Elasticsearch Query Phase
Elasticsearch query phase,内容来自 B 站中华石杉 Elasticsearch 顶尖高手系列课程核心知识篇,英文内容来自 Elasticsearch: The Definitive Guide [2.x],内容似乎有些过时,但是我觉得底层原理应该大同小异,欢迎拍砖
Query Phase
During the initial query phase, the query is broadcast to a shard copy (a primary or replica shard) of every shard in the index. Each shard executes the search locally and builds a priority queue of matching documents.
coordinate node 根据 from 和 size 参数,构建一个 priority queue, 大小就是 from+size。
from = 0,size = 10,构建一个 0+10 大小的队列,
from = 10000,size = 10,构建一个 10000+10 大小的队列
coordinate node 将请求转发到这个 index 对应的所有 primary shard 和 replica shard 上。
接收到请求的每个 shard 其实都会构建一个 from+size 大小的本地的 priority queue。
当 from = 10000,size = 10,每个 shard 都会构建一个 10000+10 = 10010 大小的 priority queue。
每个 shard 将自己的 10010 条数据返回给 coordinate node,coordinate node 将所有 priority queue 进行 merge,merge 成一份 from+size 大小的 priority queue,全局排序后的 queue,放到自己的 queue 中。
然后 coordinate node 从自己的 priority queue 中,取出当前需要获取的那一页数据,比如从第 10000 条到 10010 条。
When a search request is sent to a node, that node becomes the coordinating node. It is the job of this node to broadcast the search request to all involved shards, and to gather their responses into a globally sorted result set that it can return to the client.
Each shard executes the query locally and builds a sorted priority queue of length from+size - in other words, enough results to satisfy the global search request all by itself. It returns a lightweight list of results to the coordinating node, which contains just the doc IDs and any values required for sorting, such as the _score.
The coordinating node merges these shard-level results into its own sorted priority queue, which represents the globally sorted result set.
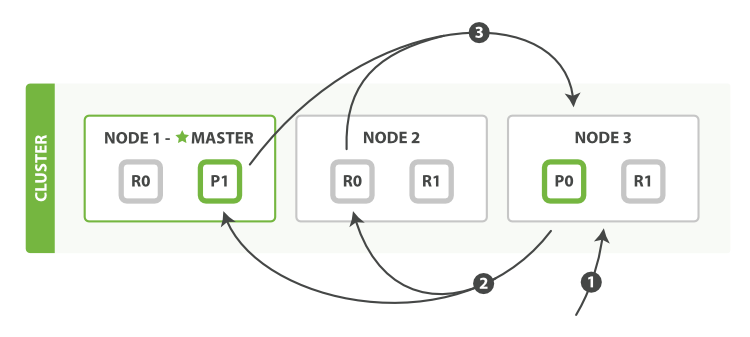
replica shard 如何提升搜索吞吐量
一次请求要打到所有shard的一个replica/primary上去,如果每个shard都有多个replica,那么同时并发过来的搜索请求可以同时打到其他的replica上去
search requests can be handled by a primary shard or by any of its replicas. This is how more replicas (when combined with more hardware) can increase search throughput. A coordinating node will round-robin through all shard copies on subsequent requests in order to spread the load.