100万级车辆数据监控的hadoop大数据架构探索与实践
大家好,我是黑马腾云。
近些年随着网络带宽的提升、AI芯片技术的发展,各种终端设备应用越来越铺及。得益于这些互联网基础设施的完善,推动着整个人类社会朝着更加智能化方向发展。无论是工业AI机器人,还是各种智能家居、车载设备,智能设备随处可见,同时这些设备也在时时刻刻搜集着数据,使得我们的数据出现了前所未有的指数级增长,这给传统的数据处理方式带来了巨大的挑战。
作者有幸在前些年主导并尝试使用hadoop大数据生态技术对传统车联网项目进行改造,取得了一些成果。本文对该项目进行复盘,聊聊大数据架构在车联网行业中的实践。由于技术更新迭代较快,加之水平有限,不足之处敬请轻拍!
一、项目背景
系统主要功能是对车辆(货运渣运、公交车、出租车、长途车、家用汽车等)进行实时监控,防止车辆被盗、阻止不安全的驾驶行为,同时生成各种业务报表,为环保、交通以及汽车金融4S店提供数据服务。系统部分功能模块包括:轨迹查询、实时追踪、快速查车、报警分析、报警设置、风险评估、预警分析等。
为了实现车辆数据的实时采集和分析,对可能存在的风险驾驶行为立即进行语音播报提醒,同时将采集数据(行驶轨迹、报警数据等)生成行为报表为业务系统提供数据支撑,改造前项目按以下步骤处理数据流:
1、将装有各类传感器的车载终端设备安装到车辆上,设备实时采集数据,并按照规定好的协议报文每20秒发送回一条数据至服务器网关程序。
2、服务器网关程序接收中断采集数据并按协议进行解析,对于风险驾驶行为下发指令到设备,对于轨迹等数据则存入入库队列。
3、入库队列数据存入SqlServer数据库。
系统示意图如下:
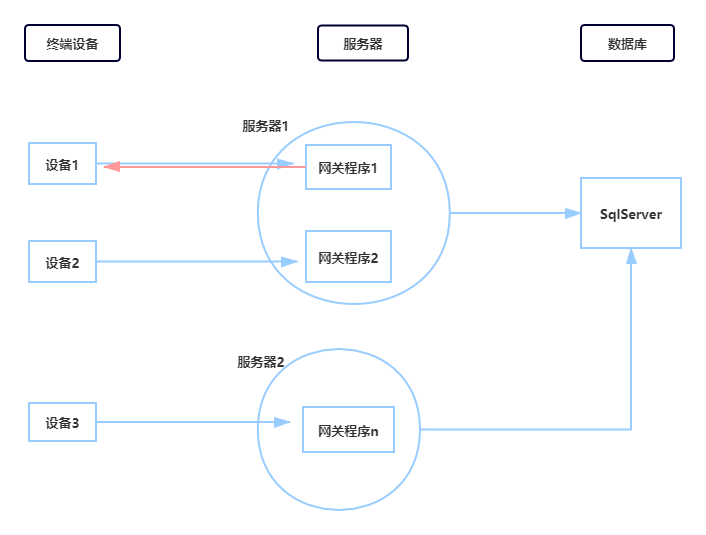
对于改造前的项目,不难看出使用了传统的软件架构模式,存在诸多的问题(由于软件架构本身是根据业务进行迭代的过程,在项目前期的业务场景下这种方式还是很不错的,至少项目稳定为公司支撑了N年业务),因此6-8台服务器能撑起10-15万左右的车辆接入,随着业务量的增加,需要继续投入硬件服务器,成本比较高。
以上模式存在以下问题:
1、服务器未组成集群,每台服务器都是各自为政,或多或少会资源分配不均
资源分配不均的结果是,要么导致服务器资源浪费,要么导致某些服务器负载过大。设备与服务器网关的接入并非真正意义的负载均衡,为了降低服务器压力,虽然编写了算法进行轮询,但比较初略,粒度比较大。
2、数据库只有一个,并且未读写分离
业务中有频繁读写的场景,有可能导致数据库堵塞。比如设备每20秒回传依次数据,就会入轨迹库,同时还要维护最后实时的位置表;另外查询车辆轨迹也会频繁查询数据库。
超过一个月的轨迹查询,有时候需要几分钟时间,这是难以忍受的。因此数据库的读写性能也是一个瓶颈。
3、网关程序功能耦合,应进行拆分
改造前网关程序干了所有核心的事情:解析协议、维护消息队列、入库程序。实际上,网关程序只应该解析协议,按照规定的报文格式解析设备回传数据,然后再分发到消息系统,通过消息的订阅机制去通知不同的业务系统处理数据,从而解耦系统。再比如入库程序就不应该放在网关,而应该独立出来。
软件设计的一个原则:高内聚、低耦合。这样系统维护起来才能减少各个模块间的依赖关系。
4、网关部署非常麻烦
相同的网关程序,需要手动部署多份,每次有版本更新,都需要停服手动去更新。这就会导致数据丢失,虽然短暂的数据丢失对轨迹数据不会有太大影响,但是对于关键的报警数据丢失则可能造成巨大的损失。
为了满足日益增长的业务,并同时解决掉以上问题,对系统的重构就势在必行。
二、项目需求
1、功能需求
除了上述提到的原有功能的平滑迁移,还需要添加:视频采集、视频分析、危险驾驶报警等功能。通过车载摄像头实时采集车辆数据及驾驶员行为,把采集的视频画面与AI训练的模型进行对比,分析的出是否有疲劳驾驶、抽烟、打电话等不安全的驾驶行为,一旦发生这些行为立即在车内进行语音播报提醒。
系统部分功能模块如下图:

2、性能需求
查询秒级响应
1台车辆1个月的轨迹查询,响应时间应明显提升,至多不超过3秒。
良好的扩展性和伸缩性
可根据业务容量动态部署,至少满足100万车辆接入
危险行为分析不超过3秒
三、技术选型及架构
1、Linux+Docker
为了便于实现软件部署及迁移、扩容的,把原来的windows服务器改为Linux服务器,所有应用和服务都迁移到Docker里统一管理。
引入Docker后,网关程序每次更新发布将变得非常简单,无需再关心具体服务器上的网关程序,只需要把软件包打包为Docker镜像文件,发布到软件仓库即可。通过这种方式解析部署繁琐以及服务中断的问题。
2、Kafka消息中间件
引入kafka消息中间件,实现各个业务系统的解耦。各个业务系统通过订阅kafka内的消息读取所需的数据即可,这就把各个业务系统的耦合性降低,防止某些业务出现问题导致整个数据流挂掉。
同时将不同消息(数据)放入不同的主题(topic),对应业务系统作为消息消费者只能取到各自对应的数据。
3、Flink实时计算框架
Flink是非常优秀的实时处理框架,其高性能已在各大厂得以实践和证明。
对于实时报警、驾驶行为数据,采用Flink计算框架进行实时处理,减低消息处理时延。
4、数据存储HBase+MySql
数据存储采用:HBase+MySql数据库结合。HBase是基于Hadoop的列式存储数据库,与传统关系数据库相比,它更适合存储车辆轨迹数据;而对于有关联关系的数据则采用关系数据库MySql更加合适。
根据终端设备特点,把数据分为车辆轨迹数据、实时定位数据、报警数据等。对于需要反复查询,但是不会更新的历史数据存入HBase;对于分析报表则存入MySql。
5、视频分析及模型训练
为了对驾驶员驾驶行为进行分析,我们需要实时采集视频并回传到服务器,然后再将视频画面与训练的AI模型进行比对分析,一旦发生危险行为则立即下发到终端设备进行语音播报。
经过实践,通过采集视频和服务器端算法分析的模式存在一定问题,由于数据需要在设备和服务器之间来回传输,对于信号比较差的地方(如山洞、高原、偏远地区、地下室等)导致时延较大。
针对这个问题我们做了改进,将视频检测、视频分析和算法匹配功能直接嵌入设备芯片,把视频处理功能交由硬件处理,这样减少数据的来回传输,做到秒级响应。
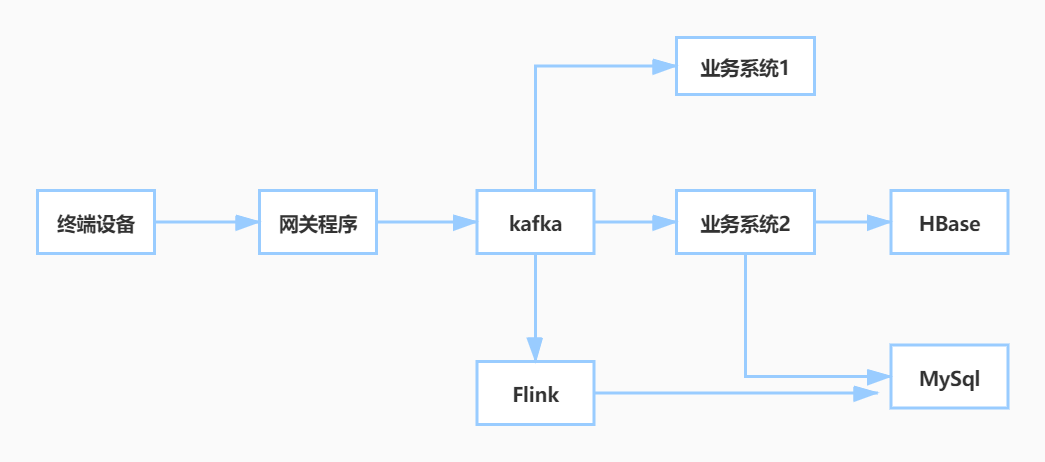
改进后系统流向和层次结构如下:
系统数据流向图
系统层次结构图:

四、方案具体实施步骤
ps:由于篇幅所限,以下仅列出核心步骤,省去了运行结果和部分步骤,请大家参考时注意。
1、搭建Docker服务器集群
服务器全部安装Linux操作系统,并安装Docker。
(1)安装Docker
Docker安装命令
yum install -y yum-utils \ device-mapper-persistent-data \ lvm2
yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
yum install docker-ce
(2)创建swarm集群
所有机器Docker安装完成后,创建swarm集群,将所有集群划分到同一个swarm网络。
创建集群主节点
docker swarm init --advertise-addr=IP地址
其它节点加入集群
docker swarm join --token XXX IP地址
(3)创建overlay网络
docker network create -d overlay --attachable 网络名
创建网络后,后边的各种服务划分到此网络下。
(4)安装portainer
portainer提供了轻量级的集群监控功能,前期推荐使用,后续随着业务增加可以使用K8S。通过portainer可以方便查询和管理各个docker节点的状态,也提供了诸如容器的创建、停止、日志查看等管理功能。
2、基础环境搭建
创建好swarm集群后,就要规划每个节点放那些服务。这里的服务包括:Zookeeper、Hadoop、Kafka、Flink、Redis、协议网关、HBase、Mysql等。
(1)集群规划
规划的原则就是根据组件特点,按需分配。
通常Hadoop、Hbase、Mysql主要用于存储数据,因此对应节点的存储要足够大,磁盘转速要足够快,磁盘转速理论上要大于7200转;对于Kafka、Flink组件是内存大户,因此需要部署在内存足够大的节点上;至于Zookeeper则用于存储集群组件的数据,HBase和Kafka的元素据都存储于此,因此至少要部署到3-5各节点,根据zookeeper的选举机制,建议是配备奇数个节点。
(2)创建镜像
规划好节点对应的组件后,就要为每个组件编写镜像文件(dockerfile)和部署文件(docker-compose)。
以下以网关为例,镜像文件如下:
FROM centos:latest
MAINTAINER heimatengyun
# 1.create java environment
ADD jdk-8u191-linux-x64.tar.gz /usr/local
ENV JAVA_HOME=/usr/local/jdk1.8.0_191
ENV CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
ENV PATH=$JAVA_HOME/bin:$PATH
镜像文件创建好以后,需要通过docker build命令将其打包为镜像。
docker build -f basejdk-dockerfile -t cetrdpd/basejdk:1.0 .
(3)创建部署文件
此处以kafka节点的部署为例,docker-compose文件如下
version: '3.2'
services:
kafka1:
image: wurstmeister/kafka:2.12-2.1.0
networks:
- hbase
volumes:
- kafka_data_1:/kafka
deploy:
mode: replicated
replicas: 1
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
constraints:
- node.hostname == serv223
environment:
KAFKA_ZOOKEEPER_CONNECT: zoo1:2181,zoo2:2181,zoo3:2181,zoo4:2181,zoo5:2181
KAFKA_ADVERTISED_HOST_NAME: kafka1
KAFKA_ADVERTISED_PORT: 9092
kafka2:
image: wurstmeister/kafka:2.12-2.1.0
networks:
- hbase
volumes:
- kafka_data_2:/kafka
deploy:
mode: replicated
replicas: 1
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
constraints:
- node.hostname == serv224
environment:
KAFKA_ZOOKEEPER_CONNECT: zoo1:2181,zoo2:2181,zoo3:2181,zoo4:2181,zoo5:2181
KAFKA_ADVERTISED_HOST_NAME: kafka2
KAFKA_ADVERTISED_PORT: 9092
kafka3:
image: wurstmeister/kafka:2.12-2.1.0
networks:
- hbase
volumes:
- kafka_data_3:/kafka
deploy:
mode: replicated
replicas: 1
endpoint_mode: dnsrr
restart_policy:
condition: on-failure
placement:
constraints:
- node.hostname == serv225
environment:
KAFKA_ZOOKEEPER_CONNECT: zoo1:2181,zoo2:2181,zoo3:2181,zoo4:2181,zoo5:2181
KAFKA_ADVERTISED_HOST_NAME: kafka3
KAFKA_ADVERTISED_PORT: 9092
volumes:
kafka_data_1:
kafka_data_2:
kafka_data_3:
networks:
hbase:
external:
name: zyt
其余的各组件,按照同样的方法搭建即可。按照这种方法准备好所有的基础环境。
3、kafka创建主题
上述搭建好kafka集群后,为kafka创建主题,分别用于存放设备回传的原始数据、轨迹数据、报警数据。
kafka主题创建命令为
kafka-topics.sh --create --zookeeper zoo1:2181 --replication-factor 1 --partitions 3 --topic 主题名称
创建好主题后,就可以接收来自网关程序的设备数据。
4、创建HBase和Mysql表
创建Hbase表格的语句为create,分别创建用于存放轨迹表格和实时位置表
create 'gps','loc'
create 'gps',{NAME=>'loc',TTL=>8640000} 设置过期时间为100天
create 'gps-realtime','loc'
mysql表格根据业务需求创建,方法比较简单,在此不做阐述。
到这一步,基本数据已经可以流通了。
5、网关程序开发
网关程序主要用于接收并解析设备报文,按照协议将16进制报文解析为对应的位置数据、报警数据等内容,存入kafka主题即可。
6、入库代理程序
主要用于读取网关解析并存入kafka的轨迹数据,然后存入Hbase。
7、Flink实时分析程序
主要用于分析网关解析并存入kafka的报警数据,形成对应的报警报表入库到Mysql。
8、地理位置解析代理
由于不同地图采用的GPS定位经纬度坐标有差异,因此在入库前还需要对坐标统一进行转化,以便在高德地图或腾讯地图可以正常显示。这一过程也成为纠偏。
方法比较简单,但要注意更具设备的特点,区分GPS定位还是基站定位,需要做特殊处理。
9、业务系统
业务系统根据采集到的mysql数据进行相应的处理,为前端业务系统提供查询服务。
业务系统采用前后端分离的开发模式,前端页面采用vue进行开发,独立部署到nginx中;
业务系统后端采用springboot+springcloud微服务架构模式,将业务功能进行拆分。
10、其它子系统
其它一些子系统由于给具体业务相关,这里不做介绍。
通过上述的流程,已经完成了设备数据的采集、报文协议解析、flink实时计算以及入库,为其它业务子系统提供了数据来源和依据。
由于采用了kafka消息中间件,各个业务系统只需要按需订阅各自的数据即可,使得系统扩展性和维护性得以提高。
五、结果及结论
通过系统的改造和近3年观察运行,已达到预期目标。
1、查询低延时
10台服务器组成的集群,50万车辆已平滑迁移,经过测试100万车辆。单台车辆超过一月的历史数据查询,响应延时不超过3秒。
2、扩展性良好
当业务增长时,只需要横向扩充服务器节点即可。
3、驾驶行为检测准确率90%
只要有抽烟、疲劳表情驾驶,立即报警提醒。
六、后续优化
虽然达到预期目标,但业务需求还是会不断变化,技术也是在不断更新迭代中。项目中还有以下地方需要改进:
1、驾驶行为的检测误报
模型训练还需要采集更多素材,比如更多的人脸表情、抽烟和打电话的细节处理。比如能准确识别拨打手持电话,但对蓝牙耳机方式拨打电话,还需要结合画面和语音进行更细腻的检测,防止误判。
2、数据压缩及协议简化
每月累计新增2T数据,其中部分数据还有压缩和优化的空间。
3、将业务系统进一步独立
将业务系统彻底独立,使大数据集群和业务系统进行物理级别网络隔离,提高安全性。
写在最后
随着技术的更新,以特斯拉为代表的新能源汽车正在逐渐普及,无论是政府的引导还是车商的补贴,都告诉我们智能汽车是未来的趋势。假以时日,电池技术更加成熟、芯片技术更加智能,各种智能车将普及到大众生活中。
除了特斯拉,传统车企,国内互联网企业也加入这场战斗中来,百度、小米等相继宣布造车、华为也在联合各大汽车厂商搭建车联网生态,由此可见车联网很可能是继互联网、移动互联网后的又一大风口,让我们拭目以待!
到时候各种传感器已经内置到汽车零件中,不用像现在一样还要额外通过加装设备采集车俩数据。到时候很有可能由厂商或第三方大数据机构统一对车俩数据进行联网处理,这也会影响着车联网软件的架构更新,欢迎持续关注。