硬核系列 | 手写脚本语言编译器(一)
前言
本系列博文一共分为3个部分,前2部分,我会聚焦在编译器的前端技术上,站在实战的视角,深入为大家讲解词法分析器、语法分析器的实现过程。而最后一部分,主要侧重讲解编译器的后端技术,并结合之前所学的内容,将AST抽象语法树生成对应的字节码指令,实现一款基于解释型语言的编译器。当然出于私心,也顺便为了回顾下自己尘封已久的汇编语法,我还会直接将语法树生成底层的汇编指令执行。
究竟什么是编译器
所谓编译器,简而言之,就是
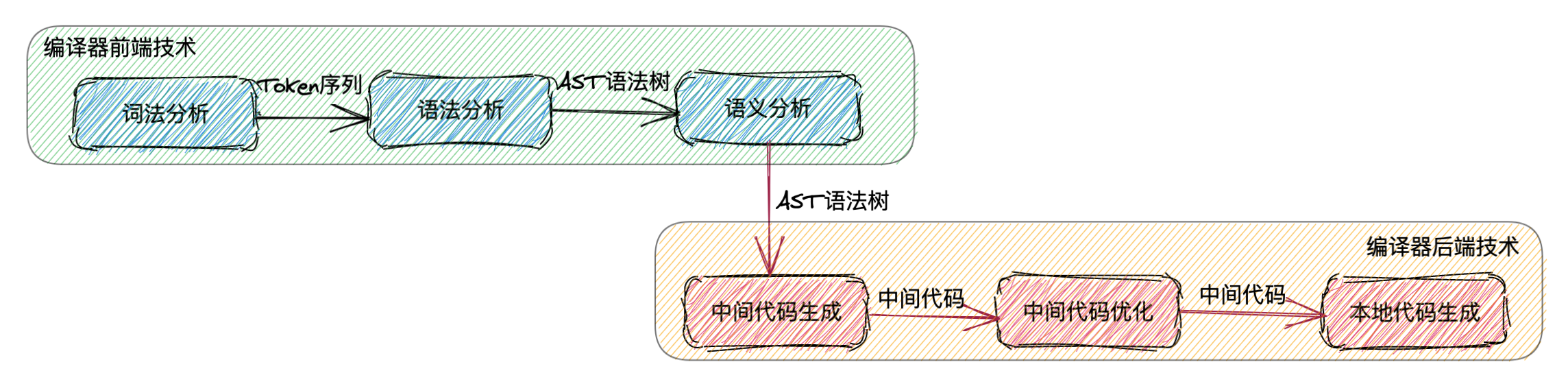
在前端编译技术中,主要包括了词法分析、语法分析和语义分析等3个阶段。其中词法分析是整个编译任务的伊始,其主要作用就是一个字符一个字符的读取源文件中的内容,并根据指定规则将其转换成对应的词法单元(即:Token序列),这里听起来似乎比较抽象,降维解释来说,
当词法分析器将字符序列解析为一个个的Token序列后,编译器接下来就会进入到语法分析阶段,在此大家需要注意,编译器并不会在一开始就将源码中的所有字符序列都转换为Token序列,而是由语法分析器来负责驱动词法分析器,这实际上有点类似于Lazy模式,真正需要用到的时候再解析。
我们都知道,程序中语法没错,并不代表语义没错,比如,二元运算中数值0不能作为除数,但语法却是正确的。因此,当语法分析器解析出AST抽象语法树后,接下来编译器就会进入到前端编译技术的最后一个阶段,即语义分析。
其实在大部分场景下,编译器前端技术的应用场景要远远大于后端,且就纯粹的技术难度而言,后者明显更为复杂,
词法分析器的实现细节
在上一个小节中,我们已经大致清楚词法分析器的主要任务就是负责一个字符一个字符的读取源文件中的内容,然后将这些字符组成词素,最后再转换成对应的Token序列输出。这里我简单解释下词素和Token的对应关系。所谓词素,实际上指的就是读入的字符集合,也称之为字符序列(比如:“abc”是一个词素,“int”同样也是一个词素),
接下来,我们正式开始编写我们的词法分析器。首先,我们需要定义好Token,而Token的构成部分,主要包括如下4部分内容:
tokenAttribute:每个Token都对应着一个属性值; tokenKind:用于表示Token的类型; pos:每一个Token的起始位; length:词素的具体长度;
示例1-1,定义Token类型:
public class Token {
private TokenAttribute attribute;
private TokenKind tokenKind;
private int pos;
private int length;
protected Token(TokenAttribute attribute, TokenKind tokenKind, int pos) {
this.attribute = attribute;
this.tokenKind = tokenKind;
this.pos = pos;
this.length = attribute.getMorpheme().length;
}
// 省略相关的getter方法和toString方法
}TokenAttribute代表着Token所对应的属性值,其中主要包括词素信息和flag标记位。
public class TokenAttribute {
private char[] morpheme;
private int flag;
protected TokenAttribute(char[] morpheme, int flag) {
this.morpheme = morpheme;
this.flag = flag;
}
// 省略相关的getter方法和toString方法
}public enum TokenKind {
// @formatter:off
IDENTIFIER, INT("int"), INTLITERAL(), STRINGLITERAL(), TRUE("true"),
FALSE("false"), BOOL("bool"), IF("if"), ELSE("else"), FOR("for"),
LPAREN("("), RPAREN(")"), RBRACE("}"), LBRACKET("["), RBRACKET("]"),
LBRACE("{"), COMMA(","), DOT("."), EQ("="), NULL("null"),
GT(">"), LT("<"), BANG("!"), TILDE("~"), QUES("?"),
COLON(":"), EQEQ("=="), LTEQ("<="), GTEQ(">="), BANGEQ("!="),
AMPAMP("&&"), BARBAR("||"), PLUSPLUS("++"), SUBSUB("--"), PLUS("+"),
SUB("-"), STAR("*"), SLASH("/"), AMP("&"), BAR("|"),
CARET("^"), PERCENT("%"), LTLT("<<"), GTGT(">>"), GTGTGT(">>>"),
PLUSEQ("+="), SUBEQ("-="), STAREQ("*="), SLASHEQ("/="), AMPEQ("&="),
BAREQ("|="), CARETEQ("^="), PERCENTEQ("%="), LTLTEQ("<<="), GTGTEQ(">>="),
GTGTGTEQ(">>>="), MONKEYS_AT("@"), RETURN("return"), SEMI(";"), VOID("void"),
STRING("string"), ANNOTATION("//"), FLOAT("float"), FLOATLITERAL(), UNKNOWN();
// @formatter:on
public String name;
TokenKind() {
}
TokenKind(String name) {
this.name = name;
}
}而Token类型中的pos属性代表着每一个Token类型的起始位,
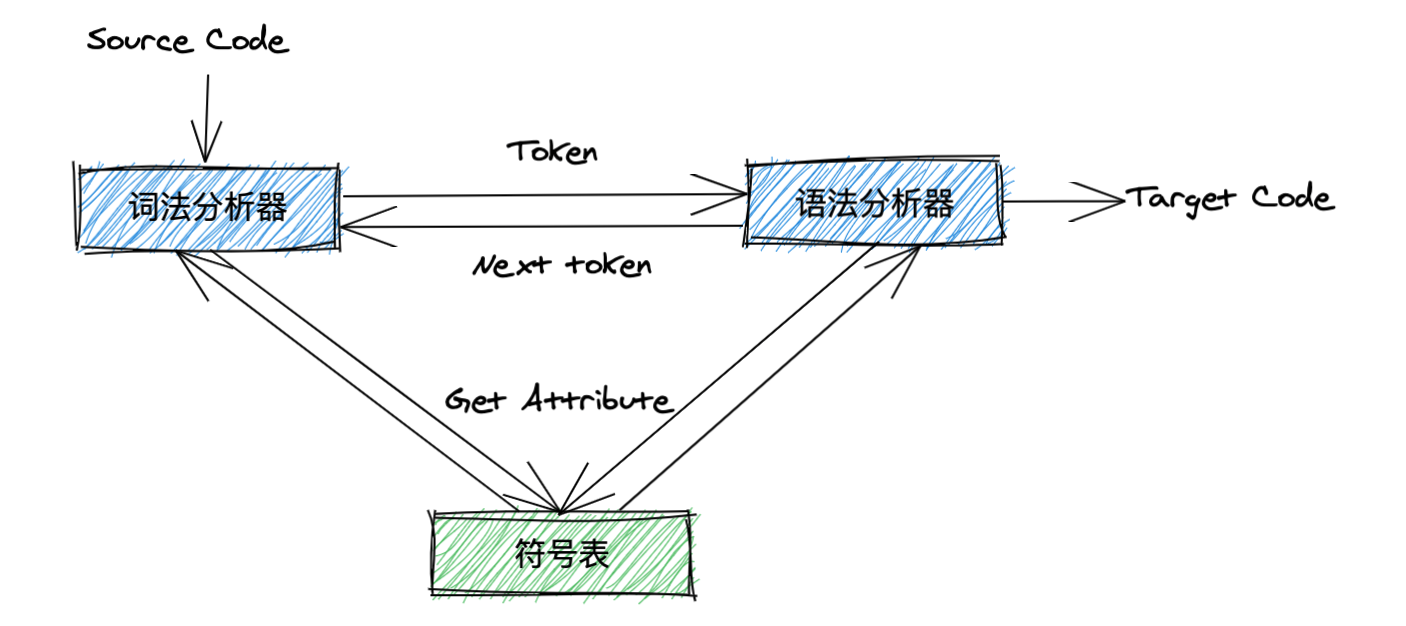
词法分析器在进行词法分析期间会频繁的与SymbolTable(符号表)进行交互,站在词法分析器的视角来看,符号表中记录着每一个与Token对应的TokenAttribute,也就是说,无需为同一个词素去重复创建相同的TokenAttribute。在此大家需要注意,
为每一个保留字都实现一个独立的状态转换流程; 编译器初始化时就将各个保留字记录至符号表中。
关于第1种实现方式,我放在后面再讲,先看第2种更为通用和灵活的实现方式。编译器在初始化阶段就选择将所有的保留字(即:预定义类型)都保存至符号表中,并同时记录每一个词素的字符串长度,最后计算出所有保留字的词素总长,称之为maxFlag。举个例子,假设我们在TokenKind中只定义了INT和FLOAT等2个保留字,那么编译器在初始化时,词素int的TokenAttribute.flag会被指定为3,而记录词素float时,TokenAttribute.flag会被指定为8。换句话说,在符号表中创建TokenAttribute时,其flag值是持续累加的,待初始化结束后,最终maxFlag的值也等于8。当词法分析器在创建一个Token时,会从符号表中获取出对应词素的TokenAttribute(不存在时则创建),如果,则意味着目标词素尚未出现在符号表中,那么它的Token类型就一定是IDENTIFIER,如图4所示。
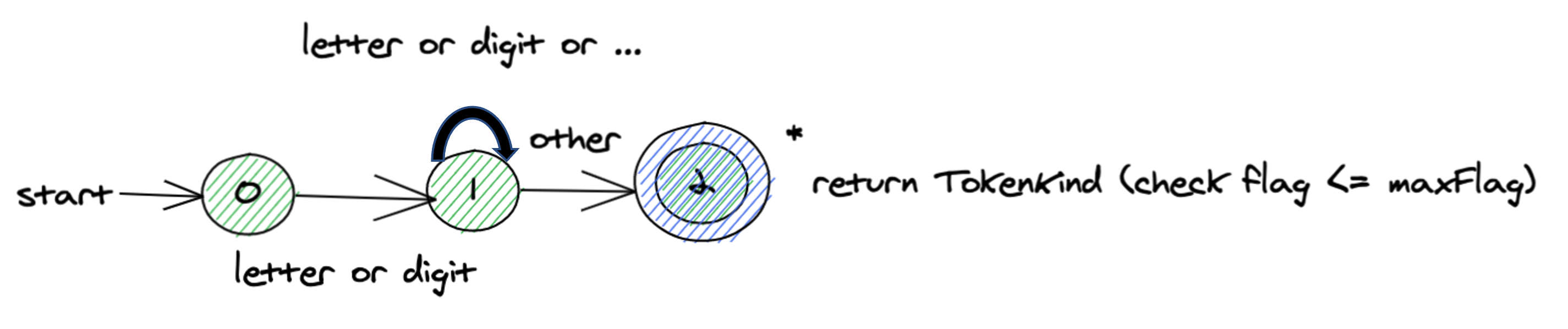
符号表中创建TokenAttribute的核心代码,示例1-4:
protected TokenAttribute getAttribute(char[] morpheme) {
var chars = new Chars(morpheme);
return attributeMap.computeIfAbsent(chars, key -> {
// 每个TokenAttribute.flag标记位的值等于递增的词素长度,用于构建反向索引,从缓存中获取出对应的TokenKin类型
length += morpheme.length;
return new TokenAttribute(morpheme, length);
});
}当然,上述实现方式看起来是比较复杂的(这是Javac编译器的实现方式),当然也可以采用空间换时间的方式,用不同的集合存储不同的TokenAttribute,区分保留字和非保留字,如果在保留字集合中无法获取到对应的TokenAttribute则表示目标词素尚未出现在符号表中。当然具体采用哪种方式,大家则还需要结合实际的业务场景而定。
接下来,我们正式进入到词法分析的核心部分,即实现词法解析的过程。当然,首先我们需要定义好词法分析器接口,明确词法分析器要实现的主要功能有哪些,示例1-5:
public interface SpiderLexer {
/**
* 读取下一个Token序列
*
* @return
* @throws LexerParseException
*/
Token nextToken() throws LexerParseException;
/**
* 回溯到上一个Token
*
* @param pos
*/
void prevToken(int pos);
/**
* 回溯到上一个字符,这里是为了解决预读场景
*/
void prevChar();
/**
* 读取下一个字符
*/
void nextChar();
}当成功定义好功能接口后,接下来我们需要实现SpiderLexer。刚才曾经提及过,我们需要在词法分析器的初始化阶段就将所有保留字记录至符号表中,以便于后续通过比对flag来区分目标Token的具体类型,示例1-6:
protected Scanner init() {
Stream.of(TokenKind.values()).parallel().forEach(tokenKind -> {
var name = tokenKind.name;
if (Objects.nonNull(name) && !name.isBlank()) {
// 根据词素从符号表中获取出对应的TokenAttribute,没有则添加
var attribute = symbolTable.getAttribute(name.toCharArray());
var flag = attribute.getFlag();
// 记录预定义类型的TokenKin序数,与flag相对应
ordinals.put(flag, tokenKind.ordinal());
// 记录预定义类型的标记位,当词素的flag>maxKey时则意味着是标识符
maxflag = maxflag < flag ? flag : maxflag;
}
});
logger.debug("maxflag:{}", maxflag);
return this;
}在上述程序示例中,每一个保留字都会优先被记录至符号表中,然后接下来初始化阶段还会做2件事,首先是存储TokenKind的序数,Key为TokenAttribute.flag,这里相当于构建了一个反向索引,如果在创建Token时,确定是保留字,则通过对应的flag值从TokenKind中获取出对应的Token类型。其次,计算出所有保留字的词素总长至变量maxFlag中。词法分析的过程,实际上就是将有穷自动机的状态转换图转换为代码解析的过程,这一点大家务必要牢记。接下来,我们来看下究竟应该如何读取Token,示例1-7:
public Token nextToken() throws LexerParseException {
// 记录每一个Token的起始位
var pos = index;
Token token = null;
loop:
do {
// 读取下一个字符
nextChar();
switch (ch) {
//@formatter:off
case ' ': case '\t': case Constants.LF: case Constants.CR: case '\u0000':
break;
// 如果是字母或者符号"$"、"_"开头则以标识符的方式读取
case 'A': case 'B': case 'C': case 'D': case 'E':
case 'F': case 'G': case 'H': case 'I': case 'J':
case 'K': case 'L': case 'M': case 'N': case 'O':
case 'P': case 'Q': case 'R': case 'S': case 'T':
case 'U': case 'V': case 'W': case 'X': case 'Y':
case 'Z':
case 'a': case 'b': case 'c': case 'd': case 'e':
case 'f': case 'g': case 'h': case 'i': case 'j':
case 'k': case 'l': case 'm': case 'n': case 'o':
case 'p': case 'q': case 'r': case 's': case 't':
case 'u': case 'v': case 'w': case 'x': case 'y':
case 'z':
case '$': case '_':
// 读取标识符
token = scanIdent(pos);
break loop;
// 读取数字字面值
case '0': case '1': case '2': case '3': case '4':
case '5': case '6': case '7': case '8': case '9':
token = scanNumber(pos);
break loop;
// 读取字符串字面值
case '\"':
token = scanString(pos);
break loop;
case '[': case ']': case '(': case ')':case '.':
case ',': case '{': case '}': case ';':
try{
addMorpheme();
token = getToken(pos);
}finally{
sBuf = null;
}
break loop;
//@formatter:on
default:
// 读取中文标识符或符号
token = Utils.isChinese(ch) ? scanIdent(pos) : scanOperator(pos);
break loop;
}
} while (ch != Constants.EOI);
return token;
}当调用nextToken()方法获取出Token时,词法分析器会判断当前读入的第一个字符是什么?当匹配正则规则时则进入到scanIdent()方法中读取一个完整的标识符。而如果匹配正则规则则进入到scanNumber()方法中读取一个完整的数字字面值,其它以符号,运算符等字符开头的读取规则以此类推。考虑到篇幅限制,本文仅以读取一个完整的标识符为例进行讲解,示例1-8:
private Token scanIdent(int pos) {
while (true) {
switch (ch) {
//@formatter:off
case 'A': case 'B': case 'C': case 'D': case 'E':
case 'F': case 'G': case 'H': case 'I': case 'J':
case 'K': case 'L': case 'M': case 'N': case 'O':
case 'P': case 'Q': case 'R': case 'S': case 'T':
case 'U': case 'V': case 'W': case 'X': case 'Y':
case 'Z':
case 'a': case 'b': case 'c': case 'd': case 'e':
case 'f': case 'g': case 'h': case 'i': case 'j':
case 'k': case 'l': case 'm': case 'n': case 'o':
case 'p': case 'q': case 'r': case 's': case 't':
case 'u': case 'v': case 'w': case 'x': case 'y':
case 'z':
case '$': case '_':
case '0': case '1': case '2': case '3': case '4':
case '5': case '6': case '7': case '8': case '9':
break;
//@formatter:on
default:
// 判断是否是汉子编码
if (Utils.isChinese(ch)) {
break;
}
try {
// 返回Token
return getToken(pos);
} finally {
// 回溯上一个符号
prevChar();
sBuf = null;
}
}
// 组装词素
addMorpheme();
// 预读下一个字符
nextChar();
}
}参考Java语法规范,标识符的第一个字符需要匹配正则规则,而一个完整的标识符由正则规则构成。当词法分析器进入到scanIdent()方法中所读取到的字符不匹配正则规则时退出,并返回目标Token输出。在生成Token并指定其类型时,如果则表示为保留字,反之为Token类型为IDENTIFIER,示例1-9:
private TokenKind getTokenKin(int flag) {
// 如果flag <= maxflag则意味着是Token的类型为预定义类型,反之为标识符类型
if (flag <= maxflag) {
// 根据flag获取预定义类型的TokenKind枚举序数
var ordinal = ordinals.get(flag);
return TokenKind.values()[ordinal];
}
return TokenKind.IDENTIFIER;
}先前我曾经提及过,词法分析器区分Token类型通常有2种比较常见的方式,在示例1-7至1-9中,我为大家演示了保留字的优先录入方式,那么接下来,我们再来看看第1种方式。尽管采用这样的方式比较繁琐和冗余,但作为了解大家还是必须要清楚和掌握的。

采用第1种方式,无非就是为语法中的每一个保留字都构建一个独立的状态转换图,如图5所示。以保留字if为例,在nextToken()方法中,我们需要调整下代码,如果当前字符为‘i’,则推进if关键字的状态,示例1-10:
var state = State.IDENTIFIER;
if('i' == ch){
state = State.IF_1;
}
// 读取标识符
token = scanIdent(pos, state);而scanIdent()方法中,也需要进行相应的状态判断和流程推进,示例1-11:
if('i' == ch && state == State.IF_1){
state = State.IF_2;
}else if('f' == ch && state == State.IF_2){
state = State.IF;
}else{
state = State.IDENTIFIER;
}而最终再返回Token时,我们可以根据当前词素的State来区分出Token类型,示例1-12:
var tokenKind = TokenKind.IDENTIFIER;
if(state == State.IF){
tokenKind = TokenKind.IF;
}
// 返回Token
return getToken(tokenKind,pos);关于词法分析器的其它实现细节,本文就不过过多进行叙述,如果大家感兴趣,可以参考的具体实现。

至此,本文内容全部结束。如果在阅读过程中有任何疑问,欢迎在评论区留言参与讨论。
推荐文章: