281 val vectran: VectorAssembler = new VectorAssembler().setInputCols(Array("sepal_length", "sepal_width", "petal_length", "petal_width")).setOutputCol("features")
282 val datatrans1: DataFrame = vectran.transform(data
283 // 3-特征工程---最大值最小化的处理------[0,1[区间
284 val sclaer: MinMaxScaler = new MinMaxScaler().setInputCol("features").setOutputCol("scaledfeatures")
285 val scalerModel: MinMaxScalerModel = sclaer.fit(datatrans1)
286 val datatrans: DataFrame = scalerModel.transform(datatrans1)
287 val Array(trainset, testset): Array[Dataset[Row]] = datatrans.randomSplit(Array(0.8, 0.2), 123L)
288 // * K-Means建模
289 //loss很高
290 // val kmeans: KMeans = new KMeans().setFeaturesCol("features").setPredictionCol("predictions").setK(3)
291 //loss降低
292 val kmeans: KMeans = new KMeans().setFeaturesCol("scaledfeatures").setPredictionCol("predictions").setK(3)
293 val kmeanModel: KMeansModel = kmeans.fit(trainset)
294 // * 5-预测分析
295 val testResult: DataFrame = kmeanModel.transform(testset)
296 testResult.show()
297 testResult.groupBy("petal_length", "predictions").
298 agg(("predictions", "count")).show()
299 // * 6-模型校验分析-wssse打印结果 println("wssse", kmeanModel.computeCost(testResult)) //(wssse,2.5189564869286865)
300 println(kmeanModel.clusterCenters.mkString(","))
将得到的结果保存至Hbase中,供可视化界面查询使用。