大画 Spark :: 网络(1)-如何构建起基础的网络模型
背景
8月的时候考虑开始写一个spark的专题系列。当时,看过一些技术文章,思考使用和生活中很近的例子来列举应该会产生共鸣,方便小伙伴的理解和学习。在企业内做培训的时候,采用了一下这样的方法,但是效果却出奇的不好。
之所以会采用这样的方式,在我看来,是我深度理解这个技术框架后,自我记忆与自我消化的一个产物,用这个形象的比喻让大家联想记忆应该会更简单吧?然而,我发现是我仓促了。
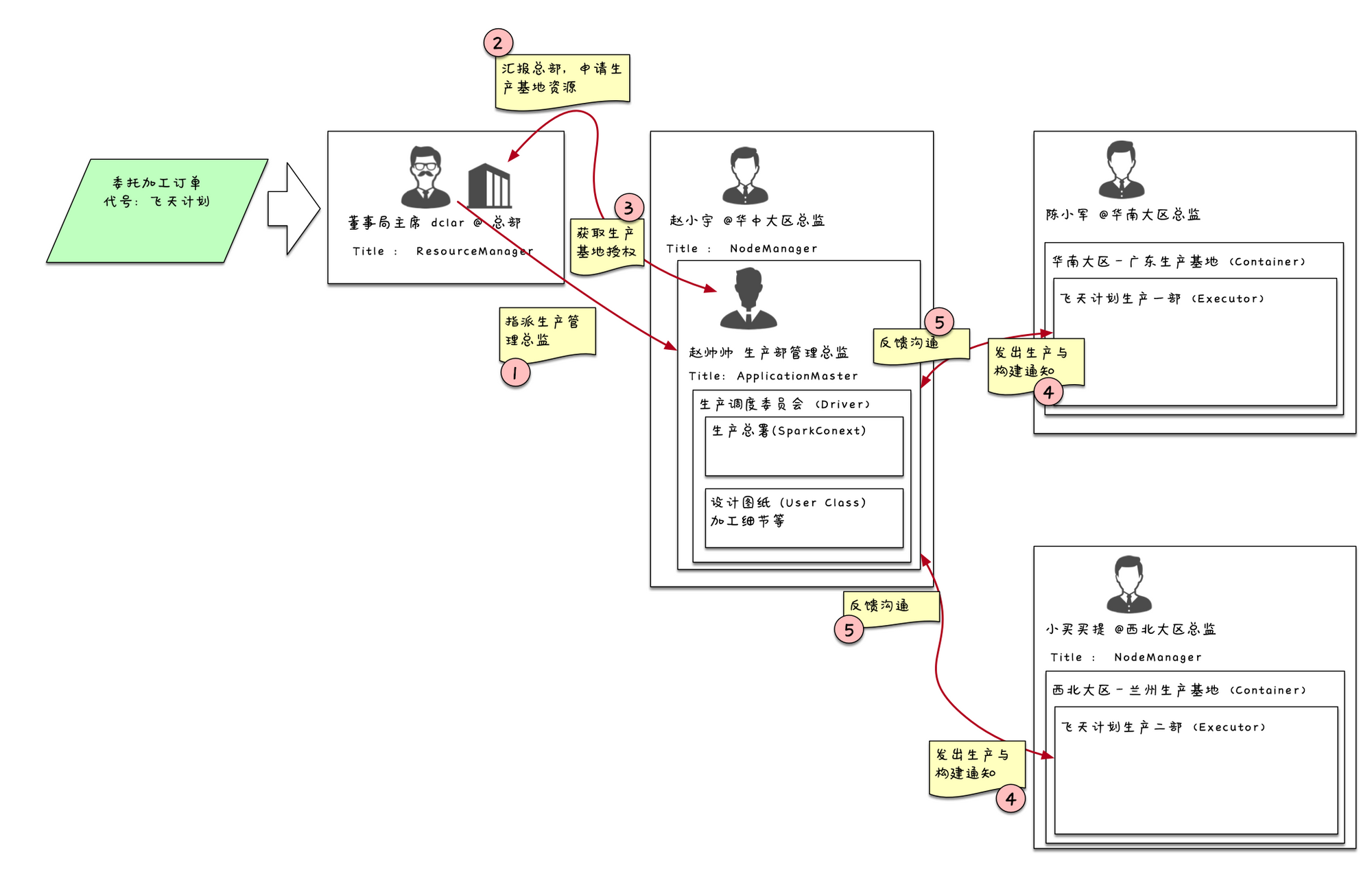
开发同学的资历和认知,导致他们理解我举的公司例子的程度也不一样,甚至有些人还需要再次转换一下思维来再次理解一下公司为何要这么运作,反而对一个问题更加复杂化了。
思来想去,还是用清晰易懂的画图方式,从构建过程到运行过程,讲清楚结构和数据流,我们只采用技术语言来沟通,拉通拉平沟通的维度,而剩下的就是如何更科学的描述这个过程即可。
前言
从今天开始,我来尝试把这个《大画spark》系列换个方式做下去,希望得到大家的指正和反馈。根据我的经验,我会把spark分成几大模块进行讲解,我并不会完全按照spark内部自身结构,流水线的讲解,而是采用我认为可以最快掌握spark的方式来循序渐进的推进
为何先讲网络
大数据处理的一个核心概念就是——分而治之,当单台服务器无法满足计算和存储日益增长的数据量时,我们必须采用这个分别治理的策略,这样就自然而然的产生了并行计算和分布式存储。
在分散存储的服务器上,如何快速的调度起并行的计算,在计算过程中传递数据和参数,最终通过网络向Hadoop写入数据结果或者拉取计算结果,都离不开网络。可以把网络理解成联通每一个城市(服务器、仓储计算节点)的高速公路,通过这条高速公路可以看到城市间的协调联通,也可以看到它们之间都有哪些协作的工作,从而更深的理解城市间的关系。
回到spark,理解一个节点的存储和计算是很简单的,就像学习Springboot,最笨却有效的方法就是debug跟踪,时间和精力到位,结果自然是好的。但对于spark,它是一个非常复杂的多节电协调的分布式计算框架,往往一件事情需要在n个节点做m个步骤才可以完成,采用学习springboot的策略来一个节点一个节点一个服务一个服务的理解,你会发现就是“从入门到放弃”的过程。所以必须先要从宏观上理解整个套路,然后再采取各个击破的策略,从宏观上来看,第一个就要理解spark的网络原理,对于后面我们在了解整体框架后,自己再去看很多细节有非常大的益处。
前置知识
。
讲spark网络这块,我会剥离开的核心内容,只从暴露给用户的接口,也就是暴露给spark的部分来讲,不涉及到的细节,不让大家陷入到更多的知识之间交织的细节中去。
Spark从2.x开始全面采用了,相对于1.x采用的akka而言,的性能与热度都更高。所以学习spark的同时,我也希望大家能够深入了解,因为可以成为很多Java程序员去理解内核的一个敲门砖,从而更深入的理解JVM,用户态、内核态、,对整个技术生涯有着非常大的帮助。在我看做应用服务开发的同学,是必须要掌握的一门技术,因为服务端除了框架技术必备知识之外,最主要的就是领域设计与优化,优化中又包括内存与网络,在这块是教科书。所以我会在精力允许的情况下,再开一个《大画Netty》的专栏对这块的知识再做一个总结,在《大画Netty》中我会总硬件底层核心技术到操作系统、JVM做一个贯通性的讲解,让大家彻底搞懂。
如何讲述
避免大篇幅的代码,因为市面上讲代码的书籍和文章太多了,我希望还是通过我的理解来最快速度剥离出本质给到大家,所以会有很多图,包括很经典的数据结果,我也会画图来说明
一些具体的案例,可能会有代码的展示,但是主要是提纲挈领级别的,不会长篇大论
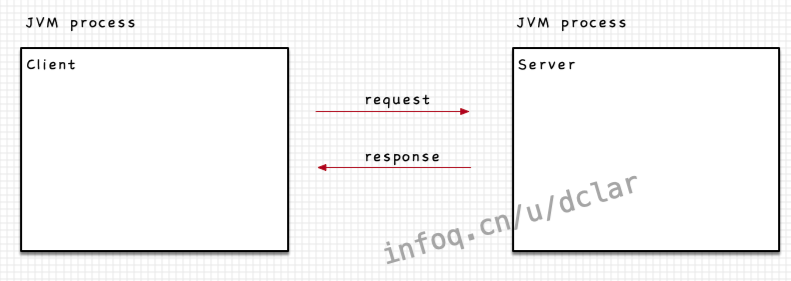
从一个简单的网络通信模型开始
JVM进程
众所周知,process进程与thread线程最大的区别在于,内存区域的共享。多个thread是可以共享其process中的共享内存区域的,但是process之间是不可以的,那么process之间需要做沟通交流就会采用网络的方式。
http协议
我们最熟悉的http协议就是在TCP协议之上的一类供用户来使用的应用层协议。注意,http也可以直接理解为是一种格式。
看一个最简单的的例子,中内嵌,可以在内暴露http服务,通过外部的调用可以访问。另一个可以创建http的request来访问,如下图所示。
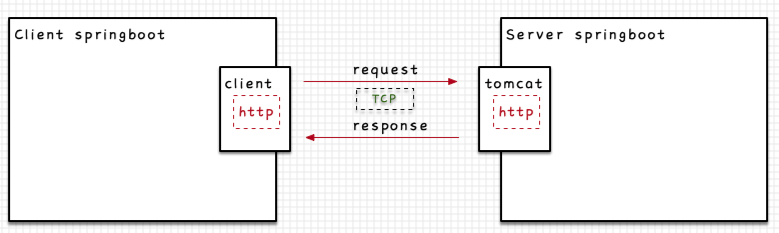
这个例子很简单,被嵌入后,可以进一步的通过各种调用进入到,进而最终达到我们定义的的每一个的方法,这个过程都应该深深的烙印在做后端应用开发的同学的脑海中了。
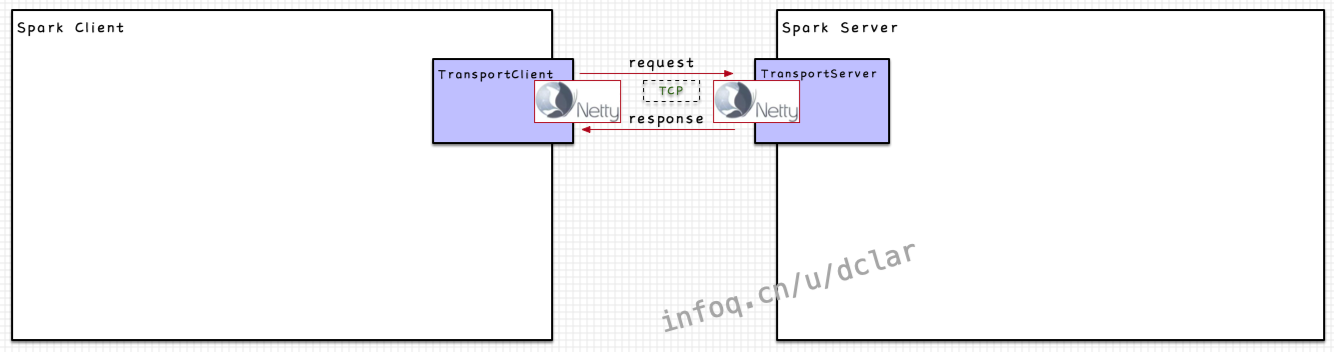
Spark中的简单网络模型
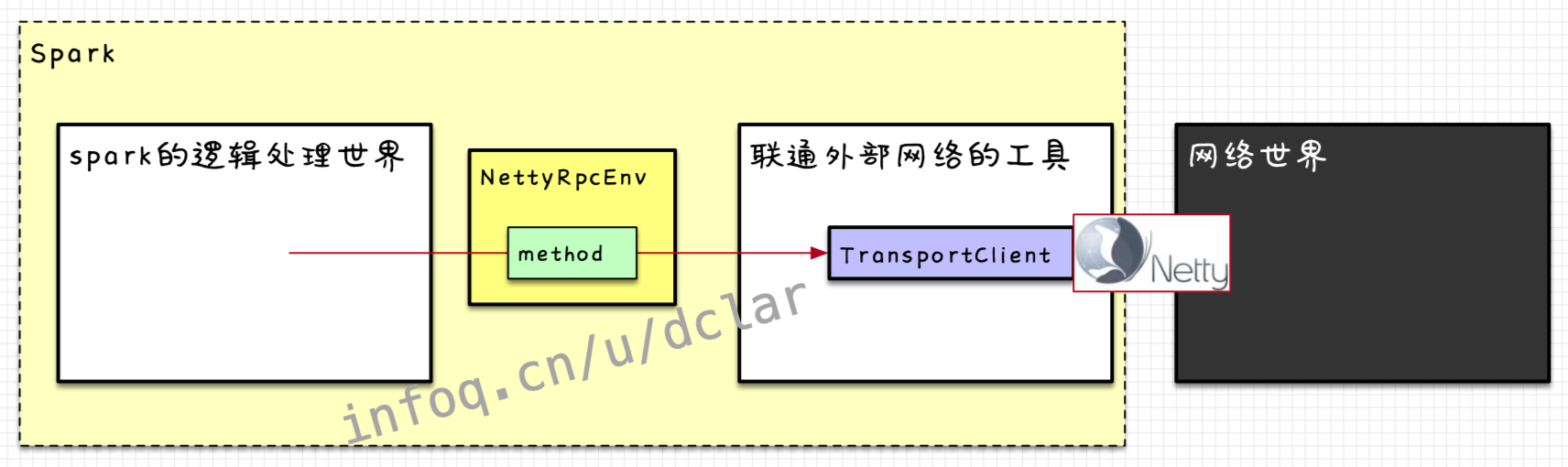
在spark中,网络通信的模型其实和如出一辙,本身spark作为调度计算的框架也没有网络的框架,也需要一个外置的框架来联通网络,通过框架的接口打通内部,这个框架就是,如下图所示
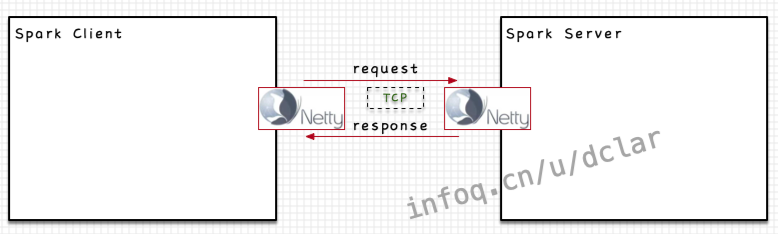
通过,2个JVM进程可以进行网络通信。而Spark在这个调用过程中并不是使用http协议,而是采用自定义的和,这块涉及到了的一些知识,我们暂且不谈。
需要注意的是,Springboot中虽然采用http协议,但是其调用过程封装成的是一个RPC的过程,而在spark中,虽然可以看到有的封装,但其调用过程却并不像封装成一个远程过程调用,更有跨主机网络调用的味道,而使用的概念,更多的是明确对应的特点,和中的(不需要)区分开来,这块我们后面会细说。
Spark中网络模型的构建
一般,讲到这里,很多书籍或者文章就都会直接上代码和各种UML图了,根据我在做培训和分享的经验,这种套路一般人还是很难接受,我会按照high level的方式来逐步递进、逐渐深入的做讲解
Client与Server
在spark中,对于client和server,需要构建的client端与Server端,这两个构建的角色就是与
如下图所示,这两个组件并不需要直接去构建网络部分,而是通过它们两个各自构建出的client端和server端,所以和就是2个抽象的构建工具
需要再次强调一点,作为client端与server端,请求的发送client → server的过程,根据发送请求的不同,server可以作出相应(Rpc),也可以不作出相应(OneWay)
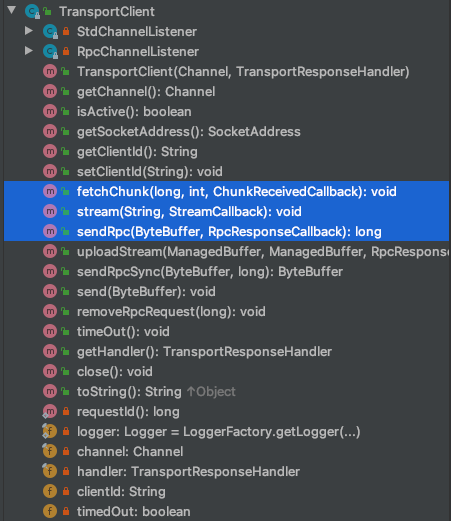
TransportClient
代码留给读者自己看,我只带着大家关注几个重点的地方。
这是class头的信息,表明是发送request(最终也是要通过)的起点,当然这个TransportClient也是被spark后面的业务处理一步步调用的
也是class头的信息,表明client也可以发送去获取流的数据的request,注意,这里的英文是为了fetching连续的块数据,注意“为了”两个字,而不是真的去fetch,所有的获取等操作会有其他的组件来做
重要的方法
可以看到我用蓝色区域标注的方法,这些都是去发送不同请求的方法,具体我们到详细的案例中再去深入理解
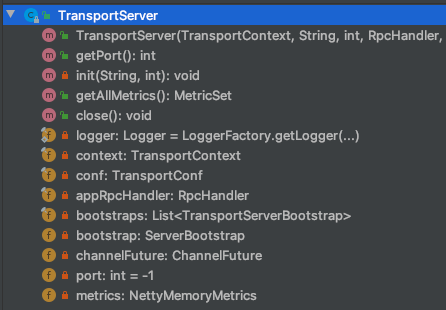
TransportServer
相对于TransportClient来说,TransportServer的功能就很贫瘠,从它的方法列表也可以看出。因为这个TransportServer主要的任务就是去构建起一个Netty的Server,而接收与响应也是其他的模块在做的,后续细化深入
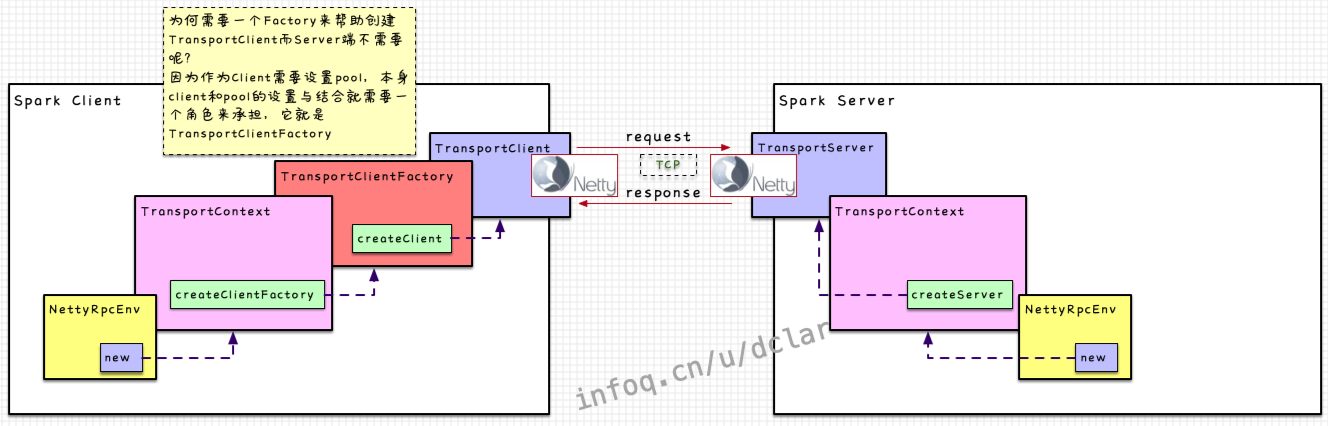
构建client与server
和是如何构建的呢?代码留给读者自己,以及我们后续看详细的流程的时候再刷代码
client端和server的构建流程如下
→→→
→→
NettyRpcEnv
这货是构建网络通信的一个基础设施(上图)
这货还是联通网络与spark的业务处理模块的桥接器(下图)
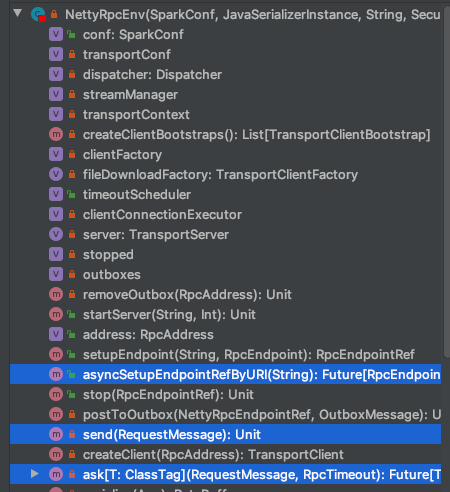
常见的较为重要method如下,后续场景细节的时候都会涉及到
TransportContext
理解一下所谓的上下文
其实,每次一说到“上下文”,我相信很多同学都很懵X,广义和狭义的上下文有着非常大的区别,但如果看过一些DDD领域模型设计的同学可能会有点感觉。在我看,很多地方的上下文可以这么理解:即,它是对限界上下文(DDD中的名词)模糊区域的一个衔接器。嗯,说完这句话,估计跟多人更懵了。我们画个图。
以java而言,在划分出很多组件的一个系统中,如果需要把它们之间的关联和调用关系整理好,需要在一个A class中声明这些组件,然后在这个A class中做各种组合连接处理,联通好每个组件之间的逻辑关系,那么这个A class你可以理解成就是一个上下文。
用一个不恰当的例子,就是组织一帮大佬开会,协调他们时间的秘书,秘书带有所有应该掌握的信息,在不同的大佬需要的时候给到他们,方便协调整合
回到,它负责构建和,并且设置Netty相应的一系列操作处理,衔接Netty与Spark之间的数据传输。下文对细节做说明的时候会经常出面
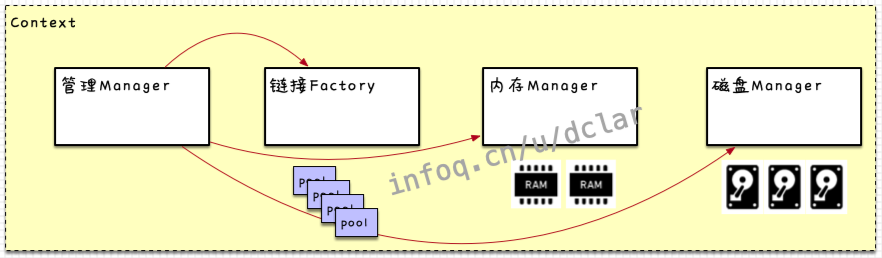
TransportClientFactory
上面的图中也说了,为什么会存在这个,见图即可
对于构建client和server的小小总结
通过这幅图整体能看到构建的过程,但是完全没有结束,因为client和server要处理相应的request和response的话就需要更多的内部细化的组件来处理,下一步我们来细化这些组件
Spark中网络收发数据的细化
补充一点Netty的知识
pipeline
如果希望在Netty中追加我们的业务处理,一般是采用向Netty中追加Handler的方式,参看下图
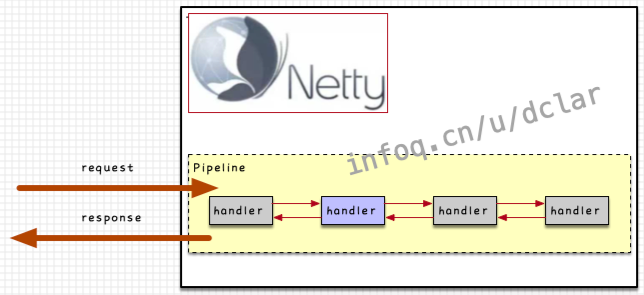
如果需要加入业务处理,我们可以在pipeline中追加很多个handler的chain,从而可以通过request或response的调用串联 起来这些handler
handler
从获取传入数据一般采用方法
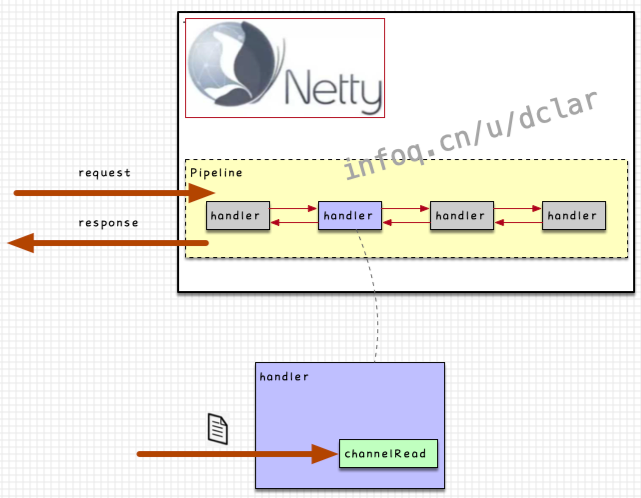
根据上面的基础知识,我们可以get到,spark和netty之间需要使用这样的handler串联起双方
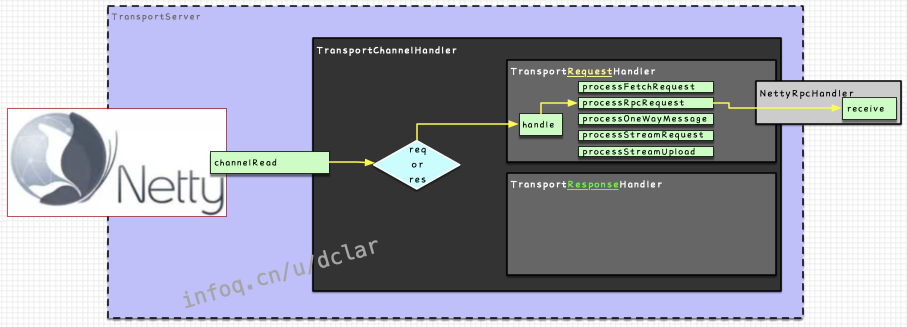
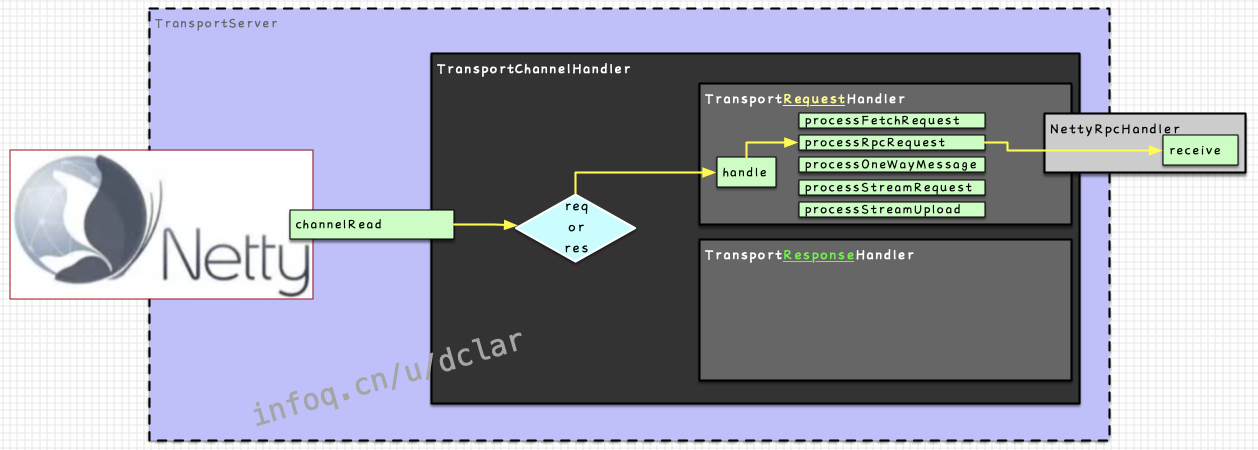
TransportChannelHandler
是的,就是承上了启下了的那个人。在client端和server端都存在这个handler,如下图
但是也不会完全去做所有的工作,内部还会继续做搭建
如下图所示,在中会根据是request还是response来选用以下2个handler进行不同的处理
:负责对request进行操作
:负责对response进行操作
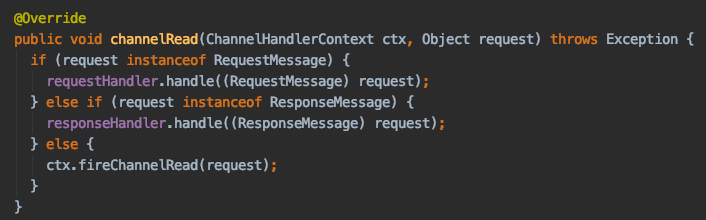
核心代码
模拟一个简单的发送过程
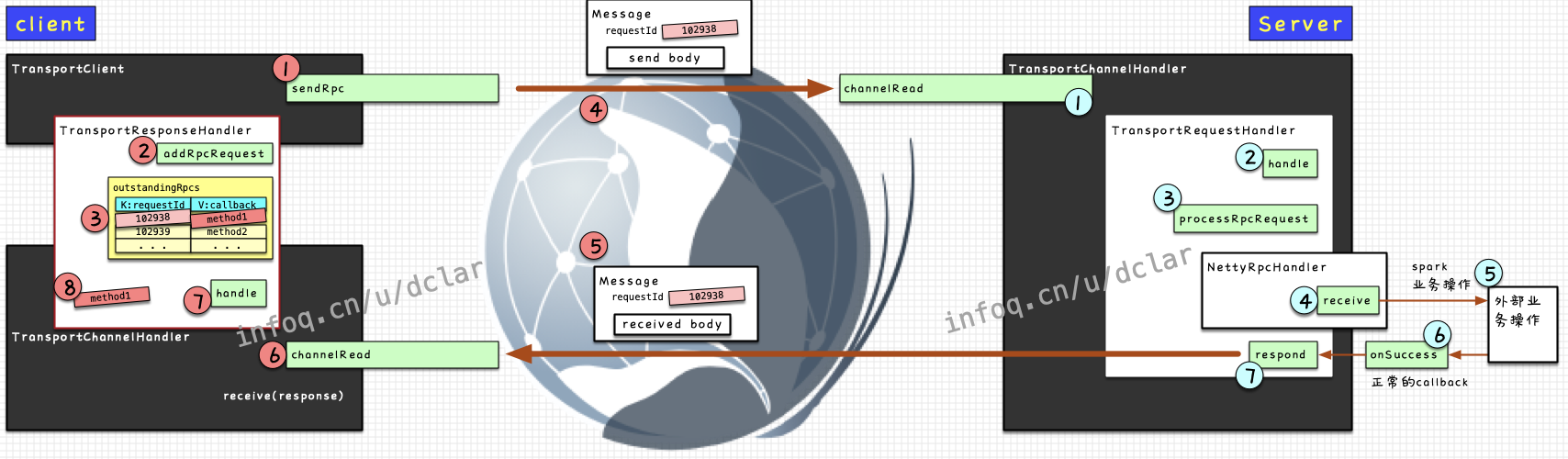
① 从client端发送RpcRequest
② 在server端接收到RpcRequest,进行一系列的业务处理
③ 业务处理完毕后,向client端reply回success(或failure)
③ client端接收到server端reply的结果
几点注意
⚠️ 注意1,下图中对于client端做了一个小小的调整,因为发送和接收不是同一个组件完成的工作,发送是由主导完成的,而接收还是通过完成的,这和server端不太一样,具体细节后面在整个过程中会说明
⚠️ 注意2,写到这里,正好有公司有小伙伴问我,这个client端是driver还是executor的呢?虽然这两个概念还没有说到,但是,这里先要声明一下,client端是driver和executor端都会有的,但是负责调度的server端只存在于driver端,而executor端出现的server是做数据传输的所生成的server,这块有点绕,聊到的时候再说

发送RpcRequest消息
我把发送的过程扩大并细化一下,这个过程其实很好理解
总结一下,通过一个requestId来判断response是不是自己的。这里要注意的是,通信不是http协议,不是阻塞的request和response,所以你马上收到的可能不是刚刚发出去的request的回应,所有消息都需要在map中进行一遍通过requestId的映射查找才可以
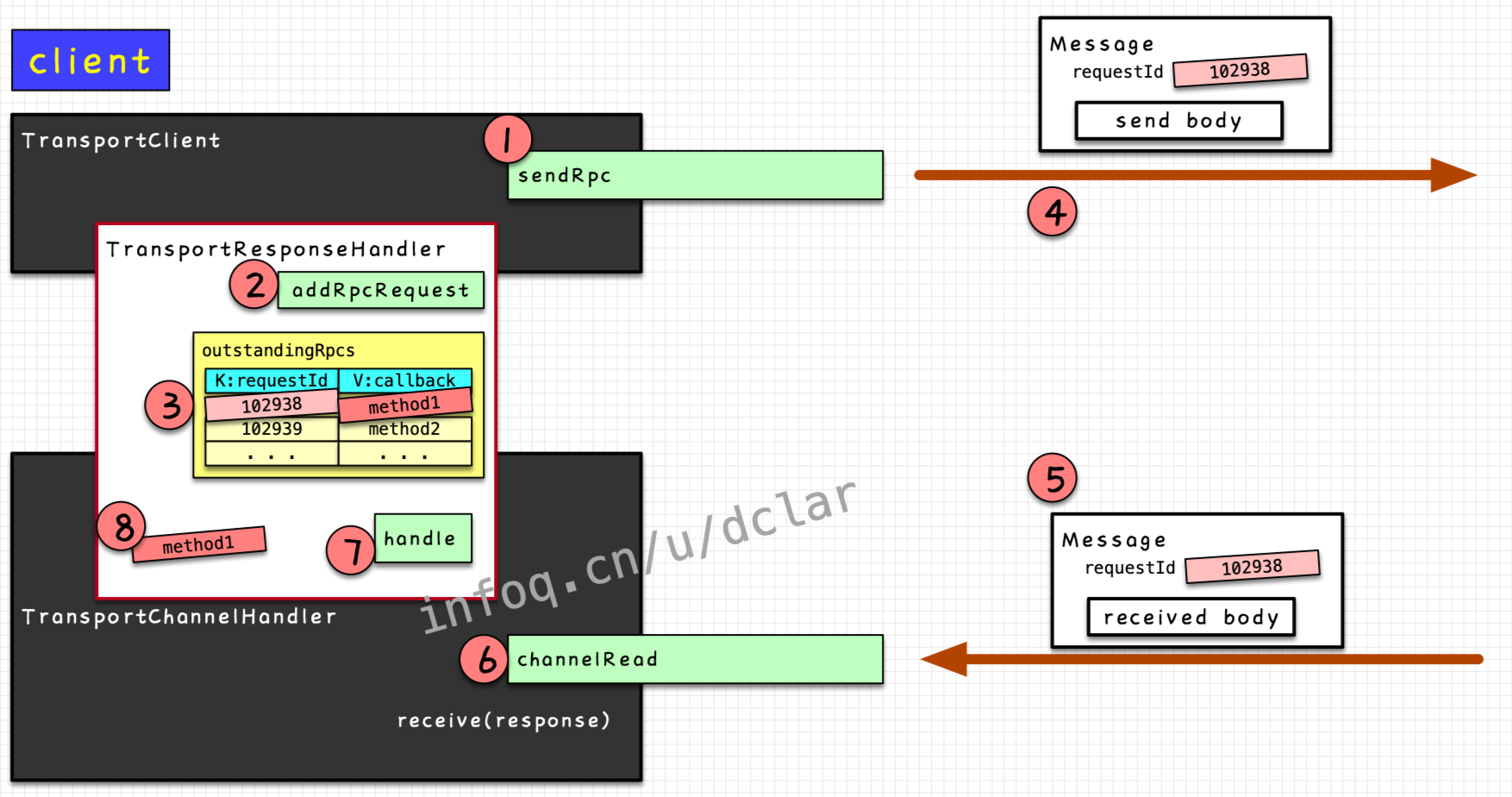
接收RpcRequest消息
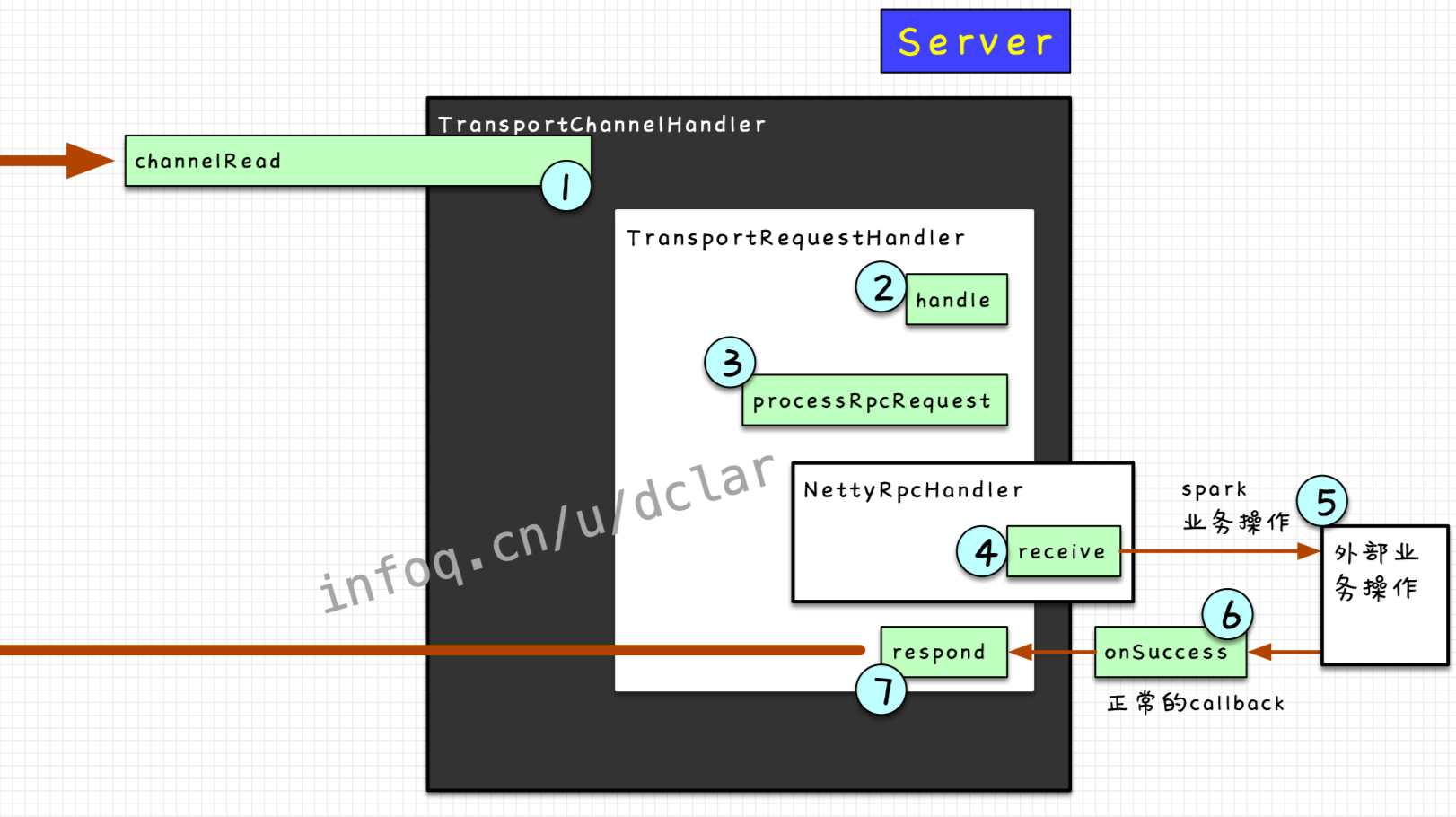
看一下整个的流程
至此,spark中一个非常简单的发送RpcRequest的过程就结束了,spark中很多基础的网络调用都是按照这个流程执行的
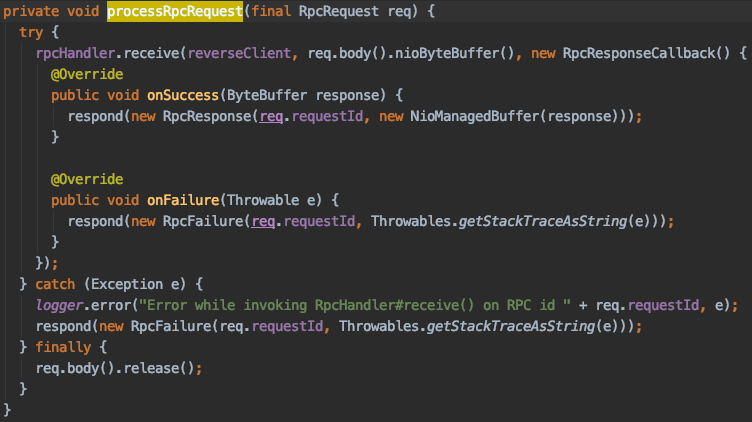
两种Request
上文也有提及,因为不是http协议,所以request不一定会有response,所以spark中也定义了连两类消息,一类是需要有response的RpcRequest,一类是不需要response的OneWayMessage
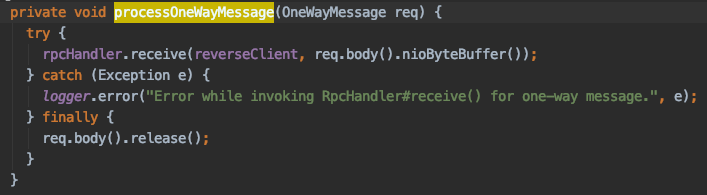
这两类消息的处理,从代码中可以很清晰的看出,上文也做了说明,RpcRequest是需要返回的,而OneWayMessage则只做了,没有任何返回处理
你可以把RpcRequest理解成应用层的TCP协议,而OneWayMessage则是应用层的UDP协议。
RpcRequest
OneWayMessage
总结
本篇从spark的网络入手,初步先把一个简单的网络通信过程理了理,通过这个网络通信的过程,spark可以实现注册、心跳、启动、停止等一系列的RPC操作,根据这个模型,我们也可以自己设计出很多类似的RPC架构模型。
下一篇继续聊网络,我们向着网络两边的业务层面稍稍延伸一些,看看收到消息后,消息是如何处理的,在业务模块中隐藏的endpoint以及endpointRef是什么,它们又是如何去处理消息,发送消息的。