HashMap源码总结
线索:
1. HashMap结构、理解散列表;
2. 理解散列函数;
3. HashMap是如何确定下标的;
4. equals和hashCode规范
5. size、capacity、threshold、loadFactor
6. 树化与反树化
7. 谈谈HashMap 在并发环境可能出现无限循环占用 CPU、size 不准确等诡异的问题。
// 阅读时重点阅读putVal(),初始化、扩容、树化都与它有关。
1. HashMap的整体结构:Node
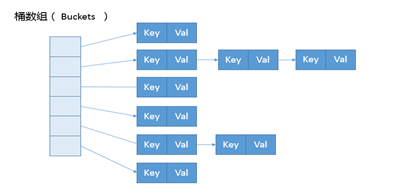
注意,链表并非散列表必要的组成部分,当散列冲突的解决方案采用线性探测或单链表改造为红黑树时,可以没有链表。
散列表是利用数组根据下标随机访问的特性,可以说,没有数组就没有散列表。
通过散列函数映射key到数组下标,取余本身就是一个散列函数,x%y=z,可以发现,z的范围是[0,y-1]。
设计一个散列函数,至少要满足三个要求:
散列函数计算得到的散列值是一个非负整数;
如果 key1 = key2,那 hash(key1) == hash(key2);
如果 key1 ≠ key2,那 hash(key1) ≠ hash(key2)。
不过,第三点无法满足,这就是散列冲突。散列冲突无法避免。因为100个抽屉放101只鸽子,就必然会发生冲突。解决散列冲突的方法有:开发寻址法和链表法。
但无论哪种方法,
我们确保以下公式恒成立:
size < threshold
threshold = loadFactor * capacity
if (++size > threshold)
resize(); // 2倍可以看到,容量和负载因子决定了可用桶的数量,空桶太多会浪费空间,如果使用的太满则会严重影响操作的性能。极端情况下,假设只有一个桶,那么它就退化成了链表。可以说散列表的好坏与容量、负载因子密切相关。
因此,在实践中,如果能事先知道 HashMap 要存取的键值对数量,可以考虑预先设置合适的容量大小,减少动态扩容的次数,从而提升性能。依据:负载因子 * 容量 > 元素数量;且容量要是2的幂次方。
而对于负载因子,如果没有特别需求,不要轻易进行更改,因为 JDK 自身的默认负载因子是非常符合通用场景的需求的。
3. HashMap源码总结。
1. Lazy-Load
Node
HashMap构造器并不初始化数组,对数组的初始化在resize()中。put-->putVal-->resize()。即,resize()兼顾扩容和对数组的初始化。
2. 总结。
①HashMap默认capacity=16,loadFactor=0.75F,因此threshold=12
②扩容是扩大2倍。// newCap = oldCap << 1、newThr = oldThr << 1; // double threshold
③数组搬迁由于 数组容量 变了,因此需要重新计算下标。然后再将旧数组中的元素搬迁到新数组。
④HashMap解决散列冲突的方法是:链表+红黑树。当某个桶的链表长度超过TREEIFY_THRESHOLD(默认8),且散列表容量超过MIN_TREEIFY_CAPACITY(64),则会进行树化。当红黑树节点好于8个时,又会反树化成链表。
⑤HashMap为什么要树化?
这本质上是一个安全问题。首先,哈希冲突的对象都会被放到同一个链表中,链表查询的复杂度是O(N),严重影响性能。
而在现实中,构造哈希冲突的数据并不困难,恶意代码就可以利用这些数据大量与服务器端交互,导致服务器端 CPU 大量占用,这就构成了哈希碰撞拒绝服务攻击。
而红黑树的增删查的复杂度都是O(logN),能提高HashMap 的性能。而在数据量较小的情况下,红黑树要维护平衡,比起链表,性能上的优势并不明显。
⑥树化相关代码:
static final int TREEIFY_THRESHOLD = 8;
static final int UNTREEIFY_THRESHOLD = 6;
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
p = tab[i = (n - 1) & hash];// p为第一个元素
//……
Node e; K k;
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
p = e;
}
}
final void treeifyBin(Node[] tab, int hash) {
int n, index; Node e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
//树化改造逻辑
}
}
static final int MIN_TREEIFY_CAPACITY = 64; 综合上述代码来看,当bin的数量大于TREEIFY_THRESHOLD时:// binCount就是一个桶中节点的数目
如果容量小于 MIN_TREEIFY_CAPACITY,只会进行简单的扩容。
如果容量大于 MIN_TREEIFY_CAPACITY ,则会进行树化改造。
3. HashMap如何确定元素的下标。
// putVal(hash(key), key, value, false, true);
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i;
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
} 1. 解读h^(h>>>16);
h>>>16,将h无符号右移16位。h是int类型,有32位,因此相当于是将高位移到低位。
^ 异或:a b相同,异或为1;a b 不同,异或为0
h^(h>>>16);
由于 高位^00…00,还是等于高位,然后是 高位^低位。因此上述步骤本质上只是多了一步 高位与低位异或的操作。即,
h高位……h高位^h低位
2. 解读(n-1) & hash
1AND1=1; 1AND0=0; 0AND0=1
a & b所得到的值,小于等于min(a,b),比如,0011&1101=0001,不会超过0011
一般来说,hash>(n-1),因此,(n-1) & hash 得到的结果小于等于(n-1)// 数组下标
3. 为什么要将h的高位移动到低位,并对其进行异或操作呢?
如果不这么做,而是直接&,那么高16位所代表的部分特征可能被丢失。// (n-1)< 这是因为有些数据计算出的哈希值差异主要在高位,而 HashMap 里的哈希寻址是忽略容量以上的高位的,那么这种处理就可以有效避免类似情况下的哈希碰撞。 而之所以使用异或操作,是因为异或^能更好的保留各部分的特征;而“&”运算得到的值会向0靠拢;“|”运算得到的值会向1靠拢。