【Knative系列】一文读懂 Knative Serving扩缩容的原理
本文主要讲解 Knative Serving扩缩容系统的设计原理及实现细节,主要从以下三个方面进行讲解:
Knative Serving 扩缩容系统的组件;
涉及的API;
扩缩容和冷启动时的 控制流和数据流的一些细节;
组件
Knative Serving 是 Knative 系统的核心,而理解 Knative Serving 系统内的组件能更容易了理解 Knative Serving 系统的实现:
了解其中的控制流和数据流的走向,了解其在扩缩容过程中的作用。因篇幅有限,这里只对组件进行简要描述,后续会针对每个组件进行详细的单独讲解。
1. queue-proxy
是 一个伴随着用户容器运行的 Sidecar 容器,跟用户容器运行在同一个 Pod 中。每个请求到达业务容器之前都会经过 容器,
这也是它问什么叫 的原因。
的主要作用是统计和限制到达业务容器的请求并发量,当对一个 Revision 设置了并发量之后(比如设置了5), 会确保不会同时有超过5个请求打到业务容器。当有超过5个请求到来时,会先把请求暂存在自己的队列 里,(这也是为什么名字里有个 queue的缘故)。 同时会统计进来的请求量,同时会通过指定端口提供平均并发量和 rps(每秒请求量)的查询。
2. Autoscaler
是 Knative Serving 系统中一个重要的 pod,它由三部分组成:
PodAutoscaler reconciler
Collector
Decider
会监测 (KPA)的变更,然后交由 和 处理
主要负责从应用的 那里收集指标, 会收集每个实例的指标,然后汇总得到整个系统的指标。为了实现扩缩容,会搜集所有应用实例的样本,并将收集到的样本反映到整个集群。
得到指标之后,来决定多少个Pod 被扩容出来。简单的计算公式如下:
want = concurrencyInSystem/targetConcurrencyPerInstance
另外,扩缩容的量也会受到 中最大最小实例数的限制。同时 还会计算当前系统中剩余多少突发请求容量(可扩缩容多少实例)进来决定 请求是否走 转发。
3. Activator
是整个系统中所用应用共享的一个组件,是可以扩缩容的,主要目的是缓存请求并给 主动上报请求指标
主要作用在从零启动和缩容到零的过程,能根据请求量来对请求进行负载均衡。当 缩容到零之后,请求先经过 而不是直接到 。 当请求到达时, 会缓存这这些请求,同时携带请求指标(请求并发数)去触发 扩容实例,当实例 ready后, 才会将请求从缓存中取出来转发出去。同时为了避免后端的实例过载, 还会充当一个负载均衡器的作用,根据请求量决定转发到哪个实例(通过将请求分发到后端所有的Pod上,而不是他们超过设置的负载并发量)。 Knative Serving 会根据不同的情况来决定是否让请求经过 ,当一个应用系统中有足够多的pod实例时, 将不再担任代理转发角色,请求会直接打到 来降低网络性能开销。
跟 不同, 是通过 websocket 主动上报指标给 ,这种设计当然是为了应用实例尽可能快的冷启动。 是被动的拉取:去 指定端口拉取指标。
API
PodAutoscaler (PA,KPA)
API:
是对扩缩容的一个抽象,简写是 KPA 或 PA ,每个
会对应生成一个 。
可通过下面的指令查看
kubectl get kpa -n xxxServerlessServices (SKS)
API:
是 产生的,一个 生成一个 , 是对 k8s service 之上的一个抽象,
主要是用来控制数据流是直接流向服务 (实例数不为零) 还是经过 (实例数为0)。
对于每个 ,会对应生成两个k8s service ,一个,一个 .
是标准的 k8s service,通过label selector 来筛选对应的deploy 产生的pod,即 svc 对应的 endpoints 由 k8s 自动管控。
是不受 k8s 管控的,它没有 label selector,不会像 一样 自动生成 endpoints。 对应的 endpoints
由 Knative 来控制。
有两种模式: 和
模式下 后端 endpoints 跟 一样, 所有流量都会直接指向 对应的 pod。
模式下 后端 endpoints 指向的是 系统中 对应的 pod,所有流量都会流经 。
数据流
下面看几种情况下的数据流向,加深对Knative 扩缩容系统机制的理解。
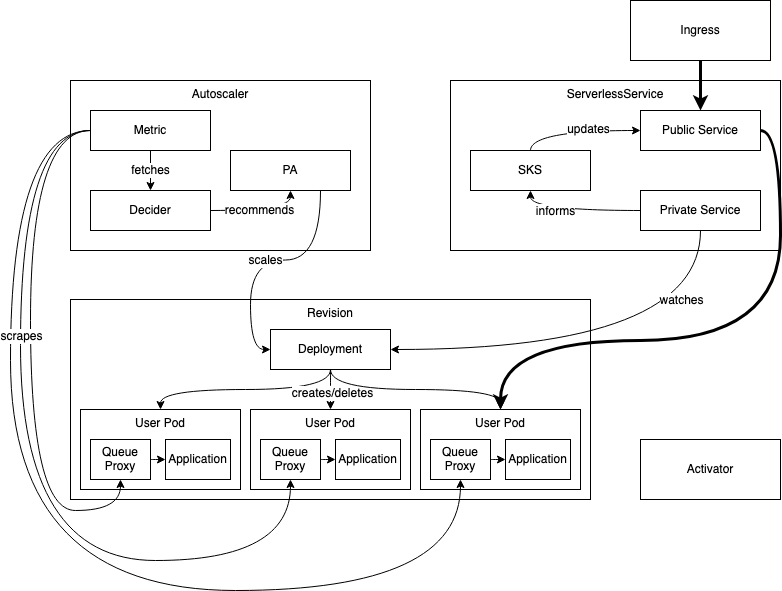
1. 稳定状态下的扩缩容
scale-up-down.png
稳定状态下的工作流程如下:
请求通过 路由到 ,此时 对应的 endpoints 是 revision 对应的 pod
会定期通过 获取 活跃实例的指标,并不断调整 revision 实例。
请求打到系统时, 会根据当前最新的请求指标确定扩缩容比例。
模式是 , 它会监控 的状态,保持 的 endpoints 与 一致 。
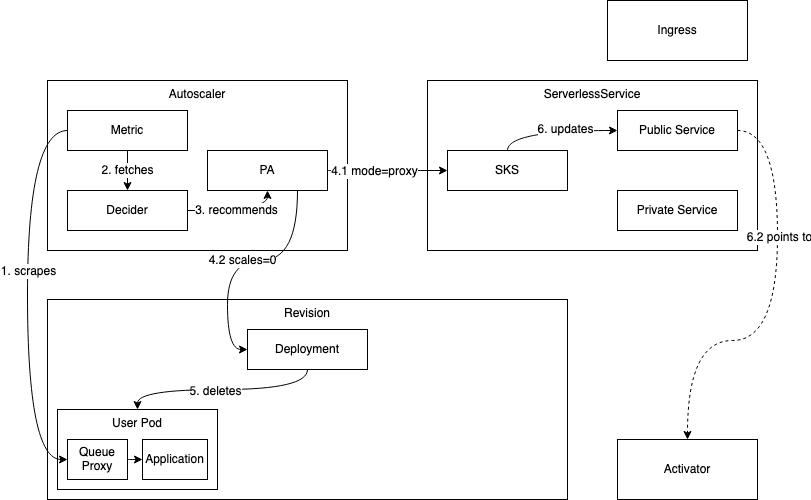
2. 缩容到零
scale-to-0.png
缩容到零过程的工作流程如下:
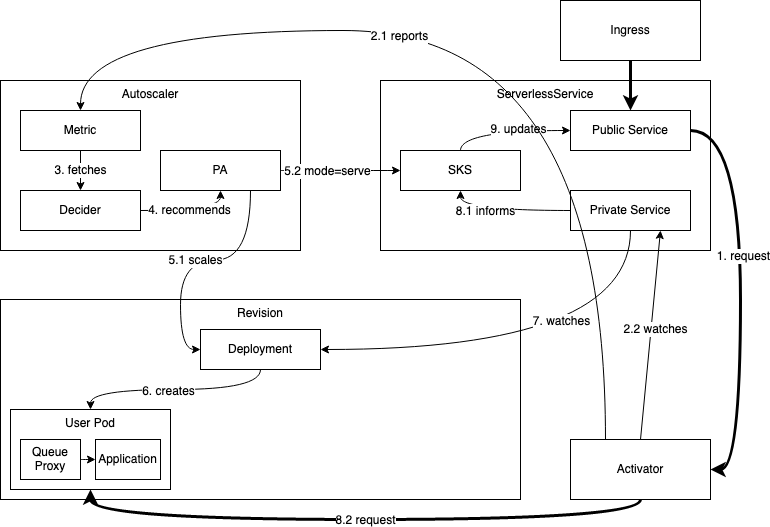
3. 冷启动(从零开始扩容)
scale-from-0.png
冷启动过程的工作流程如下:
当 缩容到零之后,此时如果有请求进来,则系统需要扩容。因为 在 模式,流量会直接请求到 。 会统计请求量并将 指标主动上报到 , 同时 会缓存请求,并 watch 的 , 直到 对应的endpoints产生。
收到 发送的指标后,会立即启动扩容的逻辑。这个过程的得出的结论是至少一个Pod要被创造出来, 会修改 对应 的副本数为为N(N>0), 同时会将 的状态置为 模式,流量会直接到导到 对应的 pod上。
最终会监测到 对应的endpoints的产生,并对 endpoints 进行健康检查。健康检查通过后, 会将之前缓存的请求转发到
健康的实例上。
最终 完成了冷启动(从零扩容)。
本文作者: zhaojizhuang