如何快速对应用系统做一个360度画像诊断?
如何快速对应用系统做一个360度的画像诊断?
1. 为什么要诊断?
2. 诊断的策略是什么?
3. 如何快速地完成诊断?
一、为什么要诊断?
企业应用开发过程中,肯定会遇到以下问题:
a.进程消耗CPU飙升、内存利用率暴增,如何定位代码?
b.数据库连接数被耗尽怎么办?
c.各类OOM如何预防?
d.线程死锁、锁争用、上下文切换太频繁怎么办?
无论多复杂的系统运行在Linux之上,其实它就是一个进程。任何东西在操作系统层面,都是以文件的形式来存储的。进程也不例外,所以从操作系统的层面,只需要关注进程和线程即可。
例如:ll /proc/{pid}/ 展示此进程(pid)的文件目录,其中包含日志输出位置、系统加载哪些JAR包,以及还可以知道系统跟哪些外部应用在交互(ll /proc/{pid}/fd |grep socket),包括使用的哪些中间件服务,都可以从socket找到。
proc文件夹下包含所有的进程(Process)等信息。
二、诊断的策略是什么?
360度画像包括以下指标:
a. 资源瓶颈
b. 连接
c. TCP状态
d. 业务日志
e. OOM
f. JVM
g. CPU飙升
h. 线程状态

业务系统从性能上看,系统性就关注两件事:一个是吞吐量,一个是系统的响应性。
先谈谈CPU:
如果CPU的利用度不高,但是系统的吞吐量和响应性却不理想,这说明程序并没有忙于计算,可能问题出现在IO上。
再谈谈IO:
IO和CPU利用率一般是呈反比的,CPU利用率高,则IO不大;IO大,则CPU利用率就小。
关于IO,磁盘IO、驱动程序IO和内存换页率。
再检查网络带宽有没有问题。
如果CPU、IO和网络都看完了,并且CPU的利用率不高,IO也不高,内存也不高,网络带宽使用也不高,但是系统性能还是上不去。那么这个程序一定是被阻塞了,可能是CPU在等待哪个锁,也可能是某个资源,比如接口返回,连接在等待等,包括上下文的切换。
影响系统性能的瓶颈有:磁盘I/O、内存、CPU、网络I/O
(1) IO谁更快?
L1>L2>>L3>>>....>>>Memory>>>>>>>...>>>>>Disk
CPU IO 内存 磁盘
(2)网络IO
某些场景下,由于网络环境的不确定性,尤其是互联网上的数据读写,网络操作的速度可能比本地的IO要会更慢。
网络IO主要延时由: 服务器响应延时 + 带宽限制 + 网络延时 + 跳转路由延时 + 本地接收延时决定。(一般为几十到几千毫秒,受环境干扰极大)
(3)CPU
CPU资源的争夺,将导致性能问题,主要是锁竞争,锁竞争会导致上下文切换频繁,带来严重的系统开销,表现就是内核态的CPU的利用率偏高
(4)内存
最可能是内存不足,对JAVA来说,关注GC就好
(5)连接
系统对外部依赖的中间件和接口
比如数据库连接,如果数据量过大或者连接超时,都是比较消耗性能的。
(6)异常
JAVA异常的捕获和处理是非常消耗资源的,如果程序高频率的在异常处理,也会影响系统和性能。
三、如何快速地完成诊断?
(1) 资源诊断
CPU、IO、内存、磁盘、网络
方法:
##CPU问题定位
先用TOP 命令查看
其中load average 最近1, 5, 15分钟的系统的平均负载。
其中还有用户态的CPU和内核态的CPU使用占比等。
##再看看内存问题的定位,
pidstat -r -p {pid} 1 2 // 查看某个进程占用的物理内存和虚拟内存
pidstat -d -p {pid} 1 2 //查看某个进程IO使用情况
-r: 内存
-d: IO
-u: CPU
## IO问题定位
vmstat命令中swpd过高,通常是物理内存不够用了,swap的消耗主要关注它的IO。
##网络问题的定位
trace命令可以用来跟踪进程的执行和系统的调用
strace -T之间的参数可以显示具体的进程系统调用的情况
网络的IO也可以通过cat /proc/interrupts来查看,网络IO消耗需要关注、网卡中断,是否不均衡分配到各个CPU。JAVA的程序一般不会引起网络的IO消耗严重问题。
##磁盘问题的定位
dstat
(2) 连接诊断
应用往往还需要和外部的服务交互,比如数据库、缓存、消息中间件等
通过netstat查看,netstat -anop |grep 3306 查看mysql连接
(3) 线程异常
关注两点:线程状态、线程连接数。
应用设计的时候需要考虑资源的限制,才能避免在某些时候因为资源过度消耗而崩溃。
线程数的控制就非常重要,程序无限制创建,最终导致其不可控,特别是隐藏在代码中的创建线程的方法。
当系统的SY值过高时,表示Linux要花费更多的时间,来进行线程的切换。Java造成这种现象的主要原因是,创建的线程比较多,这些线程都处于不断的阻塞、锁等待、IO等待和执行状态的变化过程中,这就产生了大量的上下文切换。Java应用程序在创建线程时会操作JVM堆外的物理内存,太多的线程也会使用过多的物理内存。
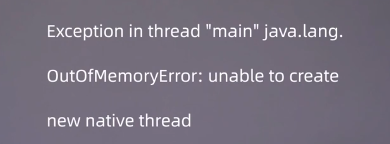
如上,线程数太多,导致内存不足,应用已无法在创建新线程。
那通过什么方法查看线程数呢?
cat /proc/{pid}/status
top -bH -d 3 -p {pid}
pstree -p {pid} | wc -l
pstack {pid} | head -l
JAVA线程状态主要包括以下几种:
Blocked (阻塞状态)
Waiting (无限时等待)
Time_Waiting (有限时等待)
New (初始化状态)
Runnable/Running (可运行 / 运行状态)
Terminated (终止状态)
其中我们最要关注的是Blocked、Waiting和Time_Waiting这三种状态,特别是Blocked状态,在获取不到CPU执行时间的时候,此时系统性能就会下降。
(4)CPU飙升诊断:分析定位程序CPU问题和查看线程状态的问题

(5)TCP状态诊断
重点关注CLOSE-WAIT 和TIME-WAIT状态,CLOSE-WAIT是被动关闭方,TIME-WAIT是主动关闭方。
如果客户端的并发量持续很高, 就会出现TIME-WAIT很高,有可能是客户端的连接连不上,可以用netstat查询定位。

(6) CPU过载
如何定位你的代码,是哪段导致CPU过载呢?
#步骤一:用top或者pidstat定位具体的进程号
#步骤二:top -p {pid} Shift+H 查看具体线程
#步骤三:将线程号(十进制)转化成十六进制 printf "%x\n" {pid} (线程栈中的线程程序号是以十六进制存储的)
#步骤四:jstack -l {pid } | grep -A 20 {16进制的线程程序号}
(7) OOM诊断
a.资源不足:可能内存分配过小
b.申请的资源太多:某一个对象被频繁申请,却没有被释放,内存不断泄露
c.资源耗尽:某一个资源被频繁申请,系统的资源在耗尽,例如不停的创建线程,不断的发起网络连接等
定位方法:
步骤一: 确认内存是否真的分配过小,jmap heap {pid}
步骤二:找到最耗费资源的对象,jmap -histo:live {pid} | more
步骤三:再确认你的资源是否耗尽,通过pstree和netstat来查看进程创建的线程数以及网络连接数等资源是否被耗尽
内存分析的最简单方式是通过内存的dump命令来导出内存栈
(jmap -dump:live,format=b,file=heap001 {pid}),不过会导致一次JVM的Full GC,导出的文件可通过MAT VisualVM来查看
(8)JVM GC问题
GC会导致系统应用的暂时停顿,如果频繁的GC,就会产生系统的延迟响应。
开启GC日志,可以方便观察定位,应用的停顿原因;也可以通过jstat来收集信息
jstat -gccause {pid} 1000
(9)日志诊断
检查日志的异常,Error等各种数据库异常等,前提是日志栈没被吃掉
比如说监控系统,awk命令来分析
#Reference
每日一课-360度的画像诊断