实用机器学习笔记十六:循环神经网络
前言:
本文是个人在 B 站自学李沐老师的实用机器学习课程【斯坦福 2021 秋季中文同步】的学习笔记,感觉沐神讲解的非常棒 yyds。
从多层感知机到循环神经网络(RNN):
上一篇文章讲的是图片分类问题,今天来讲自然语言处理中的语言模型循环神经网络。
语言模型:目的就是预测下一个单词,比如:
hello----->world hello world----->!
上面这个预测案例也可以使用MLP来解决:
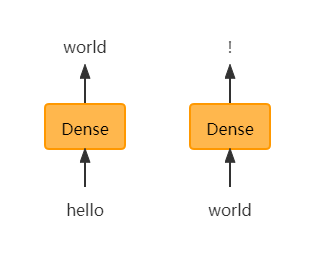
hello可以使用one-hot编码作为输入,输出可以使用softmax分类来解决,比如可能有1000个分类,那么输出就是1000维的向量。再对world做预测,使用同样的模型和同样的模型权重参数。不知道大家有没有注意到一个问题:在对world做预测时,模型只看到了world这个词,并没有看到world前面的词hello,也就是说只看到了上一时刻的world,没有看到world之前的信息,信息无法传过来。可能你会说在对world做预测时,把hello也放进输入,那么输入的维度就发生了变化,全连接层的输入维度是不能发生变化的。问题就是如何把长度会变的一个序列表示成一个固定长度的输入?可能你会想到之前介绍的Bag-of-word(词袋包:每一个词的独热编码相加)来解决,但是这种相加的方式并没有把时序信息(比如:hello world 变成world hello后,独热编码相加并不会变化)表示出来。
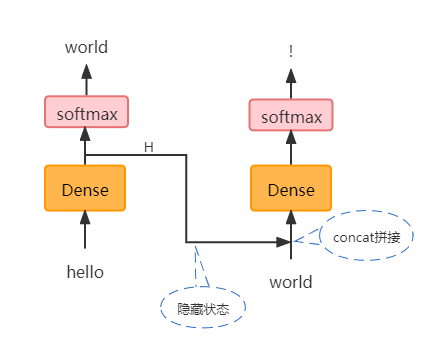
循环神经网络来解决:
如下图是循环神经网络的语言模型。为了在为world做预测时可以拿到前一时刻的信息,就在两个全连接层之间添加了一条数据通道,把全连接层对hello处理的输出结果拿出来作为隐藏信息H和world做拼接,这样就拿到了前面时序的信息。这个隐藏信息里面包含了hello之前所有时刻的输入信息,因为hello之前的信息也在往hello这里传递。而且最重要的是,不管这个传递有多少步,隐藏状态H的维度是不变的,唯一能决定H维度的就是全连接层的神经元的个数。
RNN和Gated RNN(门RNN):
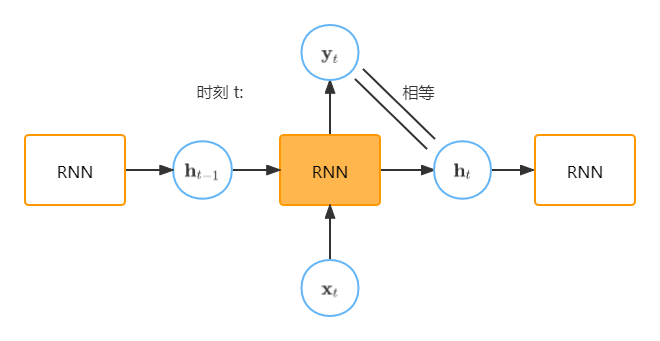
基础版RNN:,具体形式如下:
看上面这个式子,如果去掉激活函数实际上也是一个线性模型。在RNN中,即在下面这张图中,(是有激活函数的),这和上一张图中不太一样,但是我反复听了几遍课程,确实是这样的,不知道是不是沐神说错了还是怎么的,我又查了几篇博客,都是和下面这个图是一个意思。所以这里就认为下下面这个图是正确的。这里的是一个h*h的矩阵,只和RNN单元的输出神经元个数有关,加入输入是一个x维的向量,是h*x维的矩阵。
Gated RNN(LSTM,GRU):更好的控制信息流。
输入遗忘门:控制当前时刻输入,流入RNN的量
隐藏遗忘门:控制以往时刻信息流入当前时刻RNN的量
代码:
W_xh = nn.Parameter(torch.randn(num_inputs, num_hiddens)*0.01)
W_hh = nn.Parameter(torch.randn(num_hiddens, num_hiddens)*0.01)
b_h = nn.Parameter(torch.zeros(num_hiddens))
H = torch.zeros(num_hiddens)
outputs = []
for X in inputs: # input shape : (num_steps, batch_size, num_inputs),
# 这个循环次数就是num_steps,就是有几个时间步
H = torch.tanh(X @ W_xh,+ H @ W_hh + b_h)
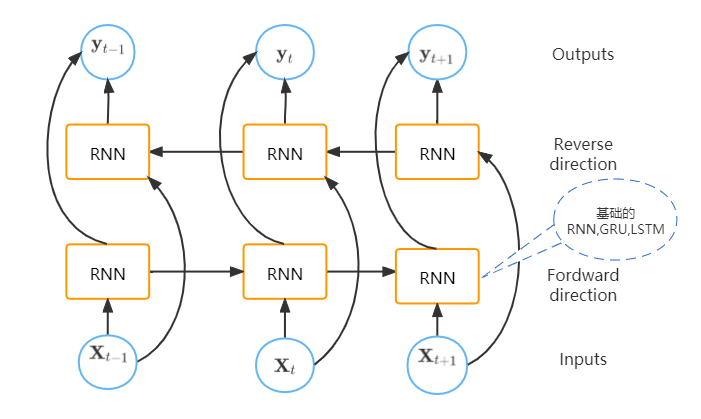
outputs.append(H)Bi-RNN(双向RNN) 和 Deep RNN:
Bi-RNN:
Bi-RNN的输出既有正向时序的信息,也有反向时序的信息,比如你做完形填空时,就可以根据后面的句子来推导前面的空。
Deep RNN: