开源| DewCloud——通用物联网平台
DewCloud诞生背景
DewCloud脱胎于我在业余时间为一家物联网公司开发的机油加注物联网项目,目前实现的功能包括:
智慧大屏: 润滑油 年月日、地理区域、油品用量,油桶库存,设备状况实时展示,机器故障停机、油量不足实时报警
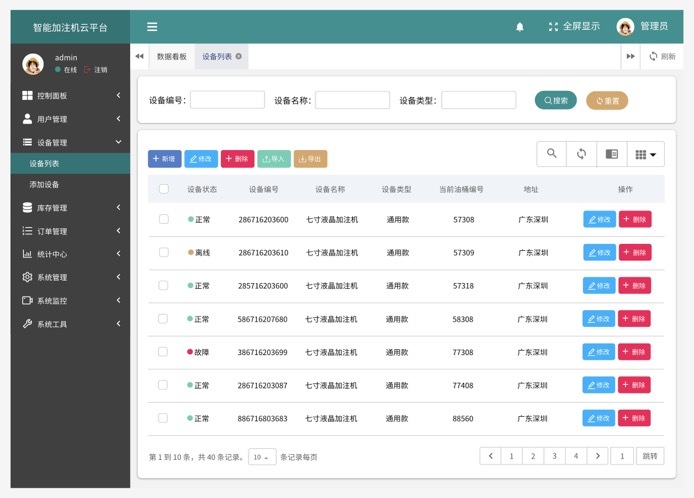
设备管理:设备列表、加注列表、设备定位
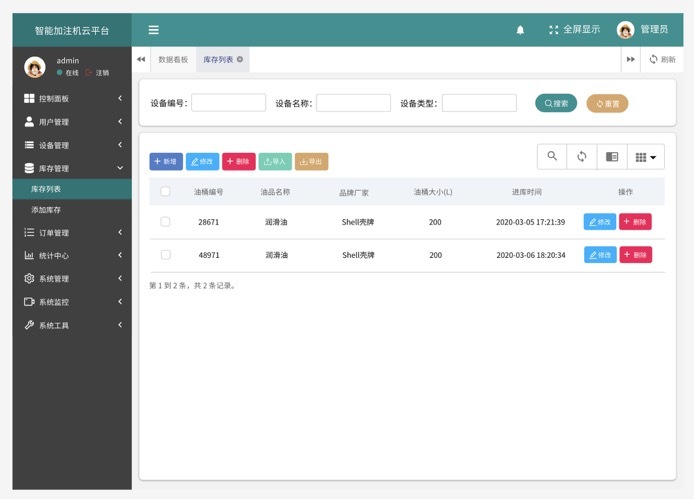
油库管理:库存列表
机油用量和客户管理
我们正在把它改造为通用的物联网平台,希望志同道合的朋友们一起加入进来。本篇文章主要介绍DewCloud项目的背景、技术架构和后续规划。
机油加注市场现状
机油即发动机润滑油,能起到减少发动机磨损的作用,被誉为汽车的“血液”。机油保养是汽车保养必不可少的一环,也是汽车后市场重要的组成部分。
市场调研
经过分析,市场上对于智能机油加注机的市场关注度明显过低,目前我们知道的竞品只有一家,而且他们的机油加注机仍然比较传统,软件方面只有简单的油耗显示界面,只能做到简单的开关机,停留在了物联网1.0的阶段。
说到物联网的发展阶段,我们有必要梳理一下。在我看来,物联网的发展经历了三个大的版本迭代:
1.0 简单的万物互联
1.5 提高开发效率,产品自定义、模版引擎和代码自动生成
2.0 半自动化,场景联动
2.5 提高数据处理和智能模型的进化,大数据和机器学习
3.0 全自动智能化,AI
伴随着工业4.0的迈进,也得益于AI和5G技术的发展,目前美、德、日和中国正在跨入第三代智能物联网时代。
需求与功能
与我们合作的厂商生产的智能加注机,包括加注机器、控制触摸屏和智能云平台(也就是后来的开源DewCloud平台)三部分。加注机器基于最新专利,有效地缩小了机器体积,减轻重量,提升加注流畅度,减少噪音,进一步提高用户的体验度。配套的软件,也是智能加注机的核心——智能加注云平台,运用大数据和机器学习技术,其最大远景是革命性地降低机油油耗。目前云平台能够实现以下功能:
油耗监控:精确的加注数量:当前加注量,设定加注量,实际加注量,总加注量,油桶总量,油桶余量,余量不足实时监控,大幅度减少管理、运营成本和润滑油浪费
库存管理:通过小程序扫码,加注机和润滑油油桶绑定,显示每个油桶的用量和状态,精确控制库存成本
机器状态监测:加注机工作状态实时上报,有效减少机器故障和停机时间
销量分析:润滑油各区域(中国地理区划),年月日,油品(品牌)用量分析,智能定点投放,
高精度定位:GPS和北斗定位,划定围栏,防止遗失
客户管理:管理分销商等客户关系,控制权限,利用分成的方式提升用户粘度
由上分析可知,我们主要的客户群体包括:润滑油品牌方,如美孚;润滑油供应商和个人车主。
平台技术架构
首先上图,下面是前期机油加注云平台的总体技术架构图。
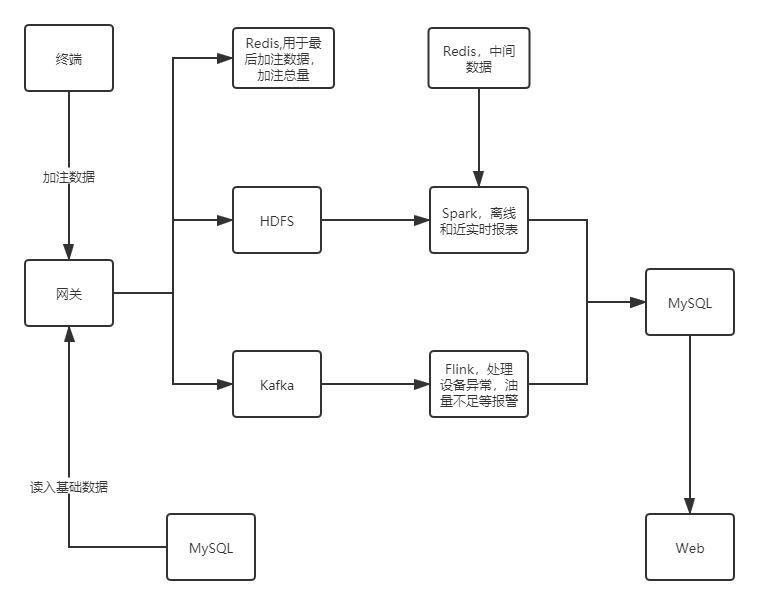
平台模块
我们可以看到云平台主要分为网关,Web端和数据仓库这三个组件:
网关:加注机终端通过TCP包的方式,以每5秒一个数据包的速度,传送给网关,网关负责通过制定的协议解析出TCP数据包,并将解析出的数据分发给HDFS、Kafka和MySQL等数据通道。
数据仓库:基于HDFS的离线数据和Kafka的流数据,用数仓分层的理论加工加注数据,形成报表传送给Web后端数据库,另一方面数仓数据也是机器学习训练模型的数据来源,以识别出机油损耗的模式,从而降低机油油耗。
Web端:Web端网站是机油加注云平台的主要组件,包括前端页面展示和后端管理系统。页面大屏显示出后端报表数据,
Demo
详细的技术实现代码,我们会在接下来的文章中分析,此处我们以数据仓库为例,用简单的代码来看一下我们用Flink实现报警的功能,报警的需求是当设备上报的油桶余量不足10%时,便生成一个报警,这里我们将报警写入MySQL,以供web业务端展示报警报表。
首先我们用网络数据调试器向网关模拟发送数据,网关会将数据解析后写入kafka
kafka-console-consumer --bootstrap-server cdh1.macro.com:9092,cdh2.macro.com:9092,cdh3.macro.com:9092 --from-beginning --topic fill
{"addTime":1593147840000,"currentAmount":0.3,"devId":"XT365-000170","devStatus":"1","ifOffline":"1","ip":"127.0.0.1","leftTankAmount":5,"realTotalAmount":2377.39,"registerTime":1606658457000,"settingAmount":0.3,"tankCapacity":1000,"totalAmount":2017.9315}
{"addTime":1593147840000,"currentAmount":0.3,"devId":"XT365-000170","devStatus":"1","ifOffline":"1","ip":"127.0.0.1","leftTankAmount":5,"realTotalAmount":2377.69,"registerTime":1606658458000,"settingAmount":0.3,"tankCapacity":1000,"totalAmount":2017.9315}
接下来我们写一段代码来消费kafka数据,并将报警结果写入MySQL
import com.alibaba.fastjson.JSONObject;
import com.iiot.bean.InSufficient;
import com.iiot.commCommon.Fill;
import com.iiot.jdbc.MySQLSinks;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.streaming.api.windowing.time.Time;
import java.util.List;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010;
import org.apache.flink.util.Collector;
import org.apache.flink.shaded.guava18.com.google.common.collect.Lists;
import org.apache.flink.streaming.api.functions.windowing.AllWindowFunction;
import java.util.Properties;
public class InSufficientOilAlarms {
public static void main(String[] args) throws Exception{
//构建流执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//kafka
Properties prop = new Properties();
prop.put("bootstrap.servers", "cdh1.macro.com:9092,cdh2.macro.com:9092,cdh3.macro.com:9092");
// prop.put("zookeeper.connect", "localhost:2181");
prop.put("group.id", "fill6");
prop.put("key.serializer", "org.apache.kafka.common.serialization.StringDeserializer");
prop.put("value.serializer", "org.apache.kafka.common.serialization.StringDeserializer");
prop.put("auto.offset.reset", "earliest");
DataStreamSource stream = env
.addSource(new FlinkKafkaConsumer010(
"fill",
new SimpleStringSchema(), prop)).
//单线程打印,控制台不乱序,不影响结果
setParallelism(1);
//从kafka里读取数据,转换成Person对象
DataStream dataStream = stream.map(value ->
JSONObject.parseObject(value, Fill.class)
);
SingleOutputStreamOperator result = dataStream.map(new MapFunction() {
@Override
public InSufficient map(Fill fill) throws Exception {
InSufficient inSufficient = new InSufficient();
Float leftTankAmount = fill.getLeftTankAmount();
Float tankCapacity = fill.getTankCapacity();
String devCode = fill.getDevId();
long timeBegin = fill.getAddTime().getTime();
System.out.println("devCode:-------------------------------------------------" + devCode);
String alarmType = "";
if ((leftTankAmount / tankCapacity) < 0.1 ) {
alarmType = "inSufficientOil";
inSufficient.setDev_code(devCode);
inSufficient.setCreateTime(System.currentTimeMillis());
inSufficient.setTimeBegin(timeBegin);
inSufficient.setAlarmType(alarmType);
inSufficient.setRemainAmount(leftTankAmount);
}
return inSufficient;
}
}
);
//收集5秒钟的总数
result.timeWindowAll(Time.seconds(5L)).
apply(new AllWindowFunction, TimeWindow>() {
@Override
public void apply(TimeWindow timeWindow, Iterable iterable, Collector> out) throws Exception {
List inSufficients = Lists.newArrayList(iterable);
if(inSufficients.size() > 0) {
System.out.println("5秒的总共收到的条数:" + inSufficients.size());
out.collect(inSufficients);
}
}
})
//sink 到数据库
.addSink(new MySQLSinks());
//打印到控制台
//.print();
env.execute("kafka 消费任务开始");
}
}
将项目打包,传到集群中,用Flink on YARN的方式运行作业,进入YARN reourcemanager里面查看作业运行日志:
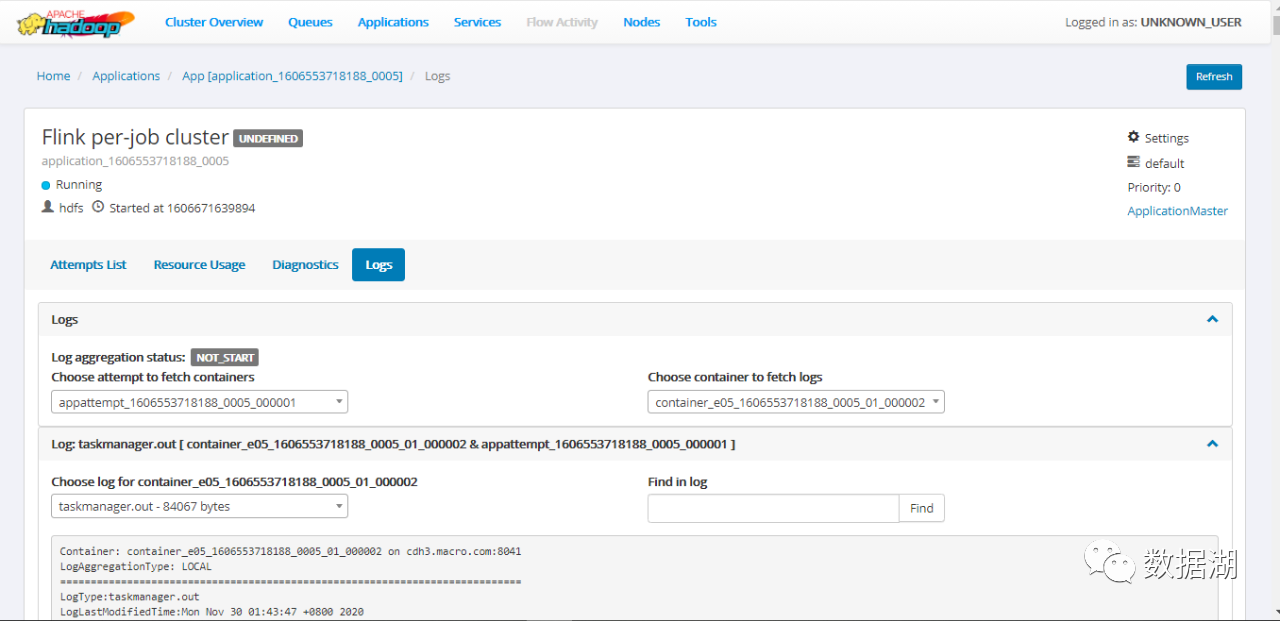
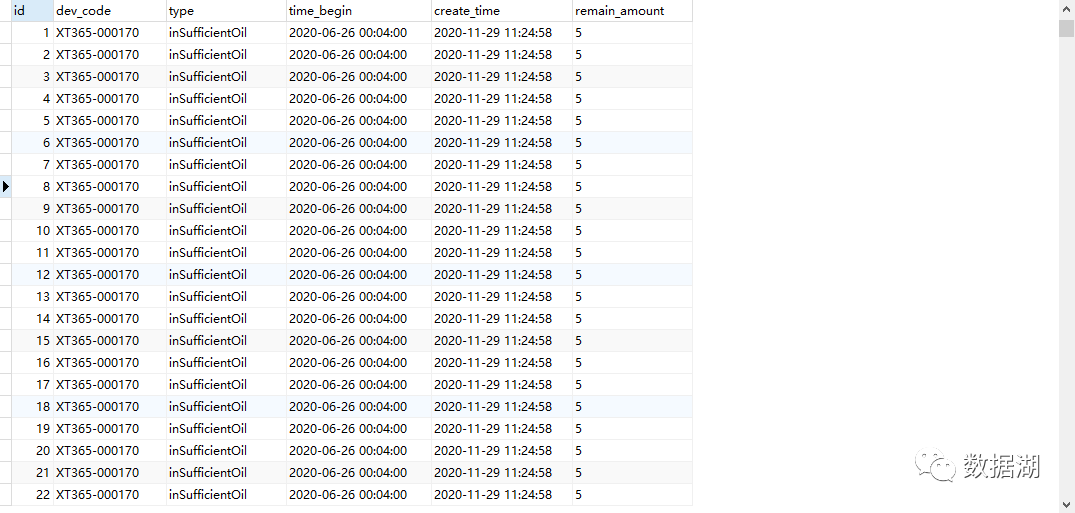
可以看到MySQL已经插入数据了。
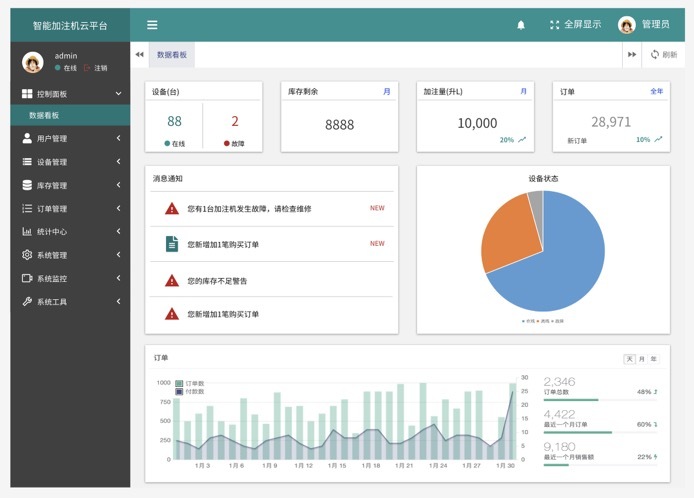
DewCloud页面展示
后续规划
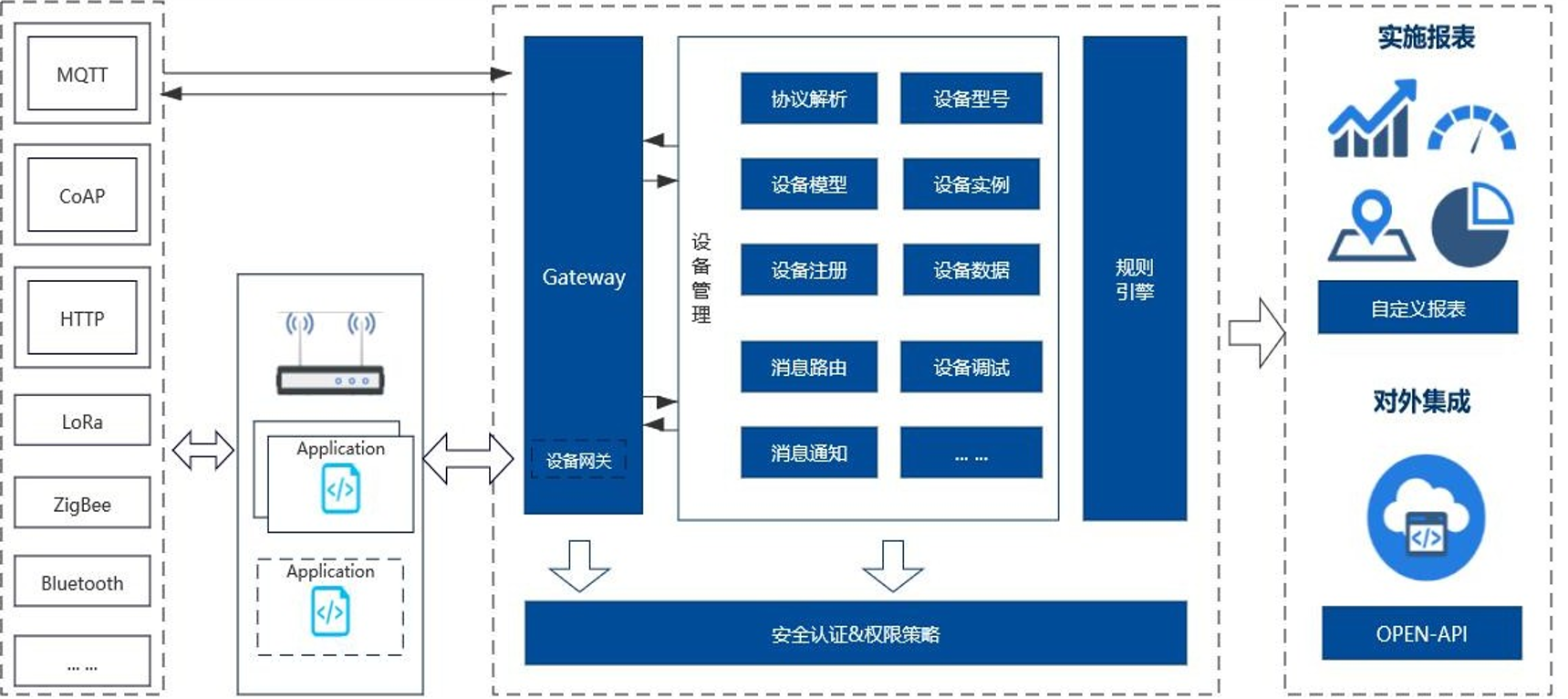
后续我们希望把DewCloud做成开箱即用, 低代码开发,设备快速集成的企业级物联网基础平台,帮助企业快速创建行业物 联网业务系统。
规划平台架构
写在最后
DewCloud 是我们基于生产级别的物联网项目开发出来的通用物联网平台,我们希望它能帮助物联网开发团队快速实现物联网项目的开发和设计,提升企业开发效率,欢迎大家使用。