极客大学架构师训练营 数据结构与算法 平衡二叉树 红黑树 动态规划 遗传算法 第15课 听课总结
说明
讲师:李智慧
数据结构与算法
时间复杂度与空间复杂度
时间复杂度
并不是计算程序具体运行的时间,而是算法执行语句的次数。
表示对n数据处理需要进行 次计算。
, , 多项式时间复杂度
和 非多项式的时间复杂度。
空间复杂度
一个算法在运行过程中临时占用存储空间大小的量度。
表示需要临时存储n个数据。
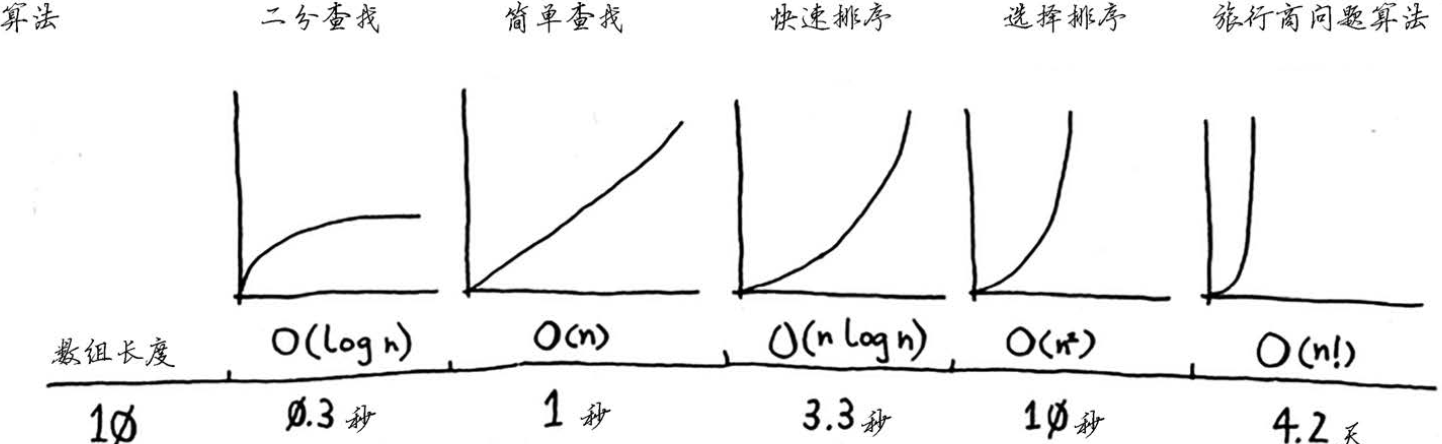
NP问题
P问题:能在多项式时间复杂度内解决的问题。
NP问题:能在多项式时间复杂度内验证答案正确与否的问题。
NP-hard 问题:比NP问题更难的问题(NP问题的解法可以规约到NP-hard问题的解法)
NP完全问题:是一个NP-hard问题,也是一个NP问题。
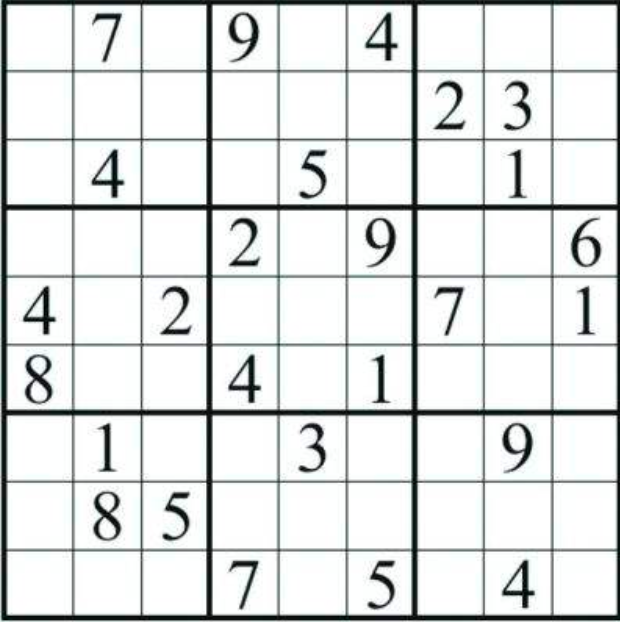
NP问题举例:数独填写,横竖都是填写不重复的1~9个数, 方块也是写的1~9个数。
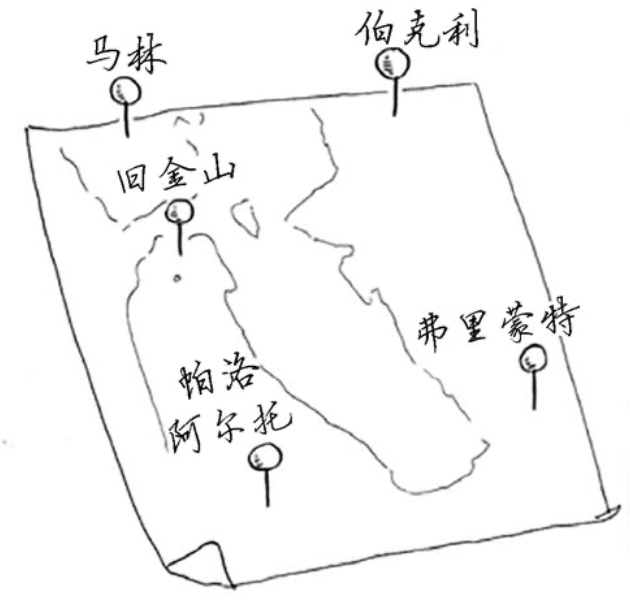
访问全部地区的最省方式。
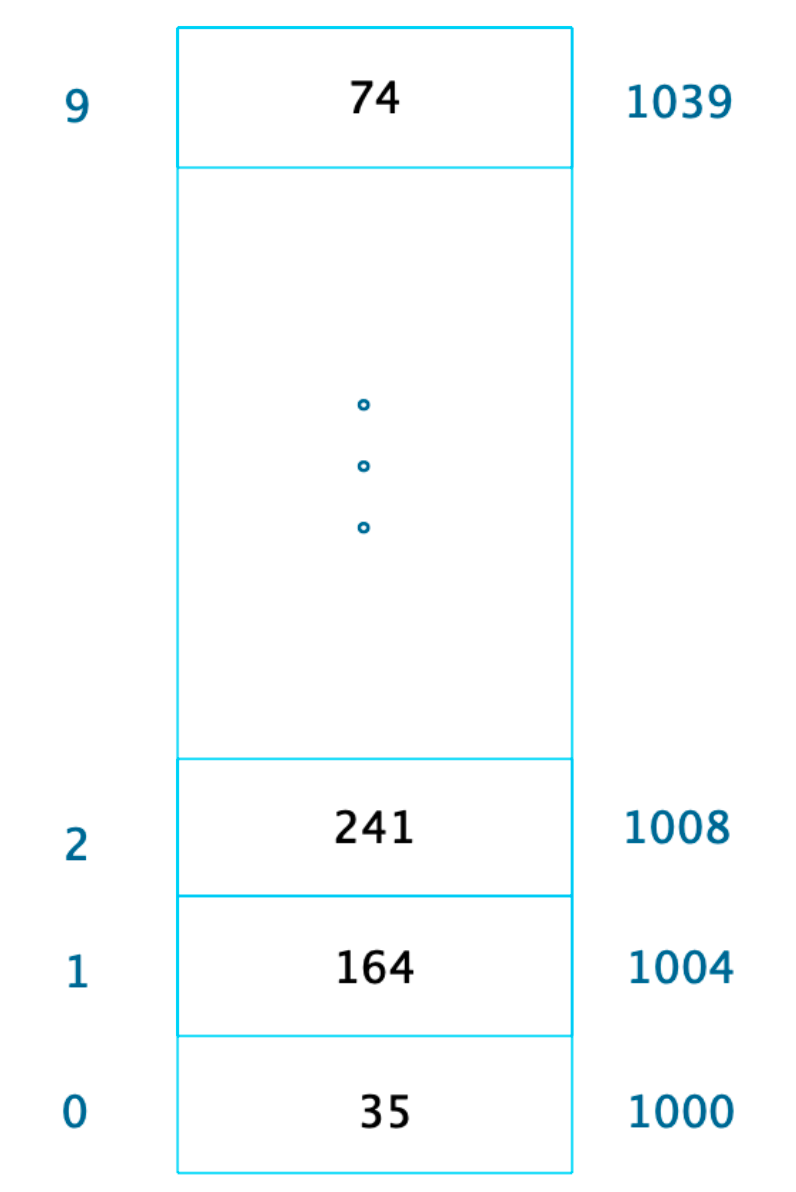
数组
创建数组必须要内存中一块连续的空间。
数组中必须存放相同的数据类型。
随机快速读写是数组的一个重要特性,根据数组的下标访问数据,时间复杂度为 O(1).
链表
链表可以使用零散的内存空间存储数据。
所以链表中的每个数据元素都必须包含一个指向下一个数据元素的内存地址指针。要想在链表中查找一个数据,只能遍历链表,所以链表的查询时间复杂度总是O(N).

链表中增删数据要比数组性能好的多
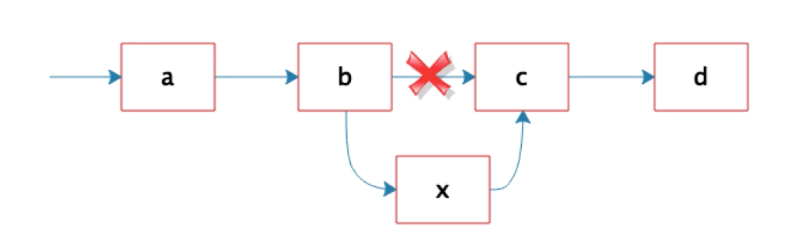
链表增删数据时间复杂度总是O(1).
数组增删数据时间复杂度总是O(N).
数组链表结合,实现快速查找和快速增删
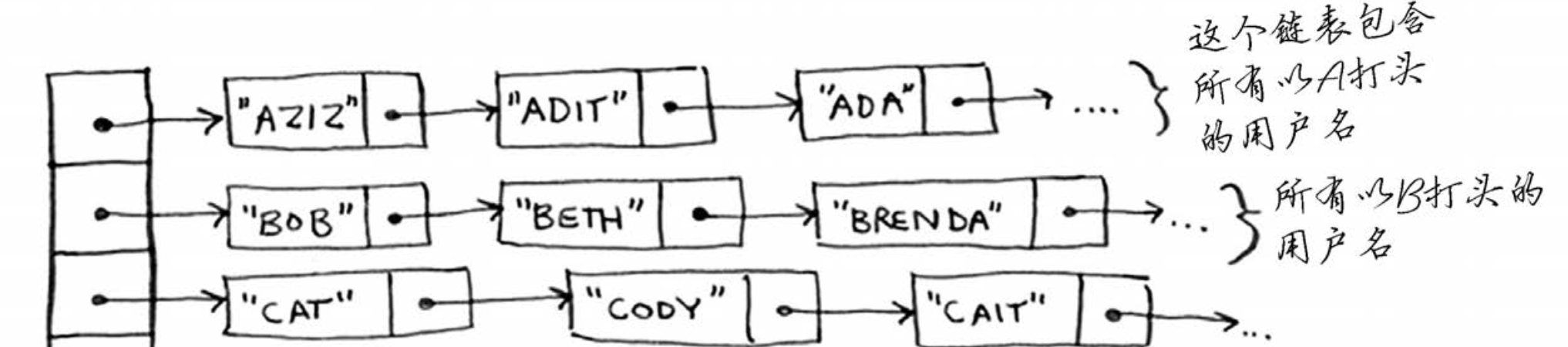
Hash 表
如何既快速访问数据,有快速增删数据?
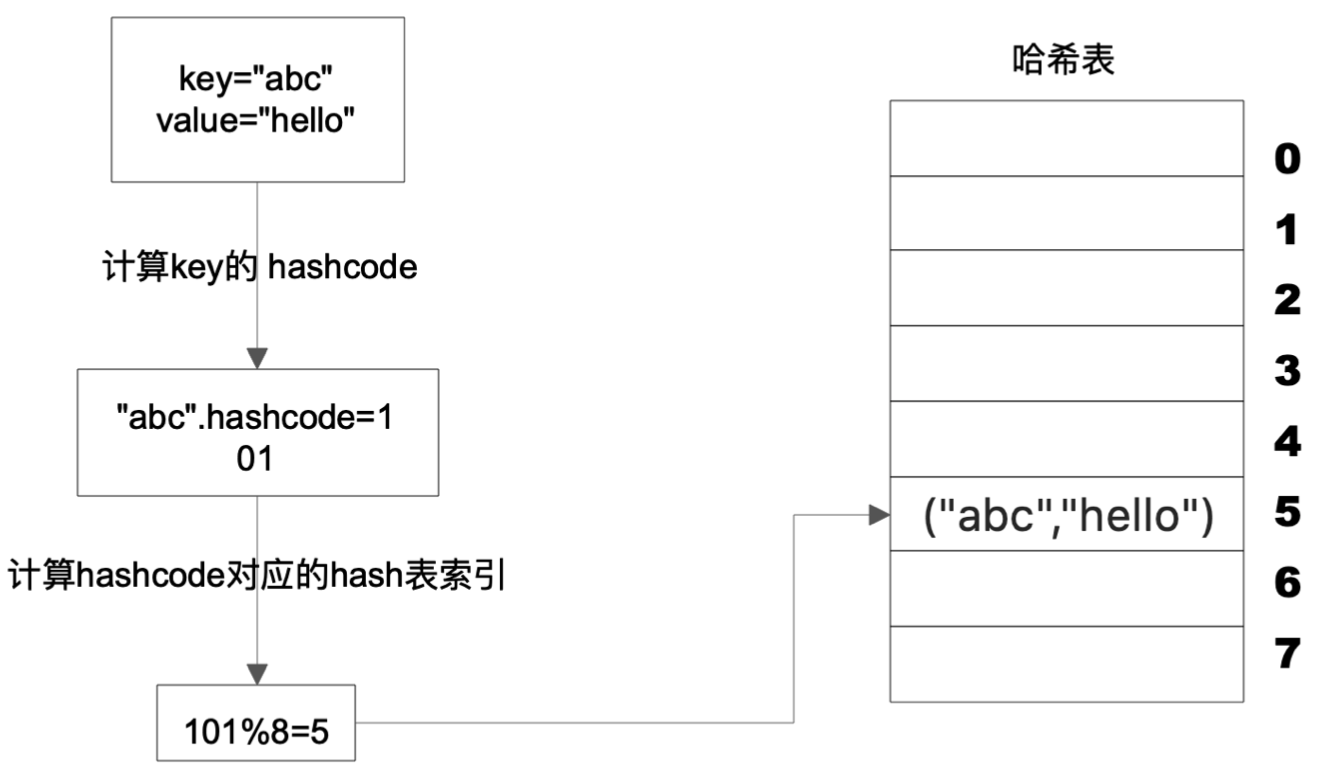
Hash表查、增、删数据时间复杂度总是O(1).
Hash 冲突
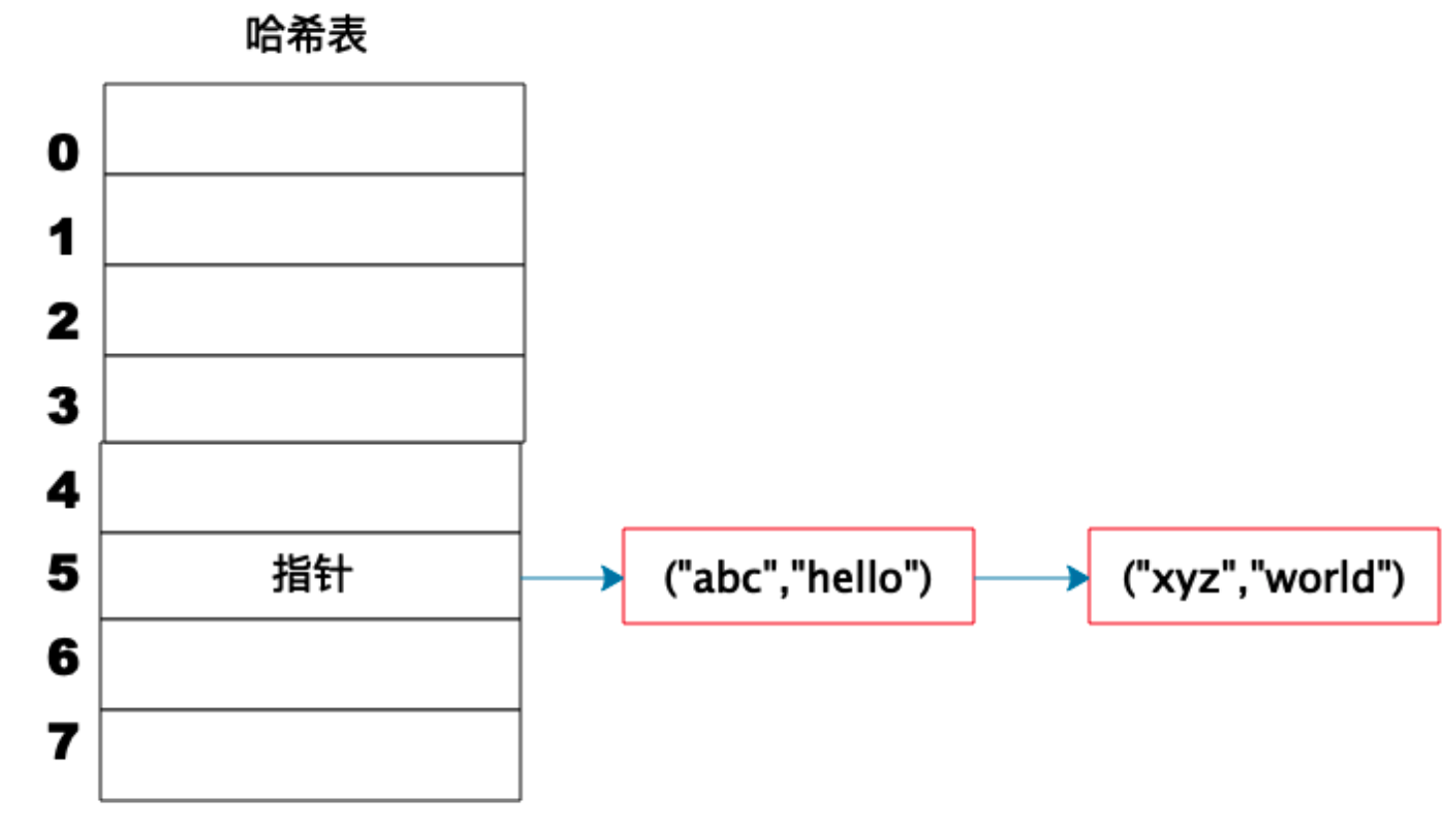
如果Hash(Key)的位置,存储不止一个值,就挨个匹配key值,取出相应的value值。
栈
数组和链表都被称为线性表。
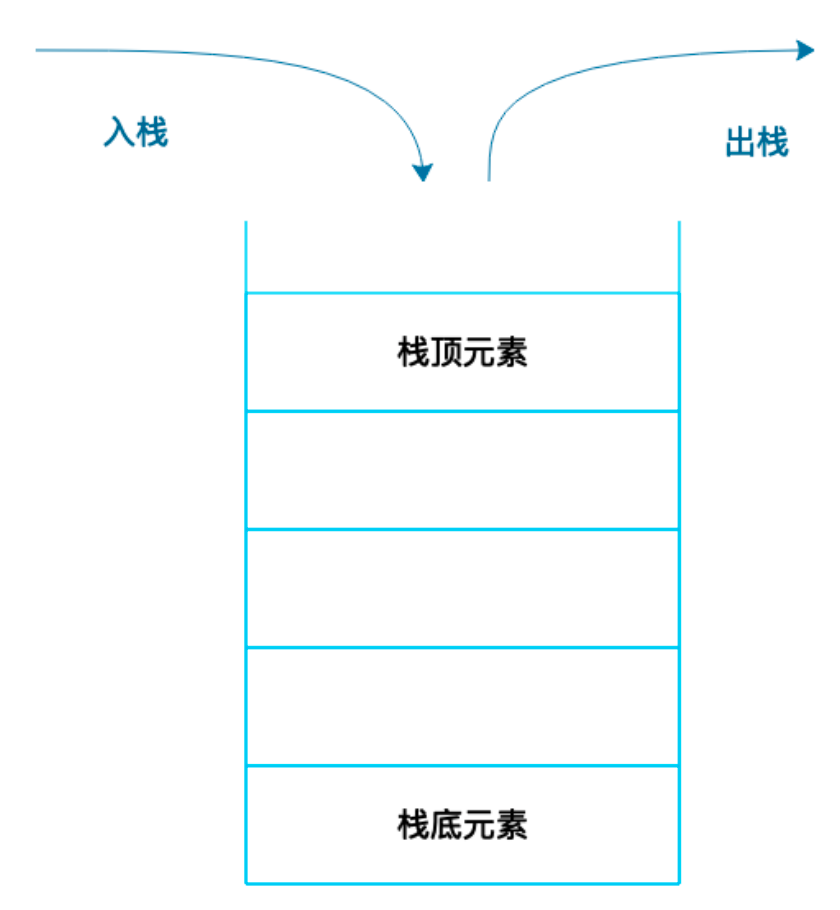
栈就是在线性表的基础上加了这样的操作限制条件:后面添加的数据,在删除的时候必须先删除,即通常所说的“后进先出”。
线程运行时专有内存为什么被称为线程栈?
线程调用栈
void f() {
int x = g(1);
x++; // g 函数返回,当前堆栈顶部为f函数栈帧,在当前栈帧继续执行f函数的代码。
}
int g(int x) {
return x + 1;
}
队列
队列也是一种受限的线性表,栈是后进先出,而队列是先进先出。
典型的应用场景:生产者消费者;阻塞等待的线程被放入队列。

用队列搜索好友中关系最近的有钱人
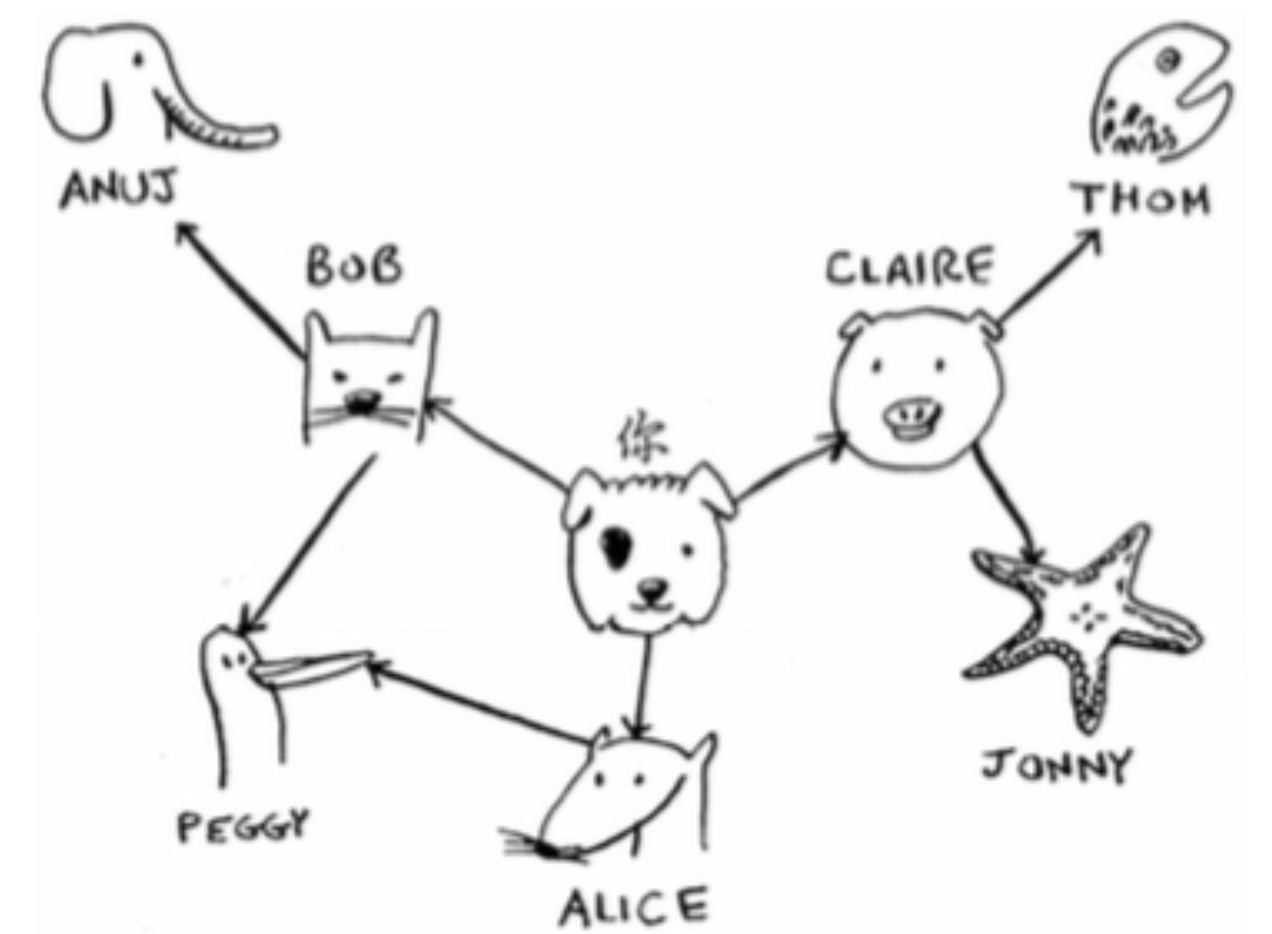
构建一个队列:
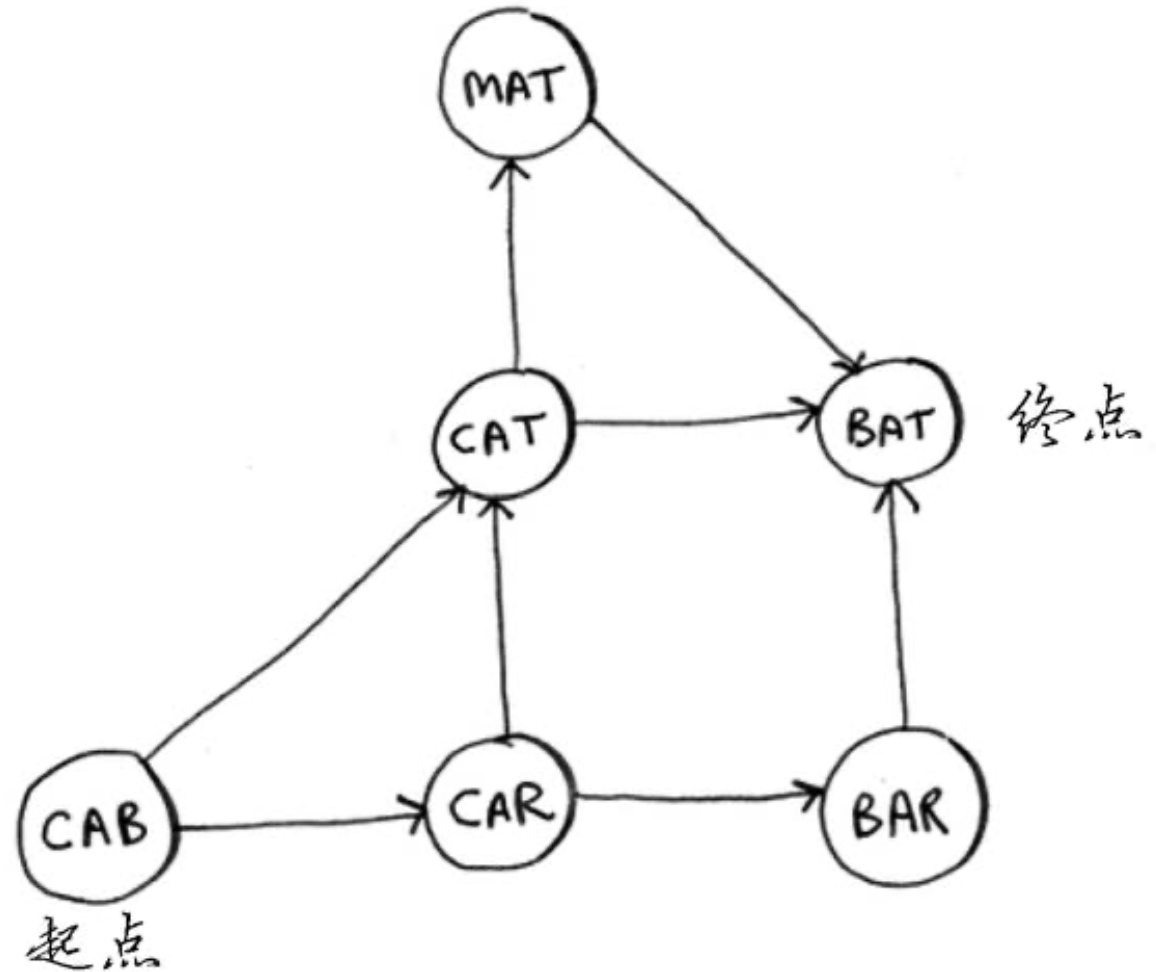
用队列搜索最短路径
树
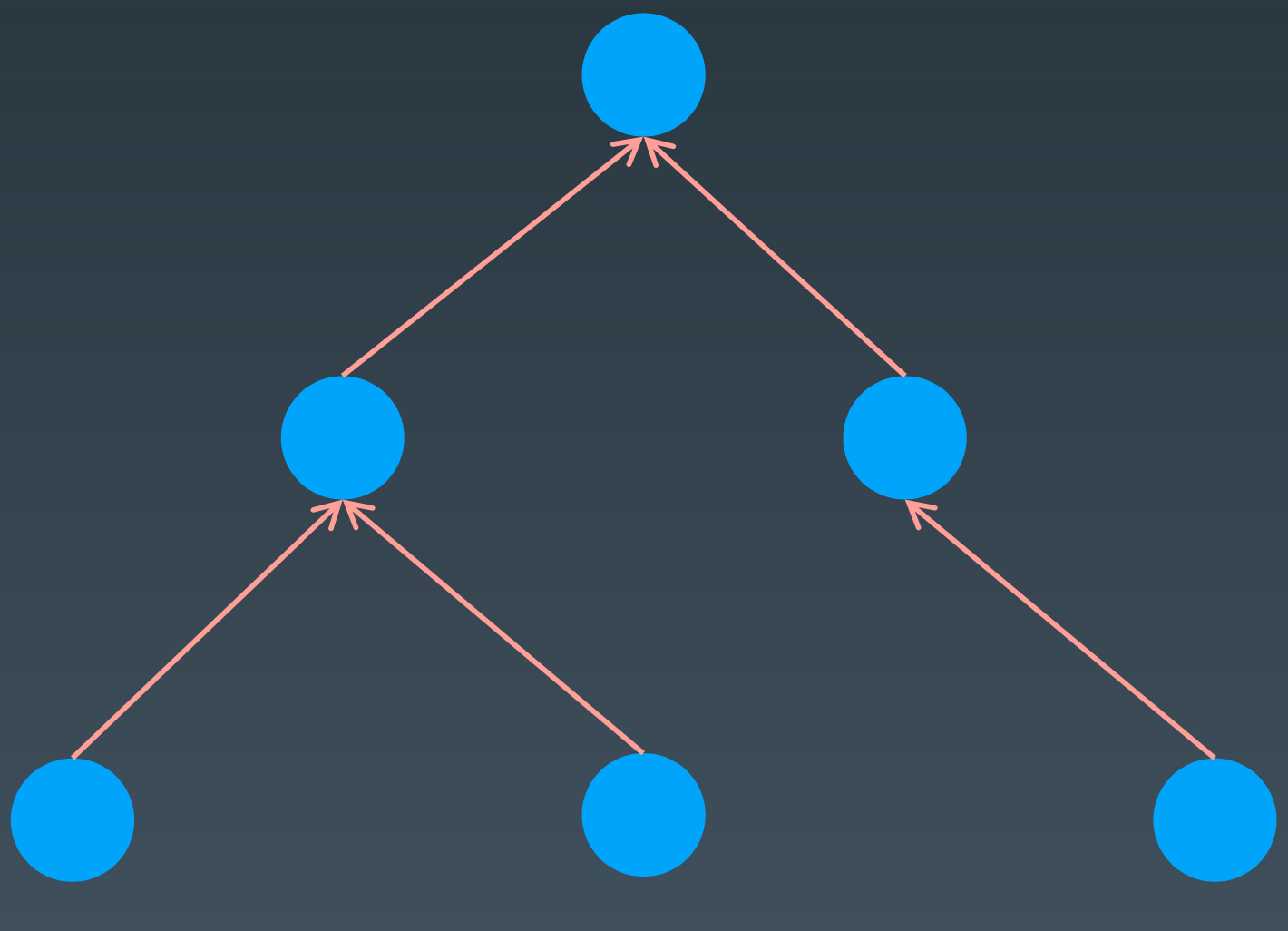
二叉排序树
左子树上所有节点的值均小于或等于它的根节点的值。
右子树上所有节点的值均大于或等于它的跟节点的值。
左、右子树也分别为二叉排序树。
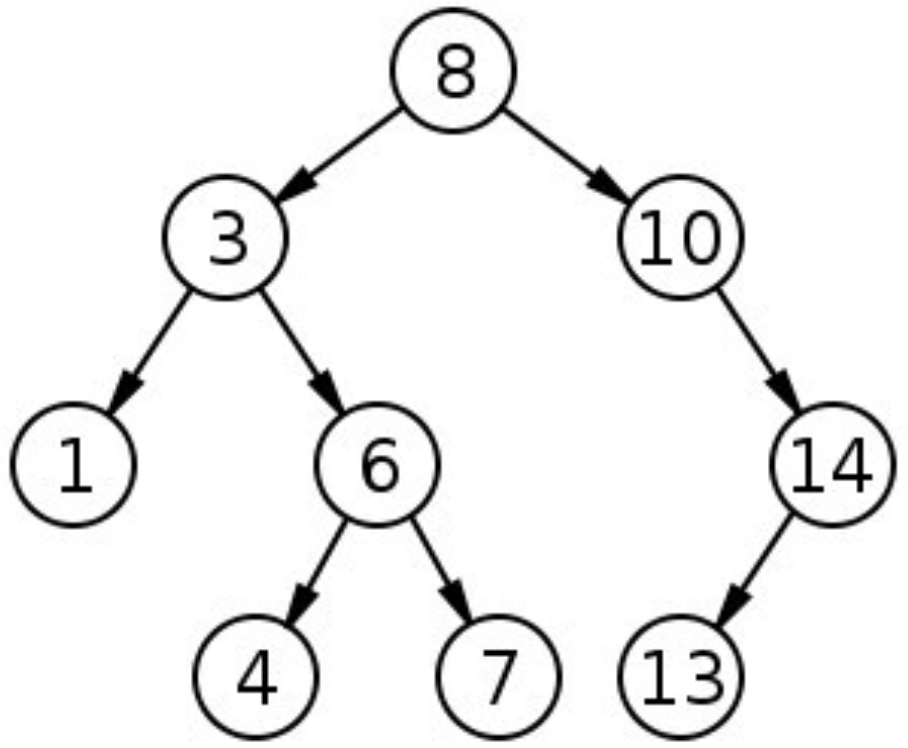
时间复杂度:O(logn)
不平衡的二叉排序树
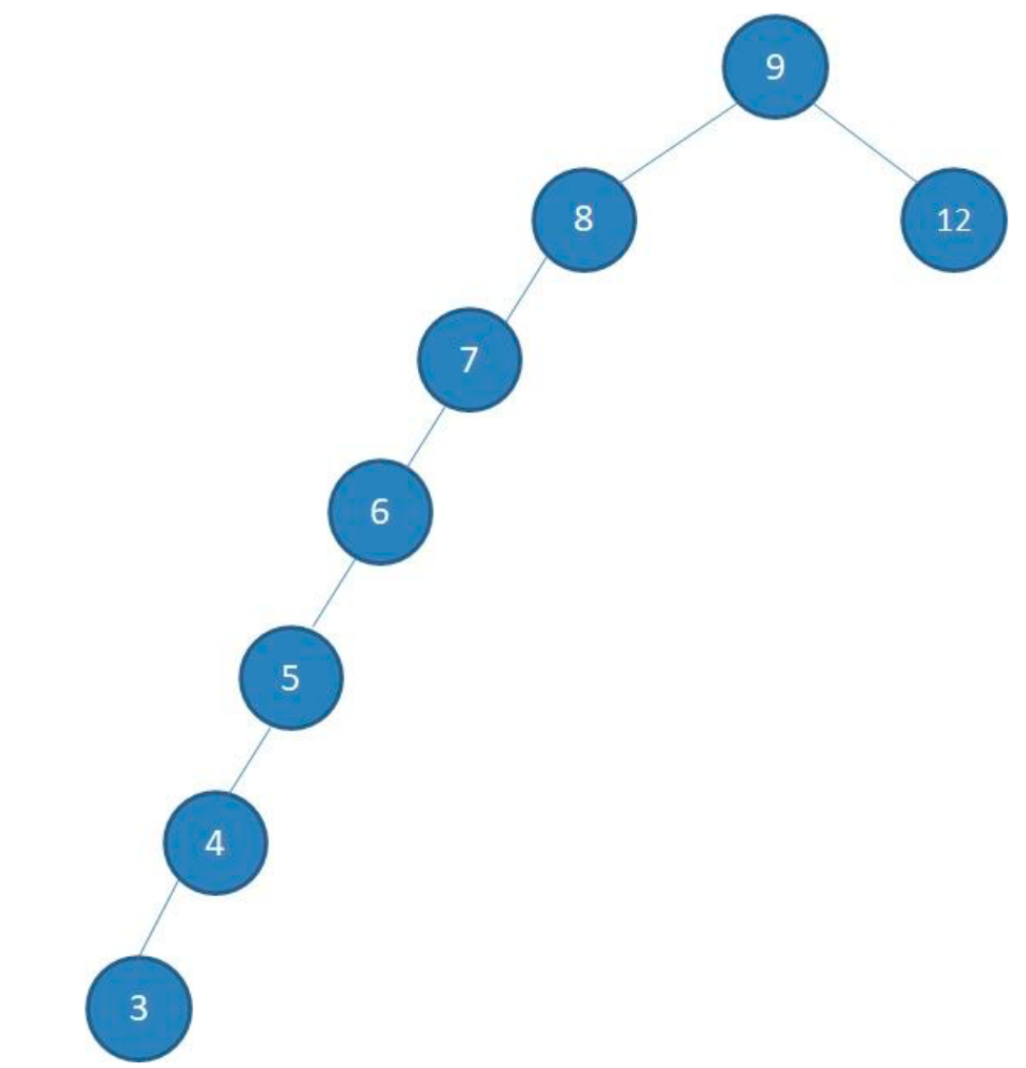
不平衡的二叉排序树退化为链表,时间复杂度:O(n)
平衡二叉(排序)树
从任何一个结点出发,左右子树深度只差的绝对值不超过1.
左右子树仍然为平衡二叉树。
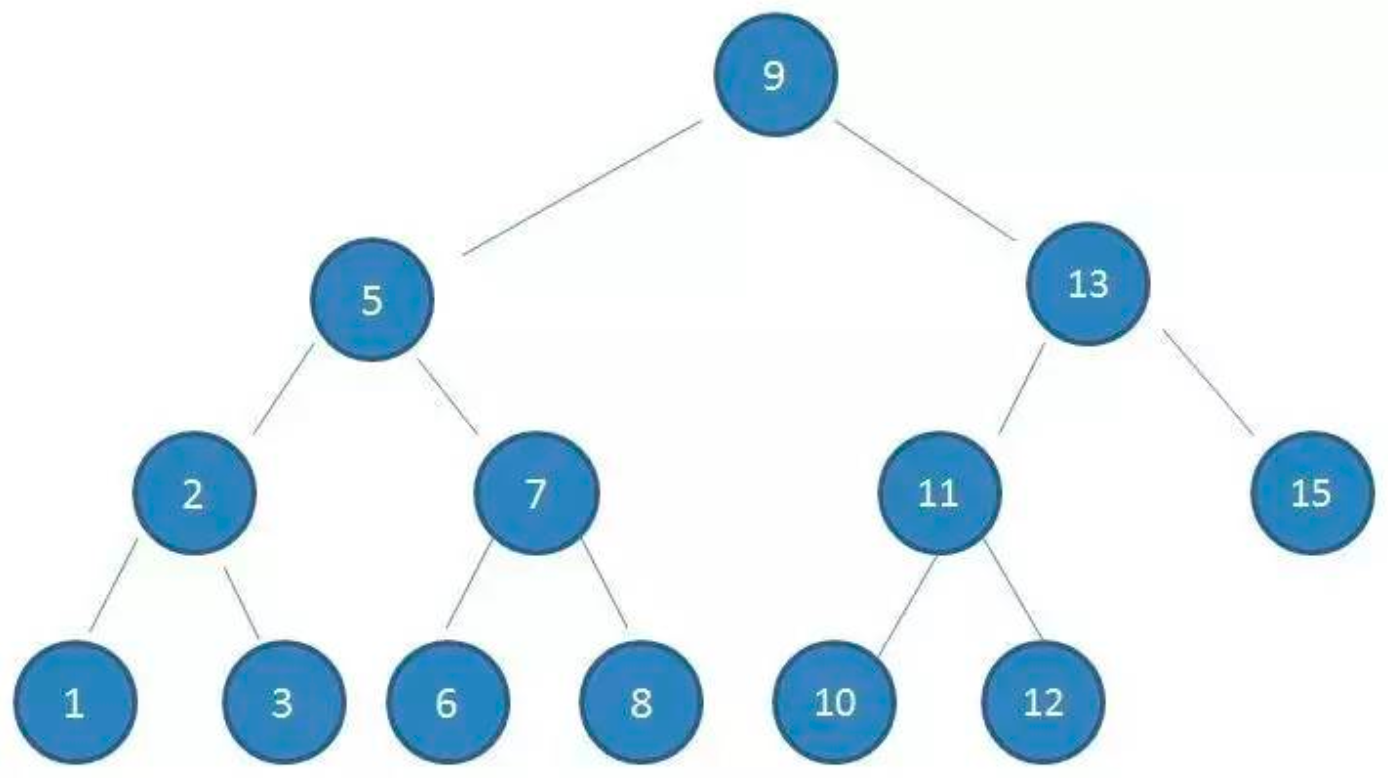
旋转二叉树恢复平衡
插入式,最多只需要两次旋转就会重新恢复平衡。
删除时,需要维护从被删结点到根节点这条路径上所有节点的平衡性,时间复杂度为.
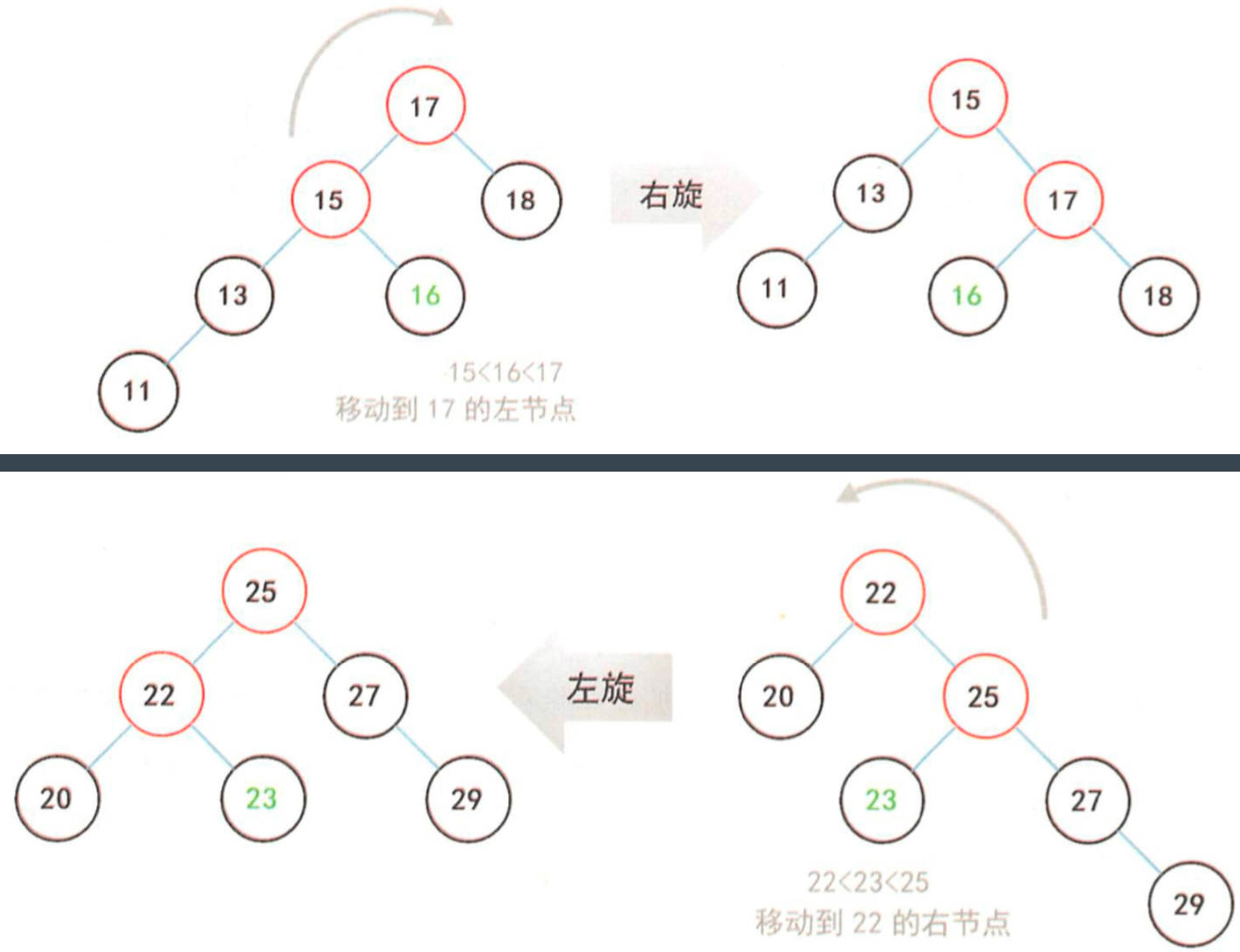
右旋的过程:
左旋的过程:
红黑(排序)树
每个节点只有两种颜色:红色和黑色。
根节点是黑色的。
每个叶子节点(Null)都是黑色的空节点。
从根节点到叶子节点,不会出现两个连续的红色节点。
从任何一个节点出发,到叶子节点,这条路径上都有相同数目的黑色节点。
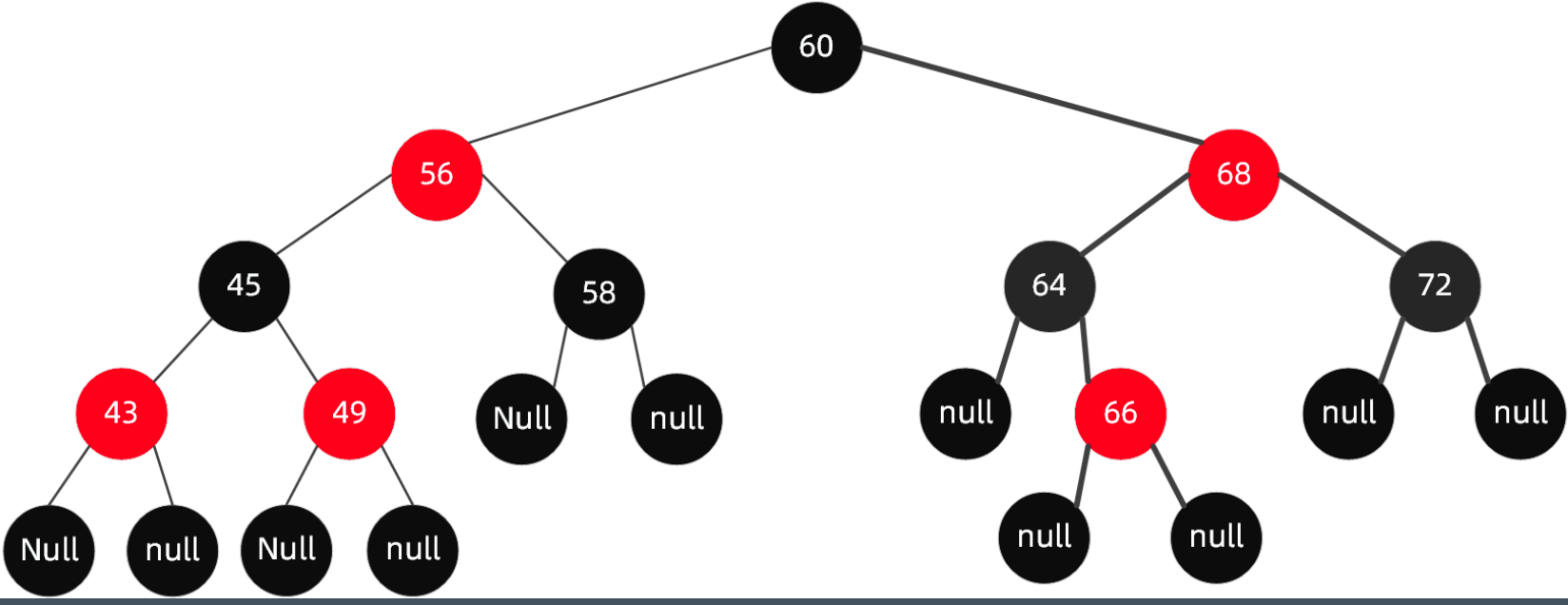
增删结点的时候,红黑树通过染色和旋转,保持红黑树满足定义
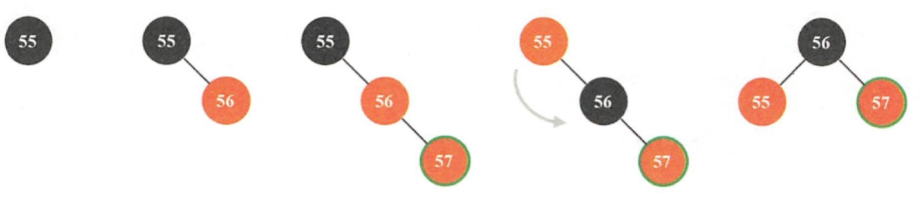
TreeMap就是用红黑树实现的。
红黑树 vs 平衡二叉树
红黑树最多只需3次旋转就会重新达成红黑平衡,时间复杂度O(1).
在大量增删的情况下,红黑树的效率更高。
红黑树的平衡性不如平衡二叉树,查找效率要差一些。
跳表
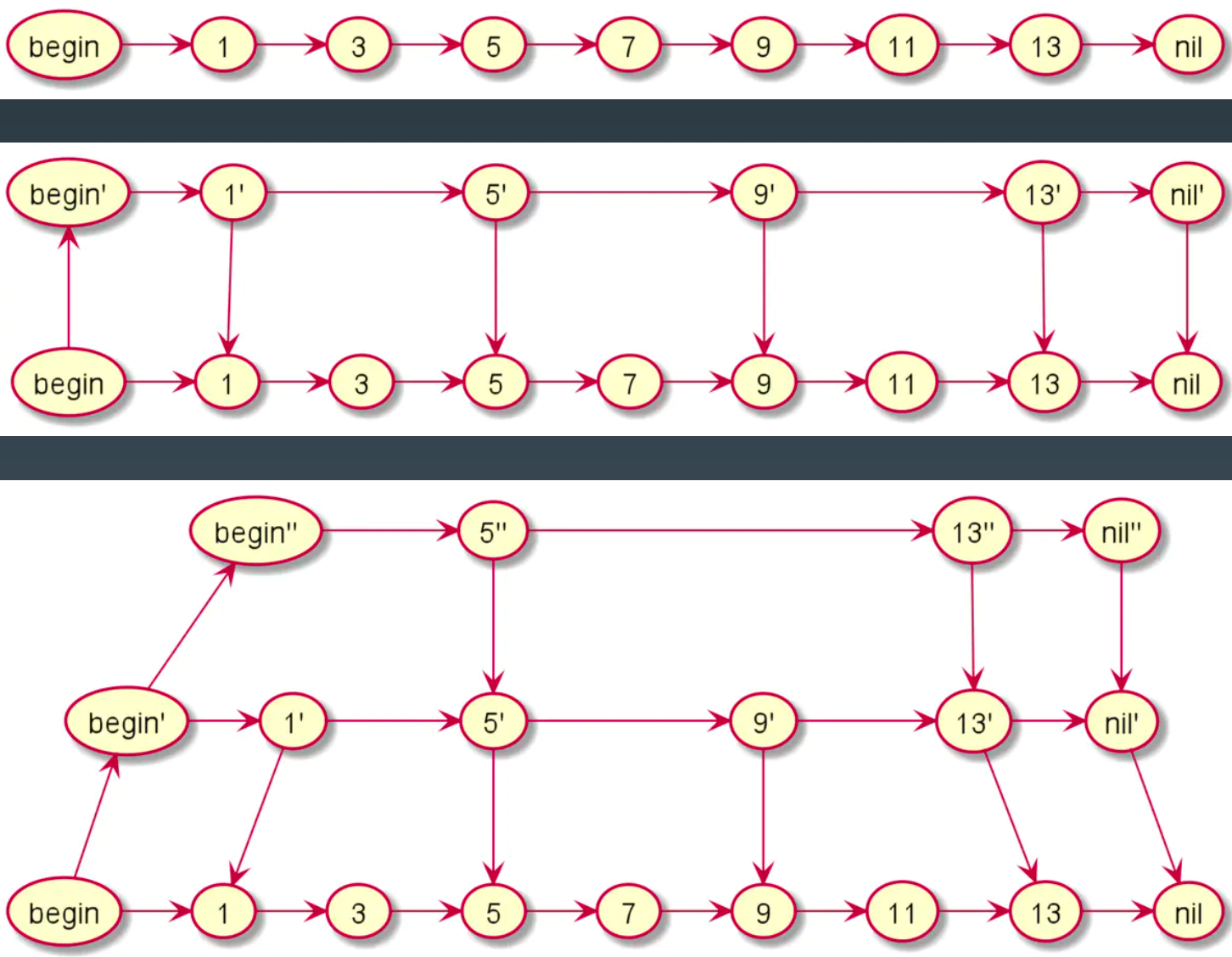
时间复杂度:O(logn)
空间复杂度:O(n)
常用算法
穷举算法
递归算法
贪心算法
动态规划
递归算法(快速排序算法)
def quicksort(array):
if len(array) < 2:
return array // 基线条件: 为空或只包含一个元素的数组是 “有序”的
else:
pivot = array[0] // 递归条件
less = [i for i in array[1:] if i <= pivot] // 由所有小于基准值的元素组成的子数组
greater = [i for i in array[1:] if i > pivot] // 由所有大于基准值的元素组成的子数组
return quicksort(less) + [pivot] + quicksort(greater)
print quicksort([10, 5, 2, 3])注意:
递归算法一定要有退出条件,否则就会栈溢出 Stack Overflow.
栈的空间是有限的,所以函数调用不能太深,比如写个计数,超过1000就退出。
时间复杂度:O(n * log(n))
贪心算法
背包问题: 拿一个装4磅中背包到商城买东西,将哪些商品放入背包才能受益最大化。
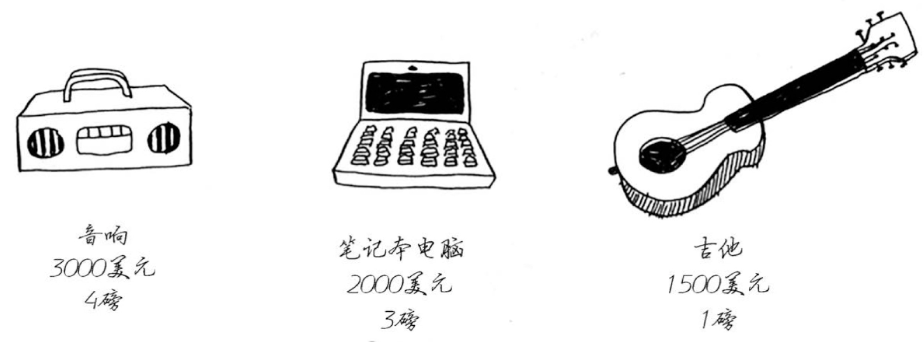
每一步都找当前的最优价,但是不一定是结果的最优解。
改进贪心算法 - 迪杰斯特拉算法(最快路径)
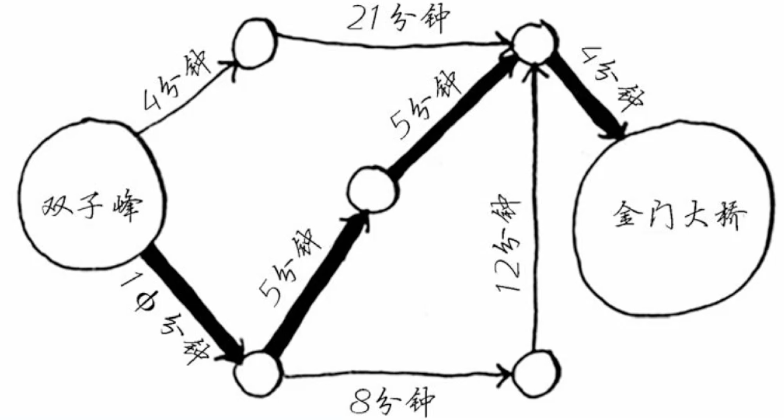
迪杰斯特拉算法(最快路径)
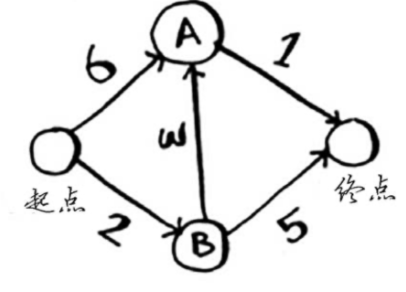
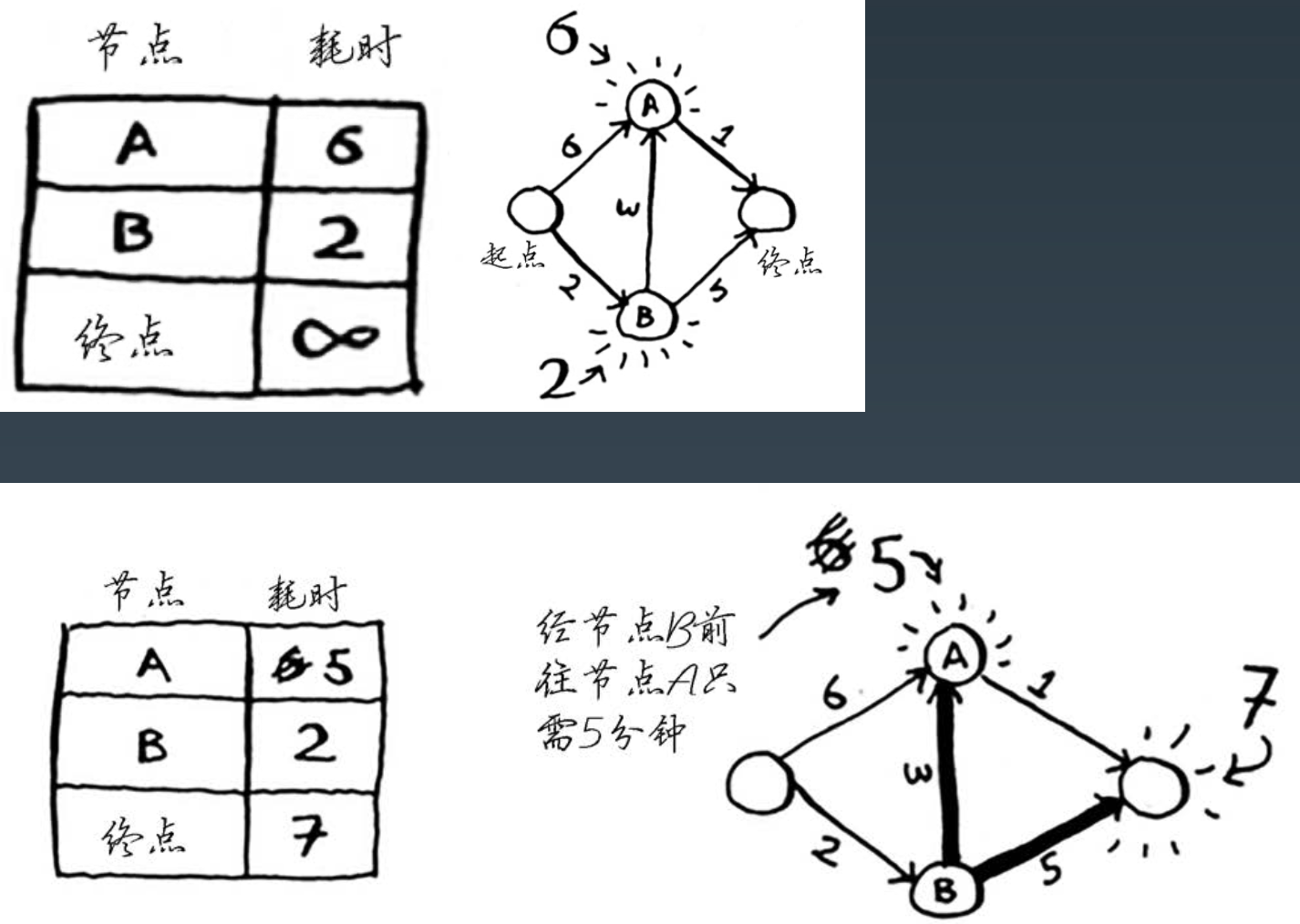
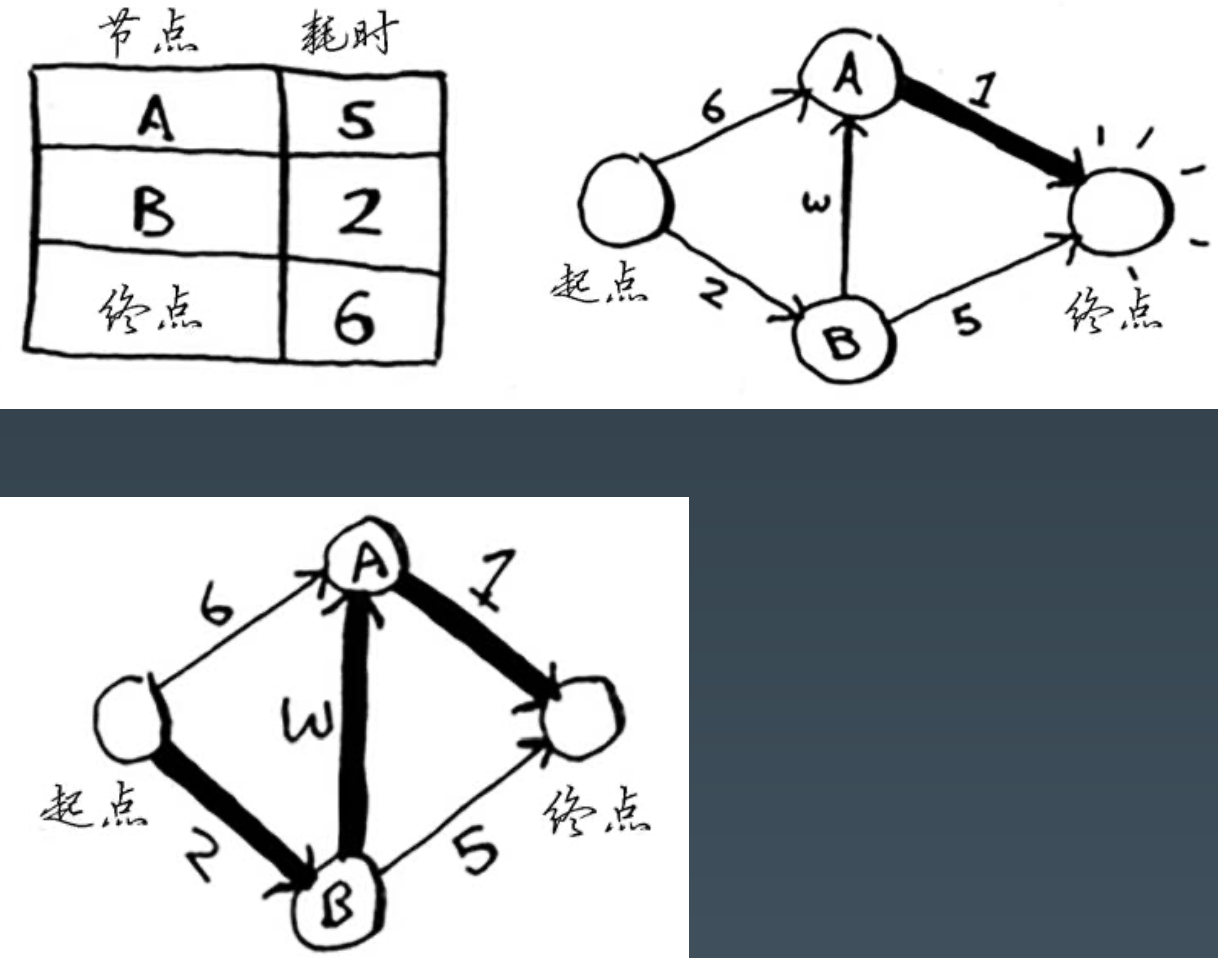
迪杰斯特拉算法的核心是找到起点到每个节点的最快路径。
动态规划
动态规划算法解决背包问题:
通过找到合适的角度,将所求解的目标值在某(几)个维度上展开,将一个大问题拆解为若干小问题,小问题的最优解,寻找大问题的最优解。
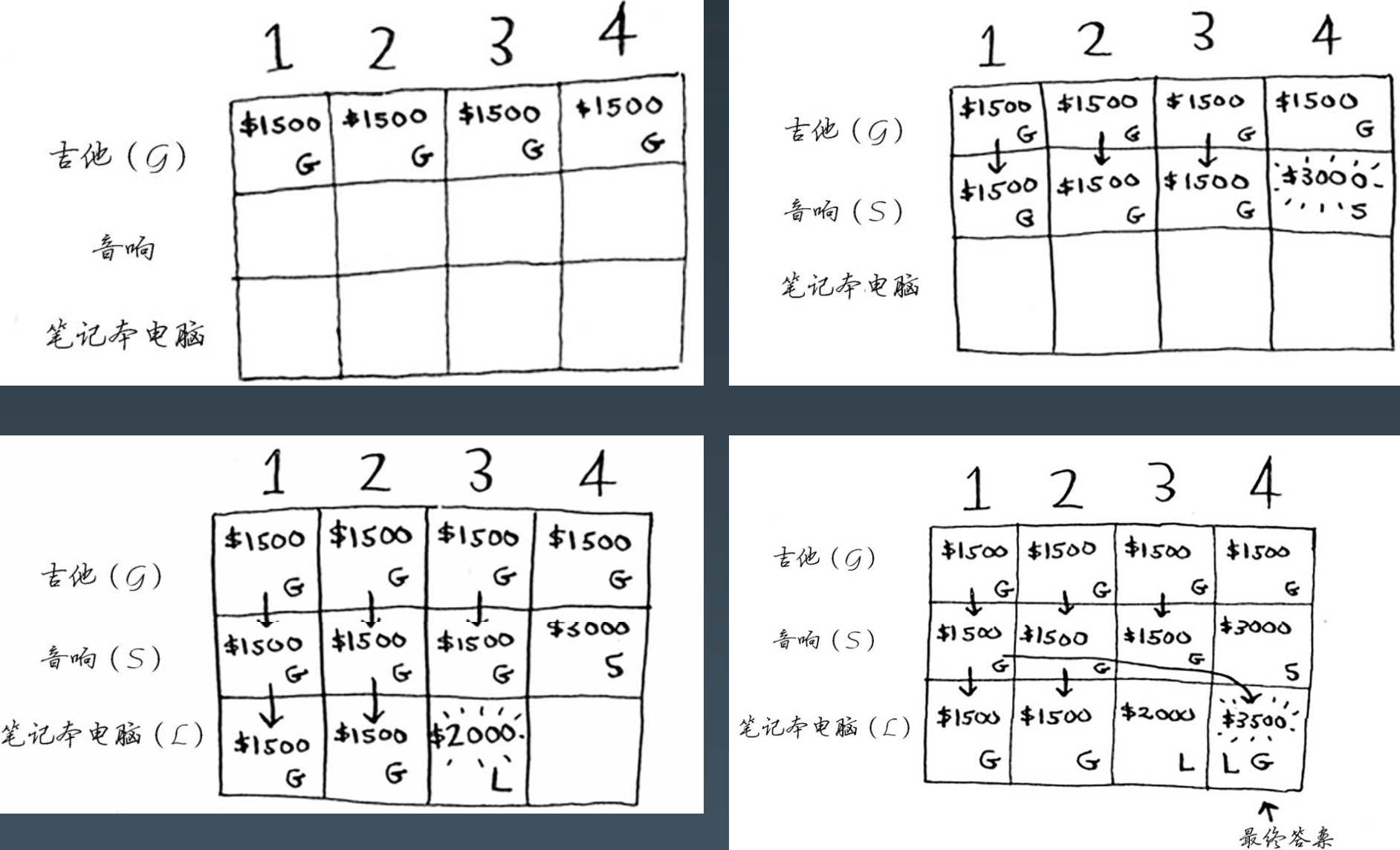
每个动态规划算法都是从一个网格开始,背包问题的网格如下:

遗传算法不一定得到最优解
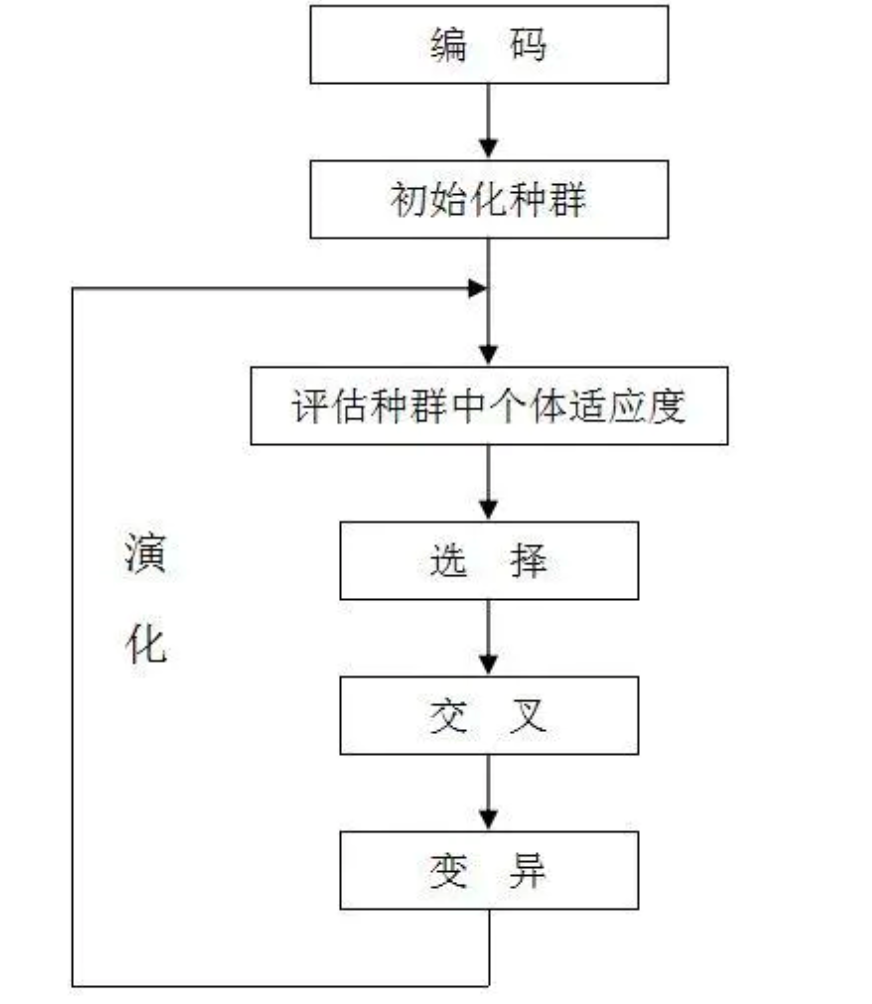
遗传算法过程
遗传算法解决背包问题
遗传算法( Genetic Algorithm, GA ) 是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。
遗传算法以一种群体中的所有个体对象,并利用随机化技术指导对一个被编码的参数空间进行高效搜索。其中,选择、交叉和变异构成了遗传算法的遗传操作;参数编码、初始群体的设定、适应度函数的设计、遗传操作设计、控制参数设定五个要素组成了遗传算法的核心内容。
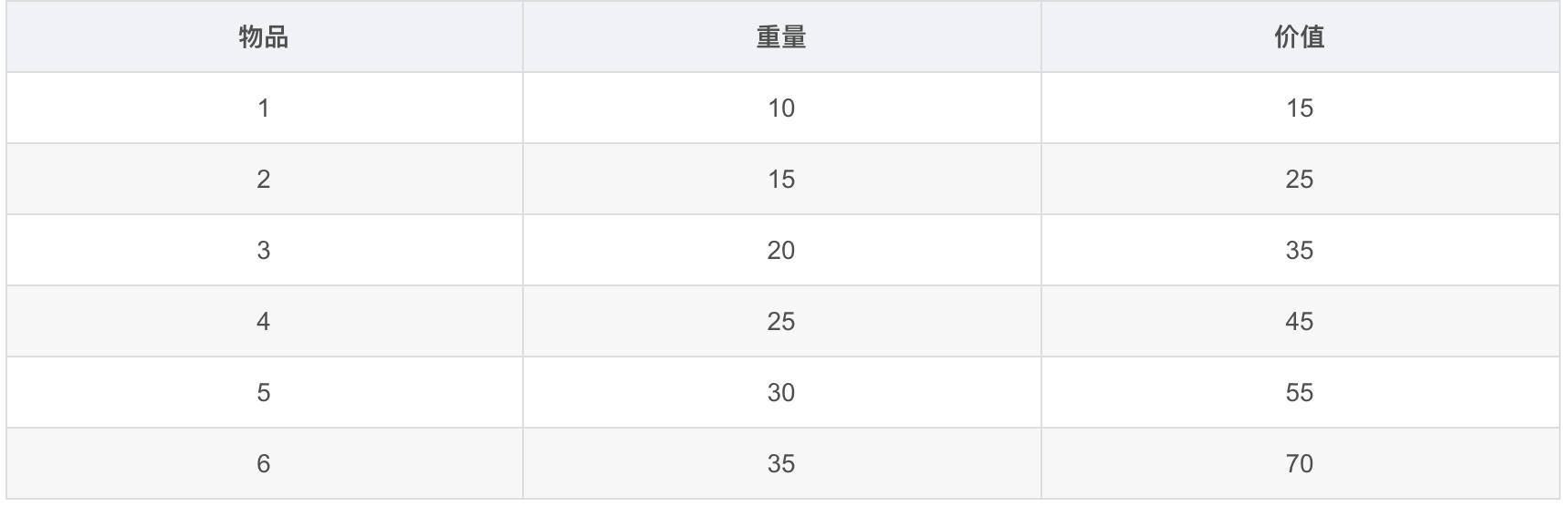
例子:80公斤背包装哪些物品价值最大?
基因编码与染色体
物品基因编码

基因组合:染色体
选择初始染色体:随机产生(也可以人为或者算法选择)
100100, 对应物品1、物品4存在。
101010, 对应物品1、物品3、物品5存在。
010101, 对应物品2、物品4、物品6存在。
101011, 对应物品1、物品3、物品5、物品6存在。
适应函数与控制参数
选择适应度函数,这里为商品总价值。
100100 = 15 + 45 = 60.
101010 = 15 + 35 + 55 = 105.
010101 = 25 + 45 + 70 = 140.
101011 = 15 + 35 + 55 + 70 = 175.
选择控制参数,这里为重量
100100 = 10 + 25 = 35.
101010 = 10 + 20 + 30 = 60.
010101 = 15 + 25 + 35 = 75.
101011 = 10 + 20 + 30 + 35 = 95.
染色体101011超重,淘汰。
选择算法
在剩下的染色体中选择可以被遗传下去的染色体以及繁殖次数。
100100, 适应度函数为 60.
101010, 适应度函数为 105.
010101, 适应度函数为 140.
选择算法
轮盘选择 ( Roulette Wheel Selection ): 是一种回放式随机采样方法。每个染色体进入下一代的概率等于它的适应度值与整体适应度值和的比例。
随机竞争选择( Stochastic Tournament): 每次按轮盘赌选择一对个体,然后让这两个个体进行竞争,适应度高的被选中,如此反复,直到选满为止。
均匀排序:对群体中的所有个体按照适应度大小进行排序,基于这个排序来分配各个个体被选中的概率。
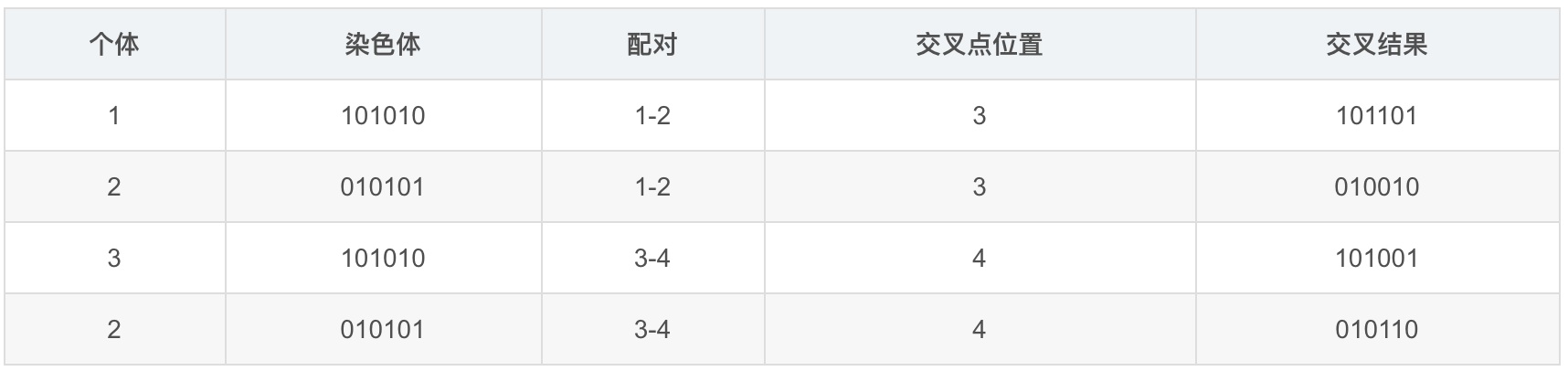
交叉遗传
选中结果: 101010 和 010101 个繁殖两次
生产下一代:染色体交叉遗传
循环迭代,如果连续几代遗传都没有出现更强的染色体(价值总和更大),那么算法收敛,当前最大价值的染色体为最终解。
有时候会在遗传过程中进行基因突变,得到基因突变染色体。
时间复杂度:O(1)