二叉树先序中序后序的非递归实现
上一篇中我们讲到对于递归形式的实现,无论是先序、中序还是后序,代码都是统一形式,区别无非就是处理节点的函数位置不同,那么对于非递归的形式,是否也有统一的实现方式呢?
答案是肯定的,只不过如果要达到这种统一,需要引入一些额外的变量和代码进来。
先序和中序遍历
对于非递归的遍历方式而言,先序和中序是很容易找到统一的代码形式的
func handle(v int) {
fmt.Println(v)
}
func tranverse(root *TreeNode) []int {
cur := root
s := newStack()
for cur != nil || !s.isEmpty() {
for cur != nil {
s.push(cur)
//先序
//handle(cur.Val)
cur = cur.Left
}
cur = s.pop()
//中序
//handle(cur.Val)
cur = cur.Right
}
return arr
}代码形式来看是统一的,先把节点放到stack里面, 然后当当前的节点为nil的时候,我们从stack里面把节点pop出来,唯一的区别是处理节点的函数放置位置会有所不同。
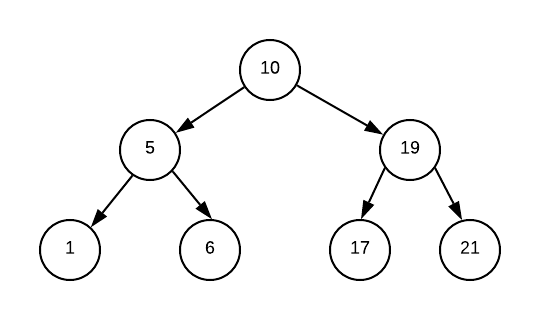
从观察stack, 我们可以看出来,只要处理元素的函数放在pop之后,那么就是中序,放在循环push里面就是先序。 但是用这个代码框架,我们没办法实现后序遍历,其核心原因是没有办法保存整个栈状态以及区分放到stack里面的元素是左节点还是右节点, 所以无论把处理函数放在哪个位置,都无法兼容后序遍历。
统一的形式
如果我们可以有种办法来区分处理的是左节点还是右节点,那么就可以做到兼容后序遍历。
func traversal(root *TreeNode) []int {
cur := root
s := newStack()
pre := cur
for cur != nil || !s.isEmpty() {
for cur != nil {
//先序遍历
//handle(cur.Val)
s.push(cur)
cur = cur.Left
}
cur = s.seek()
//中序遍历
//if cur.Right != pre {
// handle(cur.Val)
//}
cur = cur.Right
if cur == nil || cur == pre {
pre = s.pop()
//后序遍历
//handle(pre.Val)
cur = nil
}
}
return arr
}首先我们添加了一个pre变量, pre指向的永远都是上一次pop出来的元素,然后核心的部分其实在这段代码
if cur == nil || cur == pre {
pre = s.pop()
//后序遍历
//handle(pre.Val)
cur = nil
} 我们并没有马上pop, 而是选择性pop,并用pre变量记录下上次pop的元素,用这样的方式来改变节点访问的顺序, 在这种遍历方式下,父节点会被访问两次, 第一次作为临时节点,我们拿到右节点,所以 cur = s.seek() , 而不是pop, 然后我们通过 cur = cur.Right 拿到右节点push到stack里面去进行处理,当进行到叶子节点也就是 cur == nil 判断的时候, 我们把节点pop出来,并且 pre = s.pop; cur = nil,此时会再次去访问一次父节点 cur = s.seek(),由于 cur=cur.Right; pre == cur, 所以我们会把父节点此时pop出去。这里两次访问父节点, 其实模拟了递归方式里保存栈空间的操作,把父节点的信息保存下来了。
还是以上图为例, 当我们第一次跳出for循环之后,栈的变换为:
1. [10, 5, 1]
cur = s.seek() //此时cur为1
//中序遍历
//if cur.Right != pre {
// handle(cur.Val)
//}
cur = cur.Right //此时cur为nil
if cur == nil || cur == pre {
pre = s.pop() //pre为 1
//后序遍历
//handle(pre.Val)
cur = nil
} cur = s.seek() //此时cur为5, 第一次访问父节点
//中序遍历
//if cur.Right != pre {
// handle(cur.Val)
//}
cur = cur.Right //此时cur为6, pre为1
//接下来会把cur push到stack里面去并跳出循环 cur = s.seek() //此时cur为6
//中序遍历
//if cur.Right != pre {
// handle(cur.Val)
//}
cur = cur.Right //此时cur为nil
if cur == nil || cur == pre {
pre = s.pop() //pre为 6
//后序遍历
//handle(pre.Val)
cur = nil
} cur = s.seek() //此时cur为5, 第二次访问父节点
//中序遍历
//if cur.Right != pre {
// handle(cur.Val)
//}
cur = cur.Right //此时cur为6, pre 也为6
//此时cur == pre, 代表右节点已经访问过了, 我们需要pop
if cur == nil || cur == pre {
pre = s.pop() //pre为 5
//后序遍历
//handle(pre.Val)
cur = nil
} 从上面的步骤我们可以看出来我们的代码清楚分离了各个节点处理的阶段,如果放在for循环里就是先序,如果放在seek后就是中序,如果放在pop后就是后序。
总结
这里的核心就是只有当前节点下面的子节点都访问过之后,我们才去pop,不然就用seek来获得节点和其子节点,这样该节点的信息依然保留在stack里面,其次,用额外的变量去记录上次访问过的节点,用来识别是否右子树已经访问过了。