Spring Boot可执行JAR的原理
关键词
JAR、ZIP文件格式、类加载、JAR URL协议
注:本文Spring Boot的版本是2.x
问题
如果你清晰地知道以上问题的答案,那么可以忽略本文,本文将无法给你带来新的启发。
一图胜千言
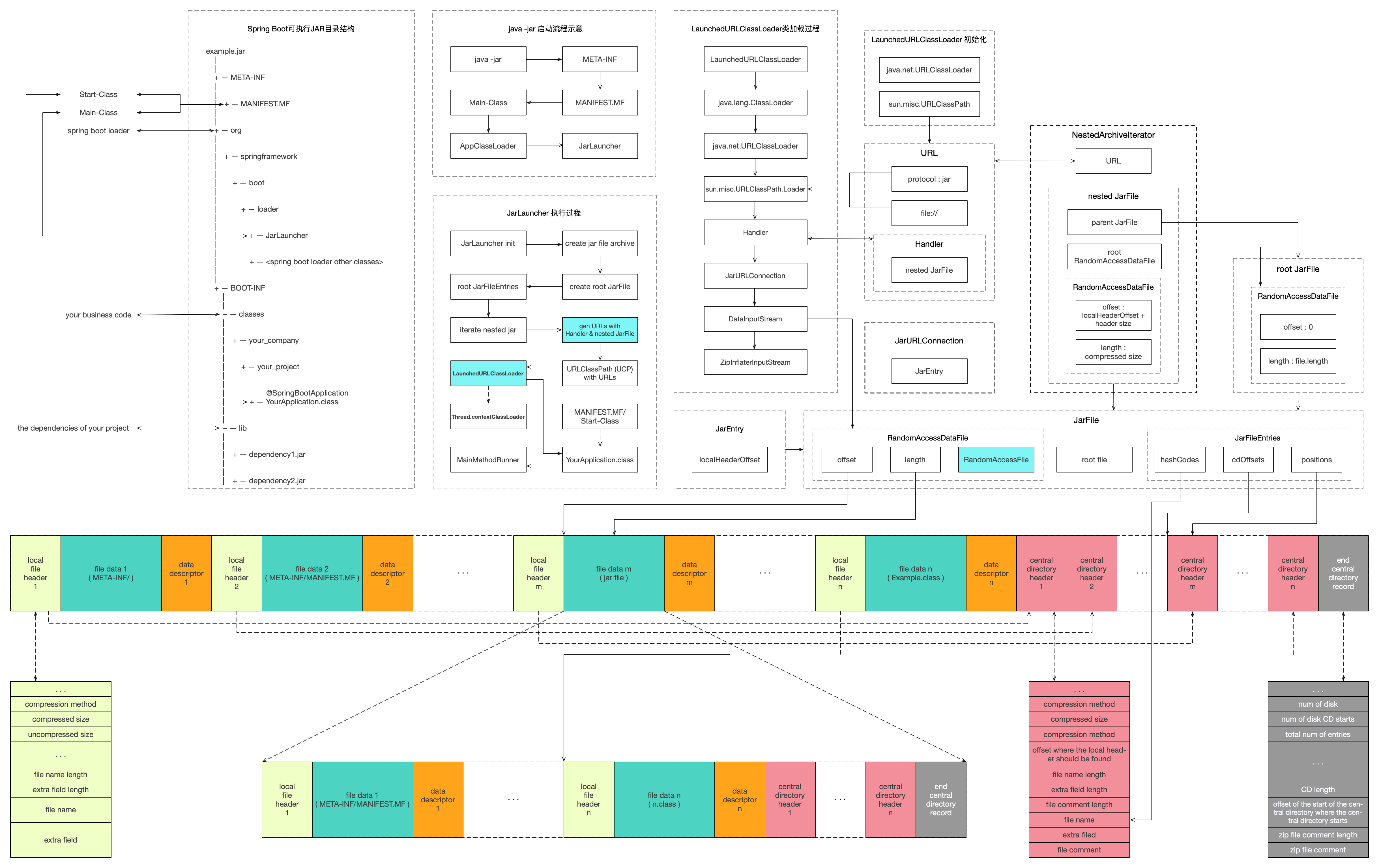
1. Spring Boot可执行JAR目录结构
Spring Boot可执行JAR(以下简称JAR包)的目录结构()与普通可执行JAR包(类似通过maven-shade-plugin打包的jar)是有区别的。JAR包有三个直接子目录,分别是:
1.1 Main-Class
Main-Class()指向可执行JAR的入口类,是MANIFEST.MF文件中的标准属性。JAR包的入口一般是JarLauncher()。这就是第一个问题的答案。JarLauncher继承自ExecutableArchiveLauncher,是整个JAR包的“main entry point”。
1.2 Start-Class
Start-Class指向JAR包中用户定义的启动类,该属性是Spring Boot自定义的属性。Start-Class指向被@SpringBootApplication注解修饰的类,一般是我们业务程序的入口。Spring Boot Loader完成内部的启动之后,会加载并反射调用Start-Class指向的业务入口类。
2. ZIP文件格式
ZIP压缩格式虽然不是最高效的压缩格式,但它是主流操作系统(Win、OS X、Linux等)都普遍支持的格式,这也许就是SUN公司采用ZIP格式作为JAR文件格式的原因(一个JAR文件就是一个ZIP压缩包)。读者可通过这篇文章()了解压缩格式的简史。
ZIP文件格式规范()详细定义了ZIP文件的格式(二进制数据格式)。图一底部彩色部分,就是一个ZIP文件的示意。图中茶色、绿色和橙色分别对应ZIP文件格式规范中的“Local file header”、“File data”和“Data descriptor”,红色和灰色部分共同构成“Central directory”,红部分对应“Central directory header”,图片最后灰色部分对应“End of central directory record”。
2.1 Local file header
本地文件头,标准长度为30个字节,可变长度包括了文件名的名称和“extra field”,文件头的签名是“0x04034b50”。从文件头可以解析出文件的压缩方法、文件压缩后的大小、文件压缩前的大小、文件名称、文件名称的长度等关于文件的关键信息。注意:一个目录也是一个文件,类似“META-INF/”这个目录,会有独立的文件头来描述。
2.2 File data
紧跟文件头的是文件数据,除了目录、0字节的文件等之外,文件数据不能为空,且一般文件数据都是被压缩过的。
2.3 Central directory
中央目录,位于整个ZIP文件的尾部,包括了“Central directory header”和“End of central directory record”两部分,为快速定位并读取ZIP文件内容提供了便利。
2.4 Central directory header
中央目录头是本地文件头的扩展,涵盖了本地文件头所有的属性,新增了文件操作时间、文件评论等属性。
2.5 End of central directory record
“End of central directory record”,即中央目录尾记录,是ZIP文件最后一个数据结构,包含了中央目录的起始位置、ZIP文件包含的文件数量、中央目录的大小等重要属性,这些属性是“不解压ZIP文件并任意读取ZIP文件”的基础。
3. Why ZIP Format?
为什么我们需要了解ZIP文件的格式?我们来看一下Spring Boot官方文档上的一段内容(),截图如下:

大意是:
通过核心类“org.springframework.boot.loader.jar.JarFile”,可以从标准JAR文件中加载内容,也可以从内嵌JAR包中加载数据。
首次读取JAR包时,Spring Boot会计算每个JarEntry(可理解为JAR包中的一个文件)在JAR包中的偏移量。然后通过文件的随机读取,就能实现加载内嵌JAR包中的文件。
无需解压JAR包和内嵌JAR包,并且可按需加载需要的文件(懒加载)。这里的关键词是“偏移量”和“文件随机读取”。偏移量的计算,势必要熟悉ZIP文件的格式,否则无法精确计算每个文件在JAR包中的位置和数据量。随机读取的文件内容,需要知道是否被压缩,如果被压缩,需要解压之后,才能加载到JVM(读者可以回顾一下,Java中哪个类是用来支持随机文件读取的)。
4. 核心数据结构
4.1 JarFile
JarFile继承自java.util.jar.JarFile,并实现了对内嵌JAR包的操作和读取。图一中“JarFile”虚线框部分示意了JarFile的构成。JarFile即可以表示最原始的JAR包,也可以表示内嵌的JAR包。图一中“nested JarFile”和“root JarFile”都是一个JarFile对象,一个重要的区别在于RandomAccessDataFile中的两个属性:offset和length。
4.1.1 JarFileArchive
JarFileArchive本质上是对JarFile的抽象。Archive翻译过来就是归档,在ZIP等压缩技术出现之前,大家用的就是“tar”这种归档技术(不压缩文件)。JarFileArchive最主要的功能是遍历内部JAR包,并生成URL,便于实现加载内嵌JAR包中的类。
4.1.2 JarEntry
JarEntry继承自java.util.jar.JarEntry,并多了一个属性:localHeaderOffset。该属性表示JAR包中每个文件的本地文件头在JAR包中的偏移量。从图一中可以看出,localHeaderOffset就是指向所有茶色部分的起始位置。在计算内嵌JAR包中文件的本地文件头时,需要注意加上内嵌JAR包在外部JAR包的偏移量。JarEntry可以通过JarFileEntries计算获得。
4.1.3 JarFileEntries
JarFile在初始化阶段,就会初始化JarFileEntries。JarFileEntries记录的是ZIP包中所有中央目录头的偏移量,通过这些偏移量就能读取得到JAR包中所有文件的属性。中央目录的计算,是一个猜测的过程。首先读取“End of central directory record”,由于它包含了可变长度的“zip file comment”,所以会先猜测一个起始的读取位置,然后根据“End of central directory record”的属性特征(数据签名是0x06054b50L),尝试计算出“End of central directory record”的实际起始位置,最后读取“size of the central directory”和“offset of start of central directory with respect to the starting disk number”,即可读取ZIP包的所有中央目录头了。
JarFileEntries通过三个数组来记录每个中央目录头的偏移量,三个数组分别是:
三个数组会顺序记录JarEntry的hashCode、偏移量和原始序号。然后基于hashCodes的值,对三个数组进行快排。最后通过一个临时数组调整positions的值,使得通过下标的自然序能快速找到对应的hashCode值和偏移量。positions用来保留JarEntry在中央目录中的原始顺序,处理的过程建议阅读一下源码。下图示意了三个数组的前后变化:
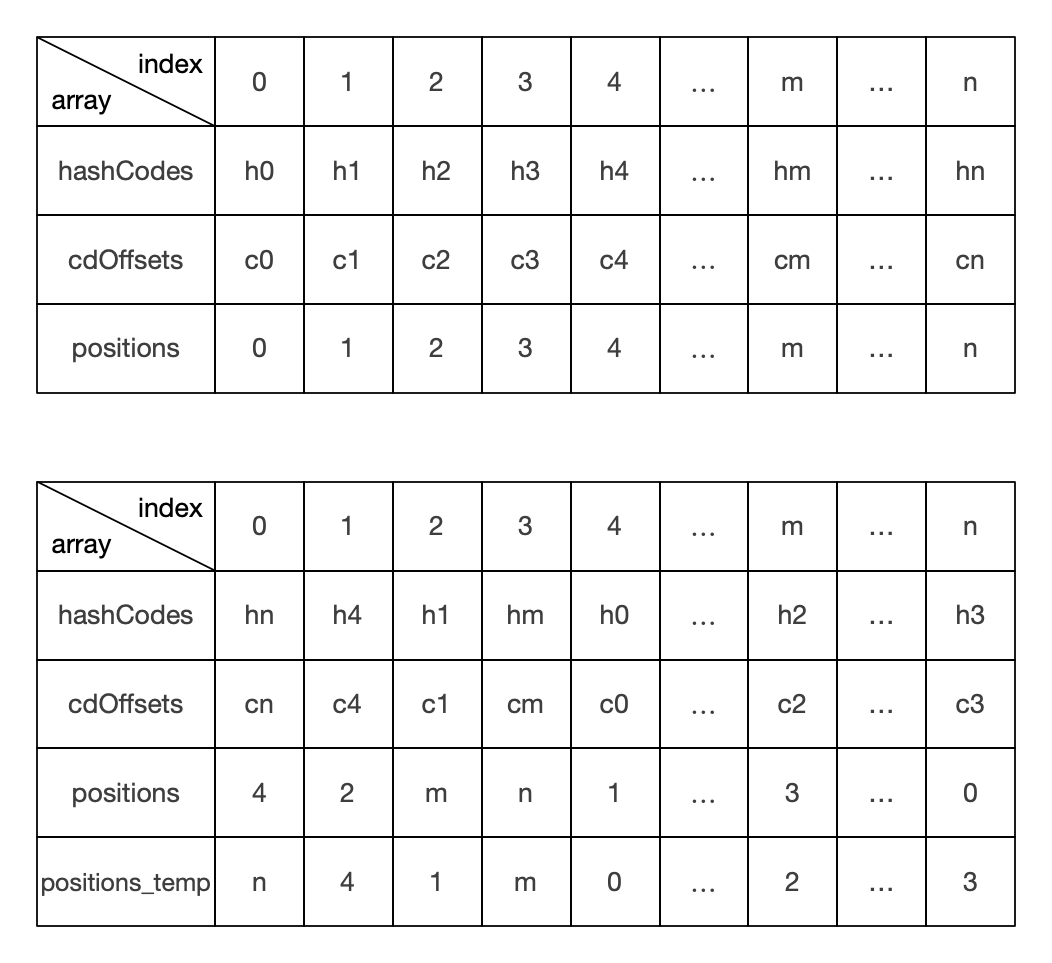
如果我们要加载JAR包中的某个类,首先计算文件名的hashCode,然后使用二分查找从hashCodes中找到index,cdOffsets[index]就是该文件对应中央目录头的偏移量。
4.1.4 RandomAccessDataFile
RandomAccessDataFile很重要,封装了java.io.RandomAccessFile(Java老司机看到这个类是不是会心一笑^_^),同时记录了当前JarFile的偏移量offset和大小length。通过RandomAccessFile和JarEntry,就能实现任意读取和加载JAR中的文件,包括内嵌JAR包,且无须解压任何JAR包。
4.2 ExecutableArchiveLauncher
ExecutableArchiveLauncher继承org.springframework.boot.loader.Launcher,后者是所有Spring Boot Loader启动类的抽象类。ExecutableArchiveLauncher是JarLauncher和WarLauncher的父类,封装了可执行JAR的公共实现,包括创建LaunchedURLClassLoader类加载器、业务代码的启动入口等。LaunchedURLClassLoader类加载器会被设置成当前线程的线程上下文类加载器。
4.3 MainMethodRunner
MainMethodRunner是一个工具类,通过反射,来启动业务的启动类。业务启动类是通过当前线程的线程上下文类加载器加载。
5. LaunchedURLClassLoader类加载器
LaunchedURLClassLoader是Spring Boot Loader自定义的类加载器,是第二个问题的一个答案。它继承自java.net.URLClassLoader,说明也是通过指定的URL路径,来寻找和加载目标类。
5.1 初始化
首先通过JarFileArchive遍历并过滤出内嵌JAR包,过滤的条件是以"BOOT-INF/"开头的文件,即JAR包中的业务代码和依赖。这一步通过JarFileEntries.EntryIterator实现。然后获取每个内嵌JAR包的URL。图一“URL”虚线框中示意了URL的三个关键初始化参数:
图一“LaunchedURLClassLoader 初始化”虚线框示意了LaunchedURLClassLoader在初始化时,会初始化一个URLClassPath,URLClassPath的一个入参就是所有内嵌JAR包的URL,即指定了LaunchedURLClassLoader会在这些URL中搜索并加载需要的类。
5.2 类加载实现
LaunchedURLClassLoader重写了父类的loadClass(String name, boolean resolve)方法。LaunchedURLClassLoader类加载器依然遵循了双亲委派模式,在重写的方法体中,通过super.loadClass(name, resolve)交由父类完成类加载。跟读源码发现,最终通过java.net.URLClassLoader.findClass(final String name)来完成类加载。findClass方法是通过URLClassPath$Loader.getResource来加载目标文件和资源的。由于内嵌JAR包不是标准的JAR包,无法通过URLClassPath$JarLoader(JarLoader是Loader的一个子类,另一个子类是FileLoader)来加载JAR包中的文件和资源,所以Spring Boot Loader扩展了“JAR URL协议”。
6. JAR URL协议扩展
URLClassPath是通过URLClassPath$Loader来完成资源读取。URLClassPath$Loader是URLClassPath私有内部类,两个子类分别是:
URLClassPath内部通过“getLoader(final URL var1)”来生成Loder。根据getLoader的实现源码和URL的属性可知,Spring Boot Loader通过扩展URLClassPath$Loader来完成内嵌JAR包文件和资源的读取。请注意:这里不是通过继承URLClassPath$Loader来扩展,而是通过实现自定义的java.net.URLStreamHandler和java.net.JarURLConnection来扩展。
图一“LaunchedURLClassLoader类加载过程”虚线框示意了类加载过程中涉及的核心类。
6.1 Handler
Handler,即org.springframework.boot.loader.jar.Handler,是java.net.URLStreamHandler的实现。如果URL中没有提供默认的URLStreamHandler实现,URL会自动寻找与当前URL协议匹配的Handler。如何实现自动寻找?两种途径:
JarFile虽然在初始化每个URL时提供了自定义Handler的对象,但JarLauncher在启动过程中,依然在“java.protocol.handler.pkgs”属性中注册了org.springframework.boot.loader.jar.Handler的类路径。源码如下:
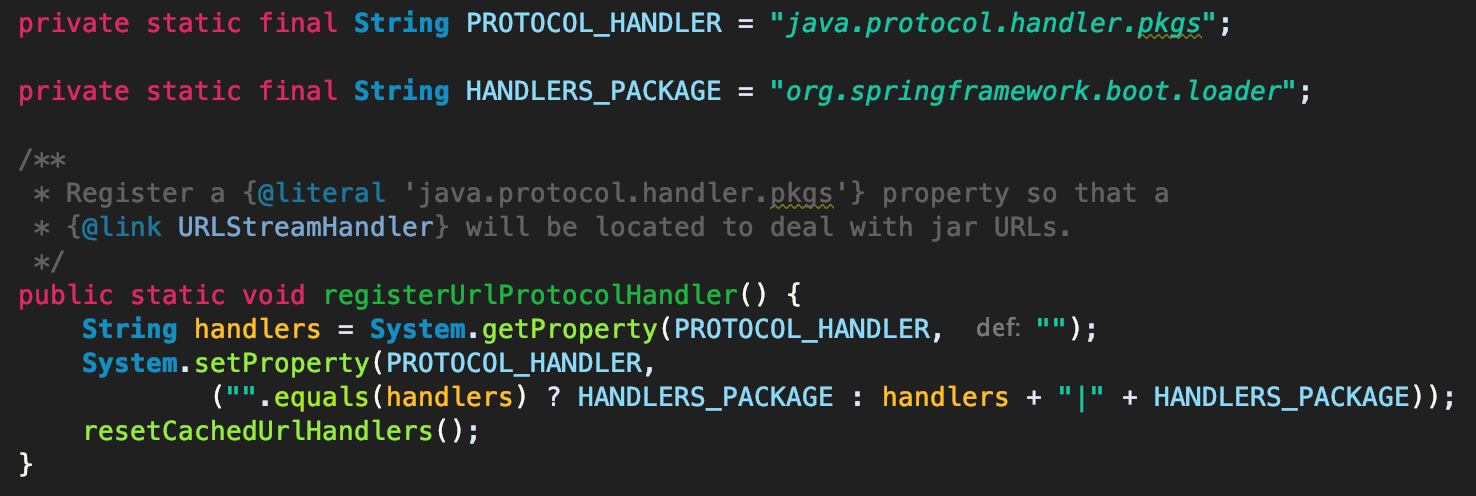
请注意,这里注册的类路径“org.springframework.boot.loader”不是完成的类路径。因为URL在加载自定义Handler时,通过“String clsName = packagePrefix + "." + protocol + ".Handler"”来拼接目标Handler的类路径。从该JDK源码可以看出,如果要实现java.net.URLStreamHandler,实现类的名称必须是Handler,且包路径的结尾必须是对应的protocol。你觉得JDK这种实现,是最优的方式嘛?
6.2 JarURLConnection
JarURLConnction,即org.springframework.boot.loader.jar.JarURLConnection,继承了java.net.JarURLConnection。Handler通过“openConnection(URL url)”获取JarURLConnection。JarURLConnection主要的功能是生成一个JarEntry,由于Handler中的JarFile是内嵌JAR,即外部JAR包中的一个文件,通过初始化一个JarEntry指向该内嵌JAR,便可通过JarEntry中的localHeaderOffset属性,来读取目标类的二进制数据。
6.3 InputStream
这里的InputStream包括了org.springframework.boot.loader.data.RandomAccessDataFile$DataInputStream和org.springframework.boot.loader.jar.ZipInflaterInputStream。DataInputStream是RandomAccessDataFile的内部类,同时继承了java.io.InputStream,可以理解为定义了一个JarFile的输入流。
ZipInflaterInputStream继承了java.util.zip.InflaterInputStream。InflaterInputStream用来解压“deflate”格式(deflate算法是ZIP压缩文件的默认算法)的压缩数据。由于JAR包的类文件是被压缩的文件,这里封装了ZipInflaterInputStream用来解压目标类的class文件。
7. 为什么要造轮子?
这要从“打包”说起。
7.1 构建
Java世界中,打包是软件构建的重要一环。通过构建工具(Ant、Maven、Gradle等),可以方便的对Java工程进行构建,包括编译、测试、打包、分发、部署等等。Java工程打包之后生成的JAR包,可细分为Uber-JAR(亦称之为Fat-JAR、JAR with dependencies)和非Uber-JAR。Fat-JAR包中不仅包含了业务代码,同时还包含了所有的依赖。
7.2 打包过程中的问题
Fat-JAR在打包过程会遇到一些问题,举两个场景:
以Maven为例,对比各种Fat-JAR打包方式的实现和优缺点:
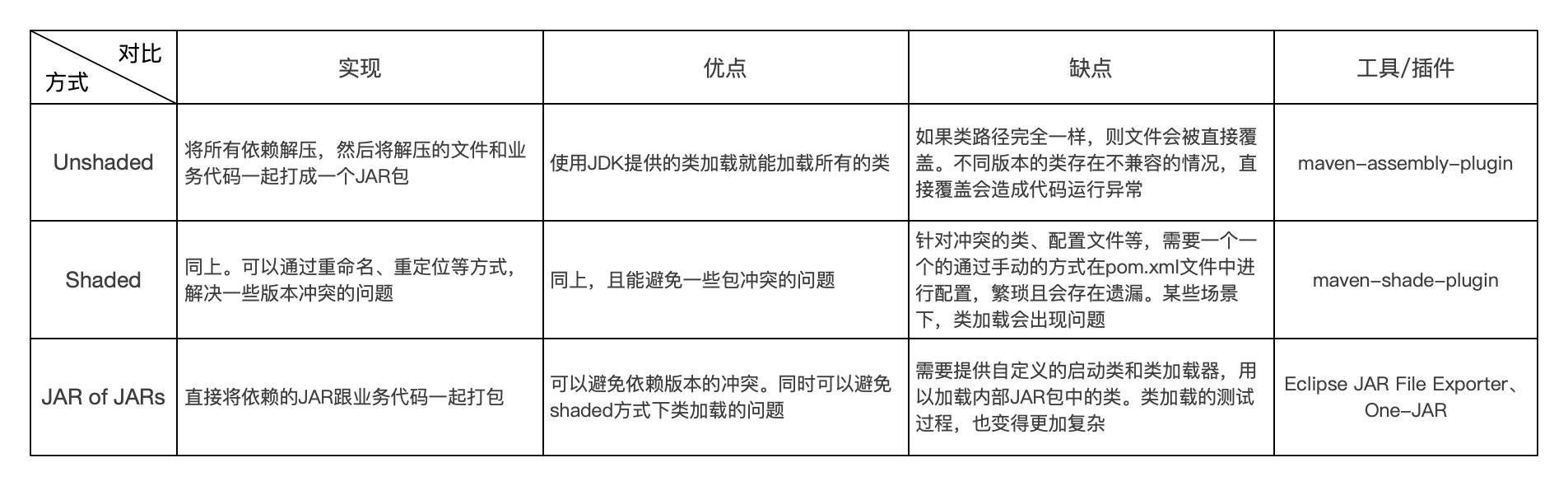
Unshaded和Shaded都会先解压依赖的JAR包,解压的文件会根据完整的类路径名称生成文件夹和文件。注意,这里的路径不会包含JAR包的版本信息。shade翻译过来就是影子,Shaded的打包方式,直白一点可以理解为通过重命名或者重定位方式,给冲突的文件,创建一个影子路径(即路径或者文件名的别名)。针对同名的配置文件,Shaded可以设置合并同名的配置文件,即同名配置文件中的配置,会追加到同一个文件中。如果配置文件中,有两个相同的key,则两个配置都会保留,但读取的是最后一条记录。这个在Spring Boot中是有问题的。
Spring Boot的一个重要特性是“自动配置”,它通过读取META-INF/spring.factories中“org.springframework.boot.autoconfigure.EnableAutoConfiguration”的配置,实现目标类自动装载到Spring容器中。如果采用Shaded的方式简单合并配置文件,则大量自动装载的类将得不到装载,应用启动会失败。如果Spring Boot要采用maven-shaded-plugin插件来打包,则依然需要使用到spring-boot-maven-plugin中提供的“org.springframework.boot.maven.PropertiesMergingResourceTransformer”来正确的合并META-INF/spring.factories中的配置。
8. 总结和后记
一句话总结Spring Boot可执行JAR原理:为了支持Spring Boot的新特性和规避“shade style jars”的问题,采用“JAR of JARs”的Fat-JAR打包方式,同时根据ZIP包的二进制格式,直接计算并读取JAR包中各文件的偏移量和二进制数据,扩展“JAR URL”协议,实现不解压且高效地加载内嵌JAR包中的类。
附一个笔者写的任意读取ZIP文件的工具类:
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* Created by durianskh@gmail.com on 2020-04-16 16:29
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
public class CDHeader {
/**
* 0 - The file is stored (no compression)
* 1 - The file is Shrunk
* 2 - The file is Reduced with compression factor 1
* 3 - The file is Reduced with compression factor 2
* 4 - The file is Reduced with compression factor 3
* 5 - The file is Reduced with compression factor 4
* 6 - The file is Imploded
* 7 - Reserved for Tokenizing compression algorithm
* 8 - The file is Deflated
* 9 - Enhanced Deflating using Deflate64(tm)
* 10 - PKWARE Data Compression Library Imploding (old IBM TERSE)
* 11 - Reserved by PKWARE
* 12 - File is compressed using BZIP2 algorithm
* 13 - Reserved by PKWARE
* 14 - LZMA
* 15 - Reserved by PKWARE
* 16 - IBM z/OS CMPSC Compression
* 17 - Reserved by PKWARE
* 18 - File is compressed using IBM TERSE (new)
* 19 - IBM LZ77 z Architecture (PFS)
* 96 - JPEG variant
* 97 - WavPack compressed data
* 98 - PPMd version I, Rev 1
* 99 - AE-x encryption marker (see APPENDIX E)
*/
private int compressionMethod;
private int compressedSize;
private int uncompressedSize;
private int fileNameLength;
private int extraFieldLength;
private int fileCommentLength;
private String fileName;
/**
* The number of the disk on which this file begins
*/
private int diskNumStart;
/**
* This is the offset from the start of the first disk on
* which this file appears, to where the local header SHOULD
* be found.
*/
private int relativeOffsetOfLocalHeader;
private int absolutionPosition;
private byte[] headBytes;
private int curHeadLength;
private int entryLength;
}
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* Created by durianskh@gmail.com on 2020-04-16 14:38
*
* CD = Central Directory
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
public class EndCDRecord {
/**
* The number of this disk, which contains central directory end record
*/
private int curDisNum;
/**
* The number of the disk on which the central directory starts
*/
private int diskNumCDStarts;
/**
* The total number of files in the .ZIP file
*/
private int totalEntries;
/**
* The size (in bytes) of the entire central directory
*/
private int curCDLength;
/**
* Offset of the start of the central directory on the disk on which the central directory starts
*/
private int diskOffsetCDStarts;
}
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* Created by durianskh@gmail.com on 2020-04-17 09:30
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
public class LocalHeaderAndFileData {
private int compressionMethod;
private int compressedSize;
private int uncompressedSize;
private int fileNameLength;
private int extraFieldLength;
private String fileName;
private byte[] fileData;
}
import java.io.RandomAccessFile;
import java.util.Arrays;
import java.util.Map;
import static me.durianskh.demo.jarfile.springboot.util.ByteUtil.bytesToInt;
import static me.durianskh.demo.jarfile.springboot.util.ByteUtil.extraBytes;
/**
* Created by durianskh@gmail.com on 2020-04-17 09:21
*
* https://pkware.cachefly.net/webdocs/casestudies/APPNOTE.TXT
*/
public class ZipUtil {
private static final String CLASS_ENTRY = ".class";
private static final String JAR_ENTRY = ".jar";
public static final int EXTHDR = 16; // EXT header size
public static final int LOCHDR = 30; // LOC header size
public static final int CENHDR = 46; // CEN header size
public static final int ENDHDR = 22; // END header size
public static EndCDRecord genEndCDRecord(byte[] bytes) {
return EndCDRecord.builder()
.curCDLength(bytesToInt(bytes, 12, 4))
.curDisNum(bytesToInt(bytes, 4, 0))
.diskNumCDStarts(bytesToInt(bytes, 6, 2))
.diskOffsetCDStarts(bytesToInt(bytes, 16, 4))
.totalEntries(bytesToInt(bytes, 8, 2))
.build();
}
public static void extractCDHeaders(Map CD_HEADERS, RandomAccessFile raf,
int absolutePosition, long totalHeaders, byte[] bytes) throws Exception {
int relativePosition = 0;
for (int i = 0; i < totalHeaders; i++) {
CDHeader cdHeader = genCDHeader(bytes, relativePosition, absolutePosition);
if (cdHeader.getFileName().endsWith(CLASS_ENTRY)) {
CD_HEADERS.put(cdHeader.getFileName(), cdHeader);
} else if (cdHeader.getFileName().endsWith(JAR_ENTRY)) {
// there is no nested jar in nested jar
byte[] targetBytes = extraBytes(raf, cdHeader.getRelativeOffsetOfLocalHeader(), cdHeader.getEntryLength());
LocalHeaderAndFileData localHeaderAndFileData = genLocalHeaderAndFileData(targetBytes, cdHeader.getCompressedSize());
byte[] entryData = localHeaderAndFileData.getFileData();
int entryDataLength = entryData.length;
EndCDRecord nestEndCDRecord = genEndCDRecord(Arrays.copyOfRange(entryData,
entryDataLength - ENDHDR, entryDataLength));
int nestCDLength = nestEndCDRecord.getCurCDLength();
int nestCDHeadersLength = nestCDLength + ENDHDR;
absolutePosition = cdHeader.getRelativeOffsetOfLocalHeader() + LOCHDR + localHeaderAndFileData.getFileNameLength()
+ localHeaderAndFileData.getExtraFieldLength();
extractCDHeaders(CD_HEADERS, raf, absolutePosition, nestEndCDRecord.getTotalEntries(),
Arrays.copyOfRange(entryData, entryDataLength - nestCDHeadersLength, entryDataLength - ENDHDR));
}
relativePosition += cdHeader.getCurHeadLength();
}
}
public static CDHeader genCDHeader(byte[] bytes, int relativePosition, int absolutePosition) {
CDHeader cdHeader = CDHeader.builder()
.compressionMethod(bytesToInt(bytes, relativePosition + 10, 2))
.compressedSize(bytesToInt(bytes, relativePosition + 20, 4))
.uncompressedSize(bytesToInt(bytes, relativePosition + 24, 4))
.fileNameLength(bytesToInt(bytes, relativePosition + 28, 2))
.extraFieldLength(bytesToInt(bytes, relativePosition + 30, 2))
.fileCommentLength(bytesToInt(bytes, relativePosition + 32, 2))
.diskNumStart(bytesToInt(bytes, relativePosition + 34, 2))
.relativeOffsetOfLocalHeader(bytesToInt(bytes, relativePosition + 42, 4))
.absolutionPosition(absolutePosition)
.build();
cdHeader.setFileName(new String(Arrays.copyOfRange(bytes, relativePosition + CENHDR,
relativePosition + CENHDR + cdHeader.getFileNameLength())));
int headLength = CENHDR + cdHeader.getFileNameLength() + cdHeader.getExtraFieldLength() + cdHeader.getFileCommentLength();
cdHeader.setHeadBytes(Arrays.copyOfRange(bytes, relativePosition, relativePosition + headLength));
cdHeader.setCurHeadLength(headLength);
int entryLength = LOCHDR + cdHeader.getFileNameLength() + cdHeader.getExtraFieldLength() + cdHeader.getCompressedSize() + EXTHDR;
cdHeader.setEntryLength(entryLength);
return cdHeader;
}
public static LocalHeaderAndFileData genLocalHeaderAndFileData(byte[] entryBytes, int compressedSize) {
LocalHeaderAndFileData header = LocalHeaderAndFileData.builder()
.compressionMethod(bytesToInt(entryBytes, 8, 2))
.compressedSize(bytesToInt(entryBytes, 18, 4))
.uncompressedSize(bytesToInt(entryBytes, 22, 4))
.fileNameLength(bytesToInt(entryBytes, 26, 2))
.extraFieldLength(bytesToInt(entryBytes, 28, 2))
.build();
header.setFileName(new String(Arrays.copyOfRange(entryBytes, LOCHDR, LOCHDR + header.getFileNameLength())));
int headerLength = LOCHDR + header.getFileNameLength() + header.getExtraFieldLength();
header.setFileData(Arrays.copyOfRange(entryBytes, headerLength, headerLength + compressedSize));
return header;
}
}