生产服务器内存泄漏的排查过程与优化解决方案
最近在排查生产上,应用占用内存过大的问题,排查出来是jdk8bug+jetty服务器内存泄漏导致的,将过程记录下来,大家一起探讨。
一、环境信息
操作系统:centos、
内存分配器:glibc2.17
JDK版本:jdk8u_101.b13
配置:4C8G 即4CPU+8G物理内存。
Jetty版本:jetty-8.1.13.v20130916
应用信息:java应用,垃圾收集器使用G1,-xmx=-xms = 4G
二、现象
jetty启动应用后,Java应用进程占用1.4~1.5G。
运行一段时间后,应用进程占用5G+。
物理内存free -h,剩余100-300M之间。
部分机器开始使用swap空间,范围是:100~700M,一直缓慢持续上升。
三、排查过程
现状:
free -h 显示如下:

操作系统开始使用swap,大家都知道,只有物理内存吃紧的时候才会使用swap,也就是说明剩余的物理内存分配和使用起来有压力了。操作系统启动了应急策略:使用swap将部分不活跃的内存转移到swap区域以便腾出更多的内存空间。
使用sar和vmstat命令,可以看到在频繁的发生pageout到swap区域,暂未发生整个进程的内存页swap out:
执行sar -B 1,显示如下:
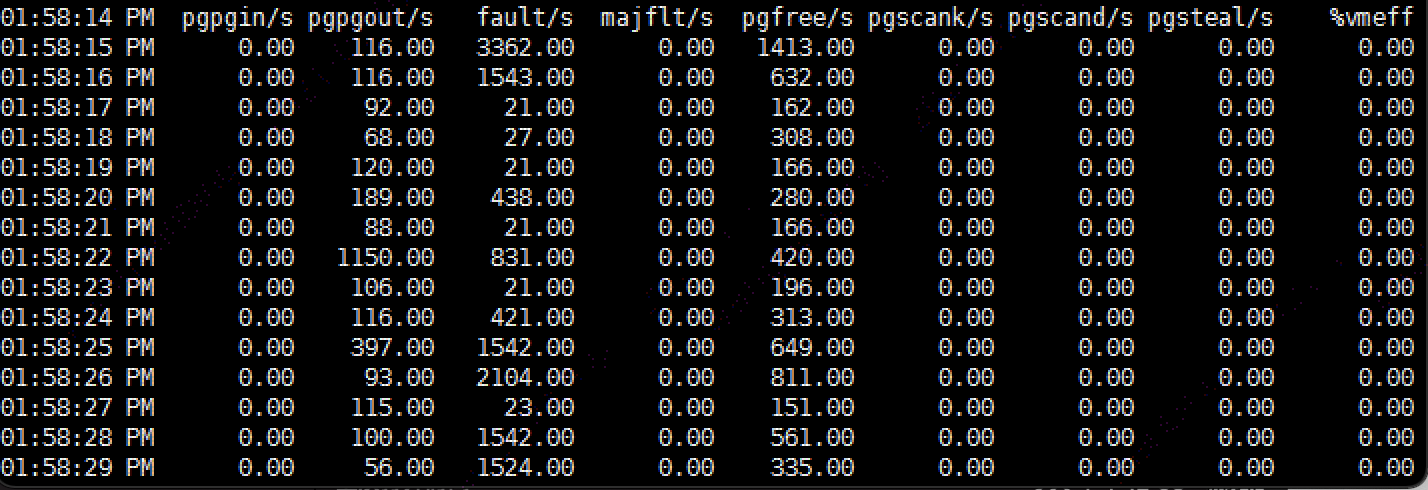
执行vmstat 1,显示如下:
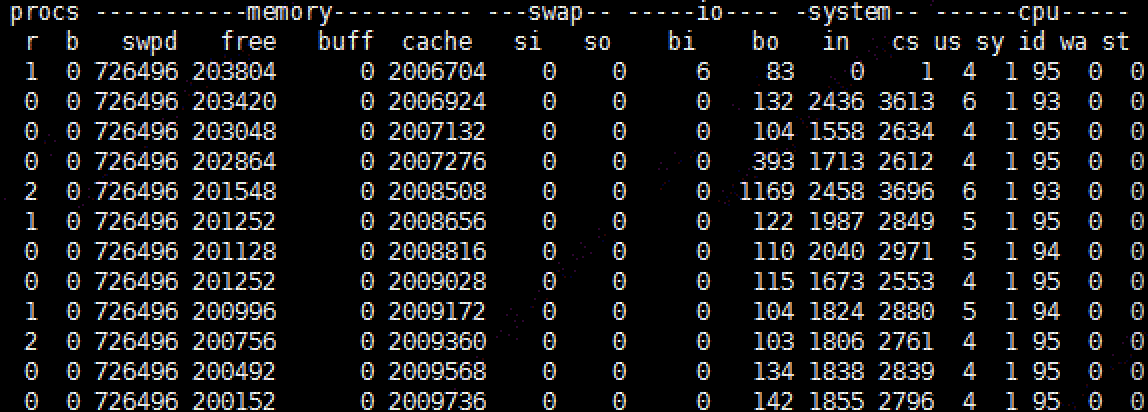
观察到我们的应用进程占据的内存很大,top -pH 该进程,显示如下:
// [图片正在脱敏处理,稍后提供]
由上图可知,应用进程占用了5.6 G, 虚拟内存占用了9.4G(那么大!!!),线程的个数是700个。
在开发环境模拟生产流量运行一段时间后,监控堆内堆外的内存使用情况,通过arthas工具(或者jconsole)观察如下:
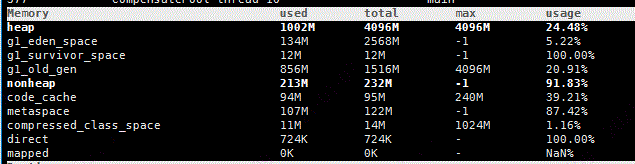
通过上图可知,我们的应用堆外内存的占用情况是240M左右:
code_cache(95M) + metaspace(122M) + compressed_class_space(14M) + direct(724K) +mapped(0K) = 232M。
按照配置堆大小是4G:-xms =-xmx =4G,JVM堆外内存占据240M来计算的话,进程应该占用的内存上限为:
上限大小 = 堆(4G)+ 非堆(JVM堆外,code_cache,、metaspace、compressed_class、direct等,240M) + 线程(400M,其实远远不到) = 4.625G。
但是现在实际占用已超过这个上限将近1G 。这就足够说明该应用的内存占用是有问题的。是否存在内存泄漏需要排查下,主要排查地方如下:
1、堆内存,看看是否存在堆内存泄漏。
2、堆外内存(仅仅指JVM的堆外内存),看看是否存在泄漏。
3、Native Memory内存泄漏,这部分内存的使用是JVM管控和追踪不到的地方。
3.1 堆内存和堆外内存排查
堆内存排查的最好方式是将应用的内存快照dump一份,使用Eclipse的MAT(Memory Analyzer Tool)工具进行分析,官网地址: ,它是一个强大的基于Eclipse的内存分析工具,也可以独立的安装软件,可以分析内存的使用情况,帮助我们找到内存泄露,减少内存消耗。
使用命令进行dump内存,切记这个操作会对应用造成影响,生产上使用要谨慎 ,
jmap -dump:live,format=b,file=appMem.bin pid 将bin读入到MAT后,选择显示可疑内存分析,呈现的结果如下:
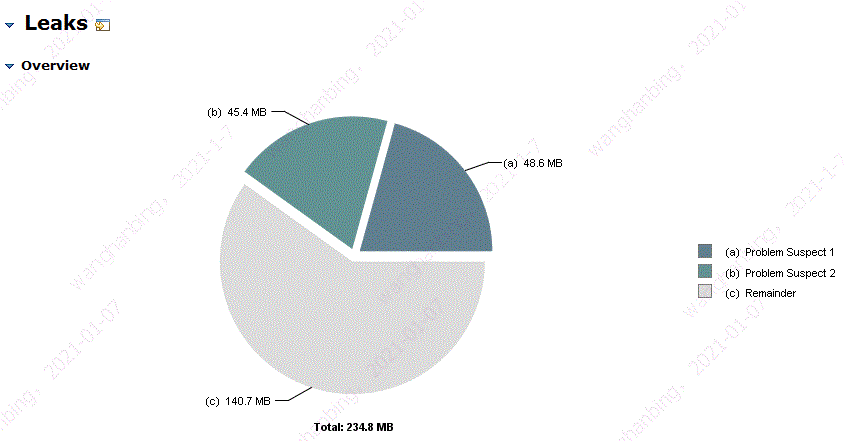

MAT提示我们有两个可疑的内存泄漏点:
com.alibab.dubbo.common.URL
com.alibaba.druid.pool.DruidDataSource
第一点我们的应用依赖的服务机器数量比较多,服务的数量也很多,所以有1万5的URL对象不足为奇,同时alibba的URL也不涉及到资源的操作,所以可疑排除内存泄漏。
第二点说明数据库链接数,也没有什么可疑的点。
从可疑点并不能看出来什么,也可以从首页的Overview的各个指标,比如Histogram、Top Consume和Big Object等。可以参考 这个教程。
同时也通过atrthas、jconsole、jvisualvm进行跟踪应用程序的跟踪,可以看到堆内存的分布:新生代Eden、老年代、堆外的几个指标也很正常。同时通过arthas也可以生成内存使用的火焰图,并没有使用direct内存。
这时候还是不能确认堆和堆外内存的使用是否正常,这时候使用NMT(Native Memory Tracking)对JVM的内存使用情况进行跟踪。官网地址是:,可以在应用的启动参数中加上如下参数:
-XX:NativeMemoryTracking=detail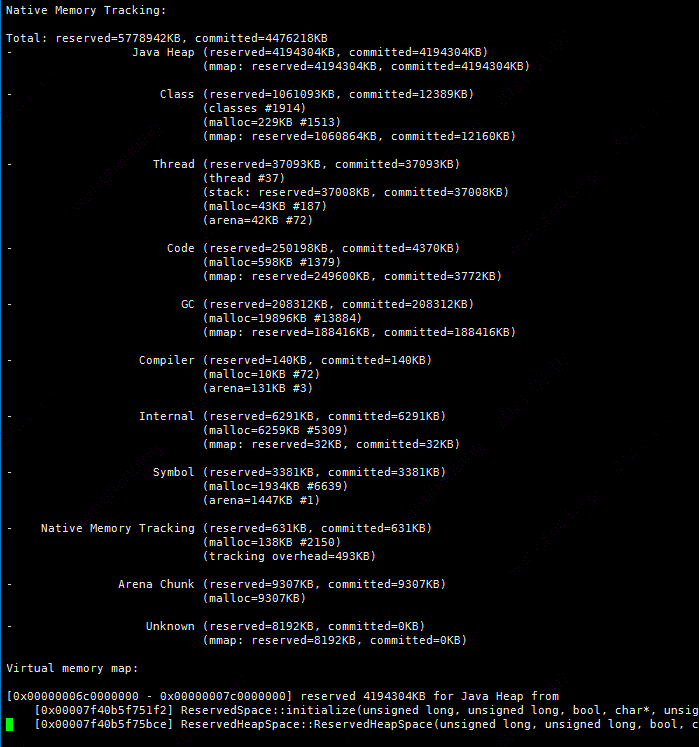
为了追踪NMT的各个内存区域的使用情况,编写了一个每1小时采集的脚本,对NMT的各个内存区域使用情况进行统计分析:
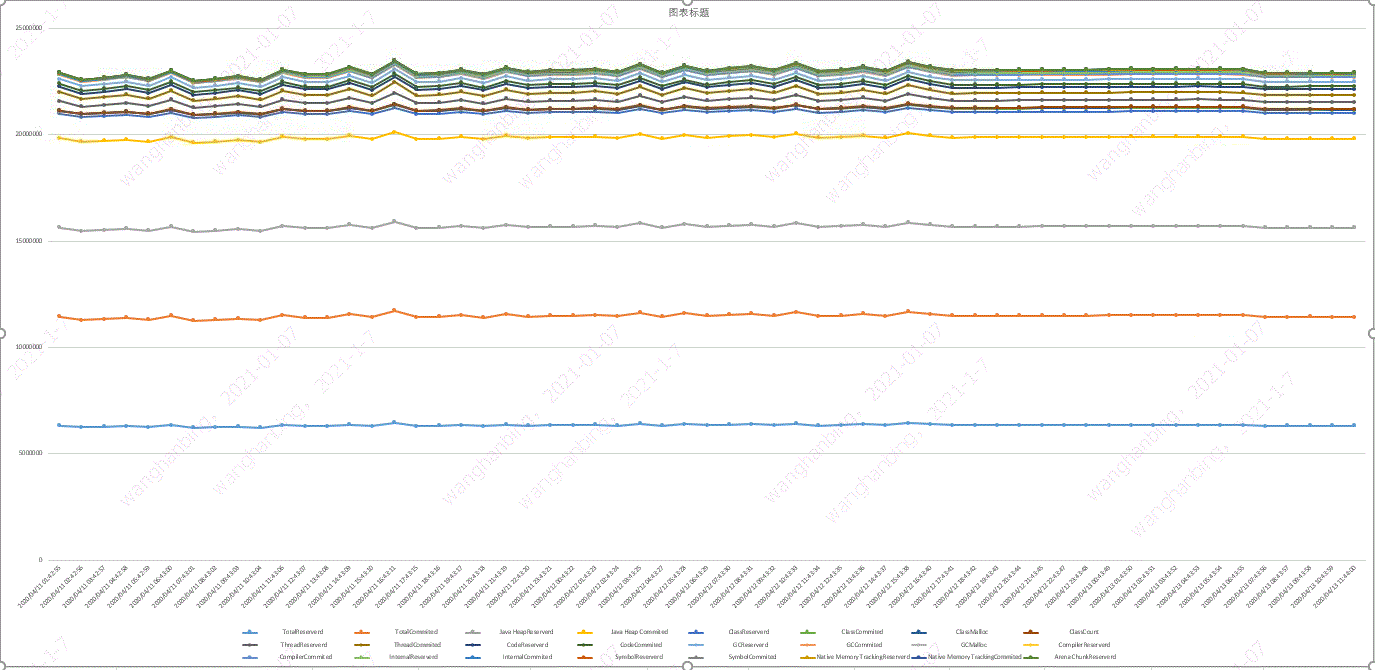
运行几天后,各个区域的内存使用无异常。
到这儿基本上可以确定应用的JVM堆是没有问题的。
3.2 Native Memory排查
通过上面的分析可知,JVM的内存使用是没有问题的,这时候就需要考虑JVM无法追踪和监控的内存:原生内存。根据/proc/meminfo整理下操作系统的内存分布情况:
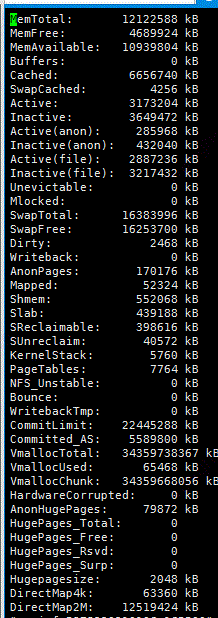
对各个区域进行整理得出如下的内存分布:

这时候写了一个操作系统的meminfo的内存定时采集器,这个采集器主要定时采集/proc/meminfo的各个区域的内存情况:
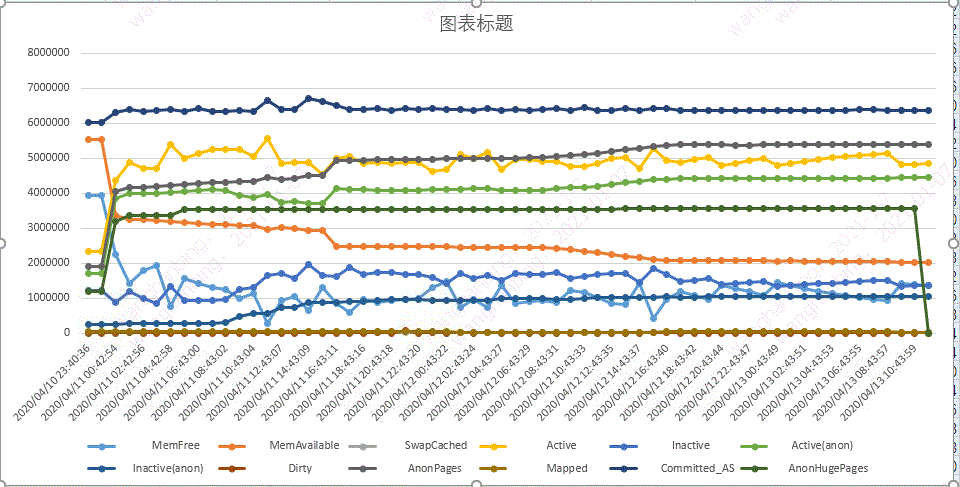
从上图可以看到如下的变化:
MemFree持续下降并保持平稳,这也符合生产上的现状,内存可用率持续下降。
Active(annon)、AnonHugePage、Dirty这两个区域持续上涨。
其他的指标都是变化后基本上不再变化。
Active(annon)、AnonHugePage这个主要是进程的匿名内存块使用在增长,Dirty是指这个进程使用的物理内存大小,是记录逻辑地址与物理地址额映射关系,是真正被操作系统感知到使用的物理内存,这个值也一直在增长,说明我们使用的物理内存越来越多,但是我们使用Native Memory Tracking跟踪程序,JVM整体各个区域是平稳的,不增长的。这时候疑点就出来了:为什么JVM外的内存使用一直在增长??。
这时候可以使用pmap命令对进程使用的地址空间和大小进行查看,基本命令如下所示:
pmap -x pid | sort -k 2 -r -n | head -50 执行命令后发现大量的64M内存块不在Native Memory Tracking的地址管理空间中,统计了下大概有45+个64M的逻辑内存块,第一列是地址,第二列是逻辑地址大小,第三列是实际使用的物理内存大小,对申请的物理内存(即第二列)排序后后如下:
又对第三列进行排序,看看内存的使用物理内存的情况:

上面两个图,这些64M块的逻辑地址(第一列)都可以在/proc/pid/smap中,也就是说这些地址确实是属于这个进程申请的,但是为什么会申请那么多的逻辑地址块同时已经使用了那么多物理内存呢?
选择其中一个64M的内存块地址,去/proc/pid/smap中找到这个块的启始地址,使用gdb工具将这地址块的内存dump出来,看看是什么内容:
gdb --batch --pid -ex "dump memory gdb_64M.dump 0x765e38000000 0x7f5e3bffa000"生成的gdb_64M.dump, 通过strings gdb_64M.dump 命令查看内存块的内容,如下:
可以看到基本上都是一些类名称,应该是存储的解压jar包的内容。
把思路扩大点,看看为什么会产生64M这种东西,外事不决问谷歌,通过关键字“64M”、“内存”等关键字搜索相关的信息,确实搜到了相关信息,总结如下:
64M内存块是glibc申请的,glibc是一种内存管理器,内部存在一个内存池,应用频繁申请的小内存和释放内存都通过glibc内存管理器申请和释放,这样能够减少与操作系统交互的次数,提高性能和效率。但是glibc持有的内存池因为存在内存碎片问题,导致内存的释放条件苛刻,导致进程 持有很大一块内存,特别是多线程竞争激烈的情况下,容易出现进程持有大量的内存,导致内存耗尽,表现为内存泄漏。
glibc每次向操作系统申请一大块内存(32位系统1M, 64位系统64M)进行切分成小块进行管理。
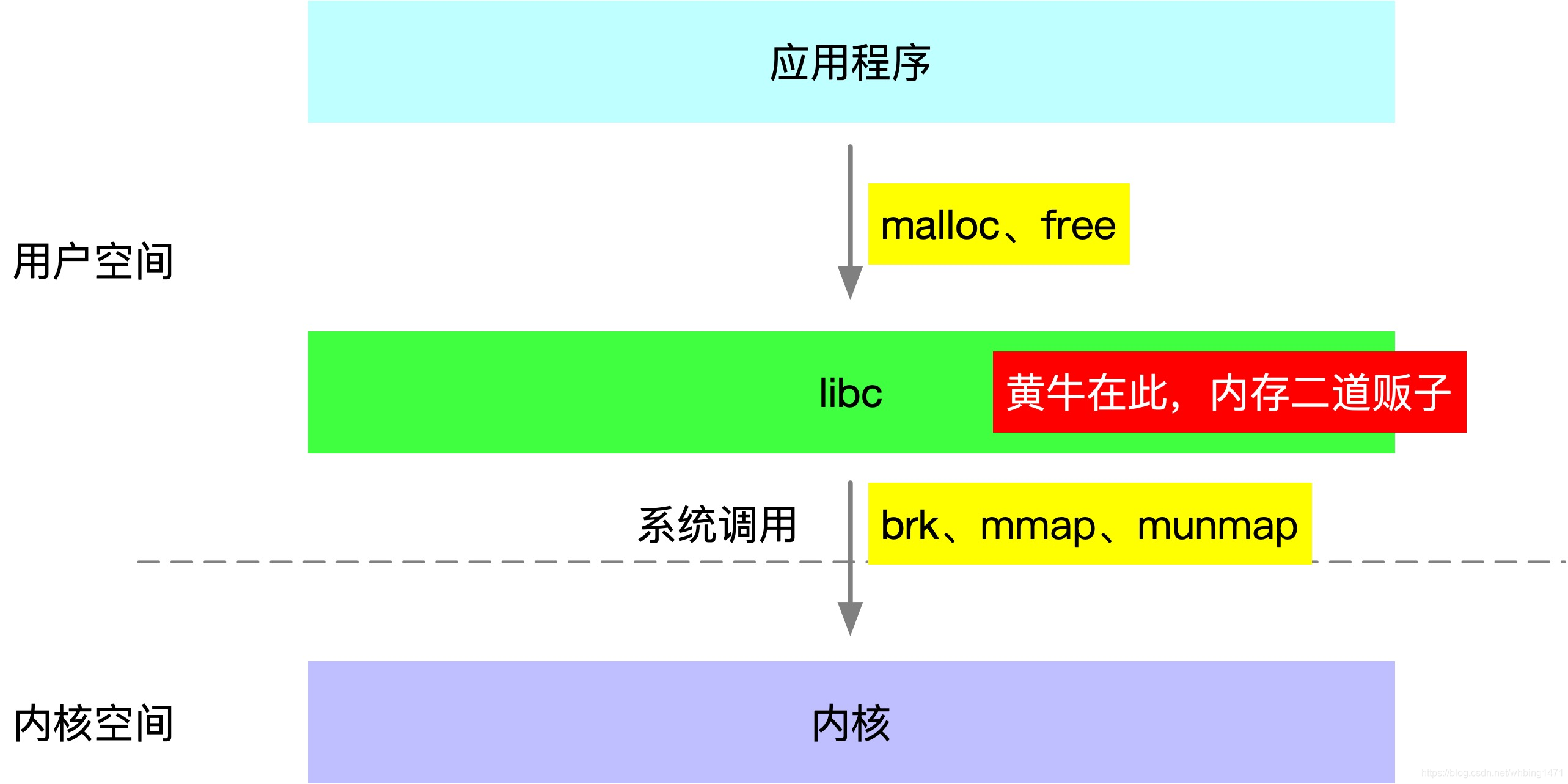
了解这些信息后,知道了原来是glibc在搞鬼,一直持有内存,不容易释放,所以导致内存占用过大。那就验证下45+个64M是不是glibc申请的:
使用strace工具对应用对操作系统的内存申请(brk和mmap)与释放(mummap)进行跟踪,为了能够从应用启动的时候就进行追踪,在jetty启动的时候就跟踪:基本命令如下:
strace -f -e "brk,mmap,munmap" -tt -o straceLog ./jetty.sh start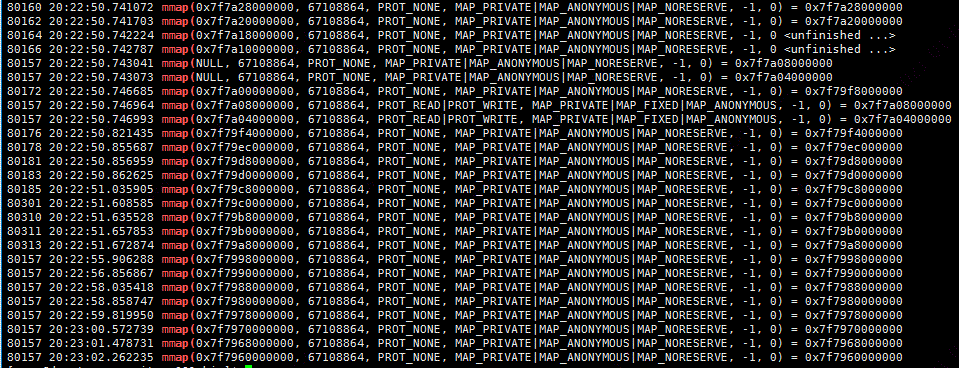
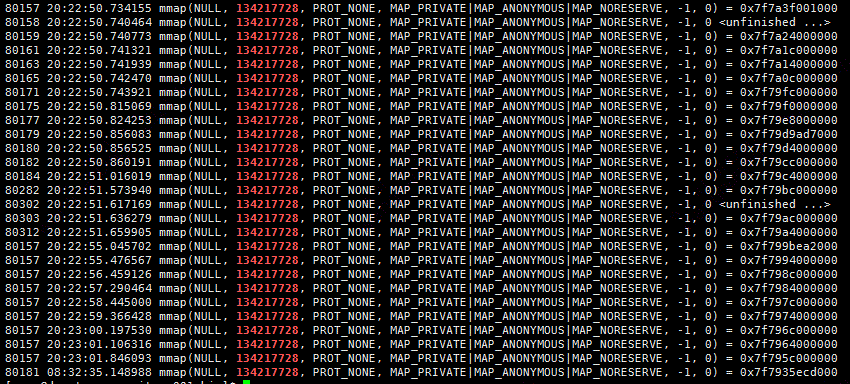
第二个图为什么申请的是2倍的64M,这是因为glibc在申请内存时没有采用锁机制,而是采用CAS的方式,当多个线程同时申请64M的操作时,只有一个成功,其他都失败。这时候失败的线程就会第二次申请,这次申请的内存是128M,申请成功后 ,会释放前面的64M,保留后面的64M地址空间。
从上面的次数可以统计出48个64M内存块。
这儿基本上确定了64M内存是glibc申请和管理的。现在业界比较成熟的内存管理器有如下:
jemalloc – FreeBSD and Firefox
tcmalloc – Google
这两个内存管理器对内存的管理都比较有效,减少了内存碎片的产生,接下来使用tcmalloc替换 glibc后 ,安装tcmalloc并在/etc/profile 文件中添加如下环境变量(注意tcmalloc是自己的安装地址)
sudo vim /etc/profile:
LD_PRELOAD="/usr/lib/libtcmalloc.so然后执行source /etc/profile使得环境变量生效。
经过几天的测试后,结果如下:
操作系统中也没有了64M的内存块了,启动时的内存占用也变小了。
可以看出tcmalloc对内存的管理要好于glibc,可以替换成tcmalloc,应用进程占用更少的内存。
按道理到这儿就应该结束了,已经找到多出来的内存是什么,是什么导致了64内存块的存在,怎么优化下内存的管理方式减少内存块个数。
按道理查到这儿应该也可以了。 基本结论如下:
应用程序没有出现内存泄漏。
64M内存块是glibc持有的,且glibc因内存池和内存碎片的原因,容易使得进程占用内存过大。
可是好奇害死猫~~~,还是想知道下为什么进程需要那么多的64M内存。因为根据glibc的特性,只有内存竞争激烈时才会产生大量的64M内存块,所以接下来想查明64M内存块到底是谁使用的,怎么去优化下不使用那么多内存。
3.3 服务器内存泄漏排查过程
现在需要查清楚的是:
是谁频繁使用内存?
申请64M做什么?
使用后为什么一直没释放?是否存在Native内存泄漏?
针对第一个问题:是谁频繁使用内存?
编写了一个Linux的hook函数,去统计线程的malloc次数,具体的可以参考,
LD_PRELOAD=./malloc_hook.so ./jetty.sh start > mallocLog
使用如下命令对结果文档进行统计:
cat mallocLog | awk '{print $1}' | less | sort | uniq -c | sort -rn | less统计出的结果如下:
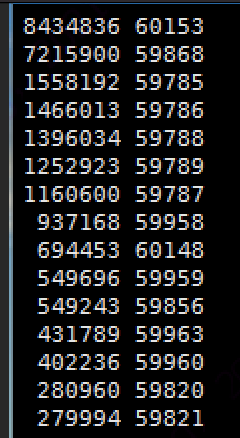
使用malloc最多线程pid=60153,通过jstack查看,这个线程是jetty的线程:
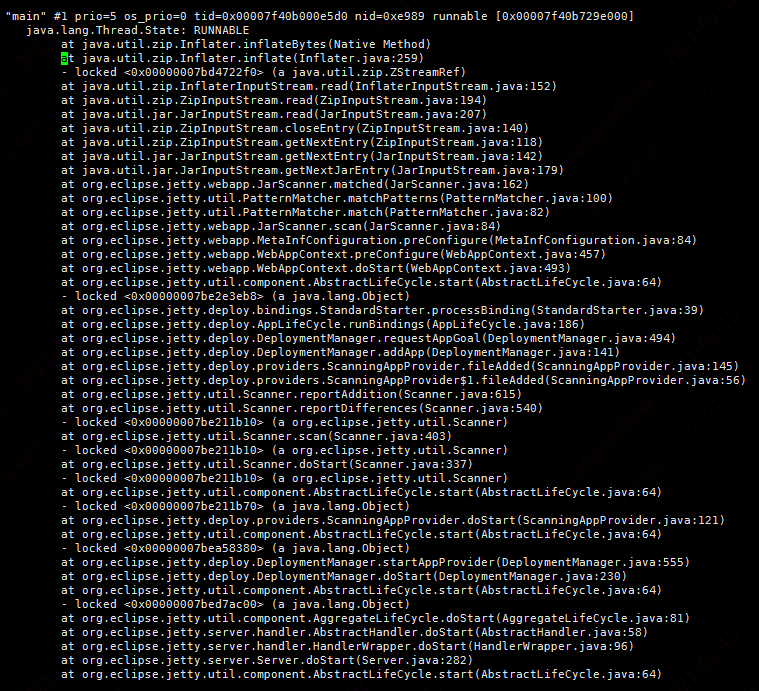
从堆栈可以看出jetty主线程在解压jar包,难道是使用Inflater解压jar需要那么多内存,一直都听说使用Inflater不当容易造成内存泄漏,是不是因为使用Inflater造成内存泄漏了。
针对第一个问题,来回答第二个问题,需要使用gperftools,这是google的内存分析利器,关于安装和配置,可以参考官网,github地址:.使用这个工具的前提是需要使用tcmalloc,这个已经在前文的配置中配置过了,使用如下命令重新启动jetty即可:
HEAPPROFILE="home/user/heap-gperftools/gzip" ./jetty.sh start一定要注意,这个路径存在目录的话这个目录一定要存在,不存在创建好。同时在这个目录下会生成很多文件,一定要筛选出来进程的heap。还存在其他的参数控制,我采用的默认:
# 此配置表示进程每分配X字节内存输出一个文件,默认是1G输出一个文件,这个设置的是4G
export HEAP_PROFILE_ALLOCATION_INTERVAL=4073741824
# 此配置表示进程每使用X字节内存输出一个文件,默认是100M输出一个文件,这个设置的4G
export HEAP_PROFILE_INUSE_INTERVAL=4048576000
启动后会输出以下信息:
[图片正在脱敏处理,稍后提供]
从输出信息也可以看出在使用100多M内存后就触发回收了,而不是一直增长。虚拟地址确实是在增长。
生成的heap文件使用如下命令进行解析和排序:
/home/xxx/gperftools/bin/pprof –text /usr/local/java8/bin/java gzip_149180.0001.heap |sort -nr -k 5 | head -20[图片正在脱敏处理,稍后提供]
对结果排序后,得到的结果如下:
[图片正在脱敏处理,稍后提供]
[图片正在脱敏处理,稍后提供]
刚开始的第一张inflater使用内存不是很明显 ,从第2张到第15张,inflater使用就非常的明显,infalter是用于解压缩器,使用那么凶猛,一定是在在解压东西。
这时候使用btrace工具跟踪某个函数的调用,btrace的脚本如下:
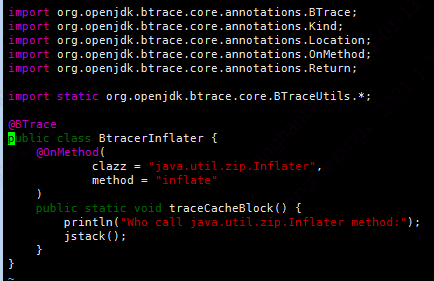
跟踪的调用结果如下:
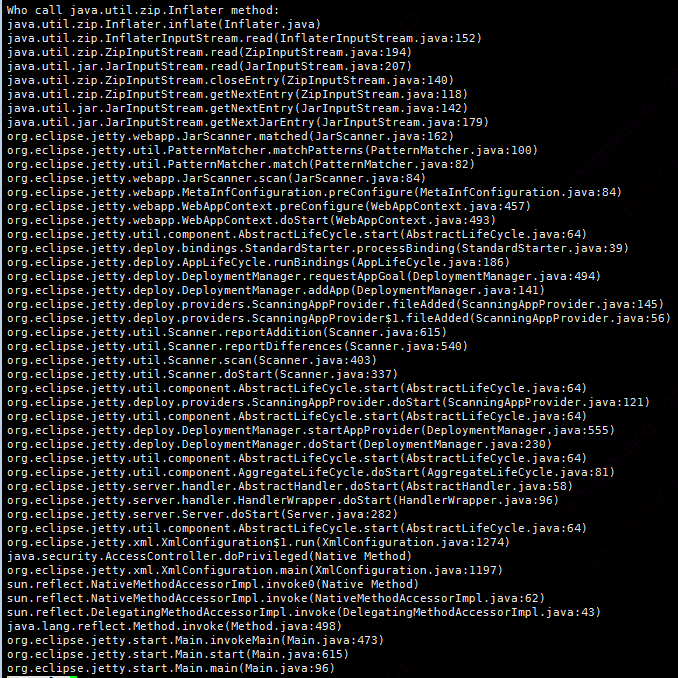
从图中可以看到,确实是jetty启动线程使用解压jar包。
现在可以知道的是:申请的64M,是jetty启动时,扫描和解压jar包在频繁的使用内存。
现在需要查明第三个问题:使用后为什么一直没释放?是否存在Native内存泄漏?
现在知道是因为解压jar包需要使用内存,glibc才会申请64M内存,并且放在内存池中,可是解压完成后为什么内存没有释放?
这时候就需要了解下jetty的启动过程了。jetty启动时为了支持Servlet规范中的注解方式(使得不再需要在web.xml文件中进行Servlet的部署描述,简化开发流程),jetty在启动时会扫描class、lib包,使用ServiceLoader,将使用注解方式声明的Servlet、Listener注册到jetty容器,在扫描jar包的时候调用了inflate,分配了大量的内存。
现在从ServiceLoader这个类入手,分析类的加载过程,分析jdk的源码,看看是否有内存泄漏,通过查看源码和搜索相关问题进行确认,jdk8存在bug,有以下问题:
jdk8打开jar时是默认缓存的,缓存会占用内存。
因为缓存机制,jdk8的ServiceLoader和UrlClassLoader同时加载一个jar包文件,会导致这个jar包的文件句柄泄漏,文件句柄泄漏对redeploy危害巨大的,但是对我们这种重启的应用危害性不大。
针对以上两个问题的帖子如下:
通过查看jdk源码得知,jdk9-111 已经修复了这个问题,将缓存去掉 ,如下所示:
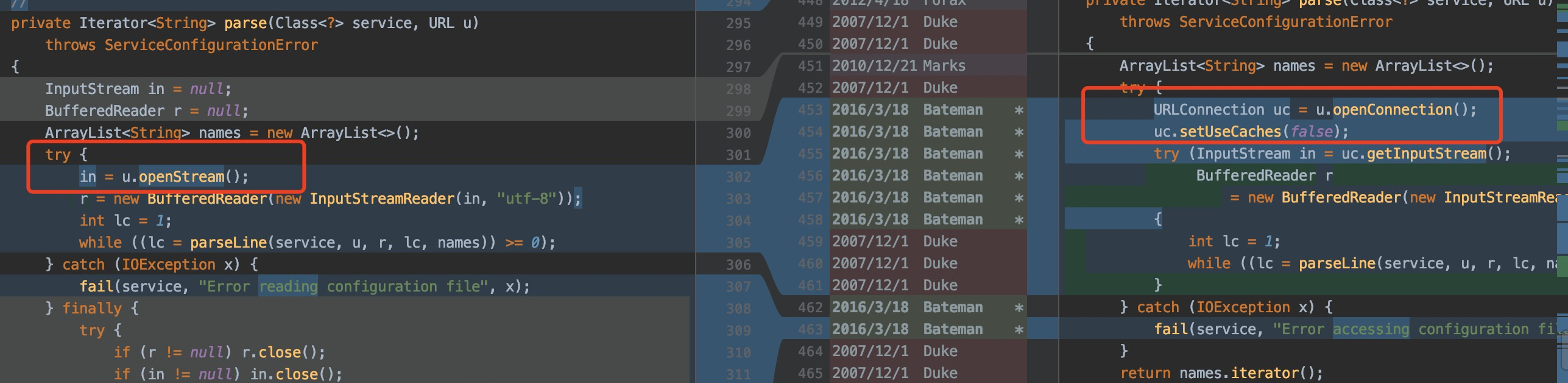
通过使用解决这个问题的jdk11,重启应用后占用的内存从:1.4G下降到1G。
通过pmap查看使用中的64M的内存块从启动之初的15+个降低到5+个。 优化前和优化后效果如下:
[图片正在脱敏处理,稍后提供]
还是有不少的使用的64M存在,是不是哪儿还有缓存内存或者内存泄漏,
通过查找jetty产品的发布log,查查这些版本线都解决了那些bug,网站:
同时也在jetty的论坛上,通过搜索 memory、leak等关键字搜索哪些bug是目前使用版本存在,被高版本修复的,正好定位到一个bug:
确定是jetty扫描资源时的泄漏,这时通过源码确认这个bug并且确定这个bug是在那个时候版本上进行修复的:9.3.4,修复的情况如下,使用try进行资源打开和关闭:

如果想了解为什么关闭inputstram会导致内存泄漏 ,可以看看源码,这个也是和jdk8的默认缓存相关,默认缓存了又不关闭通过 InputStream去关闭或者清理对应的Inflater(end()或者reset()),这不就导致内存泄漏了吗!!!内存泄漏的测试例子可以看下, 其中如果主动关闭资源的话,关闭流程如下所示:

知道这个问题后,将jetty版本升级到解决 这个问题的较高版本,重启应用后:
内存占用从1G降低到600~700M。
64M的使用块1~2个。
四、结论及优化方案
jdk8有bug,这个bug不影响我们的应用,jdk较高版本在ServiceLoader时禁用了缓存,节省了300M的堆外内存使用。-----解决方案:升级到jdk9-111及以上 版本。
AnnotationParser.java 存在未关闭文件流的问题,同时由于jdk8的缓存机制,导致内存泄露。----解决方案:升级jetty-9.3.4及以上版本。
glibc 64M大内存块问题,这是glibc的产品特性,如果多线程高并发的应用,建议使用tcmalloc或者jemalloc,能更好的管理内存。
大功告成了!!!!!!
以上的建议在上生产前,请做好生产压测验证。