极客大学架构师训练营 性能优化 性能测试指标 性能测试 性能优化 CDN 网络 硬盘 缓存 异步 集群 第13课 听课总结
说明
讲师:李智慧
架构师用了很多优化手段,如何给老板证明,性能提升了呢?
性能测试
性能测试是性能优化的前提和基础,也是性能优化结果的检查和度量标准。不同视角下的网站性能有不同的标准,也有不同的优化手段。
主观视角:用户感受到的性能。
(支付转账场景,用户点击转账后,有个倒计时的页面,即时反馈给用户,让用户感受到快。)
客观视角:性能指标衡量的性能。
性能测试指标
不同视角下有不同的性能标准,不同的标准有不同的性能测试指标,网站性能测试的主要指标有响应时间、并发数、吞吐量、性能计数器等。
响应时间
响应时间:指应用系统从发出请求开始到收到最后响应数据所需要的时间。响应时间是系统最重要的性能指标,直观的反映了系统的“快慢”。
并发数
并发数:系统能够同时处理请求的数目,这个数字也反映了系统的负载特性。对于网站而言,并发数即系统并发用户数,指同时提交请求的用户数目,于此相对应,还有在线用户数(当前登录系统的用户数)和系统用户数(可能访问系统的总用户数)。
吞吐量
吞吐量:指单位时间内系统处理的请求的数量,体现系统的处理能力。对于网站,可以用 “请求数/秒” 或是 “页面数/秒” 来衡量,也可以用 “访问人数/天” 或是 “处理的业务数/小时” 等来衡量。
TPS(每秒事务数)也是吞吐量的一个指标,此外还有HPS(每秒HTTP请求数)。
QPS(每秒查询数)。
吞吐量 = (1000 / 响应时间ms) * 并发数
性能计数器
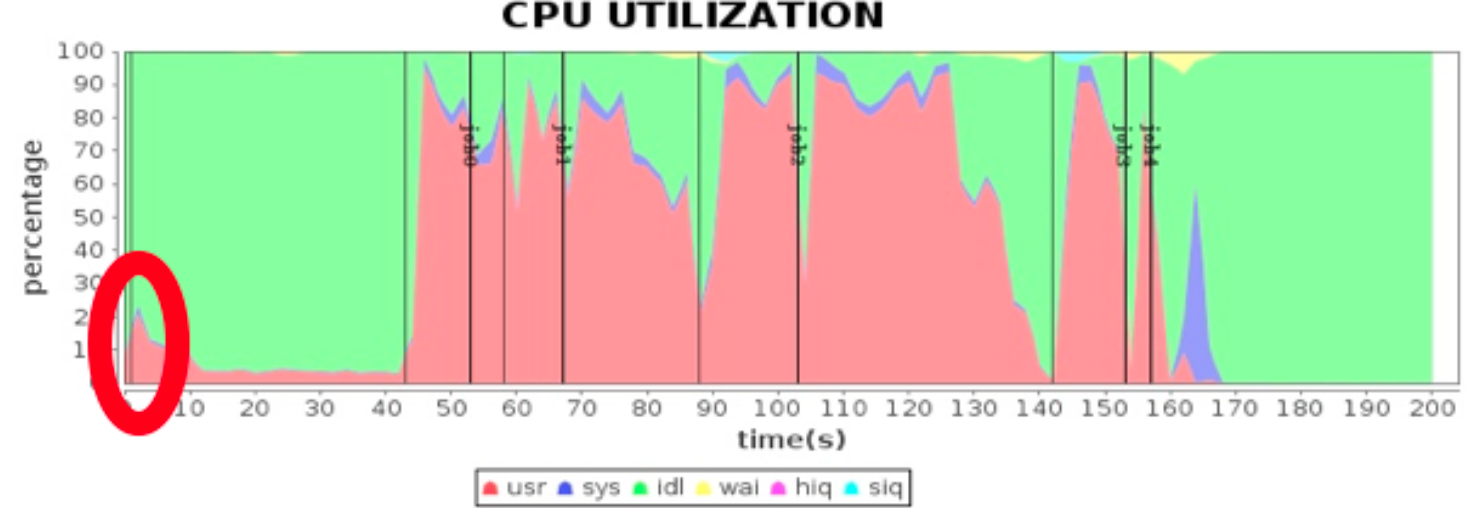
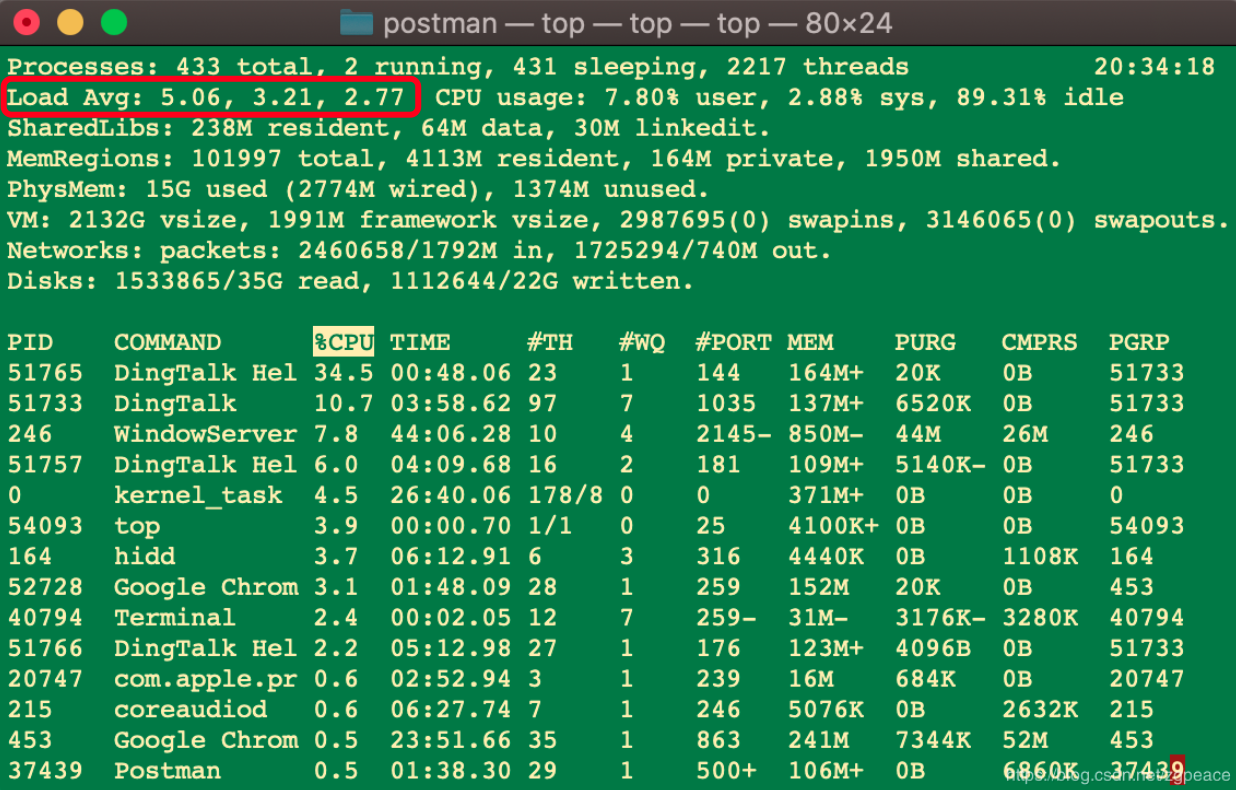
性能计数器:是描述服务器或操作系统性能的一些数据指标。包括 System Load、对象与线程数、内存使用、CPU 使用、磁盘与网络 I/O 等指标。这些指标也是系统监控的重要参数,对这些指标也是系统监控的重要参数,对这些指标设置报警阀值,当监控系统发现性能计数器超过阀值的时候,就向运维和开发人员报警,及时发现处理系统异常。
命令查看,Load Avg:正在处理的线程数 + 正在等待的线程数,三个时间段的平均时间。理想情况下是CPU的核数。
如果大于CPU的核数,表示CPU过载;如果小于CPU的核数,表示CPU空闲,资源利用不足。
性能测试方法
性能测试是一个总称,具体可细分为性能测试、负载测试、压力测试、稳定性测试。
性能测试
以系统设计初期规划的性能指标为预期目标,对系统不断施加压力,验证系统在资源可接收范围内,是否能达到性能预期。
负载测试
对系统不断地增加并发请求以增加系统压力,直到系统的某项或多项性能指标达成安全临界值,如某种资源已经呈饱和状态,这时候继续对系统施加压力,系统的处理能力不但不能提高,反而会下降。
压力测试
超过安全负载的情况下,对系统继续施加压力,知道系统崩溃或不能再处理任何请求,以获得系统最大压力承受能力。
稳定性测试
被测试系统在特定硬件、软件、网络环境条件下,给系统加载一定业务压力,使系统运行一段较长时间,以此检测系统是否稳定。在生产环境,请求压力是不均匀的,呈波浪特性,因此为了更好地模拟生产环境,稳定性测试也应不均匀地对系统施加压力。
TPS
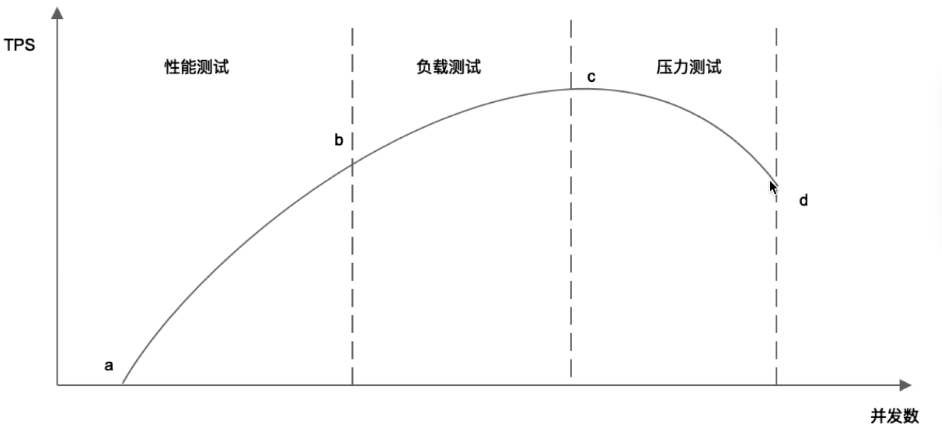
性能测试目标: 要把这条曲线测出来。
性能测试:a~b 并发数增加,TPS快速增加。
负载测试:b~c 并发数增加,TPS增长速度变小。
压力测试:c~d 并发数增加,TPS反而开始下降。
让系统在b点位置左右运行;如果在c点位置左右,那么就很容易系统奔溃了。
到底是在b点位置的左还是右呢?这要依赖于投资多少钱的机器。如果要省钱,那么在b点靠右的位置,安全性会低一点,到达c点比较危险。如果不差钱,那么可以多加机器(比如银行),那么就在b点靠左的位置。
响应时间
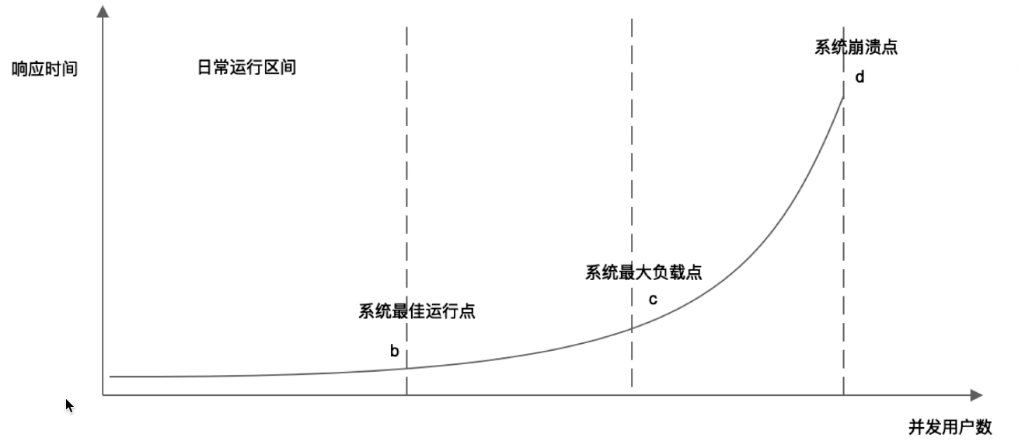
通常瓶颈点在于磁盘和内存数。
并发数 | 响应时间(ms)|TPS | 错误率(%)| Load | 内存(G)| 备注
| - | - | - | - | - | -
10 | 500 | 20 | 0 | 5 | 8 | 性能测试
20 | 800 | 30 | 0 | 10 | 10 | 性能测试
30 | 1000 | 40 | 2 | 15 | 14 | 性能测试
40 | 1200 | 45 | 20 | 30 | 16 | 性能测试
60 | 2000 | 30 | 40 | 50 | 16 | 性能测试
80 | --- | 0 | 100 | --- | --- | 性能测试
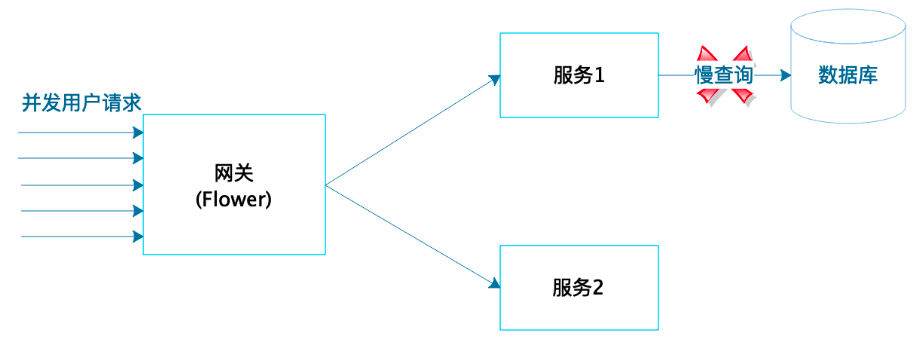
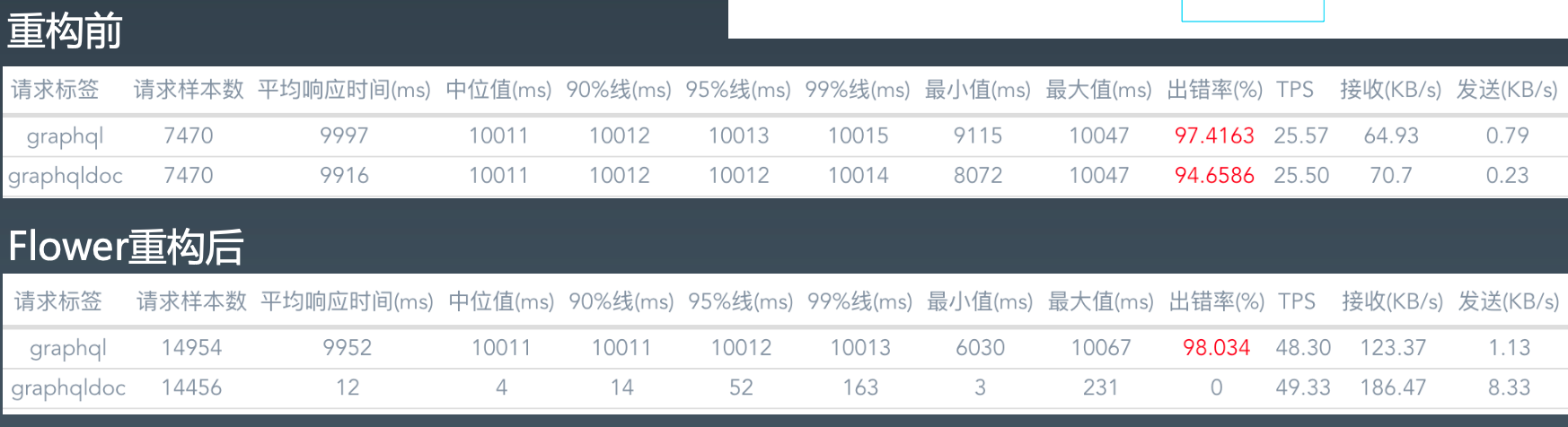
基于Flower的应用重构性能测试
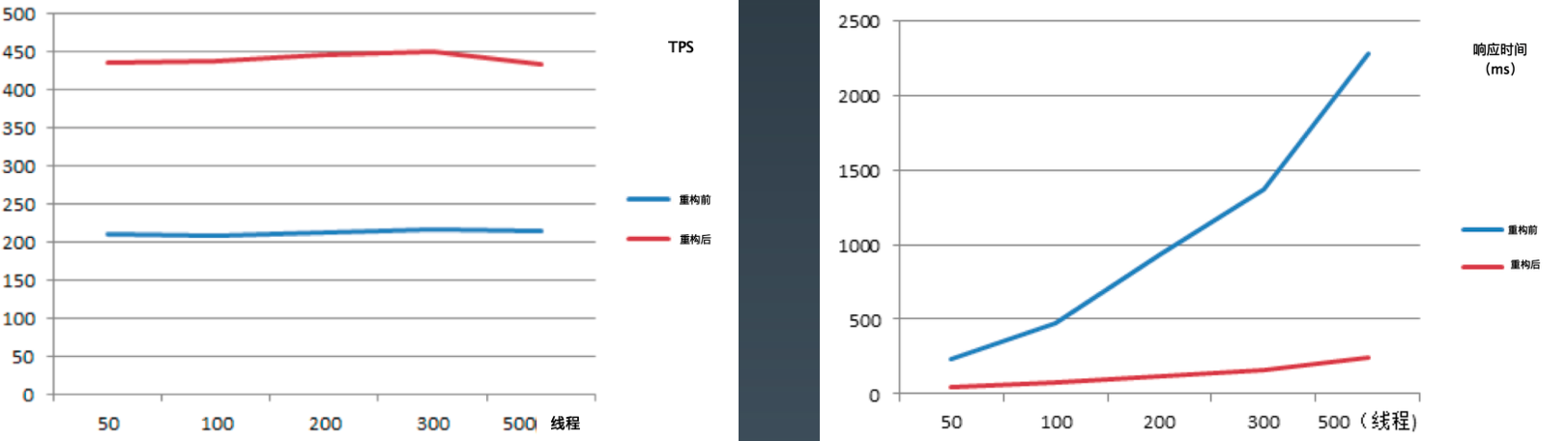
性能测试压测可用性
重构前
Flower重构后
软件性能优化的两个基本原则
你不能优化一个没有测试的软件。
你不能优化一个你不了解的软件。
新来架构师,一看系统就觉的技术架构很落伍,要用业界比较牛的架构重构。一般这种架构师撑不过试用期。别这样,千万别这样。毕竟技术团队花了很长的时间在这套系统里面,要先了解系统。了解问题,比掌握技术更关键。不要盲目的那所谓的牛逼技术到处用。不要拿着锤子🔨去砸钉子,要先找到钉子。
性能测试的主要指标
响应时间:完成一次任务花费的时间。
并发数:同时处理的任务数。
吞吐量:单位时间完成的任务数。
性能计数器:System Load, 线程数,进程数,CPU,内存,磁盘,网络使用率。
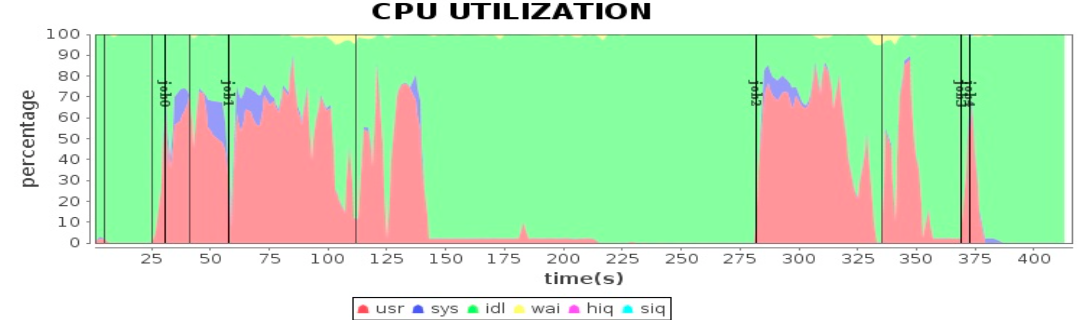
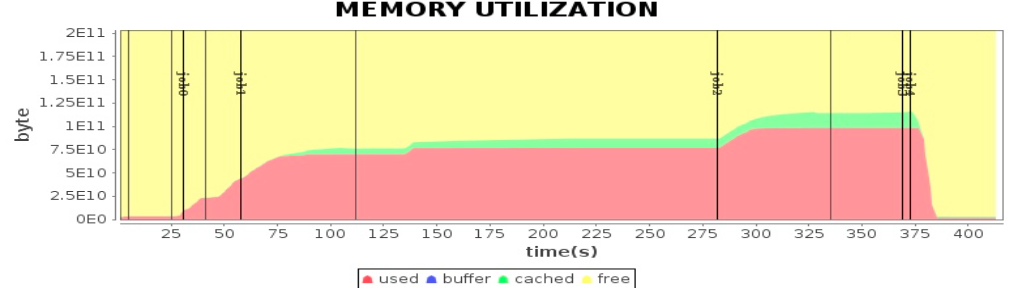
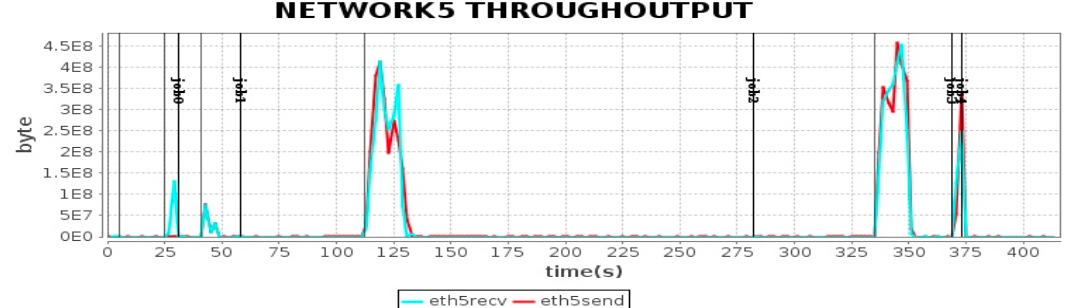
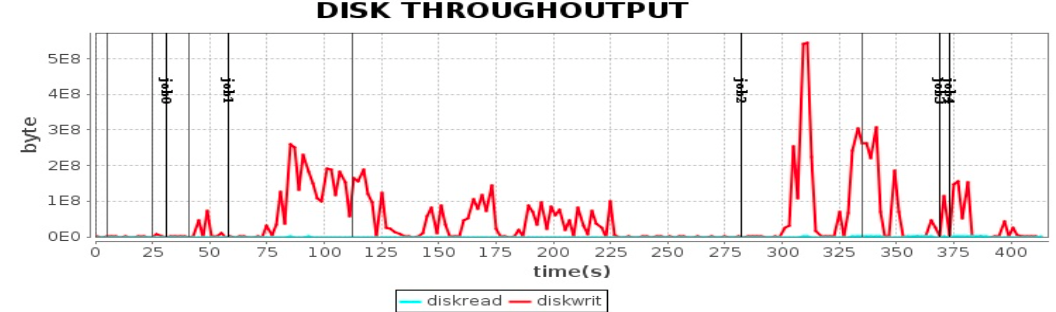
Spark 应用性能测试
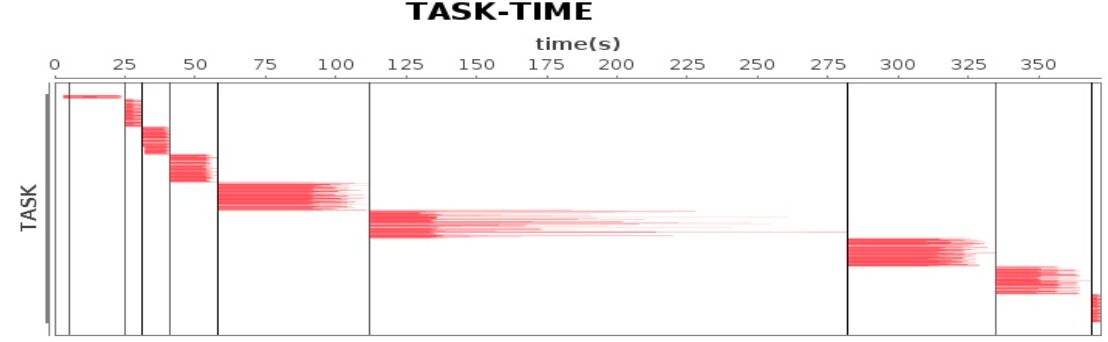
很多个Task在执行
性能优化的一般方法
性能测试,获得性能指标。
指标分析,发现性能与资源瓶颈点。
架构与代码分析,寻找性能与资源瓶颈关键所在。
架构与代码优化,优化关键技术点,平衡资源利用。
性能测试,进入性能优化闭环。
系统性能优化的分层思想
机房与骨干网络性能优化。
服务器与硬件性能优化。(垂直伸缩)
操作系统性能优化。
虚拟机性能优化。(垃圾回收性能优化,锁对性能的优化)
基础组件性能优化
软件架构性能优化
软件代码性能优化
机房与骨干网络性能优化
异地多活的多机房架构。
专线网络与自主 CDN 建设。

从美国到中国网络传输需要300ms左右时间。就近提供机房,让用户快速访问。这是任何软件技术都解决不了的问题。
服务器与硬件性能优化
使用更优的CPU,磁盘,内存,网卡,对软件的性能优化可能是数量级的,有时候远远超过代码和架构的性能优化。

硬件性能优化案例
Spark 作业过程需要传输大量数据,进行资源瓶颈分析,发现大量时间消耗在网络传输上。
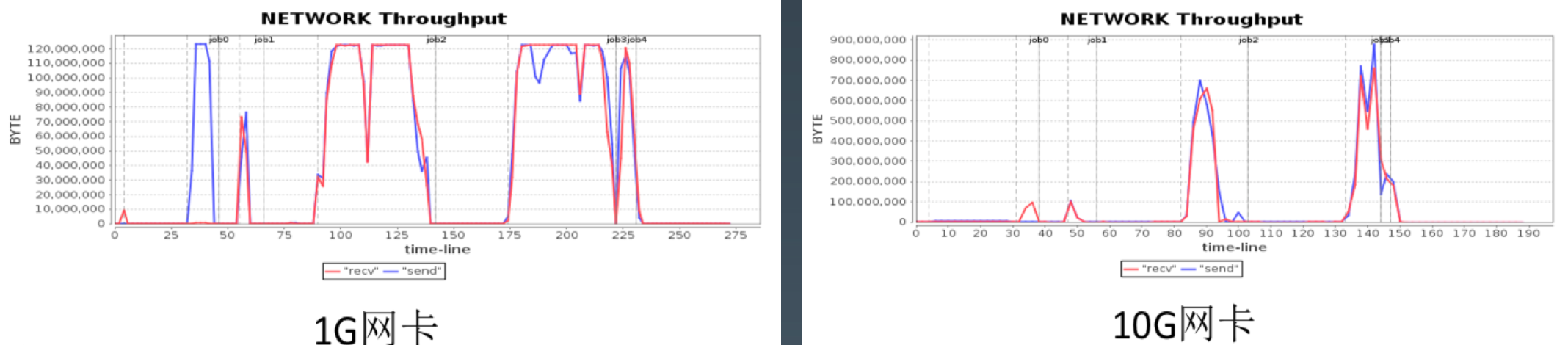
解决方案:压缩数据。(压缩以及解压缩,会增加CPU的负担,得不偿失。)
优化方案:升级网卡,10G网卡代替1G网卡。
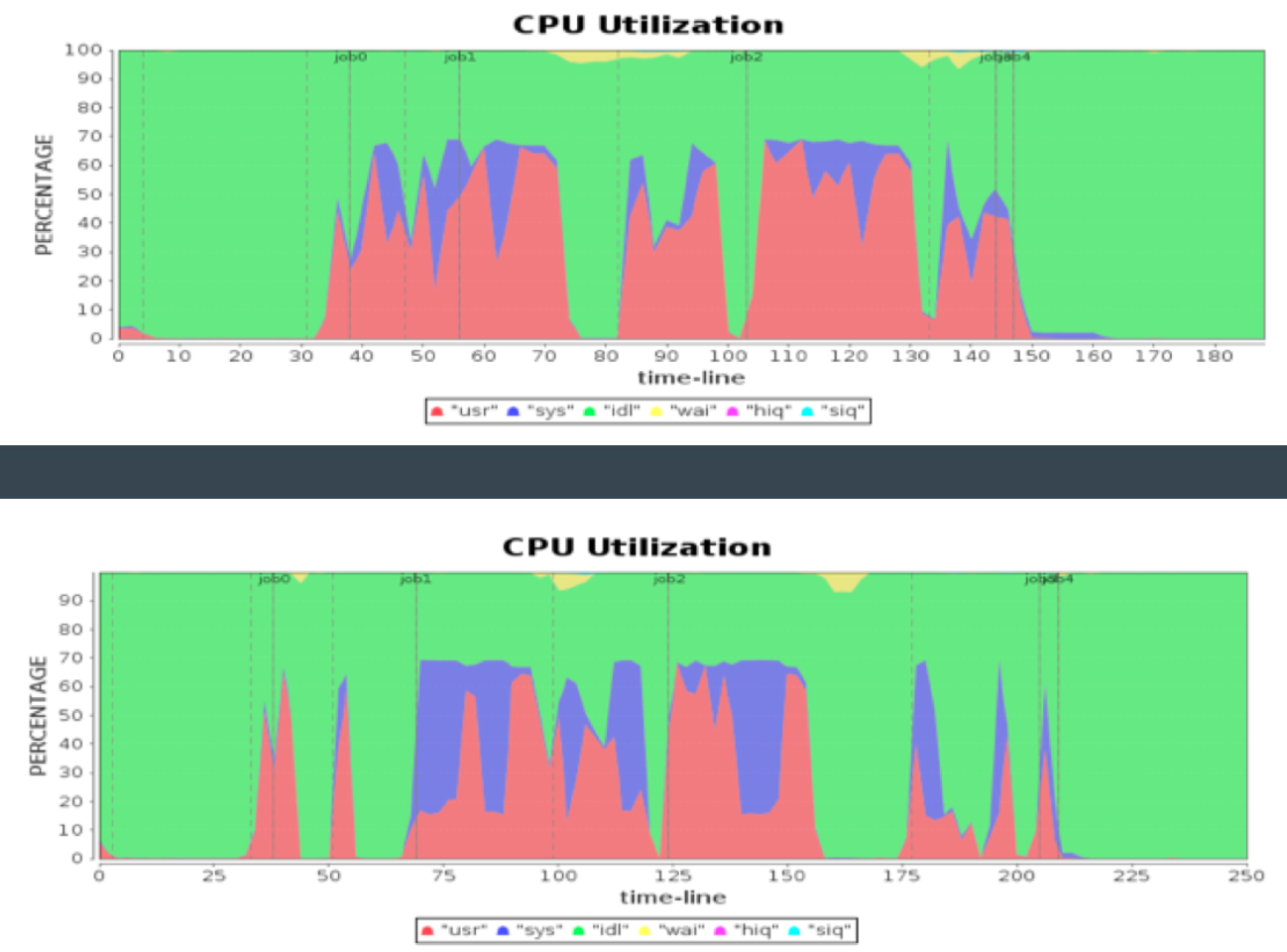
操作系统性能优化案例
资源利用分析,发现大量 CPU 操作为 sys 类型,消耗大量计算资源。
调查发现,起因是部分 Linux 版本缺省情况下打开 transparent huge page 导致。
优化方案:关闭 transparent huge page。
虚拟机性能优化
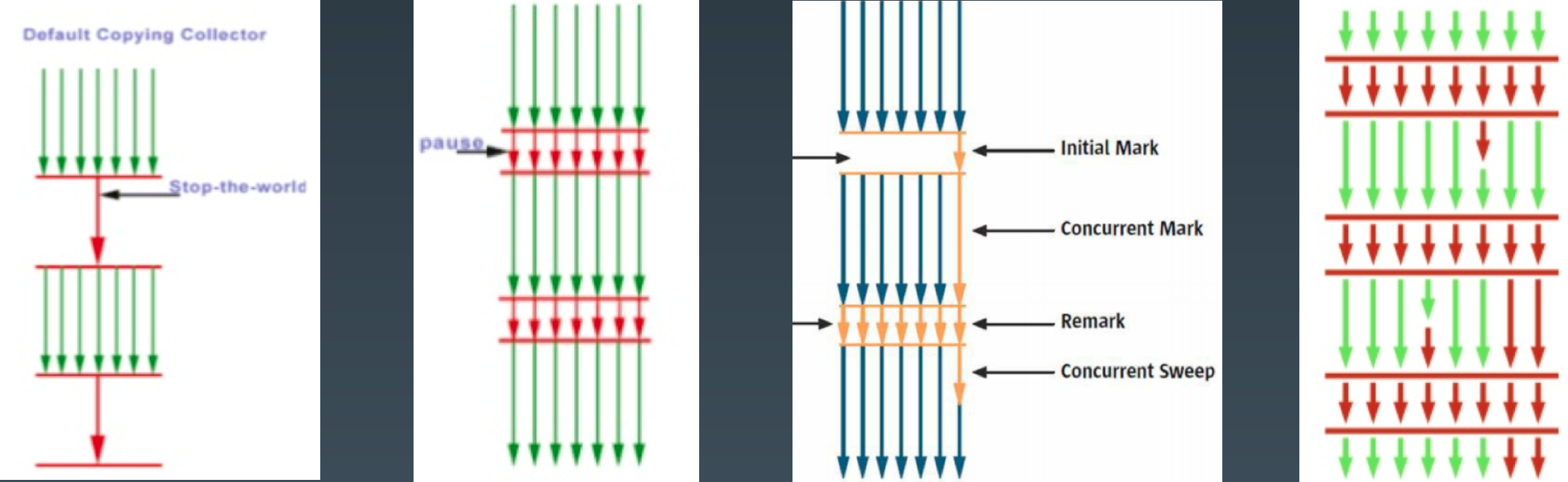
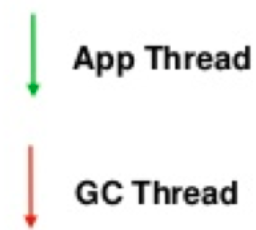
虚拟机垃圾回收的期间,全世界都停下来了。
基础组件性能优化

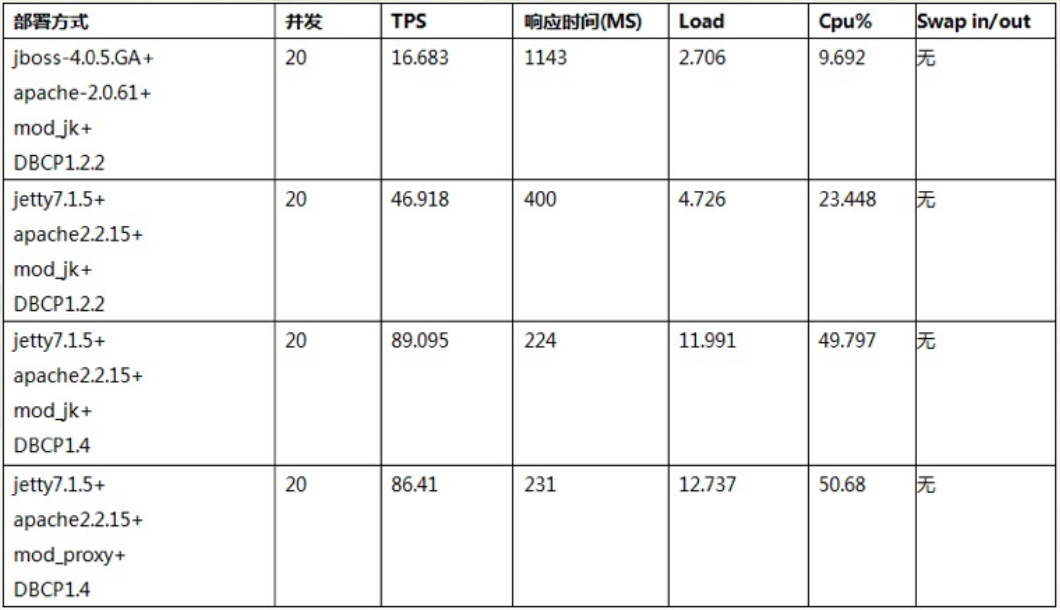
阿里巴巴应用服务器升级项目,采用Jetty 7.1.5 代替 JBoss 4.05 GA。
性能大幅提升,阿里巴巴全站下线 1/3 应用服务器,明年不用采购新机器。
架构更轻量;
配置更简单;
应用更无状态化,开发和维护的福音;
更加安全。
阿里巴巴应用服务器升级项目:
Apache2.2 + Mod - Proxy + Jetty 7.1.5 与阿里巴巴现有架构性能对比
软件架构性能优化三板斧
缓存
异步
集群
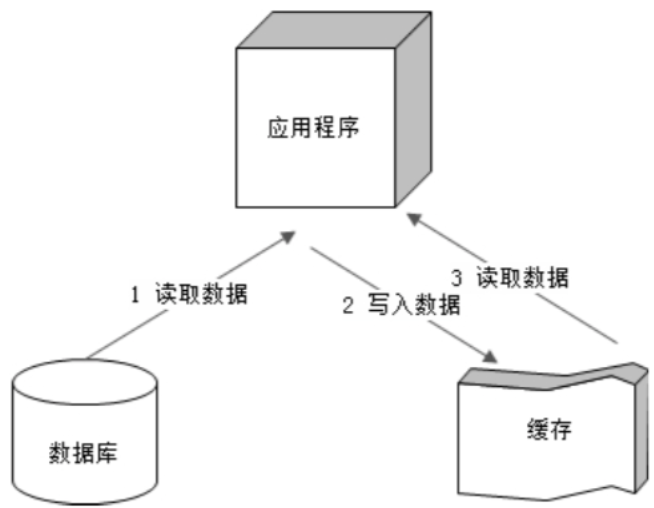
缓存
从内存获取数据,减少响应时间。
减少数据库访问,降低存储设备负载压力。
缓存结果对象,而不是原始数据,减少 CPU 计算。
缓存主要优化读操作。
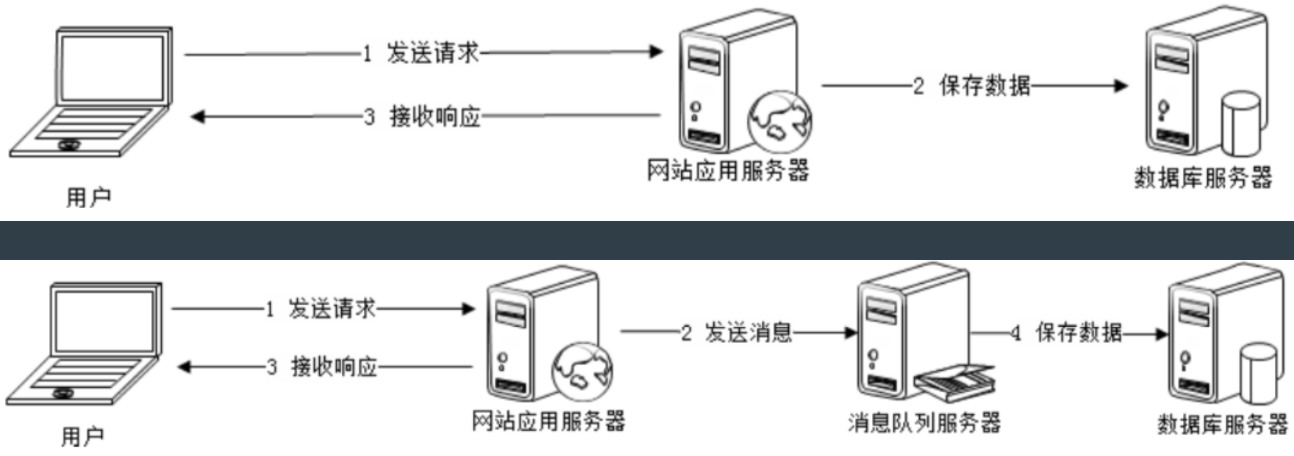
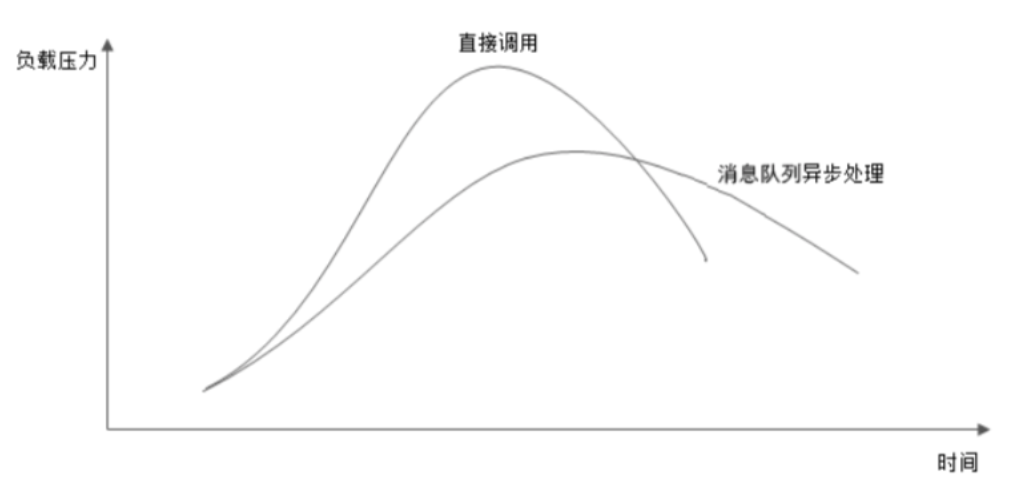
异步
即时响应,更好的用户体验。
控制消费速度,合适的负载压力。
异步主要优化写操作。
集群
古老谚语:如果一匹马拉不动车,无需换一匹更强的马,而是用两匹马拉车。
互联网技术的发展路径是:更多的用户访问需要消耗更多的计算机资源,单一服务器计算资源的增加是有极限的,所以需要增加更多的服务器。关键是如何利用起来这些服务器。
集群的技术目标只有一个:如何使很多台服务器对使用者而言看起来像一台服务器。
2010年京东刚火起来,第一天,服务器崩溃,网站一天不可用。刘强东发一条微博,请信息部喝茶,放了一把刀的图片。第二天,服务器照样崩溃,网站又一天不可用。刘强东再发一条微博,请信息部喝茶,送了信息部900台服务器。第三天,服务器照样崩溃,网站依然一天不可用。科学技术需要技术手段解决,刀子和服务器都不能简单的使用。
软件代码性能优化
遵循面向对象的设计原则与设计模式编程,很多时候程序性能不好不是因为性能上有什么技术挑战,仅仅就是因为代码太烂了。
并发编程,多线程与锁。
资源复用,线程池与对象池。
异步编程,生产者与消费者。
数据结构,数组、链表、hash表、树。
代码优化案例
Spark 任务文件初始化调优
资源分析,发现第一个 stage 时间特别长,耗时长达 14s,CPU 和网络通信有一定开销,不符合应用代码逻辑。

打开 Spark 作业 log,分析这段时间的 Spark 运行状况。
根据 log 分析结果,阅读 Spark 相关源码。
发现 Spark 在任务初始化加载应用代码的时候,每个 Executor 都加载一次应用代码,当时没太服务器最多可启动48个 Executor,每个应用代码包 17M 大小,导致加载开销巨大。
优化方案: Executor 加载应用程序包启用本地文件缓存模式。[SPARK-2713]
优化效果:Stage1 运行时间从14s下降到不到1s。