限频/限流的一些思考
intro1 :限流的常见实现方式及常见开源限流组件有注意点
intro2 : 你真的理解了漏桶和令牌桶限流算法吗,划分/区分二者科学吗
intro3 : 你知道限流保障服务可用时也可能导致其他服务不可用吗
intro4 : 你知道目前参考springcloud的Redis限频实现的lua脚本都可能是有bug的吗
早先看到朋友圈分享限频限流的文章,从中有些收获,不过笔者不打算赘述,想进一步探讨下限频限流,以及限频限流使用时可能遇到的问题,同时也是对前一篇博文的回应,或许看完本文你会对Guava令牌桶算法有不一样的理解。
什么是服务限流限频?
先看 流量整形(traffic shaping)这个概念,wikipedia解释是一种控制网络数据包传输的技术,通过控制数据速率使数据较为均匀发送。流量整形可以一定程度减少网络拥塞,并减弱突发流量带来的影响。
对于像一个操作数据库的接口、甚至google查询、微信加好友等各种系统服务来说,也需要对请求进行频率控制,这类限频的思想就来自于流量整形,漏桶和令牌桶限流算法即是源自于流量整形衍生。
对服务的频控,具体到不同的实现大同小异,如
Guava doc对限频(RateLimiter)的理解是
限频显然关键的一点是频率,包括频率大小以及频率计算方式,但还有一点是针对谁限频,即限频的key,常见的如path(url)、ip、api、method、uid等各种维度,似乎没有文章讨论过这一点,但是重要的,下文会讨论。
其实考虑到流量整形,限频还有一点要考虑,就是对 均匀 的定义,现实请求是离散又连续均匀的,比如某类请求从每分钟维度统计是均匀的,但可能具体到每秒每0.1秒可能就不是,下文也会提及这点。
但不管如何划分,限频的本质是对一类周期性共享资源的使用。
限频的 Key 设计
不论何限频组件/算法,都要面临对限流限频资源即key的选择,key虽简单,但重要。
像静态的基于API/PATH/METHOD,或者动态uid/ip/cookie等,他们有什么不同呢?
笔者认为限频也可以按功能分为服务限频和业务限频,即针对Key的不同分为:
服务限频
业务限频
服务限频通常根据 接口名/url(request path)这类常量限制,业务限频则是动态的uid、ip、cookie值、甚至地区等,服务限频只能起到保证整体的后端服务可用,不能防止恶意用户刷频,比如某接口限频100次/分钟,用户A访问刷频了99次,那么其他所有用户该分钟內只能访问1次了,基于uid的业务限频可以避免该类问题,但业务限频不能进行服务限频保证后端服务。
此外,上述限频可以认为默认皆同步实现,假设有的需要业务之间调用并计算才能得到次数,比如用户当天下单优惠次数,比如用户某类接口成功次数,用户每分钟调用接口A和B加起来不能超过多少次,这些需要渗入业务结果,或者通过大数据业务计算出超频的用户,推送给接口限频,对这类限频需求,笔者定义为异步业务限频,当然这存在之后滞后的问题。
像Nginx/lstio/linkerd/springcloud都提供了服务限频,而springcloud默认通过配置也即可支持基于uid等业务限频,有些大公司实现的网关也是支持服务和业务(如用户唯一标识)的,如Dubbo的限频Tpslimiter就是仅对service key即接口类限频,而SpringCloud Alibaba 通过Sentinel则支持更丰富的服务/业务限频策略。
服务或业务限频,同步或异步计算各有优劣和不足,但直接公开的服务,如果没有业务限频而只有服务限频存在刷频风险。对于实现限频的方式来说,基于接口/path的服务限频,存在热点问题,基于uid级别限频则可能耗费存储,而且是限频的接口数X每秒(分钟)內活跃用户数的量级。
限频实现的几种技术
上述限频按功能分类,这里聊聊按实现算法分类。
信号量、计数器、固定窗口、滑动窗口、漏桶算法(Leaky Bucket)、令牌桶算法(Token Bucket)、分布式限流。
以下内容假设读者对此稍微了解。
实际上,更早一篇来自网关Kong的文章 ,也有此分类,Kong本身使用的是。
信号量主要用来控制并发数,本文不做讨论。
原文对滑动窗口描述简略,这里补充下:假设限频每分钟100次,一般滑动窗口是将1分钟分割多个单位时间,比如分割为10个窗口,即每6秒滑动一个窗口,统计时间范围也相应后移动。次数不需要每窗口均匀的,也可以多个滑动窗口,比如同时加一个每12秒也可,这样实现每6秒不超过x次每12秒不超过y次。
固定窗口/滑动窗口是一类好理解,但计数器和窗口也是一类,都是累计次数的做法(而令牌桶/漏桶归为桶限流),滑动窗口是更细粒度的计数器/固定窗口,如上分析也是可以支持突发流量,Hystrix停更后建议的替代者resilience4j 默认即是该做法:
代码略繁,AtomicRateLimiter类变量nanoTimeStart为初始化时间,在计算当前时间窗口时以此为起点(nanoTime() - nanoTimeStart),在acquirePermission时因为burst会有其他计算但基本以时间窗口内累计permits为准,这和下文要分析的令牌桶/漏桶异曲同工。
Hystrix可以有限的做过载保护削峰,基于信号量做线程隔离/控制并发数,没有真正的限频限流机制,故本文不再讨论 Hystrix()。
Dubbo的限频 DefaultTPSLimiter 可以自定义时间间隔(不考虑gc可以到1毫秒),即该时间间隔内不超过设置的次数,即其本质是计数法,而不是自称的漏桶,像lyft/ratelimit也是计数法基于redis分布式。
笔者记得曾听过淘宝系分享早期限频就是用 计数法 + guava map实现的LRU缓存。
不过滑动窗口计数的思想,非常适合流计算工具去计算频率,下面storm/kafka部分会提及。
Nginx和阿里的 Sentinel 都实现了漏桶算法,Springcloud Gateway和Guava Ratelimiter实现了令牌桶。
上述限频方式虽然有优劣,但更有各自的适用场景,比如要求每分钟不超过60次,可以不均匀,使用计数法是比较好的,而漏桶和令牌环都做不到恰好60,因为允许突发。
同时,限频限流也不只上述几个分类,我们甚至可以任意实现有别上述几类的限频方法,比如上述计数法的两个窗口都是基于时间的窗口(时间片),我们也可以基于请求的窗口,即维护一个队列,如每分钟限制100次,那么维护队列最长1000,当请求时判断是否超1000,如否放行并追加末尾,否则取头元素时间并判断是否超一分钟:1)如否,表示已满则拒绝该请求,2)否则,放行并删头追加末尾。该方案同计数法但可以无锁,只是耗内存。
分布式限流一般是计数/桶算法的分布式版本,故不提。
上面计数法显然默认不支持的流量整形,token支持流量整形,而leaky默认否,但下文分析其例外情况。
下面让我们重点看剩下的leaky和token算法
漏桶(Leaky Bucket)/令牌桶(Token Bucket)是否值得区分
看完上述分类,读者有想过自己真的了解上述分类吗?leaky和token真的有区别吗?
真实的流量
笔者认为上述分类是混乱的,区分leaky和token不是那么必要。
在讨论leaky和token时,大家会经常看到漏桶滴水的两张对比图,即两图实际用水流/水滴模型,。
限流通常是因为服务性能有限而要求,但也会被用来纯粹的限制次数需求(防ddos/防薅羊毛等),而限频使用何种处理方法则是因为真实的请求是离散而时间是一定程度上连续导致。我们先抛开水流,看下真实的请求需要怎么处理:
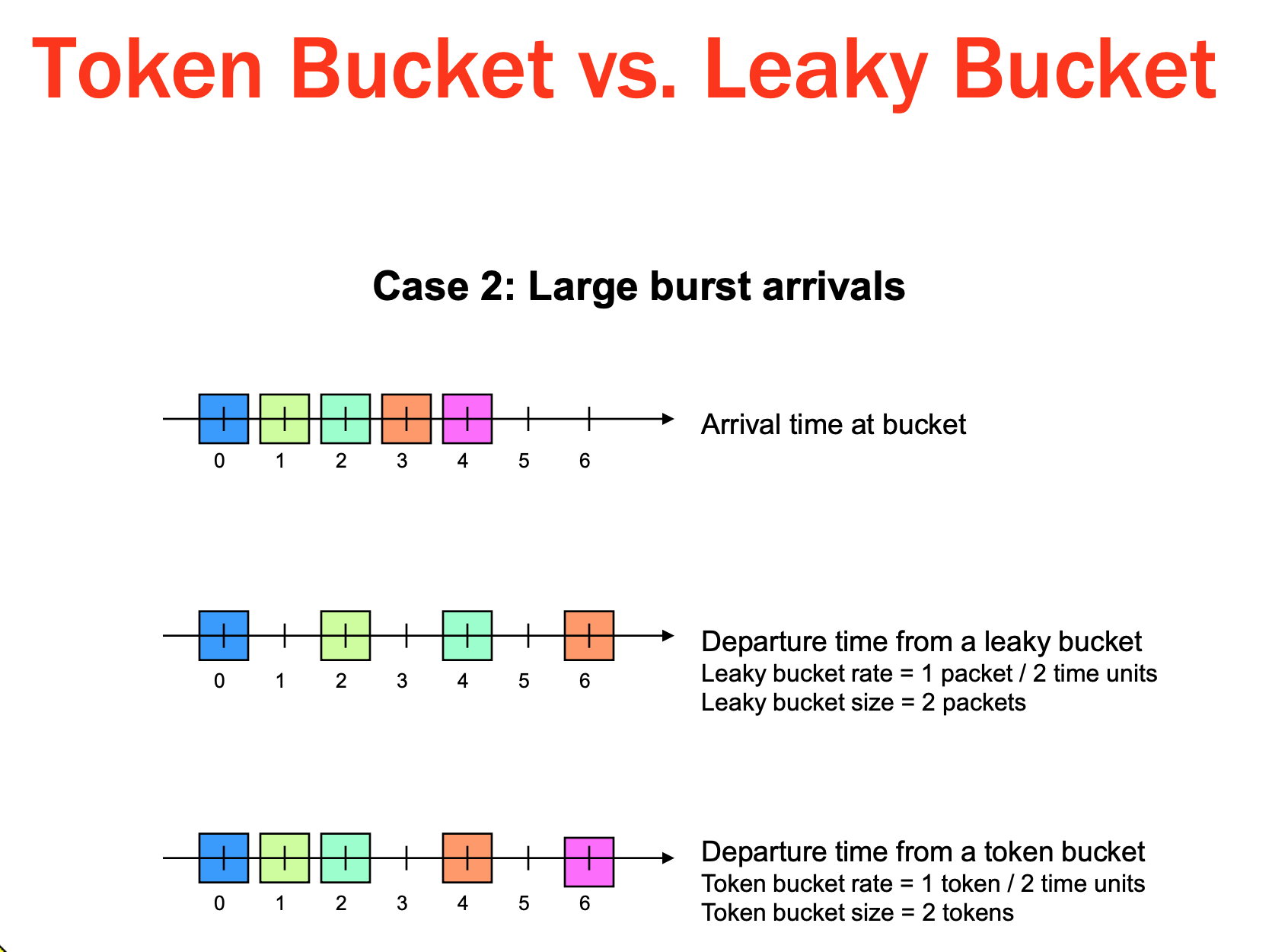
假设时间最小精度是1秒,需求是限制1分钟处理600个请求,如果不关心出现600个请求1秒处理完,那么使用基于1分钟的计数做法没有问题,这么做达到需求的限频目的,但是对服务限频而言没有,因为可能出现第59-60秒处理600个,甚至下一轮00-01秒也处理600个,即极端情况1秒处理1200个了,对服务来说不希望看到,当把计数的窗口缩小,即每6秒钟重置,也就是把60秒切分10份,每份不超过60(600/10)个请求,此时极端情况1秒处理120了…当划分越细到最小1秒,极端就是每秒20个,但此时存在1秒内不处理请求也就越明显此时划分就类似放token,但目前都是计数法,按窗口计数真正的请求。
真实请求不是均匀的,比如第2秒20请求过来,接下来3-60秒可能都没有数据,按计数法会拒掉10个,但考虑到后续空闲,拒掉是浪费,是否可缓冲到第3秒执行,即占用下时间片的额度?这里涉及历史状态,为简化,只记录上一次状态(时间或量),以及一个burst量,像guava限频就记录上次请求时间。
,对比常见水流模型二图,该图其实更易理解leaky/token的不同
Token Bucket
上述放入token的情景,换种思路,假设请求是均匀的,即把每个时间片等同于一个token,那么通过计算时间差就可以得到该周期内(秒/分钟…)已经发放的token,Token Bucket即是如此,通过控制发放(token)permit方式控制permit被消费速度(即限频),但一般不会用后台线程每 1/n 秒将 bucket 中的 token 数量加一,而是上述计算时间差,得到该时间差內增量token,加上次剩余的 token (二者不超过 bucket 容量限制),然后比较剩余token 数是否满足需要。
对于一个稳定的系统中,长期的平均顾客人数,等于长期的有效抵达率(λ),乘以顾客在这个系统中平均的等待时间(W),反过来,平均等待时间就是平均顾客数除以有效抵达率。
Guava限频/Sentinel就是基于token bucket算法,支持一定的burst,其中SmoothWarmingUp还支持平滑预热的burst,Guava Ratelimiter本质把限频转换成一种排队现象,每次请求返回的实际是下一轮请求需等待(permits)的时间。guava的burst支持即刻或者预热,即刻并不友好,而且burst量默认是一秒的,如果aquire的不是每次一个还是有害的,预热通过线性放量可以定量的缓解,当然如果你想指数级放量也未尝不可,对warmup机制感兴趣参考这篇
leaky/token是否值得区分
我们先看经典的Nginx限频限流怎么做的。
Nginx可以分别分为针对并发连接数和针对请求(QPS)进行,基于Nginx的扩展OpenRest的模块基于redis支持分布式支持leaky/token两种限频,不过这里和Nginx基于并发连接数(limit_req_conn)限频都不讨论,主要看Nginx基于QPS的限频limit_req_zone。
如下配置一个基于ip的限频,每秒20次:
http {
...
limit_req_zone $binary_remote_addr zone=allips:10m rate=20r/s;
server {
...
limit_req zone=allips burst=5 nodelay;
}
}Nginx自身有的请求限制模块,正如其描述Nginx基于leaky bucket限频。
题外话,Nginx限频缺点是:配置不适合动态修改,存储是单机内存,即不是跨机器共享分布式,内存占用大需要考虑(如上述基于ip 限频64 bit,1M最多能存储16000个,状态指的就是key,nginx有根据LRU优化,但毕竟可能数据不全)。其次,如果你有Nginx实现基于区域的限频,可以试试ip转区域的插件IP2Location Nginx Module。
注意上述“burst=5 nodelay”,表示处理突发请求不超过5个,如果不配置nodelay,那么请求会排队等到下一秒,配置nodelay表示可以立即执行(但不超过bust数),可以看到虽然基于Leaky,但是Nginx限频还是支持突发流量的。
,可以看到Nginx leaky也是把permit等同于时间片的,那么思考个问题:
在水流模型中流入和流出分别是什么?把permit等同于时间片,是否兼具流入和流出的角色?
如果读者认定Leaky不允许突发“Doesn’t allow bursty transmissions”,即
不过 确实是按照这点来区分的,分别实现了leaky/token算法,正如其备注的 “Leaky Bucket is implemented similarly to Token Bucket where OVER_LIMIT is returned when the bucket is full。”
Sentinel文档里作者认为Guava像leaky bucket,自己,而大部分中文提及Guava是token bucket,
需要指出的是Sentinel的RateLimiterController是leaky算法。
wikipedia的解释
维基百科对leaky与token的关系做了对比:
…
leaky算法分为as a queue和as a meter,as a queue可以堪称as a meter的特例(一个单位的延迟),不过原文确实提及as a queue不存在突发,防抖动,
as a meter的leaky和token算法本质同只是描述不同。
进一步理解限频
笔者觉得可以把限频限流分成两部分来看:
计频:该部分功能是计算qps,对计数类就是当前时间段內累积次数,对leaky/token是该周期内permits。
控频,或限频策略,即超频时触发何种操作。
控频分拒绝、等待、预热放行,或如Sentinel的策略 拒绝、Warm Up、匀速排队,nginx、guava、springcloud等部分支持。
这样上文提到的几个分类算法,可以认为是计频和控频实现方式的组合。
控频
介绍下几个组件对超频的处理:
Guava限频时,中aquire接口超频阻塞,而tryAquire接口则支持立即或超时后拒绝。
Sentinel支持阻塞、立即或超时后拒绝,具体DefaultController-默认处理策略,直接拒绝处理,RateLimiterController-匀速排队,WarmUpController-预热/冷启动方式,WarmUpRateLimiterController-预热+匀速排队,但Sentinel同时包含flowrule配置规则的处理。
而spring-cloud-gateway redis限频则直接拒绝,只不过会返回等待的时间tokensLeft。
Guava ratelimiter融合了令牌桶限频算法和超频处理的逻辑(了解这点,读guava代码就会更容易理解),如果你只是希望理解令牌桶限频,那么spring-cloud-gateway redis脚本就很简洁,而且目前只有setex操作,性能高,相比笔者曾见过的某司基于redis仿Guava限频算法包含hset/hget操作的脚本性能强多了。
但是,如springcloudgateway只能直接拒绝这类是起不到流量整形作用的,但流量整形直接暴露公网存在服务阻塞问题,下文会提及。
补充
1)需要指出的是,上文真实放Token的做法并非不可取,像guava实现令牌桶是线程安全的,每次aquire一个token都是synchronized的,而计数法的cas/或CLH锁等,不过在笔者老旧Mac上50-100线程內并发都是可以达到单机十万每秒吞吐,性能尚可。而真实放token的实现方式可能会更快,如使用Disruptor无锁方式,只是空间耗费了。
像Sentinel自述warmup几个限频类是参考Guava实现,但去掉了synchronnized,笔者没有完全阅读这块代码,不过无锁的几个方法应该是存在非线程安全导致限频计算错,但正如其doc提到,实现的是限频这种操作/趋势,对精确性要求不高。
2)如有的说法“令牌桶是你能承受突发流量,漏桶是你无法承受”这种说法其实是模糊的,我们服务限流大多是无法承受突发流量,但业务(如基于uid)限流是可以承受突发的-但这也是在假设用户是非恶意用户的情况下,我们可以根据服务/业务设置不同的leaky/token,但理解算法本身时,没必要区分。
3)笔者没有仔细阅读Sentinel源码,所以再简单探讨下Guava的SmoothWarmingUp和Sentinel的WarmupController的区别,不保证对。
Guava 在于控制获取令牌的速率,即获取permits的时间storedPermitsToWaitTime,通过storedPermits以及freshPermits的过程,推算出 nextFreeTicketMicros,即关注/返回的始终是下一次permits需等待的时间,这个nextFreeTicketMicros就是上文说的guava需要的上一次状态,只不过guava提前了,因为guava acquire放行的原则就是尽量提前。
而Sentinel目的在于控制QPS,而且主要是passQps,首先对于存在某些异常调用更准确些,其次,QPS是历史数据,比Guava只有上一次状态更能做到均衡,像WarmupController还用到了previousPassQps,看起来通过历史数据想实现更精准些,包括QPS影响token存储量,同时Token开始增长时间也受QPS影响,频率计算跨越太多的类,影响条件也多,绝不是其注释提到的公式那么简单。
总之,看下来,个人认为 WarmupController 通过 warningToken 比guava能更早更充裕时间的应对流量突发,而通过warningQps看起来能使该过程更平稳,个人认为对服务而言可能比SmoothWarmingUp更友好。
4)不仅上述几种,比如上述令牌桶被称为单桶单速,可以扩展单速双桶, 双速双桶等,单速双桶,顾名思义,比令牌桶多了一个桶,可以拿高速路汽车限流举例,红黄绿三灯划分两桶,就像流量被染色,绿桶全放行,黄桶等绿桶,分别用于处理量突发和速率突发的算法,笔者没有兴趣就不深入了。
总之我们需要具体情况具体分析,只有最合适没有普适且最优的。
限频限流注意事项
使用限频限流注意事项笔者不赘述,这里讨论两点:
补充下:
a)考虑到时间误差,是因为虽然可ntpdate等较时,但RTC时间存在误差,差0.1秒就能有10%误差,而有些廉价主机可能每天1+秒差。
b)其次收到反馈:
脚本在setex这个写入命令前使用了time命令,产生副作用,需要加 redis.replicate_commands() 。在3.2-4.x版本是需要加的,而且也可以如下避免频繁操作也会产生大量主从复制(对了,redis现在已经没有slave说法了)操作/流量:
redis.replicate_commands()
redis.set_repl(redis.REPL_NONE)需要再指出的是5.0之后不需要加了,实际上几年前antirez就此讨论过,而2018年后的Redis已经修改脚本复制为默认按,这里是代码改动 ,,在 里作者做了讨论,针对过去面临的一些问题和不足,认为自己考虑不周,Redis lua存在设计错误,认为应该只允许效果复制:
即,5.0之后,redis lua脚本已经默认支持一些副作用的命令后加set类写操作了,这点可能大多忽视了。
2)nginx/sentinel存在时间回退导致限频不准。
在通过时间差计算Token/permits时,像Guava ratelimiter 使用nanotime作为计时器而不是currentTimemillis,这是为了控制更精确吗?不是,纳秒是为了防止时间回拨,时间回拨时这段时间结果是不对的,所以你看到网上模拟token或leaky使用毫秒,实现都是可能出现该问题的。
同样Sentinel也存在并发的可能,不过如其所言,实现的是限频的趋势/效果,容许几次偏差。
3)热点数据
前文亦提过,这里补充下:
redis 单机set/get操作性能在十几万级别,antirez的。
热点数据容易带来尖刺,笔者在做某外卖公司的风控平台时曾对一个不大数据量的sortedset压测,削峰并不容易。
Gubernator就认为redis管道或lua脚本耗时操作,提出了本地cache存储限频数据的方案。
基于用户级别的限频,Sentinel比guava实现要耗内存,不过阅读Sentinel官方文档,笔者发现其提供了热点参数限流的功能,可以基于LRU策略统计最近访问频次高的uid,看起来似乎少量内存即可实现限流 top K的用户。
提供个信息:十万QPS对有些企业完全不够,几年前的微信摇一摇春晚红包已经是1400万次/秒的QPS级别,用户之间的红包是每秒钟收发40万,oceanbase在双十一期间也曾达6千万每秒操作。
4)限频可能会耗尽服务线程池,或者说,最小限频吞吐量可能成为你的整个系统吞吐量。
如果使用guava aquire()接口,而不是 tryAquire(),那么因为该接口有sleep操作,并且没有时间限制,当达到限频时你的线程就开始sleep了,如果请求不断的进来,那么可能线程大部分时间都在sleep了,而我们的服务如Dubbo/Tomcat/Jetty等容器都是共用请求线程池的,导致服务的其他接口请求可分配线程资源就少了,甚至没有。
想清楚这点并不难,如Tomcat,虽然请求httprequest会作为FIFO队列被线程池消费,只要有一个活跃的线程,总会拿到限频的请求,此时因超频sleep,整个容器无法服务。
可以试验看到,假设某接口使用guava的aquire限频1秒钟5次,假设burst 5,tomcat配置200线程,那么我只要以210次每秒请求该接口就能导致整个Tomcat 200个线程都在sleep约1秒,整个服务不能响应。
所以要用 tryAquire 接口,并且不设置最大等待时间,直接拒绝。
阿里的Sentinel中WarmUpRateLimiterController/RateLimiterController/RateLimiterController都有sleep阻塞,DefaultController默认是直接拒绝的,但是是Priorited的请求SphU.entryWithPriority()是阻塞的。
除非我们将这些限频的请求转入自定义的线程池,像netty我们可以直接把某类handler指定EventExecutorGroup,jetty/tomcat就麻烦些了,这属于长/短链接(请求)处理的问题,不展开探讨,当然纤程(Coroutine)可能也是一种解决方案。
说到netty异步,一句题外话,java社区曾热衷异步/响应式编程,笔者不久前看到jdbc异步(ADBA)的文章,不过异步实现是难的,oracle去年已经停掉了 ADBA项目,Spring Pivotal工程师则推出了响应式的 R2DBC, 本文并非比较此,但如社区讨论:
其他
最后,业务计频怎么做呢?
像Spark/KafkaStream/Flink/Storm等流计算工具,都提供了基于流的操作,比如读取应用到文件log、网络端口传输的数据、kafka等mq事件,对于流操作,不仅包含类似groupby/mapreduce这类操作,也支持time window概念,非常适合。
比如,Storm支持从时间或数量上来划分,通过窗口的长度/滑动间隔有不同的如,Sliding Window(滑动窗口)按照固定的时间间隔或者Tuple数量滑动窗口(重叠或间隔),也有Tumbling Window(滚动窗口),如实现统计60s内每10s的xxx。
同storm,kafka-stream也通过Timewindow和commit interval,二者组合起来实现滑动窗口(slice window),即每commit interval去上报统计该Timewindow 之内统计到的次数。
Spark-Streaming的reduceByKeyAndWindow算子也可以实现类似功能,只不过其对Time window的处理和kafka-stream不同,和storm同。Flink也有类似功能。
最后希望看完本文后 希望你除了知道”接口要加限流保障服务平稳运行“,还能进一步考虑下这么加限流是否可行/是否会影响其他服务不可用。