缓存数据的淘汰之路(中)
背景
数据又回来了,想起昨天被过期键经理上了一课,虽然心里很是难过,但是毕竟知道人外有人,原来为了控制我们数据,制定了这么野性的过期键策略,听说后面的关更难了,但是还是要闯关一下了,不是还有那句话嘛,
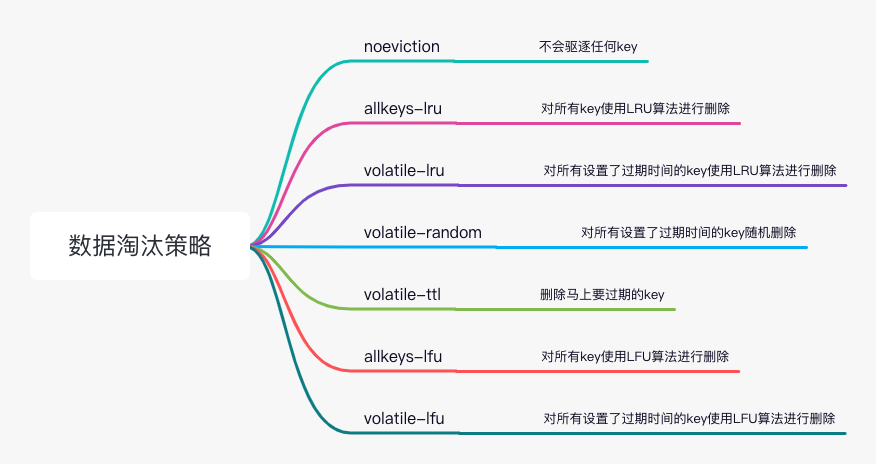
缓存淘汰策略
一路经过了过期键经理的送别,游荡在半路上,遇见了一个老头,说你是来自过期键经理的数据吧,数据连忙惊讶,哇靠,这老头连我从哪里来的都知道,莫不是;
是的,我就是那个老头,说完就哈哈大笑起来。
什么时候会遇见这个老头呢?
缓存淘汰策略触发的条件:
当前缓存空间临界最大memeory
当前需要业务改变,需要调整缓存策略
对于选中键值对,所有键值对做过滤时候
最直接的就是:比如就是当内存maxmemory不够用了,就会启用内存淘汰策略了;
老头手里有秘笈
专门治理缓存中的无量数据,
其中分为
维度
①
②
四个方面
LRU
LFU
RANDOM
TTL
其中两个缩写:
LRU: least recently used最近最少使用(Least Recently Used);最近最少使用算法LFU;
least frequently Used置换算法(Least Frequently Used)最近频率算法
LRU 和最小 TTL 算法不是精确算法而是近似算法
老头刚讲完自己的手段,数据就有问题了;
三大问题,就出现在数据脑海中
1.一般本地会用什么缓存淘汰策略呢?
2.如何修改缓存淘汰策略呢?
3.最近比较火缓存淘汰机制LRU思想是啥?
解析问题1:
1.一般本地会用什么缓存淘汰策略呢?
如果是自己本地已经下载了Redis,一般在配置文件conf中会找到,关于
解析问题2:
2.如何修改缓存淘汰策略呢?
两种方式,一种是命令,一种是conf的方式:
命令方式:
config set maxmemory-policy allkeys-lru
conf文件
# maxmemory-policy noevication 不会驱逐,会导致redis奔溃
maxmeory-policy allkeys-lru
解析问题3:
3.最近比较火缓存淘汰机制LRU思想是啥?
本质上
此算法会过滤出最近最久未使用的数据予以淘汰
实例场景:
手机的后台任务,一个任务多次使用,会默认提示他的加载能力,特别少使用的会放在最左侧,直到内存发生空间紧张,优先使用LRU;
此算法就是来源于力扣的算法, LRU的缓存机制;
LRU算法的思想:
所谓缓存: 是读和写的操作, 最好在O(1)状态机制下,完成读与写的过程
特性要求:
必须要有顺序之分,因为根据排序,留存的时间区分
读写操作一次搞定,符合O(1)的状态
如果缓存容量满了,删除不常用的数据,
每次访问要把最新的数据插入队头中去;
综上所述:
就是
其中哈希:查找链表:插入和删除快,还要有顺序,双向链表
三个问题有了答案之后,数据感觉顿时对老头,心里的敬畏之情谊,
这老头对于LRU底层,多个缓存淘汰策略的制定,很有见解,果然姜换是老的辣
数据今天的旅途很是受益
卢卡寄语
通过对数据经过过期键,到缓存淘汰策略,一次次是将数据过滤,减少内存的损耗,
其中LRU算法思想在于多个场景技术中都用到过,比如手机的多任务,就是简单的LRU来做的, 下期是卢卡带你手写LRU算法, 期待数据又更好的表现。
LRU算法
数据今天遇到一个大佬,人家都称之为缓存老头的得意门生LRU,数据在此之前早就听过它的大名,因为很多数据在过期之后,会让LRU大师兄去筛选出合适的数据,用来继续提供缓存服务,这里面就涉及了LRU大师兄的秘笈了
就是哈希链表,因为LRU大师兄,不仅查询数据get(),set()数据也特别快,关键是可以很好的排序效果;
根据这三点,数据结构的木匠就给它打造了这个关于 hash -->保持顺序链表,将数据链接起来,查询和插入;
用Java中的数据结构写出LRU算法
Java中对于链表有存在hash的,我们首先可以想到是hashmap,但是我们这次要使用一个他的子类,
public class LinkedHashMap extends HashMap implements Map
继承了HashMap的特性,查询快+插入快,底层是数组+红黑树
基于对于LinkedHashMap,我们可以看一下关于类的注释:
手写LRU算法步骤

import java.util.LinkedHashMap;
import java.util.Map;
/**
* @author lucas
* @create 2021-08-09 19:53
* @description LRU算法的基础实现
*/
public class LRUCacheDemo extends LinkedHashMap {
/**
* 1.确定初始容量
* 2.初始化构造器的,容量capacity
* 3.删除操作
*/
private int capacity; //最大容量
public LRUCacheDemo(int capacity) {
/**
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @param accessOrder the ordering mode - true for
* access-order, false for insertion-order 访问顺序
*/
super(capacity, 0.75F, false);
this.capacity = capacity;
}
// 默认的构造方法基于,负载因子和顺序
// public LRUCacheDemo(int initialCapacity, float loadFactor, boolean accessOrder, int capacity) {
// super(initialCapacity, loadFactor, accessOrder);
// this.capacity = capacity;
// }
//删除操作
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return super.size() > capacity;
}
public static void main(String[] args) {
LRUCacheDemo lruCacheDemo = new LRUCacheDemo(3);
lruCacheDemo.put(1, "a");
lruCacheDemo.put(2, "b");
lruCacheDemo.put(3, "c");
System.out.println(lruCacheDemo.keySet());
lruCacheDemo.put(4, "d");
System.out.println("增加第四个后,列表是"+lruCacheDemo.keySet());
/**
* [1, 2, 3]
* 增加第四个后,列表是[2, 3, 4]
* 解析: 当前第四个进来之后,4这个值将最近最少使用的直接踢出去
*/
System.out.println("--------------------------------------------");
lruCacheDemo.put(3, "d");
System.out.println(lruCacheDemo.keySet());
lruCacheDemo.put(3, "d");
System.out.println(lruCacheDemo.keySet());
lruCacheDemo.put(3, "d");
System.out.println(lruCacheDemo.keySet());
/***
* [2, 4, 3]
* [2, 4, 3]
* [2, 4, 3]
* 最近一直使用的,3的值最频繁,放在最右侧
*/
System.out.println("--------------------------------------------");
lruCacheDemo.put(5, "d");
System.out.println(lruCacheDemo.keySet());
/**
* [4, 3, 5]
* 5,进入之后,直接将最少使用的2挤出去
*/
/** 访问顺序(accessOrder)为ture
* [1, 2, 3]
* 增加第四个后,列表是[2, 3, 4]
* --------------------------------------------
* [2, 4, 3]
* [2, 4, 3]
* [2, 4, 3]
* --------------------------------------------
* [4, 3, 5]
*/
```js
/**访问顺序(accessOrder)为false
* [1, 2, 3]
* 增加第四个后,列表是[2, 3, 4]
* --------------------------------------------
* [2, 3, 4]
* [2, 3, 4]
* [2, 3, 4]
* --------------------------------------------
* [3, 4, 5]
*/
}
}
利用Java的集合,可以实现LRU的功能;
本质上: 如何在有限的容器中,转载多变的数据 ;
LRU: 最近访问最少的元素挑选出来
其中对于构造器中,需要注意的点,对于accessOrder-代表访问顺序
* 访问顺序accessOreder
* - true for access-order,
* -false for insertion-order
卢卡寄语
数据通过对于LRU中 LINKhashMap的实现, 是基于hash+双向链表的集合, 熟悉了LRU基本的工作机制,以及对于多个数据进入固定容器,如何筛选的过程,下期我们会根据数据的表现,提升一个段位,对于让你纯手写,不借助现成的集合方式,实现一个LRU的算法;你会如何写呢, 答案我们揭晓