[论文分享]VulDeePecker:基于深度学习的漏洞检测技术
本文分享一篇基于深度学习的面向源代码的漏洞检测方法。论文:
Li Z, Zou D, Xu S, et al. Vuldeepecker: A deep learning-based system for vulnerability detection[J]. arXiv preprint arXiv:1801.01681, 2018.
本文主要介绍论文中提到的基于深度学习的漏洞检测的数据处理和训练方法。前后综述部分,做了很大的简化,这部分可关注源论文。
1. 论文意义
传统的静态代码分析技术,不管是基于代码结构的结构化规则还是基于数据流和信息流的规则,很大程度上,依赖了安全专家定制的检查规则(feature),但是,这种定制很烦人,而且很受专家的主观性影响,因此会产生比较高的误报和漏报。误报太高,则该检查工具可认为不可用,漏报太高,则该检查工具也没有使用的必要了。
面向深度学习的静态代码分析,可以通过机器自动学习,不受专家的主观性影响,误报和漏报会有更高的优化(暂时保留意见)。
2. 论文方法实现
2.1 指导原则
面向机器学习实现,主要的步骤包括 数据收集、数据预处理、特征选择、数据向量化、选择合适的算法进行训练、预测等步骤。该论文中,汇总了三部分内容:
(1) 怎么表示程序代码?(数据收集、数据预处理、数据向量化)
(2) 适合的学习粒度?(特征选择)
(3) 选择合适的深度学习算法?(合适的算法进行训练)
上面这三部分内容就不详细介绍,下面介绍论文的VulDeePecker的实现时,上面这部分内容也就自然都解答了。
2.2 VulDeePecker设计实现
2.2.1 代码数据收集
VulDeePecker 数据收集部分如下图所示:
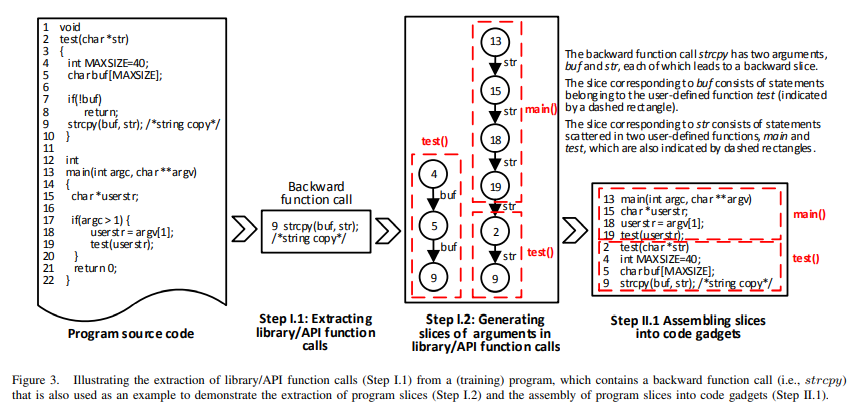
在数据收集阶段,主要有如下的几个步骤:
(1) 抽取代码中库函数/API
该论文关心的是和特定的库函数及API调用相关的漏洞,因此首先抽取程序中用到的库函数和API,拿到库函数/API和传入的参数。如上面的 Step1.1,抽取出来了库函数 strcpy。
(2) 针对参数进行程序切片
获取到上一步骤抽取到的库函数,然后针对每个参数执行程序切片,如上图,Step 1.2,对参数 buf 切片,获取到第4,5, 9 三行,对 str 切片,获取到第13,15,18,19,2,9 等几行。
程序切片 的理论及相关的方法,也是一个很大的学科内容,这里不具体描述。
(3) 对切片进行汇总
如上面的 Step 1.3,将第 (2) 步中的切片数据进行汇总,最终形成 上图中最右边 的代码,如上,对 buf 和 str 切片汇总后,拿到的 13,15,18,19,2,4,5,9(按照函数进行组织)。
如上,针对一个库函数/API调用,针对每个参数进行切片,所得到的切片汇总信息,就是一个 code gadget(code gadget是原论文中,给出的一个概念,但是在概念定义的时候,非常抽象,这里以例子方式,给出 code gadget 的具体含义)。
2.2.2 code gadget 打标签
实际上,针对特定的一个库函数/API调用,可能会因为使用不当,产生一个缺陷。而这种情况下的缺陷产生,就是这个 特定的库函数/API + 参数信息 共同作用产生的。因此通过上面的方法,提取出和该缺陷相关的所有的代码组合,就组成了一个缺陷学习所需要的代码信息,因此,一个 code gadget 就是一个缺陷检查所需的所有信息的汇总。
针对上一步收集到的 code gadget(针对特定库函数/API调用的参数切片汇总数据),标记上是否有缺陷(0 或者 1),实际上,就是对 code gadget 打标签,标记是否存在缺陷。
通过上面的两个阶段,就形成了一个 code gadget -> 是否存在缺陷 的映射,自然,学习的内容就是特定的 code gadget 是否存在缺陷?
2.2.3 数据预处理
论文中,对数据预处理有下面的几个步骤的操作:

如上箭头所示的方向,主要做了三件事情:
(1) 去掉注释等和代码无关的信息(如上,去掉了第9行的注释);
(2) 变量名映射,消除用户自定义命名对训练结果的影响(如上,将userstr 映射为 VAR1等);
(3) 函数名映射,消除用户自定义命名对训练结果的影响(如上,将test 映射为 FUN1等)。
因为 code gadget 是训练单位,因此,不同的 code gadget 中,映射后的命名,是可以重复的。
2.2.4 数据向量化
论文中,对 code gadget 向量化,做了两件事情:
(1) 语句 token 化
code gadget 还是由不同的 stmt 组成的,对 每一个 stmt 执行 词法分析,拿到每个 token。
例如 strcpy(VAR5, VAR2); token化后,就是一个序列 ['strcpy', '(', 'VAR5', ',', 'VAR2', ')', ';']。
(2) 使用 word2vec 转为 vector
word2vec 是一个非常典型的 语句 向量化 的方法。使用非常广泛。
标签本身只是是否有缺陷,因此 0 和 1 就可以表示。
(3) 向量长度转为固定长度
训练时,采用的深度学习算法只能对同样长度的向量进行训练。但是提取出来的切片长度并不是总是相同的,因此需要将数据处理为相同固定长度。
当向量小于设置的固定长度时,有两种情况:如果code gadget是基于后向切片生成的,就在向量的开头填充零;否则,将向量的末尾插零;
当向量长度大于固定长度时,也有两种情况:如果code gadget是基于后向切片生成的,就删除向量的开始部分;否则,删除向量的结尾部分。
2.2.5 基于神经网络算法训练
论文使用的是 BLSTM神经网络 算法,主要原因是,代码切片后,切片是具有上下文关系的,因此至少也需要使用 RNN 训练,LSTM 算是 RNN 中更优秀的一个算法。这部分其实没什么好介绍。其实 从 word2vec 转换为向量后,就是纯 机器学习 领域的内容了。
2.2.5 总体设计流程
论文中,这部分放在最前面,这里放在最后面,先对前面进行分步骤介绍:
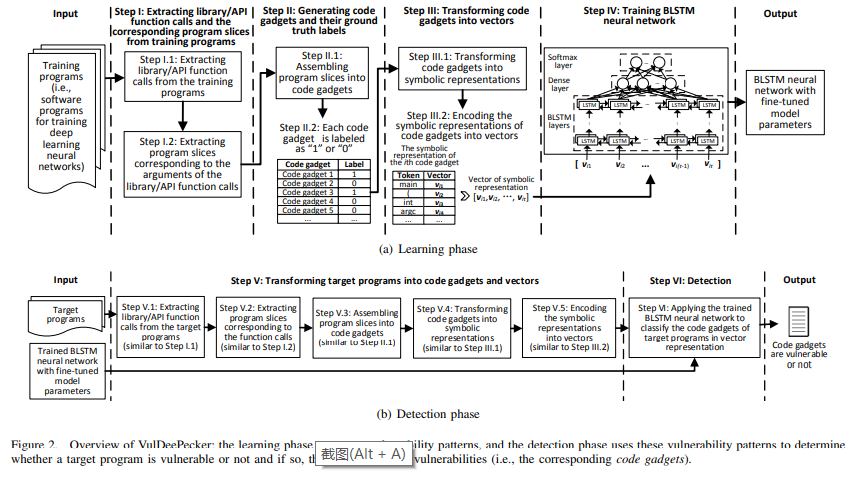
上面在设计实现步骤组织时,没有按照论文里面划分步骤介绍,而是按照一般机器学习的实现顺序进行介绍的,但是步骤没有差别。
3. 实验结果
这里,并不堆砌原论文的结果。主要介绍一下部分原论文给的结果:
(1) 这种基于学习的静态检测方法,效果杠杠的,比有些传统静态代码分析工具能力更强;
(2) 结合专家的先验知识,效果更佳,比如已知某类缺陷只跟特定的某几个 库函数/API 相关,则可以根据配置只训练和预测这几个特定的 库函数/API,其他的调用就可以忽略;
(3) 该算法对多种不同的缺陷都适用(可以理解:这种方法对 基于 静态数据流分析切片 + 特定 库函数/API 调用 类型的缺陷,应该都是 适用的,毕竟检查的机制也类似);
(4) 检查效果和不同的 dataset 相关(这里,论文中,主要是指 只有一类缺陷的 dataset 和 包含多种缺陷的 dataset 对比)。
该论文是一篇非常典型的基于机器学习方法,进行面向源代码的静态代码分析 的尝试,对于 之后做的 各种基于 机器学习 的 面向源代码的静态代码分析 的研究,有非常好的示范效果。
另外,也可以考虑到一点:
在上面的基于 机器学习 的 实现中,也用到了 静态代码分析的技术,当前主要有 基于 静态代码分析的程序切片、词法分析 及 先验知识。因此,基于 传统静态代码分析 结合 机器学习 的,静态代码分析,会是一个趋势(只看以哪个为主了)。