MySQL索引原理浅析
索引这个词,我想对于计算机相关专业的人再熟悉不过了,那么到底什么是索引呢?
百度百科定义如下:
索引是为了加速对表中数据行的检索而创建的一种分散的存储结构。索引是 针对表而建立的,它是由数据页面以外的索引页面组成的,每个索引页面中的行都会含有逻辑指针,以便加速检索物理数据。
这个定义其实是把索引完全当作数据库术语来阐述的,而在我看来,索引的应用在生活中无处不在,比如课本的目录、查字典、文件编码、图书馆图书编号等。
下面一段是从bing上搜索的对应数据库索引的定义:
A database index is a data structure that improves the speed of operations on a database table. Indexes can be created using one or more columns of a database table, providing the basis for both rapid random look ups and efficient access of ordered records.
介于以上对于索引的不同描述,我们可以得知,
为了更好的阐述MySQL索引数据结构,我们做如下约定:
下文只在InnoDB和MyISAM两种存储引擎上对索引数据结构进行分析。
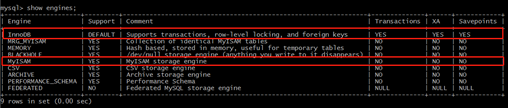
通过show engines;命令可以查看MySQL Server支持的存储引擎,如下图:(注:存储引擎本身的差异,不在本文讨论范围内)
分别基于InnoDB和MyISAM两种存储引擎创建两张表。
表结构如下图所示:(存储引擎是表级别的哦~)
-- innodb 表
DROP TABLE IF EXISTS `staff_innodb`;
CREATE TABLE `staff_innodb` (
`ID` bigint(20) NOT NULL,
`LAST_NAME` varchar(64),
`FIRST_NAME` varchar(64),
`AGE` smallint,
`HIRE_DATE` date,
PRIMARY KEY (`ID`)
) ENGINE = InnoDB;
-- 插入数据
INSERT INTO `staff_innodb`(`ID`, `LAST_NAME`, `FIRST_NAME`, `AGE`, `HIRE_DATE`) VALUES (1, 'wang', 'xiaoming', 27, '2020-01-01');
INSERT INTO `staff_innodb`(`ID`, `LAST_NAME`, `FIRST_NAME`, `AGE`, `HIRE_DATE`) VALUES (2, 'liu', 'xiaoqiang', 14, '2020-01-02');
INSERT INTO `staff_innodb`(`ID`, `LAST_NAME`, `FIRST_NAME`, `AGE`, `HIRE_DATE`) VALUES (3, 'zhou', 'xiaogang', 35, '2020-01-03');
INSERT INTO `staff_innodb`(`ID`, `LAST_NAME`, `FIRST_NAME`, `AGE`, `HIRE_DATE`) VALUES (4, 'wu', 'xiaoyu', 10, '2020-01-04');
INSERT INTO `staff_innodb`(`ID`, `LAST_NAME`, `FIRST_NAME`, `AGE`, `HIRE_DATE`) VALUES (5, 'hu', 'xiaobo', 19, '2020-01-05');
INSERT INTO `staff_innodb`(`ID`, `LAST_NAME`, `FIRST_NAME`, `AGE`, `HIRE_DATE`) VALUES (6, 'zhao', 'xiaowu', 31, '2020-01-06');
INSERT INTO `staff_innodb`(`ID`, `LAST_NAME`, `FIRST_NAME`, `AGE`, `HIRE_DATE`) VALUES (7, 'qian', 'xiaocheng', 42, '2020-01-07');
-- myisam 表
DROP TABLE IF EXISTS `staff_myisam`;
CREATE TABLE `staff_myisam` (
`ID` bigint(20) NOT NULL,
`LAST_NAME` varchar(64),
`FIRST_NAME` varchar(64),
`AGE` smallint,
`HIRE_DATE` date,
PRIMARY KEY (`ID`)
) ENGINE = MyISAM;
-- 插入数据
INSERT INTO `staff_myisam`(`ID`, `LAST_NAME`, `FIRST_NAME`, `AGE`, `HIRE_DATE`) VALUES (1, 'wang', 'xiaoming', 27, '2020-01-01');
INSERT INTO `staff_myisam`(`ID`, `LAST_NAME`, `FIRST_NAME`, `AGE`, `HIRE_DATE`) VALUES (2, 'liu', 'xiaoqiang', 14, '2020-01-02');
INSERT INTO `staff_myisam`(`ID`, `LAST_NAME`, `FIRST_NAME`, `AGE`, `HIRE_DATE`) VALUES (3, 'zhou', 'xiaogang', 35, '2020-01-03');
INSERT INTO `staff_myisam`(`ID`, `LAST_NAME`, `FIRST_NAME`, `AGE`, `HIRE_DATE`) VALUES (4, 'wu', 'xiaoyu', 10, '2020-01-04');
INSERT INTO `staff_myisam`(`ID`, `LAST_NAME`, `FIRST_NAME`, `AGE`, `HIRE_DATE`) VALUES (5, 'hu', 'xiaobo', 19, '2020-01-05');
INSERT INTO `staff_myisam`(`ID`, `LAST_NAME`, `FIRST_NAME`, `AGE`, `HIRE_DATE`) VALUES (6, 'zhao', 'xiaowu', 31, '2020-01-06');
INSERT INTO `staff_myisam`(`ID`, `LAST_NAME`, `FIRST_NAME`, `AGE`, `HIRE_DATE`) VALUES (7, 'qian', 'xiaocheng', 42, '2020-01-07');表创建后我们去看下数据文件如下图:
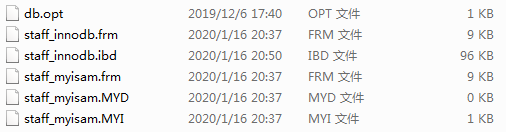
db.opt:用来记录该库的默认字符集编码和字符集排序规则用的,也就是说如果你创建数据库指定了默认字符集和排序规则,那么后续创建的表如果没有指定字符集和排序规则,那么该新建的表将采用该文件中指定的属性。
staff_innodb.frm:staff_innodb表相关的元数据信息
staff_innodb.ibd:staff_innodb表数据
staff_myisam.frm:staff_myisam表相关的元数据信息
staff_myisam.MYD:staff_myisam表数据
staff_myisam.MYI:staff_myisam表索引数据到这里有没有觉得奇怪呢?为什么myisam engine表对应三个文件,而innodb engine表对于只有两个文件?先不用急,等下文我们一起分析过索引的数据结构,到时候自然而然就明白其中的原理了。
那MySQL索引都用了哪些数据结构呢?官方文档是这样描述的:
Most MySQL indexes (, , and ) are stored in . Exceptions: Indexes on spatial data types use R-trees; tables also support ; uses inverted lists for indexes.
很明显MySQL大多数索引都是用了B-trees,那为什么MySQL索引选择了B-trees呢?要想搞明白这个,首先我们要理解常用的查找算法数据结构原理以及他们之间的区别。
二叉查找树(BST):二叉树是一种树的特殊形式,它的每个节点最多两个孩子节点,分别为左孩子和右孩子。而二叉查找树在此基础上,还有一个特点,就是每个节点比它左子树的节点值都要大,而比右子树的节点值都要小。
假设在上述示例表的AGE字段上建立二叉查找树,则得到如下:
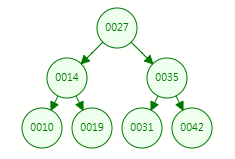
如果想查找AGE=42的数据,则从根节点开始查找,27->35->42,经过3次就可以查找成功,比顺序遍历所有数据进行查找速度快很多,这么看来好像BST也可以作为索引的数据结构,那么为什么没有用呢?下面我们再针对上述表结构中的ID字段构建二叉查找树(按照ID递增顺序),如下图所示:
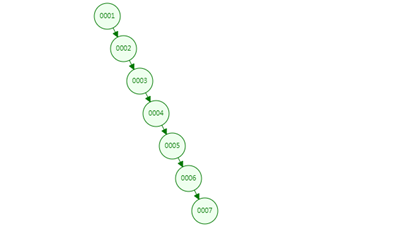
很糟糕,此时二叉树不再像二叉树,它失去了平衡,呈单边增长的态势,如果此时想查找ID=7的数据,则需要查找7次才能查找,查找效率从平衡状态的O(Log2n)退化到O(n)相当于顺序查找,效率非常低。那有没有一种数据结构能够解决二叉查找树的不平衡问题呢?下面我们来了解一下 (有兴趣的同学也可以去了解一下AVL Trees)
红黑树(Red-Black Trees):简单来说,是一种能够自平衡的二叉树(JDK1.8开始HashMap的底层就是使用红黑树实现的哦~),接下来我们用红黑树在ID字段上构建二叉树,得到如下图的结构:
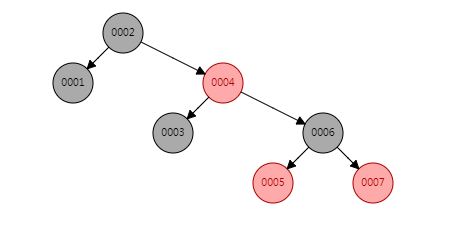
我们发现它不再是单边增长,它能够自动保持树的平衡状态。我们再次尝试查找ID=7的数据,从根节点开始查找,2->4->6->7,只需要4次查找就可以完成,效率比二叉查找树高很多,但是我们发现随着数据持续的增长下去,红黑树的深度也会不断的变大,查询效率也会逐渐降低。那有没有一种数据结构能够在控制查找次数的前提前实现快速查找呢?答案是B-Trees
B-Trees:是一种多路查找树(并不是二叉树),在构建B-Trees之前我们先了解一下B-Trees的几个重要特性:一棵m阶的B-Tree有如下特性:
1. 每个节点最多有m个孩子。
2. 除了根节点和叶子节点外,其它每个节点至少有Ceil(m/2)个孩子。
3. 若根节点不是叶子节点,则至少有2个孩子
4. 所有叶子节点都在同一层,且不包含其它关键字信息
5. 每个非终端节点包含n个关键字信息(P0,P1,…Pn, k1,…kn)
6. 关键字的个数n满足:ceil(m/2)-1 <= n <= m-1
7. ki(i=1,…n)为关键字,且关键字升序排序。
8. Pi(i=1,…n)为指向子树根节点的指针。P(i-1)指向的子树的所有节点关键字均小于ki,但都大于k(i-1)同样的,我们在ID字段上构建了如下图的B-Trees,很明细红黑树中遇到的问题已经不再存在。
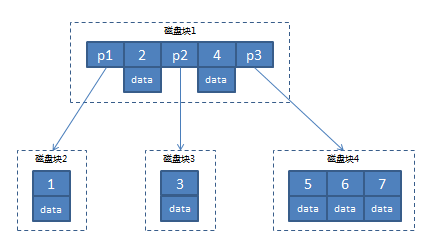
在进一步讲解上图之前我们先了解一下CPU从磁盘读取数据的相关知识,CPU从磁盘读取数据是以磁盘块(block)为基本单位的,位于同一磁盘块中的数据是一次性被读取出来的。
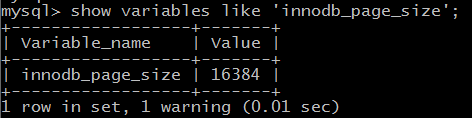
InnoDB存储引擎中有页(page)的概念,页是InnoDB存储引擎管理的最小单位,可以通过show variables like 'innodb_page_size';命令查看page size的大小,如下图(InnoDB的page size默认为16K);正常情况下系统的磁盘块是没有这么大的,因此InnoDB每次申请磁盘空间时都会是若干地址连续磁盘块来达到页的大小16KB。InnoDB在把磁盘数据读入到磁盘时会以页为基本单位,在查询数据时如果一个页中的每条数据都能有助于定位数据记录的位置,这将会减少磁盘I/O次数,提高查询效率。
在简单了解了CPU读取数据的方式以及InnoDB存储引擎中的page概念后,我们再来看B-Trees,假设每个节点占用一个磁盘块(block),我们再模拟查找ID=7的数据过程:
1. 根据根节点找到磁盘块1,读入内存。【第一次IO】
2. 比较key=7比key=4大,找到磁盘块1的指针P3。
3. 根据P3指针找到磁盘块4,读入内存。【第二次IO】
4. 在磁盘块4中的key=7的数据。整个过程经过两次IO,两次查找得到ID=7的数据;可能有人会提出疑问,从磁盘块4中的3个数据找到7,也要经过3次查找啊,这个问题我们上面已经提前强调了,一个磁盘块的数据是一次性被加载到内存的,内存中查找开销相比磁盘IO来说可以忽略不计,按照这个原理,我们是不是可以在每个节点里面尽可能的存储更多的数据,这样就可以进一步降低树的高度,提高查找效率呢?从B-Trees图中可以看出,每个节点不仅包含数据的key值,还包含了具体的data,每个page的存储空间是有限的,如果一条记录包含了几十个列甚至上百个列,这样会导致每个节点只能存储少量的key,进而会导致树的深度增大,查找时IO次数变道,导致最终的效率下降,B+Trees则针对此缺陷做了优化。
B+Trees:是在B-Trees的基础上优化而来,和B-Trees主要有以下几点不同:
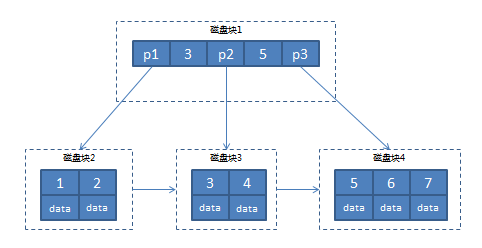
至此我们基本上可以理解MySQL为什么选择B+Tree作为索引实现的数据结构了,那MySQL具体是如何使用B+Trees实现索引的呢?
首先我们在示例的两张表中创建索引:
ALTER TABLE `staff_innodb` ADD INDEX `idx_inno_age`(`AGE`) USING BTREE;
ALTER TABLE `staff_myisam` ADD INDEX `idx_inno_age`(`AGE`) USING BTREE;staff_myisam表ID字段的primary index 和AGE字段的secondary index如下图所示:
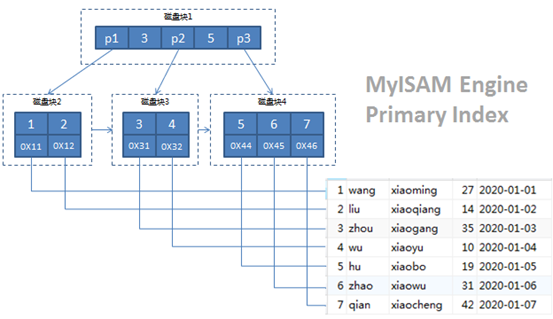
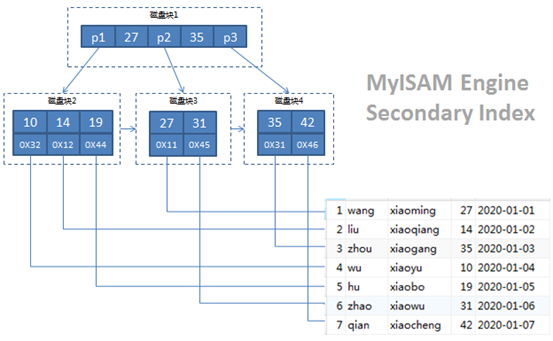
从上面两个图中我们不难发现,在结构上MyISAM Engine的Primary Index和Secondary Index 是一致的,叶子节点的data都是存储的实际数据记录的地址指针,也就是说MyISAM的index和data部分是分开存储的,这样就不难理解MyISAM Engine的表为什么有三个文件了(.frm|.MYD|.MYI) 。
下面我们再来看下staff_innodb的索引结构又是什么样的?
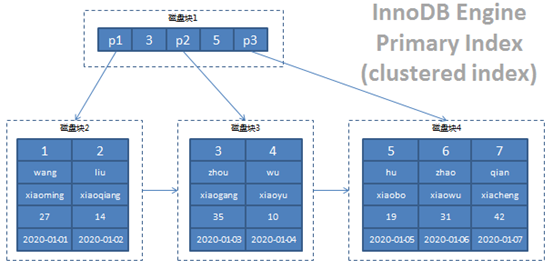
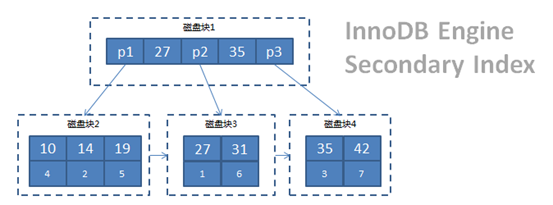
如上图所示,InnoDB的聚集索引也是一个B+Trees结构,跟MyISAM的主键索引不一样的地方是,叶子节点保存了整行记录的数据,我们可以这么理解,InnoDB的表数据文件本身就是以B+Trees结构组织的一个索引文件,既然数据文件即是索引文件,那么如果没有主键的情况下InnoDB还会聚集索引吗?答案是肯定的,聚集索引有着如下的优先级原则:显式声明的主键->第一个不允许为NULL的唯一索引->DB_ROW_ID到这里我们就不难理解为什么InnoDB的表文件对应的是两个(.frm|.ibd)。
当然真实情况InnoDB的Clustered Index并不是上图画的那么简单,叶子节点还存储了TID(Transaction ID)、RP(Rollback Pointer 回滚指针),这些都是为了支撑事务、行锁以及MVCC机制的实现。(后续的文章我们再来讲解)。
同样的InnoDB的Secondary Index的存储结构和MyISAM的也有不同,叶子节点存储的是主键。(注:UNIQUE INDEX和Secondary Index是类似的)
至于MySQL其他的索引如:HASH Index、FULLTEXT Index、Spatial Index、函数索引在后续文章再跟大家一起分析。
至此,我们对MySQL两种常用存储引擎的基本索引数据结构有了基本了解