基于ELK的日志平台介绍
一、简介
Elastic Stack是开源()的日志搜集解决方案,主要是解决分布式系统中日志集中管理。ELK是Elasticsearch、Logstash、Kibana的简称。目前Elastic Stack生态圈的组件很多,适用于各种不同的业务场景,如日志分析、指标分析、网站搜索、安全分析等。
搭建基于ELK的日志平台,主要是通过搜集程序日志,了解业务运行状况从而制定相应的调整策略。按照当前规划,制定的ELK整体架构图如下:
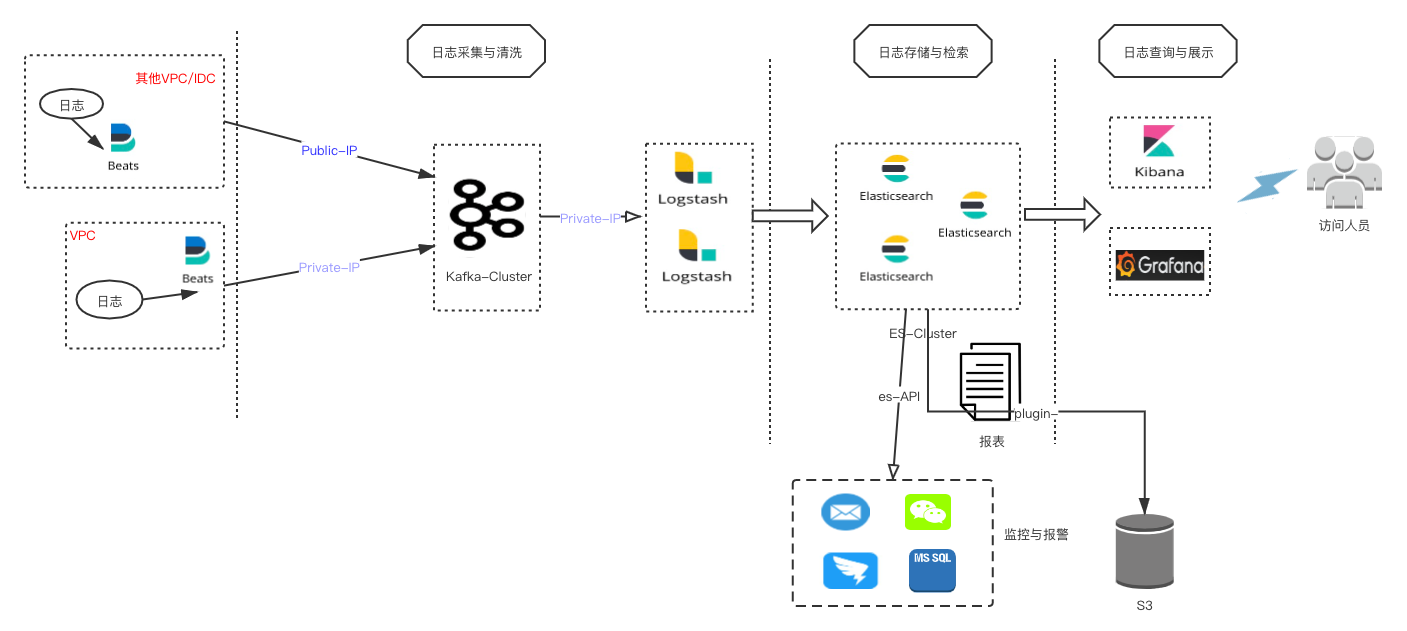
二、组件介绍
1、Beat
这里使用的是Filebeat,轻量级的日志搜集工具。在filebeat之前,一直使用logstash搜集日志,占用服务器资源较高。Filebeat主要是轻量级,建议不要有复杂的逻辑。
2、Kafka
用于存储日志内容的消息队列。Filebeat采集的日志可以直接output到kafka中,相比Redis而言,Kafka有吞吐量上的优势,并且可以根据消费者id不同进行多次消费。
3、Logstash
日志解析的主要工具。Kafka里消息内容除了日志本身,还有一些beat agent的信息。Logstash可以根据业务的需要,通过不同的规则,如正则、kv、split等进行日志的清洗。之后输出到Elasticsearch中。
4、Elasticsearch
日志内容存储。Elastcisearch可以日志如按照每天生成一个index,如k8s-2020.11.20。
5、Kibana、Grafna
Kibana提供2个比较常用等功能。一个是实时的查询页面,日志清洗之后根据业务如appname和关键字去查看程序的运行状况;另外一个功能是提供了对Elastcisearch的监控和操作,我们可以通过页面看到Elasticsearch集群运行状况和做一些curl restful的操作如增加删除索引、DSL查询语句等。
Grafna主要用于大屏展示。使用Elastcisearch作为数据源,根据具体的查询语句展示业务指标。
三、组件主要配置总结
1、Filebeat
#=========================== Filebeat inputs =============================
filebeat.inputs:
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /opt/nginx/logs/app1_access.log
tags: ["app1"]
#-------------------------- Kafka output ------------------------------
output.kafka:
# initial brokers for reading cluster metadata
hosts: ["kafka1:9092", "kafka2:9092", "kafka3:9092"]
# message topic selection + partitioning
topic: mytopic
required_acks: 1
compression: gzip
max_message_bytes: 1000000
version: 0.10.0.0 # 低版本kafka需要指定版本号
#================================ Logging =====================================
# 配置Filebeat程序本身日志保存时长,避免日志量增长导致磁盘空间不足
logging.level: info
logging.to_files: true
logging.files:
path: /var/log/filebeat
name: filebeat
keepfiles: 7
permissions: 0644
2、Logstash
日志搜集过程中最核心的组件。Logstash input/output支持很多插件,根据业务的不同可以使用不同的插件清洗成自己想要的格式。具体的使用参考官方介绍,由于版本的不同,相关细节以官网为准。
input {
# Logstash读取的数据源,这里是kafka
kafka {
bootstrap_servers => "kafka1:9092 kafka2:9092 kafka3:9092"
group_id => "ELK001"
topics => ["mytopic"]
consumer_threads => 3
auto_offset_reset => "earliest"
enable_auto_commit => "true"
codec => "json"
}
}
filter {
grok {
# apache标准日志解析规则
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
urldecode {
# 对url的中文解码
all_fields => true
}
}
output {
# 输出到Elasticsearch
elasticsearch {
hosts => ["es1:9200","es2:9200","es3:9200"]
index => "mytopic-%{+yyyy.MM.dd}"
}
}调试自己的规则可以使用如下:
input {
# 从控制台输入要解析的数据
stdin {}
}
filter{
grok {
match => {"message"=> "^<(?[^>]+)><(?\-)><(?[^>]+)[^>\n]*><(?\d+)><(?\w+\.\w+:\d+)>\s+(?.+)"}
}
}
output {
# 控制台输出解析结果
stdout {}
} 另外对于正则规则的调试也可以在Kibana后台的的dev tools中进行。
3、Elasticsearch
构建Elastcisearch集群主要注意如下2点:脑裂问题和JVM配置值的调优。这块详细的会在后面的文章中说明。
四、小结
这篇文章主要做个开篇,接下来准备几篇文章详细的说明相关使用和踩过的一些小坑。