JMM的前世今生
最近在研究JMM的时候,看了一些书籍,找了一些资料,发现都只是定义式的讲解JMM是什么,JMM有哪些规则,很多知识点相对零散,没有把JMM的来龙去脉说清楚。鉴于此,本文采用矛盾发展观来进行阐述,力争做到通俗易懂。本文先把JMM的来龙去脉讲清楚(哲学上的“为什么”),然后再讲一下JMM的定义(哲学上的“是什么”),最后就是怎么使用JMM的规则(哲学上的“怎么做”)
一、为什么要有JMM
(1)可见性问题:计算机的出现,是为了加快对任务的处理能力,计算的过程不仅仅需要CPU的参与,还需要和内存、硬盘、IO外设进行交互,至少CPU和内存的交互是少不了的。由于CPU和内存等其他设备之间,速度存在几个数量级的差距,所以引入了"缓存"(Cache),CPU和内存之间有缓存,内存和硬盘之间有缓存,其中CPU和内存之间有一级缓存、二级缓存、三级缓存(速度介于内存和CPU之间),这些缓存大多数安装在CPU芯片内。为了提高CPU的利用率(下文详细描述),cache和CPU之间又增加了StoreBuffer,进而让CPU利用率提高了不少。但是,由于StoreBuffer没有及时的写入到cache里面,造成cache短暂的可见性问题,进而导致内存的可见性问题。
(2)重排序问题:为了更有效的压榨CPU(根据Amdahl定律),使得每个处理器内部的运算都达到最大限度的利用,处理器可能会对执行的任务(代码)进行重排序优化,使得排序后执行的结果和代码执行的结果保持一致。但是,对多线程的重排序,可能会改变程序的执行结果(比如:控制依赖的重排序)。
解决重排序带问题:通过插入特定类型的内存屏障指令来禁止指令的重排序。但是,不同物理机架构支持的内存屏障指令类型不尽相同。常见的处理器允许的重排序类型如下图所示。
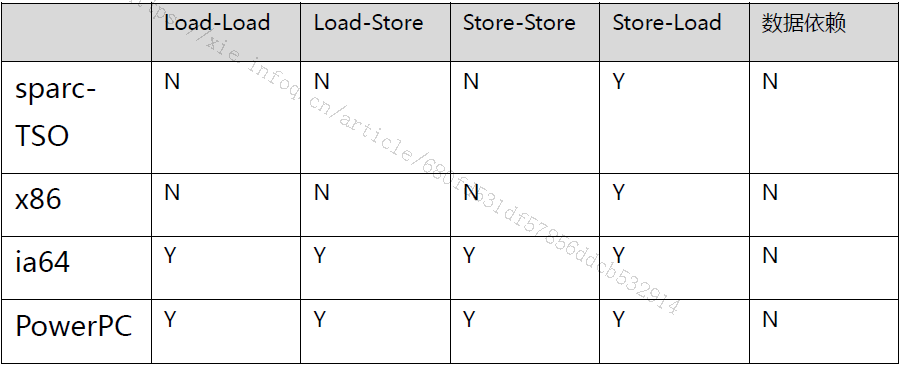
由(1)(2)可以知道,在不同架构的计算机下,会有不同类型的内存屏障,也就有不同的内存模型(内存模型:对内存或者高速缓存进行读写的抽象过程)。程序员写代码需要考虑不同计算机架构的内存模型,大大的增加了开发成本,由此,JAVA虚拟机对不同的内存模型进行再次封装,该层次叫做JAVA MEMORY MODEL,也就是JMM。JMM提供给程序员统一的接口(happens-before规则),JMM内部实现了不同架构物理机的禁止重排序规则,对于程序员来说是透明的。因此,JMM的出现,是为了统一解决可见性问题和统一解决禁止重排序问题(统一方式插入内存屏障),并且还解决了编译器重排序的问题。
二、引申思考
【为什么会重排序】
重排序发生的情况,分为以下几个层次,分别为:CPU对指令的重排序、CPU缓存的写入和读取导致的重排序、编译器对指令的重排序,下面分别进行探讨。
(1)CPU对指令的重排序
【背景】现代CPU的并行技术大多是采用流水线技术。指令的一次重叠执行方式是一种简单的指令流水线。一般的流水线,一条指令的执行过程分解为取指令IF、译码ID、执行EX、写回WB这四个阶段。现在有代码示例如下所示。(为了清楚的了解到CPU对指令的重排序,使用汇编语言来进行讲解,且涉及CPU原理性的问题。)
ADD AX,10 (1)
ADD AX,3 (2)
MOV BX,DX (3)// DX原值为1,BX赋值之前是0
假设在理想条件下,每个阶段需要一个时钟周期,上述汇编代码对应的四个阶段如图3所示。
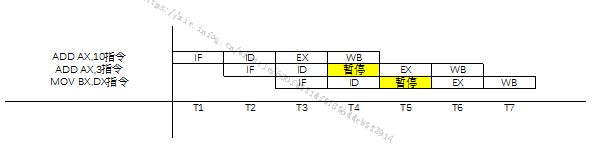
横坐标为时钟周期,总共需要7个时钟周期。从指令(2)的执行依赖指令(1)可以看出,会等待一个时钟周期的时间。指令(3)是因为同一时间同一个CPU原件只能处理一个指令流,所以也出现了一个时钟周期的等待。由于指令(3)不依赖于任何指令,所以可以进行CPU指令重排序,重排序的结果如下所示。

由图4可知,CPU指令进行了重排序,执行三条指令只需要6个时钟周期,比原来更快。此时,假如另外一个线程,有这样一个伪代码如下:
While(BX==1)
print(AX)
return
其中,AX和BX分别指汇编的寄存器(伪代码),当MOV BX,DX执行完,下一时刻,线程2执行上述伪代码(ADD AX,3 没有执行),则AX输出的值为10,并不是13,这是由于重排序导致可见性的问题。如果在“MOV BX,DX”语句前面加上内存屏障,则不会进行重排序。
(2)CPU内存的重排序
该层次的重排序,准确的说是写入缓存造成的重排序,下面以x86为例子,参考书籍《Is Parallel Programming Hard, And, If So,What Can You Do About It?》。
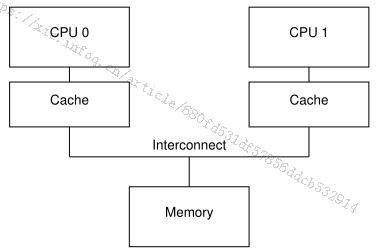
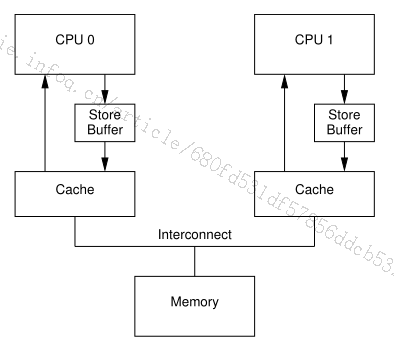
【背景】假设有两个CPU的计算机,分别是CPU0和CPU1,CPU的缓存分别为cache0和cache1, 计算机的缓存架构如图5所示。
问题:当每次从CPU0写数据到cache0的之前,本地cache0都会发送修改指令给其他CPU的cache,比如cache1(由缓存一致性决定的,比如MESI协议),由于其他cpu1的cache1有可能很忙,没办法马上恢复ack给本地CPU0的cache0,本地CPU0可能一直在等待。
解决方案:需要CPU0和cache0之间加上了store Buffer。每当CPU0把写入的数据放在了StoreBuffer里面,CPU0继续做其他的事情,由StoreBuffer来把数据写入到cache0里面(如果cache有命中的数据,则不经过StoreBuffer,直接写入cache),架构如图6所示。
// CPU0 执行以下代码,a在CPU1上,初始值为0
a=1;
b=a+1;
assert(b==2);
问题:假设在StoreBuffer的数据,一直没有写入到cache0里面,然后CPU0先执行其他指令,则相当于把后面的步骤
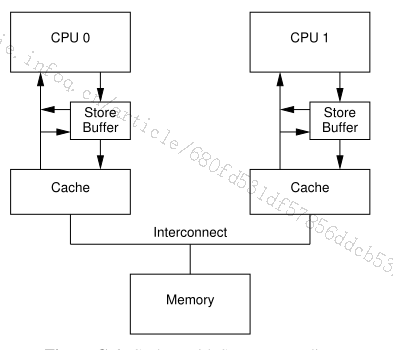
解决方案:每次读取的时候,都从storeBuffer里面读取最新值,可以看见最新的a为1的值,则assert(b==2)成立,改进的架构如图7所示。
// CPU 0 执行 foo(), 拥有 b 的 Cache Line,初始值是 0
void foo()
{
a = 1;
b = 1;
}
// CPU 1 执行 bar(),拥有 a 的 Cache Line,初始值是 0
void bar()
{
while (b == 0) continue;
assert(a == 1);
}
问题:本地cache只能看见内存或者其他CPU的cache,不能看见其他CPU的storeBuffer,如上面代码所示。(1)CPU0上初始状态cache0有b=0,执行结束之后,storeBuffer有a=1的数据,cache0直接赋值b=1,由于缓存一致性原理,cache0通知cache1,cache1的b=1;(2)CPU1上跳出while循环(b找到CPU1的chache1为b=1),于是找到本地cache1 中a=0(错误的,由于没有响应到CPU0的最新值a=1),所以导致assert(a == 1)失败,相当于把assert(a= = 1)提前执行,造成foo函数执行的结果对bar
// CPU 0 执行 foo(), 拥有 b 的 Cache Line,初始值是 0
void foo()
{
a = 1;
smp_wmb();
b = 1;
}
// CPU 1 执行 bar(),拥有 a 的 Cache Line,初始值是 0
void bar()
{
while (b == 0) continue;
assert(a == 1);
}
解决方案:如上面代码所示,在代码里面插入smp_wmb(),smp_wmb()的作用是强制把smp_wmb()(写屏障)语句后面所有的赋值语句有放入storeBuffer,不管有没有在cache上(没有smp_wmb():cache上有缓存,直接赋值,不经过StoreBuffer),当CPU1看见b!=0的时候,说明CPu0的storeBuffer已经把a和b写入cache0,使得CPU1的chche1同步更新。
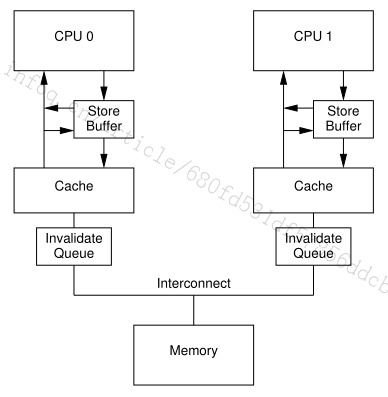
架构调整:如果StoreBuffer(有限大小)写满了(StoreBuffer没有及时收到其他cache的Invalidated ack),CPU还是会出现等待的状态,所以就会先向其他CPU发送Invalidate指令到其他CPU的Invalidate Queue队列里面,其他队列的CPU会消费Invalidate Queue里面的值。如果自己的缓存设置了Invalidated状态,等需要用到数据了再请求其他CPU的cache或者内存,模型如图8所示。
// CPU 0 执行 foo(), a 处于 Shared,b 处于 Exclusive
void foo()
{
a = 1;
smp_wmb();
b = 1;
}
// CPU 1 执行 bar(),a 处于 Shared 状态
void bar()
{
while (b == 0) continue;
assert(a == 1);
}
问题:如上面代码例子所示,(1)CPU0执行完之后,假设storeBuffer被执行完,则a=1,b=1(cache0里面),并发送invalidated信号给cache1的a和b,说明缓存无效。(2)当CPU1执行的时候,发现b在cache1里是无效的,则读取CPU0的cache0的值(b为1),则跳出循环,此时CPU1的Invalidate Queue没有被执行完成(还剩a是invalidate的元素),则还是使用CPU1的cache1的a的值(此时在CPU1中,a=0),则不符合程序期望。相当于assert(a==1)重排序到了最前面。造成foo函数修改a的值对bar函数
// CPU 0 执行 foo(), 拥有 b 的 Cache Line
void foo()
{
a = 1;
smp_wmb();
b = 1;
}
// CPU 1 执行 bar(),拥有 a 的 Cache Line
void bar()
{
while (b == 0) continue;
smp_rmb();
assert(a == 1);
}
解决方案:如上面代码所示,增加smp_rmb()方法(读屏障),强制使得本地CPU的InvalidateQueue被清理完成,处理cache的数据,使得CPU1的cache1的InvalidatedQueue全部被处理完,也就是cache1的a和b的值都变成invalidated状态。当需要cache1的a和b的值的时候,读取CPU0的cache0,即可以读取到最新值。
(3)编译器重排序
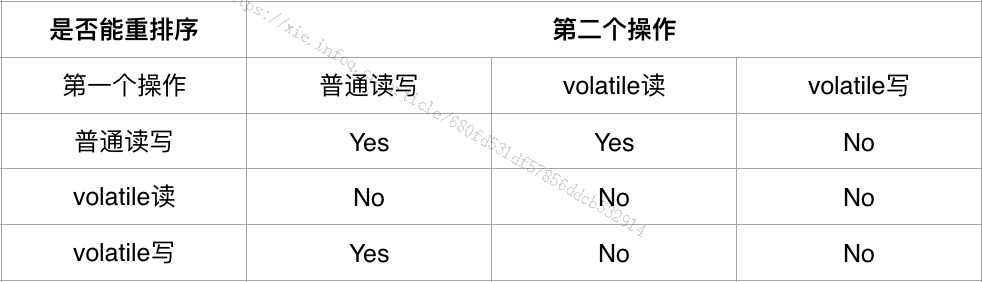
对于没有先后依赖关系的语句,编译器可以重新调整语句的执行顺序。这种重排序应该很好理解,目的和CPU指令重排序类似,都是为了缩短执行时间,但是在多线程的条件下,就会产生可见性问题。比如:JMM针对编译器制定的关于volatile重排序如图9所示。
三 、JMM是什么
JMM(java Memory Model)屏蔽掉各种操作系统和硬件的内存访问差异,使得java程序在各种操作系统和硬件环境下,达到一致的内存访问效果。JMM是一种在多样环境下对内存统一访问的模型。
四、怎样用JMM
JSR-133使用happens- before的概念来阐述操作之间的内存可见性。在JMM中,如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须要存在happens-before关系。这里提到的两个操作既可以是在一个线程之内,也可以是在不同线程之间。与程序员密切相关的happens-before规则如下。
1)程序顺序规则:一个线程中的每个操作,happens-before于该线程中的任意后续操作。
2)监视器锁规则:对一个锁的解锁,happens-before于随后对这个锁的加锁。
3)volatile变量规则:对一个volatile域的写,happens-before于任意后续对这个volatile域的读。
4)传递性:如果A happens-before B,且B happens-before C,那么A happens-beforeC。
5)start()规则:如果线程A执行操作ThreadB.start()(启动线程B),那么A线程的ThreadB.start()操 作happens-before于线程B中的任意操作。
6)join()规则:如果线程A执行操作ThreadB. join()并成功返回,那么线程B中的任意操作happens-before于线程A从ThreadB. join()操作成功返回。
五、常见问题
(1)x86架构下,为什么只有StoreBuffer屏障有用?
下面举个例子来补充说明不同的CPU模型使用不同的内存屏障,比如x86的架构,强制CPU必须先写入StoreBuffer,再写入cache(这就不需要StoreStore屏障来保证),没有InvalidateQueue(这就不需要LoadLoad和LoadStore屏障来保证),所以x86只有StoreLoad屏障有起到禁止重排序的作用。
(2)x86架构下,为什么StoreLoad屏障是使用Lock前缀?
在C语言层面,内存屏障分为StoreStore屏障、StoreLoad屏障、LoadLoad屏障和LoadStore屏障。这四种屏障在Openjdk里面,根据不同的CPU架构翻译成不同的语句。比如“hotspot/os_cpu/linux_x86/orderAccess_linux_x86.hpp”路径下的源码如下所示,使用Lock前缀的性能比直接使用StoreLoad屏障更有效率,也可以实现StoreLoad的语义。其他三种屏障都译成编译器屏障。
#ifndef OS_CPU_LINUX_X86_ORDERACCESS_LINUX_X86_HPP
#define OS_CPU_LINUX_X86_ORDERACCESS_LINUX_X86_HPP
// Included in orderAccess.hpp header file.
// Compiler version last used for testing: gcc 4.8.2
// Please update this information when this file changes
// Implementation of class OrderAccess.
// A compiler barrier, forcing the C++ compiler to invalidate all memory assumptions
static inline void compiler_barrier() {
__asm__ volatile ("" : : : "memory");
}
inline void OrderAccess::loadload() { compiler_barrier(); }
inline void OrderAccess::storestore() { compiler_barrier(); }
inline void OrderAccess::loadstore() { compiler_barrier(); }
inline void OrderAccess::storeload() { fence(); }
inline void OrderAccess::acquire() { compiler_barrier(); }
inline void OrderAccess::release() { compiler_barrier(); }
inline void OrderAccess::fence() {
// always use locked addl since mfence is sometimes expensive
#ifdef AMD64
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#endif
compiler_barrier();
}
inline void OrderAccess::cross_modify_fence() {
int idx = 0;
#ifdef AMD64
__asm__ volatile ("cpuid " : "+a" (idx) : : "ebx", "ecx", "edx", "memory");
#else
// On some x86 systems EBX is a reserved register that cannot be
// clobbered, so we must protect it around the CPUID.
__asm__ volatile ("xchg %%esi, %%ebx; cpuid; xchg %%esi, %%ebx " : "+a" (idx) : : "esi", "ecx", "edx", "memory");
#endif
}
#endif // OS_CPU_LINUX_X86_ORDERACCESS_LINUX_X86_HPP
(3)在x86处理器(Linux)中,哪些汇编指令有内存屏障的语义:
1)对 I/O 端口进行操作的所有指令。
2)有Lock前缀的所有指令。
3)写控制寄存器、系统寄存器或者调试寄存器的所有指令(例如:cli和sti,用于修改eflags寄存器的IF标志的状态)。
4)在Pentium 4微处理器中引入的汇编语言指令lfence、sfence和mfence,他们分别有效地实现读内存屏障、写内存屏障和读写内粗屏障。
5)少数专门的汇编语言指令,种植中断处理程序或者异常处理程序的iret指令就是其中的一个。
(4)在x86架构下,写入数据之后加一个写 Barrier 去刷缓存到主存,读数据之
前加入 Barrier 去强制从主存读?
上述说法错误。由上文描述可知,写入数据之后加一个写 Barrier 去把StoreBuffer强制刷新到cache,读数据之前加入 Barrier 去强制把InvalidatedQueue消费掉。
【参考资料】
(3)《JAVA并发编程的艺术》
(4)《深入理解Java虚拟机》
(5)《Understanding the Linux Kernel》
(7)《计算机系统结构》