现代分布式架构设计原则-分布式
1. 分布式
分布式系统理论体系,是现代企业架构设计的重要理论基础。随着架构的发展,分布式系统产生的目的,是为了提供比单机应用更高的性能、更强的伸缩性和可靠性。
当我们研究分布式时,我们几乎总是在围绕一个主题:如何将多台计算机组合起来,使其对外的表现好像是一台功能强大的单一计算机一样。这个主题和很多因素关系密切,这些因素也构成了本章的基本骨架。
在本章,我们将讨论分布式技术的基本原理。从拓扑结构开始说起,剖析当前分布式系统的几种常见拓扑,如主从式拓扑、主主式拓扑、无主式拓扑,等等。
在拓扑的基础上,我们进一步来探讨客户端的各种读写策略。不同的客户端读写策略,会影响到不同的一致性语义、可用性方案和容错机制。
当客户端从分布式系统中读写数据时,通常会利用分片的机制使得数据能够在各节点上均匀分布,提供更高的读写性能和冗余、可靠性。要想提升可靠性,势必要对数据进行复制,实现多副本存储。
当数据产生了复制和多副本时,一致性问题就出来了,一致性模型和会话模型是许多分布式专家研究的重要课题。在一致性模型和会话模型章节,我们会重点讨论常见的一致性语义以及实现方式,并权衡各种方案的利弊。
分布式系统的一个重要特性就是容错。在这一章,我们会讨论两种常见的网络系统模型以及常见的故障模型。另外,会介绍常见的故障检测方法以及Leader选举方式。
在事务这一章节,我们会讲解事务的基本特性、隔离级别与并发控制,并以此为契机,延伸到分布式事务领域,讨论2PC、3PC及其他的分布式事务实现方式。
分布式共识是一种基础的算法,它是一致性和事务实现的基础。在这一章节,我们讨论分布式算法的安全性(Safety)和活性(Liveness),以及分布式共识的几个基本条件。并以此为理论基础,讲解常见的共识算法如Paxos、ZAB、Raft,等等。
在深入讨论完分布式系统本身之后,我们在通信这一章节介绍常见的客户端与分布式系统之间的通信协议、序列化,以及常见的分布式框架等。
1.1 拓扑结构
在分布式系统中,拓扑结构是一个至关重要的概念。客户端的读写策略、数据的分片与复制机制、系统的一致性与会话模型、分布式事务和共识算法等基本理论以及具体实现都和拓扑结构密切相关。在本章节,我们将常见的分布式系统拓扑结构抽象成三大类:主从式结构、多主式结构和无主式结构。
1.1.1 主从式结构
主从式拓扑结构,是当前使用较为广泛的一种架构,如图 1‑1所示。主从式结构也称为单主式结构,由一个Leader节点和多个Follower节点组成。数据写入方面,Leader节点负责处理客户端发送过来的写请求,将数据更新写入本地存储,并以同步或异步的方式复制到各Follower节点。数据读取方面,存在不同的读场景,可以灵活变化,比如Leader节点本身也可以承担一部分读流量,而Follower节点通常会根据一定的负载均衡策略负责读请求,当然也有可能仅用作备份,不提供读服务。
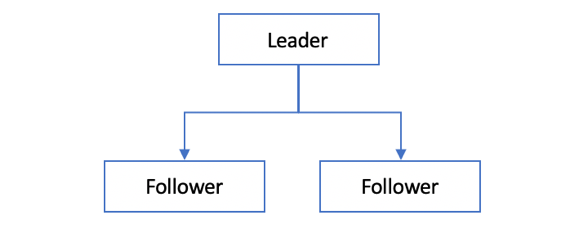
图 1‑1 主从式结构
主从式拓扑结构由于其架构简单明了、易于理解和操作简便,在实际生产环境中普遍存在,很多存储、缓存及消息中间件都使用了主从式结构。如MySQL主从式集群架构、MongoDB复制集架构、Redis主从式架构、Kafka分区的Leader与ISR,等等。主从式结构的弊端是系统存在单点故障风险,当Leader宕机后,需要通过故障检测机制识别并且触发新的Leader选举。
1.1.2 多主式结构
多主式结构,通常包括两个到多个Leader节点,每个Leader节点自身又会形成一主多从的拓扑结构,如图 1‑2所示。多主式结构又称为主主(Active-Active)复制结构,各个Leader节点之间双向交换数据变更,Leader和Follower之间又会单向复制。
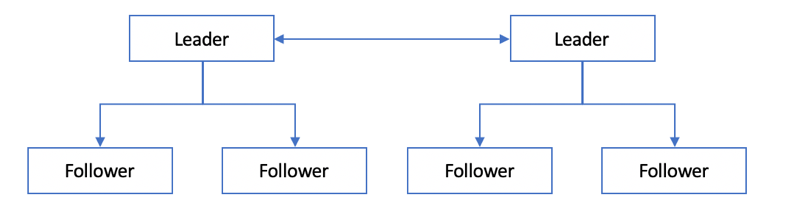
图 1‑2 多主式结构
多主式结构一般用在跨数据中心的场景比较多,涉及到数据更新的异步复制。多主式结构相对主从式结构带来的好处显而易见:
更高的性能:多主式结构的每个Leader-Follower单元可以部署在独立的数据中心,该数据中心内部由Leader负责写请求,数据读写仅需在本地操作,无需跨越数据中心。这种方式由于没有跨地理位置的网络传输,性能更佳。
更强的可靠性:传统主从式(单主)拓扑结构由于单点问题,面临着可靠性的挑战,当出现主节点宕机、网络延迟丢包、网络分区等不可预知的故障时,系统的故障检测和主从切换就显得尤为重要。对于多主式结构来说,由于多个Leader节点的存在,冗余度较高,单一Leader宕机或网络出现故障,剩下的Leader还可以继续工作,甚至对当前的数据中心毫无影响。很明显,多主式结构具备更强的可靠性,抗风险能力更强。
多主式结构也引入了更大的技术挑战,对于主主复制而言,由于同一条数据的写入可能会同时在多个Leader节点上进行,因此数据的复制必然会引起冲突,如何解决写冲突是一个很重要的研究课题。另外,由于多数据中心的存在,复制的延迟也是一个亟待解决的问题。
1.1.3 无主式结构
无主式结构,也称为为去中心或无中心式架构,顾名思义,整个分布式系统不存在任何Leader或Follower角色,节点间无主从关系,如图 1‑3所示。无主式结构集群内部,节点间一般会通过通讯协议来互相交换信息和感知彼此的状态变化。
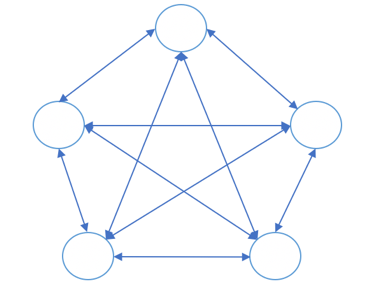
图 1‑3 无主式结构
很多分布式存储系统采用了无主式结构,如Amazon Dynamo、Apache Cassandra、Redis Cluster等。无主式结构的优势很明显,系统内部没有主从之分,各节点地位对等。因此,这类分布式系统完全没有单点故障的风险,故障转移快速,可靠性较高,也易于扩展。另外,读写可以在任意节点上进行,这使得客户端的操作流程简单易操作。
无主式结构的技术挑战性主要来自各节点的通讯成本、节点的Failover机制以及数据的复制与修复。通常会对数据进行分区处理和存储,同时以多个副本的形式提升冗余度。多副本之间可能存在主从关系,也可能是对等的关系。
1.2 读写策略
读写策略是指客户端在分布式系统上的读、写方式,读写策略与分布式拓扑结构相结合,决定了系统的一致性语义和共识的实现方式,在分布式架构设计中是一个不可或缺的因素。本章节以主从式、多主式和无主式结构为出发点,介绍了不同的读写策略。
在介绍读写策略之前,我们首先需要明确一下客户端的读写路由方式,一般有两种方式:实际的分布式系统设计中,客户端可以连接到一个节点上进行读写操作,该节点称为协调节点,协调节点负责数据的读写请求处理。对于读请求,可以直接读取本地数据或查询其他节点数据,最终返回给客户端;对于写请求,协调节点可以直接在本地执行写入操作,并将数据更新复制给其他节点,或者将写请求路由到其他节点执行写入操作,并将最终执行结果返回给客户端。
还有一种方式,客户端和分布式系统的各节点都建立连接,并维护主、从节点状态,以及读写的路由关系,读写请求由客户端直接找到对应的节点并执行操作。注意这些节点状态及路由关系的变化,客户端可能是通过一些注册发现系统(如Zookeeper)来实时更新,或者部分节点会在查询的过程中实时通知客户端做出改变。
1.2.1 单主读写
单主读写是指客户端在单主(主从式)系统上执行的读写方式。单主读写策略可以具体分为以下几种方式:
在Leader上进行读写:如图 1‑4所示,客户端只在Leader节点上进行读写操作,系统的主节点承担所有的读写流量,而Follower节点只是充当备份的角色。
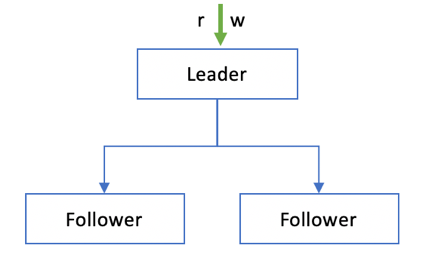
图 1‑4 Leader读写
这种读写策略的优势在于架构简单,易于实现,无需考虑复制的延迟和一致性问题。但劣势也很明显。首先在于性能,由于整个系统的读写都在Leader节点上进行,那么该节点的性能瓶颈决定了整个系统的读、写吞吐量和延迟。其次,Leader节点的单点故障风险很突出,当出现宕机或处理速度下降时,整个系统可能面临不可用的困境,这时候势必要进行故障转移操作。
在Leader上进行读写,Follower上只读:如图 1‑5所示,客户端在Leader节点上进行数据写入,以及部分数据读取。同时,客户端会连接任意Follower节点,进行数据只读操作。
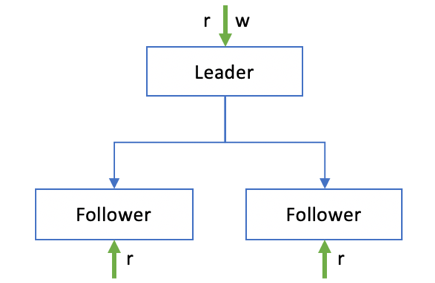
图 1‑5 Leader读写,Follower只读
和第一种读写策略相比较,这种方案将读流量传递到了多个Follower节点上。对于读多写少的场景,这种读写策略非常适合,整个系统的读取性能取决于Follower节点的规模和性能。这种读写策略也解决了读的可靠性问题,及时Leader节点或部分Follower节点宕机,在整个系统负载可承受的情况下,读操作依旧不会受到太大影响,客户端完全可以将读请求路由到正常工作的节点上。
在Leader上进行写入,Follower上只读:如图 1‑6所示,和上面的读写策略稍有不一样,客户端仍旧在Leader节点上执行写入操作,但所有的读取操作是在Follower节点上进行。

图 1‑6 Leader写,Follower只读
这种读写策略相对清晰一点,Leader节点只需要承担写入压力,读压力则由所有Follower节点来均摊。在实际场景中,这种读写策略应用非常广泛,如MySQL或Redis的主从集群,写入在Master节点上进行,而读取根据负载均衡(如Proxy或DNS)随机择取Slave节点进行。在一些CQRS的架构风格中,数据写入、读取由不同的子系统处理,我们很容易会采用这种读写策略。这种方式的缺点在于Leader节点存在单点风险,一旦宕机则写入会在短暂时间内无法正常工作。另外,读取操作会由于复制的延迟和一致性局限性,可能在短时间内无法读取到最新的数据,甚至会出现新旧数据随机翻转(这些问题会在一致性模型和会话模型中重点说明),这些问题通常要在技术和业务层面做权衡和取舍。
1.2.2 多主读写
多主读写策略是指在多主架构上进行的读和写操作。通常读和写在不同的主节点上进行,最常见的是跨地域的多数据中心,每个数据中心的读写请求均在主节点上。和主从式读写类似,多主读写也分成三大类:
在多Leader上进行读写:如图 1‑7所示,在一个分布在多数据中心中的主主复制集群中,每个数据中心的客户端将读写请求都路由到本地的Leader节点上。多个Leader之间进行主主数据复制。
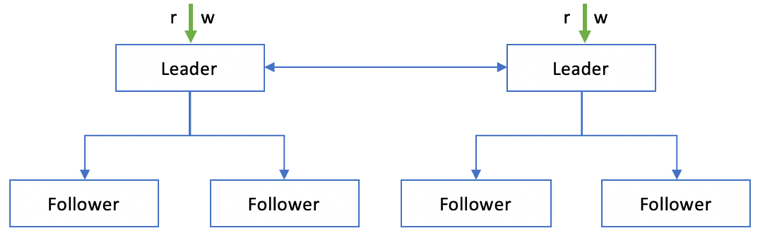
图 1‑7 多Leader读写
在Leader上进行读写,Follower上只读:如图 1‑8所示,每个数据中心的客户端的所有写请求均路由到本地的Leader节点上进行,除此之外,少量读请求也会打到Leader节点上。另外,客户端会将大量的读请求路由到本地的Follower节点上。
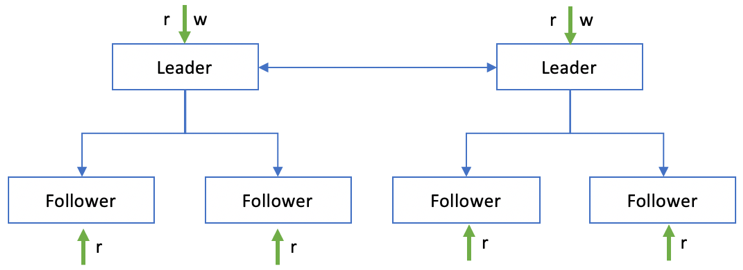
图 1‑8 多Leader读写,Follower只读
这种读写策略的写入能够及时生效,但是读取方面由于拓扑结构和复制的约束性,可能没法及时读取到最新的数据,换句话说,系统呈现给客户端的数据一致性视图是最终一致的。
在Leader上进行写入,Follower上只读:如图 1‑9所示,客户端仅仅将写请求路由到本地的Leader节点,当写入完成后,Leader节点之间执行双向数据复制。客户端的所有读请求则会路由到本地的Follower节点,读压力根据负载均衡策略来平均分摊。
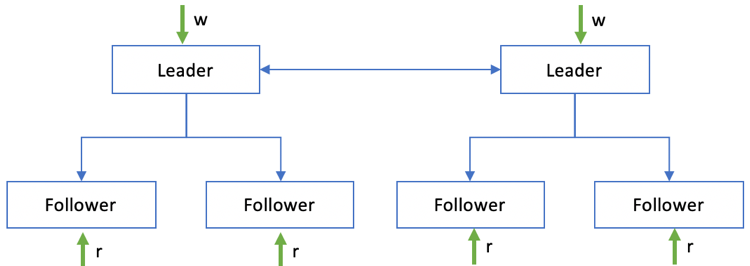
图 1‑9 多Leader写,Follower只读
这种读写策略比较常见,尤其是在两地三中心或异地多活的高可用架构中,这种业务场景通常是读多写少。我们在各数据中心的封闭交易单元中完成数据的写入和读取,数据中心之间再异步进行数据复制并解决写冲突。很多时候其他数据中心的数据,在当前数据中心并不需要及时的读取,换言之,可以允许数据延迟达到,只需确保最终一致即可。这种读写策略也达到了很好的异地容灾目的,当每个数据中心的Leader宕机,不会影响该中心的在线读业务;当某个数据中心不可用导致Leader-Follower全体宕机时,只需要把在线读流量切换到另外一个数据中心即可实现故障转移。待故障数据中心恢复后,重新开启同步,恢复数据复制即可。
1.2.3 无主读写
在一个无主式的拓扑结构中,完全无中心节点,所有节点地位对等,这就意味着读写可以连接到任意节点随意进行。根据读写策略的不同,我们可以将无主读写分为三大类:
主副本读写:如图 1‑10所示,A1、A2、A3为同一个数据分片的3个副本(Replicas),显然,我们设置了该分布式系统的复制因子为3。我们的客户端一直在主副本A1上进行读和写操作,任何请求都会通过路由算法定位到A1副本所在节点上进行读写。
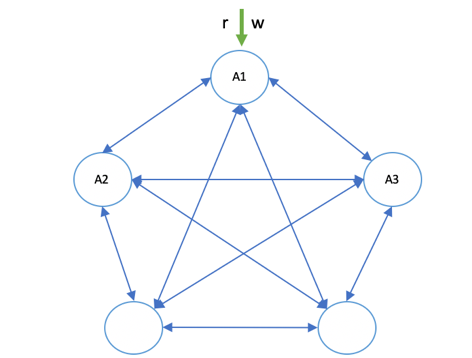
图 1‑10 主副本读写
另外两个副本A2和A3在这里主要是充当了备份的角色,它们在待命,一旦主副本A1所在节点发生宕机或者与客户端之间出现网络分区,则A2或A3就会接替A1的主副本角色,提供读写操作。主副本读写的策略提供了一种初级形态的读写方式,简单、容错能力强、运维简便,实际上有很多分布式存储系统就是基于主副本读写的方式来设计的。
主副本读写,从副本只读:如图 1‑11所示,这种读写策略在主副本读写的基础上,扩展了读策略。客户端的写请求和部分读请求依旧会路由到主副本上进行,同时,其他读请求会路由到其他副本上进行读取操作。
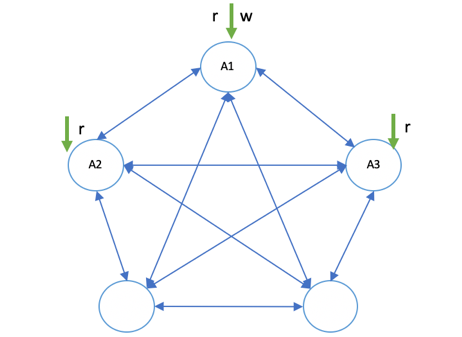
图 1‑11 主副本读写,从副本只读
一般来讲,这种读写策略是一种就近的方式。客户端随机连接到一个节点,当提交一个写请求时,如果该节点上的副本正好是负责写的主副本,则当前节点直接处理写操作,并复制数据到其他副本所在节点。否则,该节点会将写请求传递到主副本所在节点执行写入流程,该节点我们称之为“协调节点”。
多副本读写:如图 1‑12所示,多副本读写策略是一种更高级形态的读写方式,在这种策略中,分布式系统真正做到了副本之间的对等关系。客户端完全可以随机连接到任意节点,对副本执行读写操作,副本之间可以采取同步或异步的方式来交换数据变更。
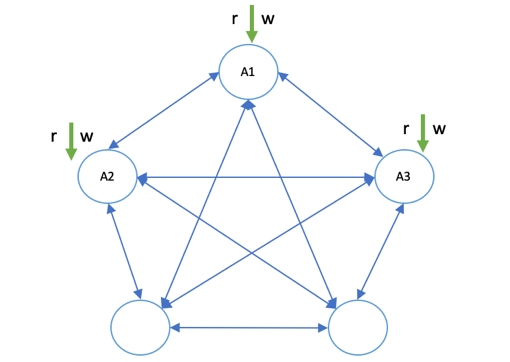
图 1‑12 多副本读写
多副本读写的使用场景很常见,如Apache Cassandra,客户端可以将数据写入任意副本,还可以指定读、写的副本数目,当符合该数目的副本数写入或读取完毕后,方可视为读写成功。多副本读写通常会引入一些新的话题,如可调一致性、Sloppy Quorum、读修复、提示移交等,这些在复制和一致性模型中会重点阐述。
1.2.4 粘滞读写
粘滞读写是指同一客户端或用户被路由到固定的节点上执行读写,如图 1‑13所示。注意这里指的是客户端或用户,这两个涵义有些差别,同一个客户端有可能是一个应用层节点,读写请求由不同用户发起,而同一个用户通常由用户唯一标识userid来区分,技术层面上可能是不同的客户端,也可能是同一个客户端。
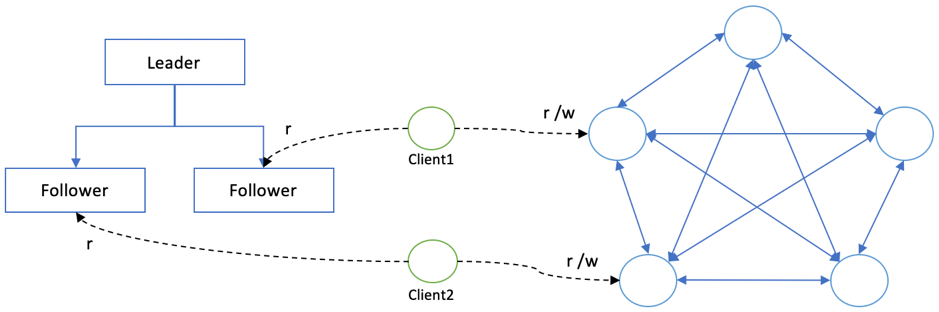
图 1‑13 客户端粘滞读写
粘滞读写策略适用于一些特殊场景,比如当网络出现分区时,为了仍提供可用的服务和一致性语义,可以切换读写策略,使得用户读写转移到正常工作节点上。在一些客户端角度的一致性视图中,通过粘滞读写可以实现特殊的一致性,比如相同的用户可以随时读取自己发布的最新内容而无需考虑延迟,另外可以单调读取其他用户的内容而不会出现新旧内容交替的问题。
1.3 分片
我们这一章节来讨论数据的分片问题。分片也称为分区,分片有很多英文名称,如Partition、Sharding、Region,等等。这些名称几乎大同小异,表示将数据打散并均匀分配到分布式系统的各节点上。为什么需要对数据进行分片呢?想象一下,当我们的数据集越来越大时,势必会遇到以下几个问题:
随着业务的发展,单节点已无法存储如此快速增长的数据集,系统很快达到容量的上限;
尽管可以将读流量均匀分配到不同的副本上,但写流量必须要在单节点上进行,因此单节点的写入瓶颈(CPU、RAM、DISK等)就成为为了系统写入的短板;
每个节点的数据集异常庞大,导致读取需要遍历大量的数据,频繁启动I/O。除此之外,有些数据库系统需要维护索引,如此大的数据集带来的索引维护成本也不可小觑。这些因素都拖垮了系统的读取吞吐率。
为了解决以上几个问题,分布式系统需要伸缩性(Scalability)来进行扩容处理。我们知道,伸缩性可分为垂直伸缩和水平伸缩,水平伸缩由于其优势明显,是现代分布式架构的必备要素,分片是水平伸缩的一种重要技术实现。关于伸缩性,我们会在后续“伸缩性”一章专门探讨,这里重点讨论分片的理论基础。
本章节我们介绍分片的两种基本方法:区间分片和哈希分片,并介绍分片的Rebalance技术。
1.3.1 区间分片
按区间分片是一种很常见的实现方式,我们可以选取分片键(ShardingKey),并对该键进行排序处理。然后,按照区间范围对键进行划分,不同区间范围的数据映射到对应的分片中。如图 1‑14所示,根据一个简单的计算公式shard=range(sharding_key)得到数据的分片位置,当sharding_key在1到10000之间时,该数据的读写被路由到shard1分片,同理,当sharding_key在10001到20000之间时,该数据的读写被路由到shard2分片,依次类推。
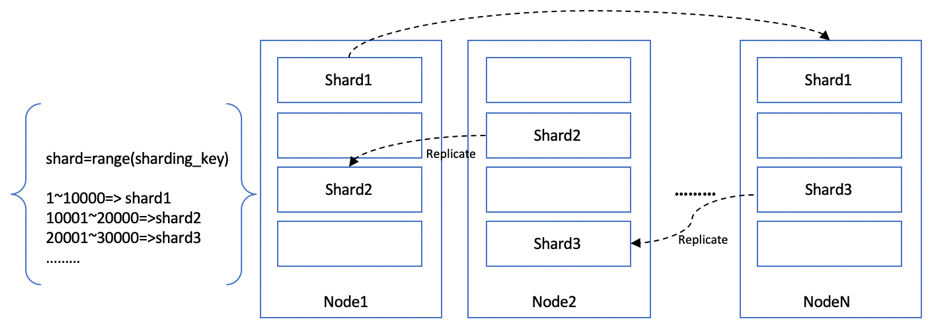
图 1‑14 区间分片
按区间分片的方式,弊端是容易产生数据倾斜,如果遇到一些热Key,则会导致某个分片数据量偏大,使得该分片所在的系统节点工作负载较高。热Key的读写请求量往往也比较大,进一步加剧了节点的负载压力,极端情况下可能会导致系统宕机不可用。这种情况我们可以仔细筛选和定义sharding_key,规避数据的集中,比如HBase就是按照RowKey来进行区间划分,不同区间范围的行被分配到不同的Region上。如果我们对RowKey进行适当的转义处理,则就可以避免数据落到同一个Region中。
1.3.2 哈希分片
由于区间分片的数据倾斜问题,我们也可以采用按键哈希的方式来进行分片。如图 1‑15所示,我们通过一个公式shard=hash(sharding_key)来计算分片的位置,比如sharding_key为1、10、15等数据,会被路由到shard1,其他部分数据会被路由到shard2,等等。
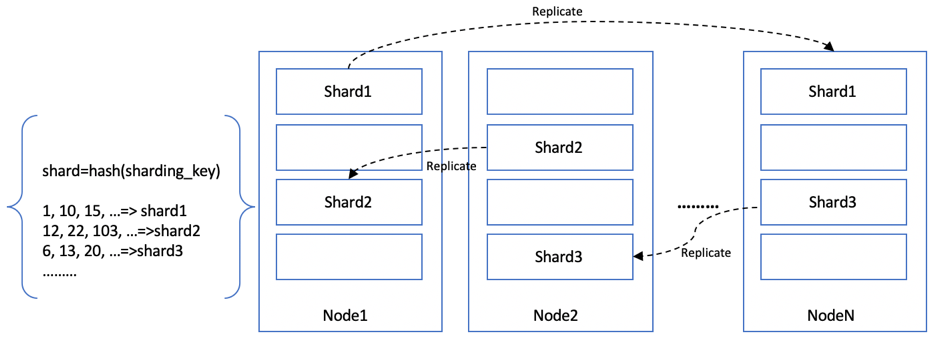
图 1‑15 哈希分片
分片通常和复制结合起来使用,图 1‑15中我们也展示了分片的数据复制。也就是说,在该图中每个分片的复制因子为2,每个分片在另外一个节点上还会存在一个复制的副本。这种方式既将一个大数据集平均分散到各节点上,又通过多副本的方式提升了数据的冗余度和可靠性。
常见的哈希算法是根据节点数目来做简单的取模运算,这种方案简单高效,但劣势却很明显,当我们在集群中添加或减少节点时,会导致大量的数据哈希结果发生变化,数据无法再落到之前的分片上。一种改进的方案是通过一致性哈希算法来减少Rehash时数据的定位问题。
1.3.3 分片Rebalance
当数据通过分片的方式被均匀分散到各节点上以后,为了让这些数据尽可能的均衡分布,提供更高的读写性能和可靠性,分片的管理就显得尤为重要。大多数时候,部分分片可能会发生数据量上升,超过了单分片或单节点的承载能力,这种情况下,我们就需要对分片进行拆分 ,并且重新分配节点,以寻求各节点的总体平衡。反之,若部分分片的数据量缩减(如数据删除导致),则需要对这些分片进行合并处理。如图 1‑16所示。
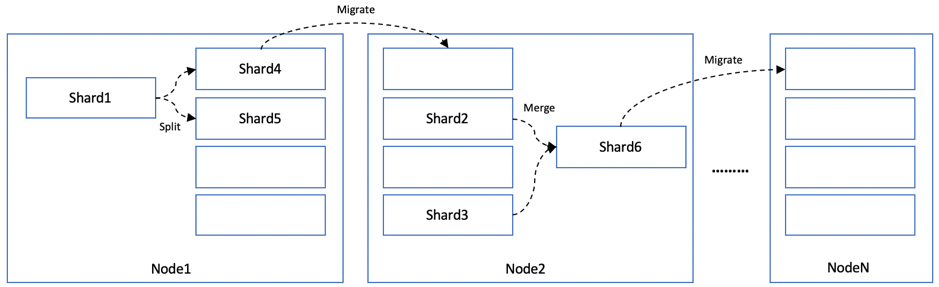
图 1‑16 分片Rebalance
为了对分片进行Rebalance,我们可以选择一定的分片策略,常见的方式有:
固定分片:当规划业务系统时,根据业务发展状况,提前对数据量级进行预估,谨慎的选取分片数,可以远远大于节点数目。这些分片数一旦被预分配后,后续就不会再增加或减少,但可以在系统内部进行迁移以达到再平衡的效果。如Elasticsearch,当我们在建立索引时,可以提前分配好固定的分片数,集群在运行过程中,可以根据节点的负载状况,动态调整分配与节点的映射关系。
动态分片:这类策略比较灵活,当我们在创建数据集时,无需花费太多精力来预分片的数量,而是根据经验,提前分配一些初始的分片即可。如Apache HBase,默认在建表时,可以不指定Region数或指定少量的初始Region数,HBase在运行过程中,当检测到部分Region数据量较大,已超过列表的阈值时,会自动执行Region的分裂,分裂完成后,客户端将读写请求路由到新的Region,与此同时,集群可能还会对Region进行必要的迁移,使得数据更加均衡。对MongoDB分片集来说,原理也大抵相似,集群的Balancer组件会实时监控分片的状态,一旦达到拆分的阈值时,会对分片的trunk进行拆分,并在节点间进行迁移,完成Rebalance操作。
抽象一点来说,为了达到分片的Rebalance,我们通查会执行以下一些基本操作步骤(各分布式系统的实现方式可能不一样):
系统根据一定的策略(如每个分片大小的上限、分片大小的增长速度,等等),对分布在各节点的分片进行监控和检测,识别到有分片需要执行Rebalance;
选择目标分片开始初始化和执行数据拷贝,目标分片从源分片上拷贝存量快照数据。拷贝期间读写依旧在源分片上进行;
当拷贝存量数据完成后,目标分片从源分片上拷贝增量数据(指上一阶段在拷贝期间,源分片上写入的新数据),直到目标分片数据和源分片最终对齐;
将读写请求路由到目标分片上,并且删除源分片数据;
1.4 复制
复制(Replication)是分布式系统理论体系中非常重要的一个概念,复制的思想是通过多副本的方式,提升数据的冗余度。复制可以带来以下好处:
数据被复制到多个副本(Replica),客户端读和写被均匀分散到多个副本上进行,从而提升系统整体的读写吞吐量,性能更高。
多个副本通常分布在地理位置不同的数据中心,客户端可以根据一定的负载均衡策略就近选取本地数据中心读写,访问延迟可以得到保证,也是提升性能的一种方式。
同一份数据(分片)通过复制技术,将数据冗余在多个副本中,当其中一个分布式节点或副本奔溃时,系统可以转移到其他副本,从而可以有效提升系统的可靠性。
在本章节,我们将逐步介绍复制的各种策略,复制的各种技术挑战,包括复制延迟、写冲突及冲突的检测与修复等。
1.4.1 主从复制
主从复制是最常见的一种复制模式,特指在主从式(单主式)拓扑结构上发生的数据传播。客户端在主节点上执行数据写入事务,该节点将该写操作追加到本地的事务日志中,并且将数据写入本地存储。然后,主节点再将数据同步到各个从节点上。
主节点与从节点之间的复制方式可以采取“推”或“拉”的模式。对于推模式而言,主节点通常会为每个从节点建立一个FIFO队列,并将需要同步的信息或完整数据放入该队列,从节点监听到队列有变化后,会识别该同步事件,并将数据复制到本地。对于拉模式而言,主节点无需通知从节点有数据变更,而是从节点间歇性去询问主节点是否有新的数据变更,从而拉取最新的增量数据,并应用到本地。
常见的复制数据,可以是数据本身,或者是主节点上的操作历史。一般以操作历史的复制比较常见,从节点从主节点获取到最近的事务日志,并按同样的执行序列,应用到本地,从而达到与主节点严格的数据一致性。
1.4.2 多主复制
多主复制的应用也比较广泛,在前面的章节也介绍过多主式拓扑结构,这种复制方式通常应用于多数据中心的数据同步。比如,在北京和上海两个数据中心,各设置一套MySQL主从集群,两个数据中心的主节点之间执行主主复制。
实际上,我们完全也可以采用主从式复制,也就是一个主从集群横跨多个数据中心。从技术实现上来讲,这种方式相对于多主复制架构更简单,每增加一个数据中心,只需要在该本地增加一组从节点即可。然而,由于写入只能在主节点上进行,这导致每个数据中心的客户端都必须在一个主节点上执行写入,带来的写入延迟是非常客观的。多主式复制则不一样,每个数据中心的客户端只需要在本地进行读写即可,性能不会受到太大的影响,另外即使出现了网络分区,也不影响单一数据中心的可用性。
1.4.3 无主复制
在一些类似Amazon Dynamo风格的分布式系统中,无主式拓扑结构大行其道,无主式复制也顺应而生。这类系统的节点之间地位对等,任何节点都可以接受读写请求,内部可以传播数据并复制。
考虑到性能和可靠性的影响,有些无主式分布式系统也提供了多数据中心部署的能力,如Apache Cassandra,客户端只需要在本地挑选任意节点进行读、写操作,即可完成本地DC的数据写入和复制。各数据中心之间也会互相复制,实现数据的最终一致。
1.4.4 同步与异步复制
复制必然会涉及到两种不同的策略:同步与异步。这两种策略对复制的意义重大,它们决定了复制的阻塞性、网络分区与可用性、数据的一致性语义,等等。
同步复制如图 1‑17所示,这种复制方式简单可靠,数据的一致性比较强,但带来的性能成本也比较高。
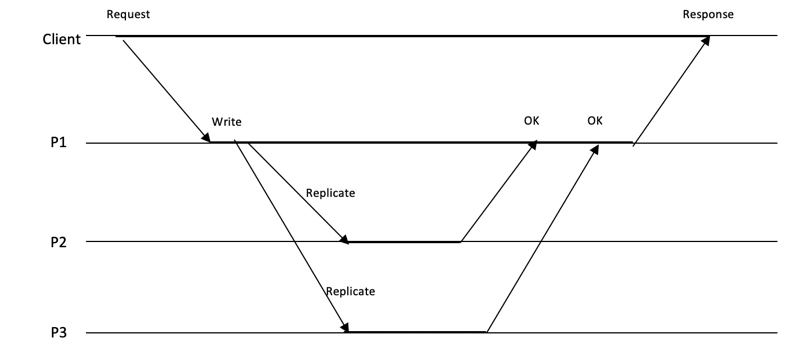
图 1‑17 同步复制
假设分布式系统中存在三个节点(或进程):P1、P2、P3,客户端的写入操作被路由到进程P1上。P1将写入操作追加到事务日志中,锁定必要的资源,并将数据写入本地存储。然后,P1将复制的指令发送给进程P2和P3,并阻塞等待P2和P3的回复。P2与P3接收到复制信息后,拉取数据变更并复制到本地,当复制完成后,向P1发送完成确认OK。当P1接收到P2和P3的OK回复后,确认该写入正式提交(Commit),会想客户端反馈写入反馈Response。
同步复制的问题在于这是一种“阻塞性”复制协议,如果在复制的过程中,P2或P3发生进程奔溃,或P1与P2或P3之间出现了网络延迟或网络分区,则P1会一直阻塞等待,数据的写入无法完成,导致写入的可用性丧失。
为了解决同步复制的阻塞性问题,我们来考虑第二种复制策略:异步复制,如图 1‑18所示。异步复制和同步复制恰恰相反,客户端无需等待复制全部完成即可返回。
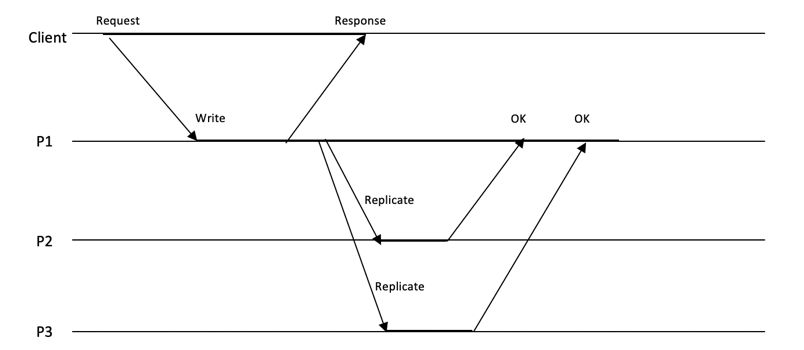
图 1‑18 异步复制
图中当P1执行完本地写入操作后,立即向客户端返回写入成功响应Response,然后,将复制指令发送给P2和P3,在P2和P2执行本地复制的同时,P1也不会阻塞等待,而是继续执行下一个读写操作。当P2、P3复制就绪后,会给P1发送确认信息OK,P1接收到确认信息后,只需将这些恢复信息记录到本地事务日志即可,到此为止,这条数据的写入彻底完成。
异步复制提升了系统的整体性能和可靠性,但也给数据的一致性带来了挑战。比如在数据复制的过程中,进程P3与P1之间出现网络分区,则P3的数据在很长时间无法更新,从而导致客户端从P3上读取的内容不是最新的,会导致一系列的一致性问题。这些由于复制导致的一致性问题我们将会在后续章节重点探讨。
1.4.5 复制级别
前面介绍了同步复制和异步服务,同步复制数据一致性高,但容错性和可用性较差;异步服务的可用性和性能好,但数据一致性比较弱。那么,是否有一些折中的方案来兼顾性能和可靠性呢?答案就是定义复制级别。
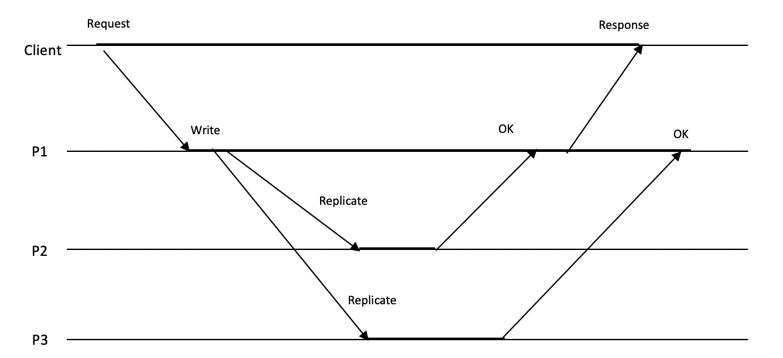
图 1‑19 复制级别
如图 1‑19所示,这是一个简单的复制级别实例。图中,客户端向进程P1发起了写请求,P1处理完本地事务及存储后,同时向进程P2和P3发起复制通知。当P1只接收到一个目标进程的回复(本例中为P2)后,即可认为写入成功,同时想客户端发送写入响应Response。而P3由于网络或自身的处理延迟,在稍后一个时间内才处理完毕,向P1发起回复,P1只需将该回复记录到本地事务日志即可。这种复制方式有时我们也称为“半同步“,也就是说副本之间的复制有一部分是遵循同步的协议,另外一部分是采用异步的复制协议。
之所以有复制级别的概念产生,是因为需要综合考虑性能、可靠性和延迟而做出的权衡和取舍。很多业务场景对数据的安全和一致性并没有很严格的要求,这种情况可以考虑只开启部分同步复制,甚至完全异步复制。相反,有些业务场景(如金融、航空、医疗等行业)对数据丢失的容忍度很低,这种情况我们需要进一步调整复制级别,使得数据尽可能安全可靠的复制到各副本。
数据的复制级别依赖于一种称为Quorum的机制,假设分布式系统中某个数据分片的副本数为N,客户端写入数据时写入W个副本则视为写入成功,而客户端读取数据时需要读取R个副本并执行数据合并处理。这里的N、W、R组成了Quorum的基本概念,一般的,我们为了保证数据的一致性,通常会在N、W、R之间做取舍,当W+R>N时,则数据更新能够被读取到,不会出现丢失。
比如,W=N,R=1表示写入时所有N个副本必须都复制成功方可认为写入成功,而读取的要求比较放松,只需读取任意一个副本则可视为读取成功。而W=1,R=1则表示写入和读取都只发生在一个副本上,换一句话说,读写并没有涉及到同步复制,这种策略的读写性能是最好的,但数据由于是异步复制,更新的速度不够及时,只能保证为最终一致性。
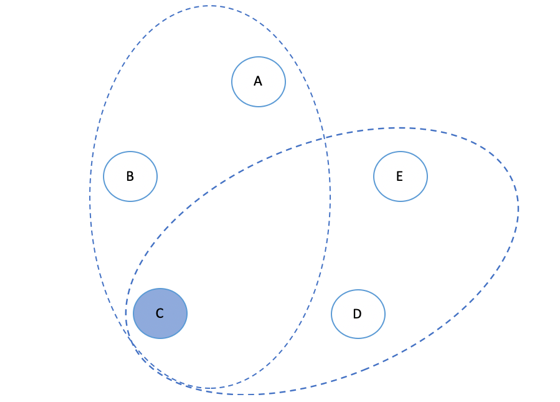
图 1‑20 两个多数派的交集
一个常见的经验法则是,设置W和R为(N+1)/2,这样保证了W+R>N。这种读写的级别称为“多数派“,也就是超过副本数的一半。为什么多数派可以保证数据在读取时能做到不丢失?因为任意两个多数派之间一定会存在交集,如图 1‑20所示。只要集群丢失了不到一半的副本,我们依然可以访问到包含最新数据的副本。
1.4.6 复制的挑战
前面也多次提到,复制之所以是分布式理论中一个由来已久的重要研究课题,是因为其面临的挑战较多。数据的多副本存储产生了复制,复制则带来了一些列难题。
说先要面临的是复制延迟。实际的分布式系统之间的网络连接并没有我们想象的那样可靠:网络通信延迟或通信步骤可能没有上限,数据包可能会发生丢包、乱序,节点之间、节点与客户端之间可能随时会发生一个或多个网络分区。在这种恶劣的网络环境下,节点在副本之间的数据复制延迟就不太确定,可能是毫秒级别,也可能是秒级、分钟级、小时级或者不确定。
其次,对于多主式复制和无主式复制而言,由于写入可能实在不同的节点上进行,这就会带来写冲突问题。比如,对于一个分布式键值存储系统来说,如果写入在不同节点上进行,可能就会导致同一个Key的写入同时在两个不同的节点上进行,当这两个节点彼此之间交换和复制数据时,就会发现数据冲突,这时候冲突的检测和解决就显得尤为重要。
再次,由于复制的延迟问题,导致同一条数据再不同的节点(副本)上,在同一时刻很难达到一致。这可能会导致不同客户端的数据读取产生很多困扰,在这种情况下,我们就需要定义数据的一致性保证,通过不同的一致性契约来满足不同的业务场景。
本章节接下来的部分会重点讨论如何解决复制带来的写入冲突,而在后续章节则会探讨一致性的话题。
1.4.7 读修复
读修复(Read Repair)是在无主式复制协议中一种常见的数据不一致的解决方案。在NWR的Quorum机制中,当W和R的数目大于1时,可能会存在数据复制存在延迟,从而导致读出的多个副本出现数据不一致,我们完全可以利用这个时机,在多副本中挑选出最新的数据返回给客户端。同时,将最新的数据写入到旧的副本中。
读修复在Amazon Dynamo和Apache Cassandra中应用很广泛,在读取的同时完成对数据的修复,达到数据的一致性快速收敛的目的。
1.4.8 宽松Quorum与提示移交
在前面我们多次提到了Quorum机制,其中N、W和R都是有效的副本个数。宽松Quorum(Sloppy Quorum)则不一样,这里的N、W和R不一定来自有效的副本,而是可能存在部分副本在特殊情况下由其他不相干的副本来“滥竽充数”。
提示移交(Hinted Handoff)则是指当存在宽松Quorum时, 部分不相干的副本也会接受数据的写请求,但是在将该数据存储到本地时,会附加一条提示(Hint),用于后续将这些数据移交到正确的副本上。
为什么会有宽松Quorum和提示移交这样的机制存在呢?在一些无中心的分布式系统中,节点的奔溃非常常见,为了不影响整体系统的可靠性,我们将写入临时转移到临时节点上,这些节点本身并没有当前数据的副本,不过没关系,数据只是暂存在节点中。一旦奔溃节点恢复后,这些带有提示的数据就会被自动转移到正确的节点上。这种方式保证了系统的可靠性,只要不是所有的节点奔溃,则整体的写入和读取都不会受到影响。
为了更好的理解这种机制,我们举个通俗的例子,在下班回家的路上遇到突发暴雨,没法到家,只得就近找到一家便利店临时避雨,在便利店中我们可以临时吃东西、休息、打电话、写文档、处理工作事务。一旦暴雨停了,我们就可以离开便利店回到家,并且把这些事情带回家继续。
1.4.9 反熵
熵(Entropy)的概念来自热力学第二定律,由德国物理学家克劳修斯于1865年提出,代表事物无序的程度,熵的值越低,则表示越有序。反熵(Anti-entropy)也称为逆熵,是一种减少熵值的过程,在分布式系统中指通过一定的技术手段,来消除各节点的数据不一致,减少差异的过程。
有很多方法可用于反熵,比如两个数据集逐个按记录进行比较和修复,这种方式计算量和存储量都比较大,效率往往不是很高。一种行之有效的方法为默克尔树(Merkle Tree)算法,Merkle树的本质就是一棵哈希树,如图 1‑21所示。
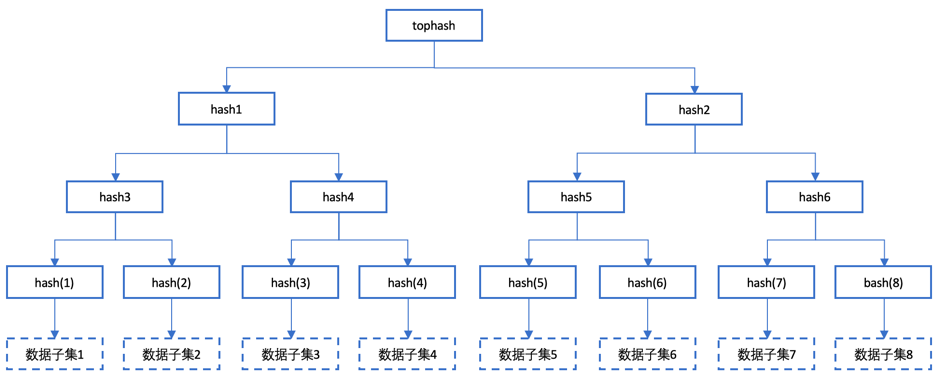
图 1‑21 Merkle树
在Merkle树中,我们可以自底向上对上数据进行哈希计算,比如我们将数据集拆分成了8个数据子集。从图上可以看出,第一层哈希是每个数据子集的哈希。从第二层开始,将第一层的哈希值两两合并,再次计算哈希值,形成图中的hash3~hash6。同理,第三层由第二层的哈希值计算得来,产生了hash1和hash2。到了第一层,也就是数的根节点,会产生一个根哈希值,我们称之为tophash。
Merkle树的这种数据结构特性决定了比较两个数据集的方法可以非常高效:
当底层的数据源发生变化时,必然会导致从该数据源往上的路径上所有的哈希值发生变化,最终使得tophash值被改变。
当两棵Merkle树的tophash相等时,则底层的数据源一定会相同。
当我们需要对两个数据集做反熵操作时,可以首先计算两个数据集的Merkle树,如果tophash相等,则可以认为数据源相等,无需反熵。反之,我们可以顺着哈希树,找到不一致的哈希值,最终定位到不一致的数据源,进行反熵和修复。
1.4.10 最后写入胜出
在复制的挑战一节中,我们提到了主主复制和无主复制所带来的的写冲突,为了解决这些冲突,我们需要检测和修复,使得数据达到一致。最后写入胜出(Last Write Wins,LWW),顾名思义,对同一条数据而言,选取最后写入或更新的那条记录作为最终数据,是一种常见的解决数据冲突的方式。
LWW假设所有的数据在不同的节点写入时,会同时附加当前的时间值(如Unix时间戳),写入该数据的元信息中。当两条或多条数据在同步时发生了冲突,则读取每条数据的时间戳,并使用时间戳最大的数据(最后写入)来覆盖其他的数据。LWW在Apache Cassandra、HBase中使用场景较多。
LWW原理简单、粗暴、直观、易于实现 ,但也有明显的缺点,因为分布式系统中物理时钟是很难严格一致的,且存在时钟漂移问题。采用时间戳的方式来决定最终数据,可能会导致时钟比较靠前的旧数据覆盖了时钟落后的新数据。
还有一个问题,如果是一个读改写(Read-Modify-Write)的操作,则可能会出现在一个节点上执行的读取-更新-再次写入,会覆盖另外一个节点上的同样操作,这会导致数据最终不一致。比如,假设某分布式存储系统不支持原子操作,必须业务层来执行计数量的增减。某客户端读取某用户的积分,根据一定的规则,为该用户增加100积分,并将最终结果再次写入当前节点,与此同时,同样的操作在另外一个节点上也在进行。当两个节点的数据在同步时发生冲突,如果按LWW法则,最终会导致原本应该给该用户增加200积分,但实际该用户只获得了100积分。
在一些对数据的实时性和准确性要求不严格的业务场景下,可以采取这种方式。如果对冲突的解决方案有苛刻的要求,我们可以采用其他的方案,如向量时钟。
1.4.11 向量时钟
在讨论向量时钟之前我们简单提一下Lamport时钟,Lamport逻辑时钟是一种表达事件相对顺序的方式。假设事件i的逻辑时钟为C(i),如果事件i发生在事件j之前,即i -> j,则我们可以认为C(i) < C(j)。然而,反过来若C(i) < C(j),则不一定存在i -> j。也就是说,i -> j是C(i) < C(j)的充分不必要条件。很明显,Lamport逻辑时钟对每个进程来说,只拥有本地的逻辑时钟,但是却缺乏其他进程的逻辑时钟。所以,通过Lamport时钟没法知道事件之间的因果关系。
为了获取事件的因果联系,有人在Lamport的基础上,提出了向量时钟(Vector Clock)算法。通过向量时钟,我们可以知道不同进程之间的事件顺序和关系:要么不存在因果关系,即事件同时发生;要么存在因果关系,及事件存在先后顺序。如图 1‑22所示。
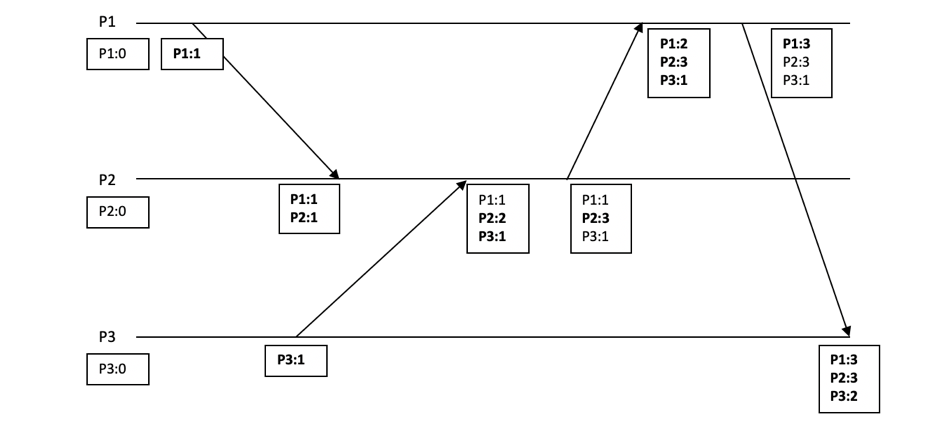
图 1‑22 向量时钟示意图
根据图中的事件消息传递和顺序,我们假设存在以下规则:
任何进程p都有一个本地逻辑时钟C(p)。
当进程p有新的事件发生(包括发送消息、接收消息)时,则自身逻辑时钟自增,即:C(p) = C(p) + 1。
当进程p发送消息给进程q时,将自身逻辑时钟C(p)携带在消息中一起发送,设消息中的时钟为T(p)。
当进程p接收到到进程q的消息时,更新本地时钟向量,取本地存储的时钟和接收的时钟的最大值。即:C(q) = max(C(q), T(q))。
在上图的例子中,假设有3个进程P1、P2和P3,它们的初始时钟都是0。P1准备发送消息给P2,首先P1将自身的时钟递增到P1=1,然后传递消息给P2,P2接收到消息后,首先将自身的时钟递增到P2=1,然后再更新时钟向量,最终为P1=1/P2=1。依次类推,最终每个进程都保存了自身和其他进程的时钟。
既然得到了向量时钟,如何判断事件之间存在因果关系与否呢?通常我们采用以下方法:
如果向量时钟V1上的各个分量都小于等于V2上各个分量,则认为V1比V2早,V1是因,V2是果。比如事件V1={P1:1, P2:2, P3:1}和事件V2={P1:4, P2:5, P3:5},不难看出,事件V1发生在前,V2发生在后。
向量时钟V1上的各个分量有的比V2上的分量大,有的要小,则认为它们之间不存在因果关系,两个事件同时发生。比如事件V1={P1:1, P2:5, P3:1}和事件V2={P1:4, P2:3, P3:1},两者是同时发生。
向量时钟可用于检测复制事件的冲突,只需要根据向量检查,当有两个事件是同时发生时,我们就可以认为它们存在冲突。注意:向量时钟仅用于检测冲突,不代表能解决冲突,后者是另外一个课题。如果我们把最后写入胜出LWW视为一种服务端自动的冲突检测和解决方案,则向量时钟方案更倾向于将冲突解决方案移交给应用层解决。假设图 1‑22在实际场景中是购物车的冲突检测方案,那么一种常见的解决方案就是将多个进程产生的数据进行“合并”处理。
1.5 一致性模型
所谓一致性模型,是指分布式系统为客户端提供的一种数据读写一致性视图的契约,分布式系统对外表现就像是一个虚拟的节点,该节点具备很强的性能、可靠性和伸缩性。客户端只要遵循该契约,就可以得到预期的结果。
一致性问题是由多副本和复制引起的,本章节将会讨论以下几种一致性模型(如图 1‑23所示):严格一致性、线性一致性、顺序一致性、因果一致性、最终一致和可调一致性,另外从单一客户端层面来说,还有读己缩写、单调读、单调写、读后写等一致性,我们会在会话模型中重点探讨。之所以有这么多一致性模型的存在,追根究底是受这些因素制约:系统拓扑结构、客户端读写策略、数据的分片策略、多副本的复制策略。这些因素在之前的章节中已经讨论过。在本章节,我们将会发现这些策略的调整可能就会引起一致性语义的变化。
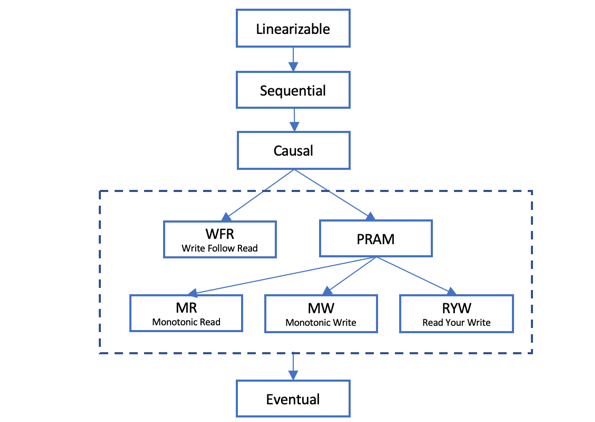
图 1‑23 一致性模型一览图
在介绍一致性模型之前,我们首先会用简单的篇幅来介绍分布式的一些著名的概念:CAP、BASE、PACELC、FLP,等等。并以这些理论基础为铺垫,进一步展开探讨各种一致性模型的特点。
在了解一致性模型时,我们也会结合实际的应用场景来分析问题。这里列出一种分布式问题的分析思路:
确认分布式系统的一致性。根据系统的架构、客户端读写策略、分片、复制等策略,确认该分布式系统对客户端所提供的一致性模型。
确认实际场景的事件顺序。根据实际业务场景,列出各种读写事件及消息的先后顺序,包括同步消息和异步消息。这些事件的之间可能存在并发关系、先后顺序关系,或因果关系。
分析可能的执行序列。根据一致性模型和事件的顺序,分析出整体事件的可能执行序列,便于了解业务操作的顺序和数据读写一致性视图。
确认执行序列是否符合场景需求。通过上面列举的各种操作序列,结合业务特点,进一步分析和确认这些执行序列是否符合业务诉求。
1.5.1 CAP理论
2000 年,Eric Brewer 教授在 PODC 会议上提出了 CAP猜想。2002 年, Nancy Lynch 和Seth Gilbert等人发表了论文《Brewer's Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services》,从理论上证明了 CAP 猜想,自此以后,CAP成为了正式的分布式理论。2012年,Lynch等人又发表文章《Perspectives on the CAP Theorem》,重新审视了CAP的细节问题。
http://groups.csail.mit.edu/tds/papers/Gilbert/Brewer2.pdf
一致性是指分布式系统对外呈现的一致性视图,并不要求系统内部各节点数据时刻保持一致。
注意CAP中的C,指的是线性一致性,是一种Safety属性。A指有限的时间内,返回正确的结果,是一种Liveness属性。注意,相互之间无任何交互的节点组成的分布式集群,不应该纳入CAP讨论的范畴,我们称这种为无关紧要的服务(Trivial services)。
CAP理论其实背后蕴藏着更深一层的原理:在一个不可靠的系统中,safety和liveness通常难以两全,我们需要在两者之中做出取舍。这个原理会在FLP不可能定理的章节中重点说明。
CAP不是非黑即白的理论,而应该是连续的,我们不应该认为任何时候只能“三选二”,这个Eric Brewer 教授本人在2012年发表的文章《CAP Twelve Years Later: How the "Rules" Have Changed》也指出了。很多时候,提供一致性的同时也可以提供尽力而为(best-effort)的可用性,反之,提供可用性的同时也可以提供尽力而为的一致性。
在实际生产环境中,由于网络是不可靠,我们发现网络分区P是必须要满足的。因此,CAP的三选二就退化成C和A中二选一了。换句话说,网络分区不是一个条件,而是一种陈述(Statement),在这种情况下,我们设计系统时需要在一致性和可用性之间做取舍。
网络分区非常复杂,举例说明不同的P导致不同的结果。
1.5.2 BASE原理
BASE原理由eBay的架构师 Dan Pritchett提出,是一种对CAP思想的延伸。BASE 是 Basically Available(基本可用)、Soft state(软状态)和 Eventually consistent (最终一致性)三个英文短语的缩写。
基本可用:在不可靠的网络环境下,即使不能保证系统100%可用,也应该尽力而为提升可用性。
软状态:系统处于一种过渡的状态,业务层面可以接受数据临时不一致。
最终一致:从客户端层面来看,读取的数据最终能够收敛和一致。
BASE理论是一种“折中”的思想,及时无法做到强一致,但从业务角度出发,只要能做到最终一致即可。
1.5.3 PACELC原理
PACELC原理是2012年的一篇论文提出的。该原理指出,在网络分区(P,Partition)的情况下,需要在我们需要在可用性(A,Availability)和一致性(C,Consistency)之间做取舍。否则(E ,Else),在网络正常的时候,我们也需要在延迟(L,Latency)和一致性(C,Consistency)之间做取舍。
PACELC原理是一种更偏工程实践的经验总结,可以视为是CAP的理论扩展。在同步或异步网络模型中,延迟可以说无处不在,所以一致性的保证势必要受到延迟的影响。延迟也是性能的一种体现,所以这里也可以认为是在性能和一致性之间做出权衡和取舍。
1.5.4 FLP不可能定理
FLP不可能定理是由Fischer, Lynch 和 Paterson三位作者在1985年发表的论文《Impossibility of Distributed Consensus with One Faulty Process》中提出的一种理论,该理论的名称由三人的姓名首字母大写拼接而成。
FLP不可能定理指出,
我们只能在这几个条件中做取舍。其中,终止性(termination)约束无法满足,完全正确(total correct)无法实现,只能满足另外两个约束(agreement和validity),也就是部分正确(partial correct)。
FLP不可能定理给后人在设计分布式算法时点亮了一盏明灯。实际环境往往都是异步网络模型,在这种情况下当遇到故障时,不可能达成共识。设计分布式系统时,为了满足三个条件,我们经常需要放松Safety或Liveness要求。
1.5.5 严格一致性
任何时候写入操作需要立刻(t2>t1)在其他节点上可见,需要立刻被任何客户端读到,这样任何客户端读取到的数据一定是严格的一致,不存在任何偏差。
严格一致性是一种理想的一致性模型,实际场景中几乎不会存在。
1.5.6 线性一致性
线性一致性(Linearizability Consistency)是由M.Herlihy和J.Wing在1991年发表的论文《Linearizability: A Correctness Condition for Concurrent Objects》中提出的,也称为强一致性(Strong Consistency),或原子一致性(Atomic Consistency)。
系统表现的好像是一个单一的副本,在全局的时间下,按顺序执行读写操作。
图 1‑24 线性一致性时序图
画图说明,将线性化点连接,呈现出一条随时间单调递增的折现,这就是线性化定义的由来。
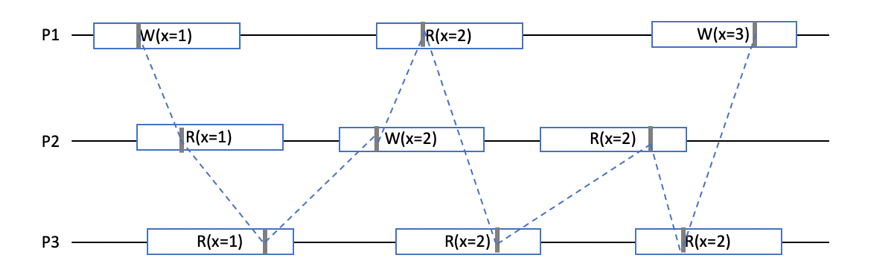
图 1‑25 线性化点与执行序列
根据全局时钟,可以对事件进行排序,生成一个全序序列。交叉(并发)部分,顺序排列有多种可能性(线性化点不确定),无交叉的部分,按时间轴排序即可。
线性一致性的实现,可以是读写策略都在主节点上进行,也可以采用共识算法。注意无主复制的分布式系统,不一定严格遵循线性化一致性,取决于NWR的配置(如N=3, W=2, R=2不遵守线性一致性)。
举个例子,线性一致性的实际应用场景。比赛得分。
1.5.7 顺序一致性
早在线性一致性提出之前,Lamport在1979年就已经提出了顺序一致性(Sequential Consistency)的概念。
不要求写入操作立刻在各节点可见,但要求不同的写入操作在各节点上以相同的顺序可见。也就是说,所有操作可以按全局来排序。
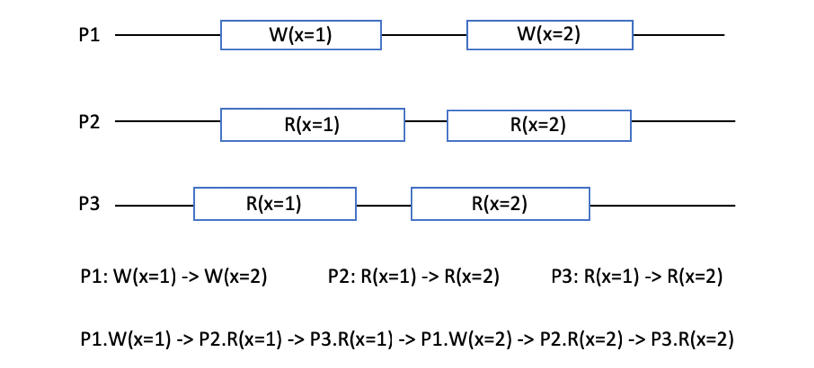
图 1‑26 符合顺序一致性
画图说明,将不同的事件排序,生成偏序序列。
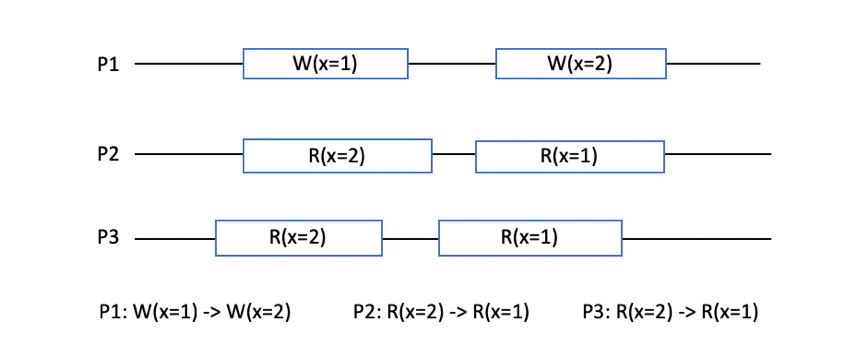
图 1‑27 不符合顺序一致性
举个例子,朋友圈A发布两条动态,B、C以相同的顺序观测到内容更新,但B可能看到第二条,A才看到第一条。
举个例子,Zookeeper的顺序一致性如何实现。
1.5.8 因果一致性
不要求所有操作按顺序执行,但具备因果关系的操作需要按顺序执行
因果一致性的实现方式。
1.5.9 最终一致性
Eventual Consistency这个一致性级别是Amazon的CTO Werner Vogels在2009发表的一篇论文里提出的,他是Amazon基于Dynamo等系统的实战经验总结的一种很务实的实现。最终一致性的问题在于“最终”的概念模糊,没有规定多长时间副本数据会收敛到一致。
最终一致性是一种比较弱的一致性保证。它实现了Liveness语义,但不保证Safety。
1.5.10 可调一致性
无主的NWR可调一致性
MongoDB的可调一致性
1.6 会话模型
把用户关到一个房间里,无法和其他用户交流,也看不到物理时钟。这个问题就退化成单一客户端层面的一致性模型。
站在单一客户端Session的角度看一致性,称为会话模型。这种一致性模型,和当前用户相关,和其他用户无关,也不用关心其他用户读到了什么数据。
会话模型是一种弱一致性的变种。
1.6.1 读已所写
发朋友圈,发现刚写完,一刷新就没了。
实现方式,读写都打到主库上,或设置时间窗口,1分钟内的读主库,超过1分钟的读从库。或将写入时间戳保存到客户端,服务端只响应大于该时间戳的更新。
1.6.2 单调读
刷新朋友圈,一会有,一会又消失,糟糕的用户体验。
实现方式,通过路由规则,将同一用户的读请求路由到固定副本上。
1.6.3 单调写
1.6.4 读后写
1.7 容错
1.7.1 网络模型
网络模型大致可以分为同步网络模型和异步网络模型。
同步网络模型:每个进程都具备精确的时钟,且各进程之间的时钟时刻保持同步;进程之间的消息传递延迟存在一个已知的上限;每个进程处理的步骤和频率是确定的。
异步网络模型:进程不存在任何时钟,更谈不上是时钟同步;进程之间消息传递延迟没有明确的上限;每个进程处理的步骤和频率不确定。
在实际环境中,同步网络模型的假设几乎是不现实的。网络可能存在丢包、延迟,时钟可能同步失败,消息传递可能出现无限延迟,等等。因此,我们应该更多考虑异步网络模型。
1.7.2 故障模型
故障主要分为两大类,他们之间没有明显的界限:
节点故障:通常指节点奔溃、处理延迟上升、进程暂停等。
网络故障:通常指网络数据包传输发生延迟、丢包、乱序、重排,或网络发生分区,等等。
故障模型通常分为以下几类:
Byzantine Failure:节点可以“撒谎”,伪造数据。一方面,节点可以随意伪造数据并传递给其他节点,比如将x设为true发送给某个节点,同时将x设为false发给其他节点。另一方面,节点可以修改其他节点发送过来的数据,如对方发送的x=true,但当前节点收到后却修改为x=false。
Authentication Detectable Byzantine Failure:节点依旧可以伪造数据并发送给其他节点,但不能伪造其他节点发送过来的数据。我们可以认为这种错误是Byzantine Failure的一种特例。
Performance Failure:比较容易理解的一种故障模型。节点能够输出正确的值,但响应的时间不符合预期,要么太早,要么太晚。
Omission Failure:这种故障是Performance Failure的一种特例。节点响应的时间无限延迟,即对方完全无法接收到数据。
Crash Failure:这种故障是Omission Failure的一种特例。当节点发生Omission failure时,直接停止了响应,我们可以认为该节点发生了奔溃。
Fail-stop Failure:这种故障是Crash Failure的一种特例。当节点发生Crash failure时,其他正常工作的节点可以检测到该错误。
从Byzantine Failure到Fail-stop Failure,严重程度依次降低,对业务的影响也逐渐减少。我们可以认为从上到下是包含关系,即:Byzantine Failures ⊃ Authentication Detectable Byzantine Failures ⊃ Performance Failures ⊃ Omission Failures ⊃ Crash Failures ⊃ Fail-stop Failures。
我们也可以将这些故障模型简单的分为两类:值故障(Value Failures)和时间故障(Timing Failures)。很明显,Byzantine failure和Authentication Detectable Byzantine Failure属于值故障,其余的属于时间故障。
1.7.3 故障检测
1.7.4 死亡与残废节点
1.7.5 集群选举
Bully算法及流程
Raft算法及流程
1.8 事务
1.8.1 事务的ACID特性
原子、一致、隔离、持久
1.8.2 读写异常
ANSI标准列出的几种异常:脏读、不可重复读、幻读
脏读本质是来说,是事务读到了被其他事务修改过的值,然后其他事务接下来会回滚该值,或再次变更该值,那么这个读到值就不再可信。画个时序图来说明。
实际还有其他的异常:读倾斜(Read Skew)、脏写、丢失更新、写倾斜(Write Skew)
结合事务的时序图,深入分析下各种异常的成因
1.8.3 隔离级别与并发控制
ANSI标准列出的几种隔离级别,以及和三种读异常之间的矩阵关系:读未提交RU、读已提交RC、可重复读RR、串行化S
实际后人还给出了其他的隔离:如快照隔离
给出一些常见的并发控制的手段:PCC(悲观并发控制)、OCC(乐观并发控制)、MVCC(多版本并发控制)。
快照隔离SI:MVCC方式实现,说下MVCC的工作原理。可实现RC和RR,解决脏读和不可重复读。RC是每次Select建立快照,RR是事务的第一个Select建立快照。
两阶段锁2PL:一种悲观策略,共享锁和排它锁。事务的某个时间获取锁,事务结束后释放锁,故称为两阶段锁。2PL可实现串行化。
Next-Key Lock:将某查询条件下的所有记录加锁。用于解决幻读。
串行化快照隔离SSI:采用乐观的思路,在提交时做快照检查,发现对象被修改则中断提交。既具备了快照隔离SI的优点(读写不干扰)、又实现了串行化。
1.8.4 两阶段提交
两阶段提交(2PC,Two-Phase-Commit)由分布式事务大师Jim Gray提出,是一种解决分布式事务的共识算法。2PC是一种成熟的分布式事务算法,至今还在大部分分布式系统尤其是存储系统中被广泛使用。
画一个时序图说明2PC的工作流程:提议阶段(Propose)、提交/回滚阶段(Commit)。只有协调者设置了超时。两阶段提交的流程如下:
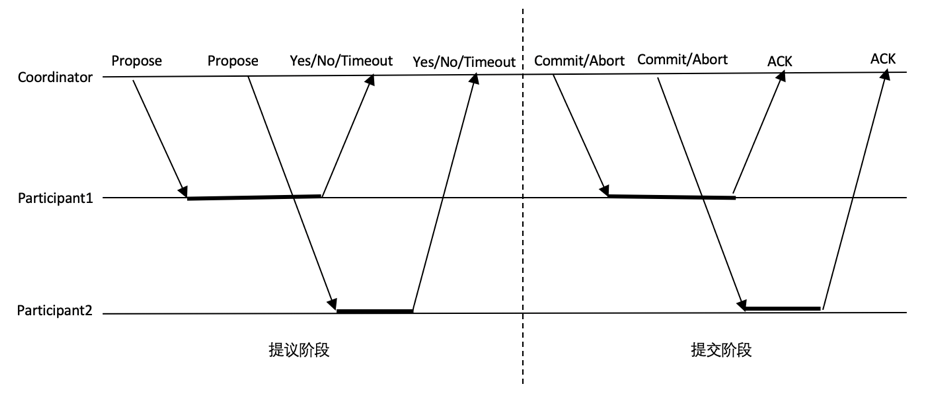
图 1‑28 两阶段提交
提议阶段。Coordinator阶段将操作写入本地事务日志,并向所有Participant广播Propose提议。Participant接收到提议后,开启事务操作并锁定相关资源,将undo/redo写入本地事务日志,当一切就绪后,向Coordinator回复Yes。如果出现问题,则回复No。Coordinator收到所有回复,或等待超时后,进入提交阶段。
提交阶段。如果在上一阶段Coordinator收到的全部是Yes回复,则向Participant广播Commit消息。否则,如收到了一个或多个No回复,或发生了一个或多个超时,则向Participant广播Abort消息。Participant收到Commit/Abort消息后,将本地事务进行提交或回滚,释放资源,并向Coordinator回复ACK。
说明每个阶段可能会发生的故障点以及应对措施。举个组织朋友周末郊游的例子说明。
第一阶段:存在的异常情况有Coordinator奔溃,或Participant奔溃,或者Coordinator与Participant之间的网络出现分区。无论哪种情况出现,所有节点最终都会进入第二阶段。
Coordinator在未发出任何Propose之前奔溃了。因为Participant未收到任何Propose,事务尚未执行,所以对系统毫无影响。
Coordinator在发出部分Propose之后奔溃了。对于已收到Propose的Participant而言,回复Yes必然超时,由于无法确认Coordinator是否已收到Yes消息,会重试几次后直接进入第二阶段等待Commit消息。同样的道理,回复No也必然超时,无论Coordinator收到消息与否,在第二阶段也必然会广播Abort消息,因此Participant没有必要进入第二阶段,会在重试几次后主动终止事务。对于未收到Propose的Participant而言,由于事务尚未开启,故不会造成影响。
Coordinator在发出所有Propose之后,在超时时间内未收到全部Yes/No响应。这种情况Coordinator会进入第二阶段,向所有Participant广播Abort消息。
第二阶段:同样会存在Coordinator奔溃,或Participant奔溃,或者Coordinator与Participant之间的网络出现分区。第二阶段Participant无法主动提交或终止事务,必须等待Coordinator发出指令。Coordinator会无限重试,而Participant会阻塞等待。
Coordinator发送部分Commit/Abort消息后奔溃了。Participant要么接收不到Commit/Abort消息,要么Ack发送失败,会一直阻塞等待。
Coordinator发送Commit/Abort消息后长时间收不到Ack响应。这种情况下Coordinator会一直无限重试,直到成功为止。
两阶段存在的缺点:提交/回滚阶段发生故障后协调者一直重试导致性能下降、阻塞性协议的弊端;协调者发生故障导致参与者进入不确定状态,无限等待。提交阶段,数据不一致。
1.8.5 三阶段提交
鉴于两阶段提交的阻塞性问题,1983年由Dale Skeen 和 Michael Stonebraker了三阶段提交(3PC,Three-Phase-Commit)协议来解决2PC阻塞的问题。
画一个时序图说明3PC的工作流程:提议阶段(Propose)、预提交阶段(PreCommit)、提交/回滚阶段(Commit)。也称为CanCommit、PreCommit、DoCommit三个阶段。协调者和参与者都设置了超时。三阶段提交的流程如下:
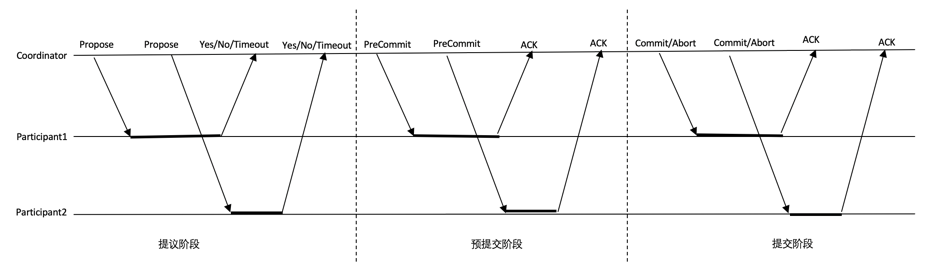
图 1‑29 三阶段提交
提议阶段。Coordinator阶段将操作写入本地事务日志,并向所有Participant广播Propose提议。Participant接收到提议后,开启事务操作并锁定相关资源,将undo/redo写入本地事务日志,当一切就绪后,向Coordinator回复Yes。如果出现问题,则回复No。Coordinator收到所有回复,或等待超时后,进入提交阶段。
预提交阶段。在提议阶段如果Coordinator收到的全部是Yes回复,则向Participant广播PreCommit消息。否则,如收到了一个或多个No回复,或发生了一个或多个超时,则向Participant广播Abort消息。Participant收到PreCommit/Abort消息后,做好提交或回滚事务的准备并发送Ack。
提交阶段。在预提交阶段如果Coordinator在超时时间内全部收到Ack,则向Participant广播Commit消息,否则广播Abort消息。Participant收到PreCommit/Abort消息后,正式提交或回滚事务,并发送Ack。
说明每个阶段可能会发生的故障点及应对措施
第一阶段:存在的异常情况有Coordinator奔溃,或Participant奔溃,或者Coordinator与Participant之间的网络出现分区。无论哪种情况出现,所有节点最终都会进入第二阶段。异常的处理方式和2PC第一阶段是一样的。
第二阶段:同样会存在Coordinator奔溃,或Participant奔溃,或者Coordinator与Participant之间的网络出现分区。
Coordinator发送PreCommit消息后长时间收不到Ack或奔溃后重启,则会进入第三阶段,发送Abort消息。
Participant如果长时间收不到PreCommit消息,或回复Ack之前发生奔溃,则可以主动终止事务。
第三阶段:同样会存在Coordinator奔溃,或Participant奔溃,或者Coordinator与Participant之间的网络出现分区。
Coordinator发送Commit/Abort消息后,如果长时间收不到Ack或奔溃重启后,会重新发送消息,重试几次后结束。
Participant长时间收不到Commit/Abort消息,则会主动提交事务。
3PC的缺点,在准备阶段,可能会出现部分参与者故障,其他参与者因为已达到准备状态,自动提交,最终导致各节点状态不一致。
1.8.6 Saga事务
1987年普林斯顿大学的H.Garcia-Molina和Salem发表了一篇论文提出了Saga的概念。一个长事务T中的操作可以拆分为彼此独立的本地事务T1、T2、 T3, 那么就可以称之为Saga。其中的每一个Ti都有一个相应的补偿事务Ci。如果部分Ti失败了需要Ci来修复回原始状态,Ci不会直接把数据库改回原先的状态, Ci通常是像前面说的会计的做法追加修正内容去抹平Ti带来的变化。
下图中事务参与者有A,B,C,每次发起的事务都有一个全局唯一的id, 参与者之间的消息在网络故障时可以重发 (可以通过id去重复消息, 或者保证幂等操作)。假如T3在C中执行时失败了,如果T3已经提交了或者这个系统不支持回滚,那么必须使用C3来补偿T3带来的变化。然后发消息给B,B会执行C2去补偿T2,然后B可以选择继续通知A去回滚,或者稍后等外部条件发生变化再执行T2,然后让C去重试。这样整个系统变成了一个状态机,参与者之间虽然有可能不一致,一个订单或者一笔交易一定会处于状态机的某一个状态,整个事务的过程仍然是整体可以追溯的。
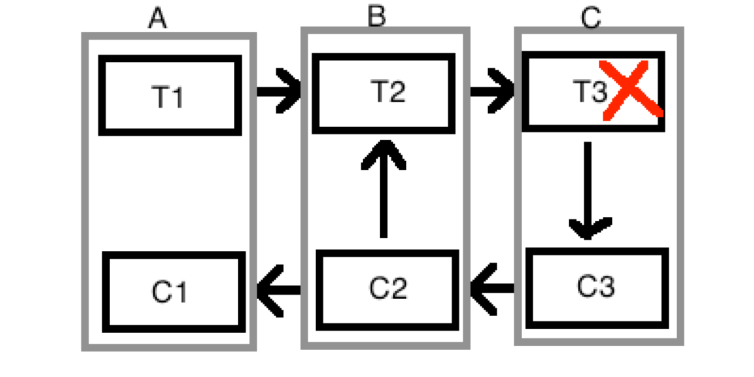
图 1‑30 SAGA事务
1.8.7 TCC事务
TCC(Try-Confirm-Cancel)的概念,最早是由 Pat Helland 于在2007 年发表的一篇名为《Life beyond Distributed Transactions: an Apostate’s Opinion》的论文中提出来的。TCC的核心思想是:针对每个操作,都应该有确认和补偿两种操作成对出现。
Try阶段:对系统资源以及约束做检查,并预留足够的资源供后续操作所需。
Confirm阶段:执行事务提交,各系统更新状态,释放资源。
Cancel阶段:当遇到事务执行失败时,发起撤销动作,各系统执行回滚并释放资源。
TCC的容错思路很简单,当在Confirm阶段或Cancel阶段出现错误时,会一直重试,直到操作成功为止。TCC要求业务实现中需要考虑操作的幂等性。
1.8.8 本地消息表
本地消息表的核心思想是将分布式事务拆分成一个个小的本地事务,并借助本地数据库来记录操作流程,实现本地事务。各系统通过异步方式处理本地事务,从而实现分布式事务的目的。
业务系统A将数据变更记录以消息数据的方式写入到本地消息表中,再执行事务操作写入业务数据,消息数据和业务数据在同一个数据库中,这样的好处是A系统可以实现本地的事务。写入完成后,发送消息到MQ中,通知其他系统,如果消息发送失败,会进行重试。
业务系统B通过监听MQ消息变化,识别到新的事件。服务B也将该操作记录到本地消息表中,同时执行事务,写入业务数据。当处理事务失败时,会发送回滚操作消息给系统A。
很明显,本地消息表是一种异步的分布式事务处理方式,它实现了数据的最终一致性。
1.8.9 MQ事务
RocketMQ的分布式事务实现方式
1.9 共识
1.9.1 共识的原则
分布式共识简单来说,就是指分布式系统中的全部或部分节点就某个提议(Proposal)达成一致。它包括以下几个基本的原则:
协定性(Agreement): 所有节点决定的值都是一样的,换句话说,两个不同的进程不能选择不同的值,最终一定会就该值达成一致。
有效性(Validity ):最终决定的值必须是其中一个节点发起提议的。也就是说,最终会从一组提议的值中选择一个值,而不是其他的情况。
终结性(Termination):所有节点最终都会决定值,而不是悬而未决,共识算法应该是最终收敛的。
举个简单的例子,团队组织活动,大家七嘴八舌发起了以下提议(Proposals):吃饭、爬山、钓鱼。决议开始了,经过若干轮投票,最终团队所有成员会同意同一项活动(Agreement);该活动必须是吃饭、爬山、钓鱼中的一项(Validity );投票过程一定是可终止的,而不是迟迟没有结果(Termination)。
我们可以认为协定性(Agreement)和有效性(Validity )保证了分布式算法的安全性(Safety),而终结性(Termination)则保证了算法的活性(Liveness)。
安全性(Safety)和活性(Liveness)是分布式系统正确性的两个重要特性,Safety更偏向于Nothing bad happens,而Liveness则倾向于Something good eventually happens。
1.9.2 Paxos算法
Paxos是分布式专家Leslie Lamport于1997年撰写的论文“The Part-Time Parliament”中提出的一种分布式共识算法,该算法在分布式领域中具有举足轻重的作用,是目前公认的最有效的分布式一致性算法之一。
Paxos算法是一种高度容错的算法,在不稳定的网络和节点情况下,能够让各分布式节点能够就某个提议达成一致。Paxos的基本角色有:Proposer、Acceptor、Learner,我们这里只讨论Proposer和Acceptor两类角色之间的交互。
Paxos算法的基本约束有(这里没有给出推理过程):
P1:任何一个Acceptor必须接受它收到的第一个提案。
P2:如果某个value为v的提案被选定了,那么每个编号更高的被选定提案的value必须也是v。
P2a:如果某个value为v的提案被选定了,那么每个编号更高的被Acceptor接受的提案的value必须也是v。
P2b:如果某个value为v的提案被选定了,那么之后任何Proposer提出的编号更高的提案的value必须也是v。
P2c:对于任意的N和V,如果提案[N, V]被提出,那么存在一个半数以上的Acceptor组成的集合S,满足以下两个条件中的任意一个:
S中每个Acceptor都没有接受过编号小于N的提案。S中Acceptor接受过的最大编号的提案的value为V。
Paxos算法的基本流程如下:
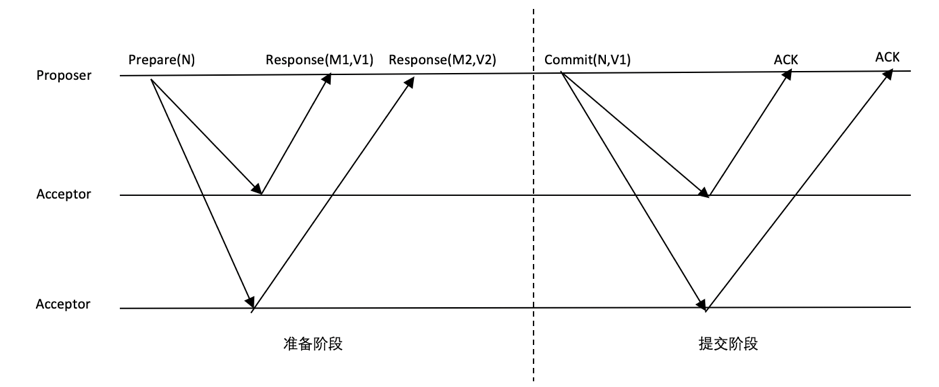
图 1‑31 Pxos算法流程
准备阶段:
Proposer选择一个提案编号N,然后向半数以上的Acceptor发送编号为N的Prepare请求。
如果一个Acceptor收到一个编号为N的Prepare请求,且N大于该Acceptor已经响应过的所有Prepare请求的编号,那么它就会将它已经接受过的编号最大的提案(如果有的话)作为响应反馈给Proposer,同时该Acceptor承诺不再接受任何编号小于N的提案。反之,如果该Prepare请求的编号N小于等于已响应过的最大编号,则本次不予响应或响应一个错误。
提交阶段:
如果Proposer收到半数以上Acceptor对其发出的编号为N的Prepare请求的响应,那么它就会发送一个针对[N,V]提案的Accept请求给半数以上的Acceptor。注意:V就是收到的响应中编号最大的提案的value,如果响应中不包含任何提案,那么V就由Proposer自己决定。
如果Acceptor收到一个针对编号为N的提案的Accept请求,只要该Acceptor没有对编号大于N的Prepare请求做出过响应,它就接受该提案,接着向Proposer回复ACK。反之,如果该Accept请求的编号N小于等于已响应过的最大编号,则本次不予接受或返回一个错误。
如果Proposer收到半数以上Acceptor对其发出的编号为N的Accept请求的ACK,则确定该值V被选定。反之,则宣告失败,重新发起Prepare请求。
1.9.3 ZAB算法
ZAB协议(Zookeeper Atomic Broadcast,Zookeeper原子广播协议),主要应用在Zookeeper的节点共识算法中,目的是保证数据的一致性,它借鉴了Paxos算法的思想,但并没有真正实现它。ZAB是为Zookeeper专门设计的支持奔溃恢复的一种原子广播协议。
ZAB协议需要保证两个基本约束:
确保那些已经在 Leader 服务器上提交(Commit)的事务,最终被所有的服务器提交。
确保丢弃那些只在 Leader 上被提出而没有被提交的事务。
ZAB协议工作在两种模式:消息广播模式和奔溃恢复模式。ZAB协议从理论上来讲,可以进一步细分为三个阶段:Phase1-发现、Phase2-同步、Phase3-广播,严格来说可以再包括选举阶段,即Phase0-选举,即:Phase0-选举(Leader Election)-> Phase1-发现(Discovery) -> Phase2-同步(Synchronization) -> Phase3-广播(Broadcast)。
注意,在实际的Zookeeper实现中,由于使用了Fast Leader Election(FLE),该算法已兼容了发现阶段的逻辑。所以,实际的实现中,各阶段如下:Phase1-选举(Fast Leader Election) -> Phase2-恢复(Recovery Phase) -> Phase3-广播(Broadcast Phase)。
可以认为恢复阶段(Recovery Phase)将发现和同步阶段进行了合并。限于篇幅,本文主要介绍理论的四个阶段:选举、发现、同步和广播。
Phase0-选举(Leader Election)阶段:当发生网络分区,或出现Leader节点宕机、Leader进程奔溃或重启时,集群进入奔溃恢复模式。大致流程如下:
新选举出来的 Leader不能包含未提交的Proposal。即新选举的Leader必须都是已经提交了Proposal的Follower服务器节点。新选举的Leader节点中含有最大的zxid。这样做的好处是可以避免Leader服务器检查Proposal的提交和丢弃工作。
如何理解“新选举的Leader节点中含有最大的zxid”?举例说明。
Leader的选举可以分为两个方面,同时选举主要包含事务zxid和节点myid,节点主要包含LEADING\FOLLOWING\LOOKING共3个状态。
服务启动期间的选举:
首先,每个节点都会对自己进行投票,然后把投票信息广播给集群中的其他节点;
节点接收到其他节点的投票信息,然后和自己的投票进行比较,首先zxid较大的优先,如果zxid相同那么则会去选择myid更大者,节点更新和保管好本地的投票。此时大家都是LOOKING的状态;
投票完成之后,开始统计投票信息,如果集群中过半的机器都选择了某个节点机器作为leader,那么选举结束;
最后,更新各个节点的状态,Leader改为LEADING状态,Follower改为FOLLOWING状态;
服务运行期间的选举:
如果开始选举出来的leader节点宕机了,那么运行期间就会重新进行leader的选举。
Leader宕机之后,非Observer节点都会把自己的状态修改为LOOKING状态,然后重新进入选举流程;
生成投票信息(myid,zxid),同样,第一轮的投票大家都会把票投给自己,然后把投票信息广播出去;
接下来的流程和上面的选举是一样的,都会优先以zxid为主,然后再选择myid,最后统计投票信息,修改节点状态,选举结束;
Phase1-发现(Discovery)阶段:选举阶段产生的Leader还只能称之为“准Leader”,需要进入发现阶段。首先说明下每个节点所持有的一些信息:
history:当前节点接收到事务 Proposal 的历史日志。
acceptedEpoch:已接受的Leader发出的最新NEWEPOCH所包含的epoch。
currentEpoch:已接受的Leader发出的最新NEWLEADER所包含的epoch。
lastZxid:history 中最近接收到的Proposal 的 zxid,也就是最大zxid。
发现阶段的基本工作流程如下:
Follower向准Leader发送FOLLOWERINFO(F.acceptedEpoch)消息。
准Leader接收到FOLLOWERINFO消息后,从Quorum集合中找出FOLLOWERINFO(e)最大的e,递增生成新的e’,发送NEWEPOCH(e’)到Follower,表示开启新的Leader纪元。
Follower接收到NEWEPOCH(e’)后,比较e’和本地的F.acceptedEpoch,若e’> F.acceptedEpoch,则将本地F.acceptedEpoch更新成e‘,同时向准Leader发送确认消息ACKEPOCH(F.currentEpoch, F.history, F.lastZxid)。反之,若e’< F.acceptedEpoch,则进入Phase0阶段,重新选举。
准Leader接收到ACKEPOCH消息后,从Quorum集合中找出F.currentEpoch和 F.lastZxid最大的Follower,将L.history更新成F.history。进入Phase2同步阶段。
Phase2-同步(Syncronization)阶段:同步阶段是指Leader在发现阶段确定了Proposal历史后,开始和各Follower数据同步和对齐的过程,流程如下:
准Leader向Follower发送NEWLEADER(e', L.history)消息。
Follower接收到NEWLEADER(e', L.history)消息后,比较e’和本地的F.acceptedEpoch,若e’=F.acceptedEpoch,则将F. currentEpoch更新成e’,同时将L.history应用到本地,实现数据同步,最后将F.hisotry更新成L.history,并向准Leader发送ACKNEWLEADER(e', L.history)消息。反之,若e’!=F.acceptedEpoch,则进入Phase0阶段,重新选举。
Leader想Follower发送COMMIT消息。进入Phase3广播阶段。
Follower接收到COMMIT消息后,按照zxid顺序开始提交事务。进入Phase3广播阶段。
Phase3-广播(Broadcast)阶段:消息广播模式是指集群正常提供读写服务的工作模式,它的写操作基本流程如下:
客户端发起一个写请求到协调节点,协调节点将请求转发到Leader节点。协调节点可能本身就是Leader节点,这种情况就无需转发。
Leader节点将客户端的写请求转化为事务Proposal提案,同时为每个Proposal分配一个全局递增的ID,即zxid。
Leader节点为每个Follower服务器分配一个单独的FIFO队列,然后将需要广播的Proposal依次放到队列中,并且根据FIFO策略进行消息发送。
Follower节点在接收到Proposal后,首先将该Proposal以事务日志的方式写入本地持久化存储(如磁盘、SSD等)中,写入成功后向Leader节点反馈一个Ack响应消息。
Leader节点接收到超过半数以上Follower节点的Ack响应消息后,即认为消息发送成功,可以发送commit消息。
Leader节点向所有Follower节点广播commit消息,同时自身也会完成事务提交。Follower节点接收到commit消息后,会将上一条事务提交。
1.9.4 Raft算法
https://zhuanlan.zhihu.com/p/32052223?utm_medium=social&utm_source=wechat_session
Raft算法中,存在三种角色:Leader、Follower和Candidate。
Leader:处理客户端读写请求,写入事务日志,并向Follower同步日志。
Follower:同步Leader的日志并持久化。
Candidate:在Leader选举中临时产生的角色。
Raft选举过程:Leader周期性的向Follower节点发送心跳信息(Heartbeat)。当Follower在一个选举超时时间内未接受到Leader的心跳,则会认为Leader已奔溃,Follower会发起一轮选举。
Follower将自身的状态置为Candidate,首先投票给自己,并向其他Follower发送RequestVote RPC请求。其他Follower接收到请求后,会比较自身的term与请求Follower的term,如果term合法,则将投票信息返回给对方。投票发起方,当最终收集的投票数过半时,则投票生效,将自身状态修改为Leader,并发送心跳给其他Follower,确定其领导者地位。
Raft日志同步过程:
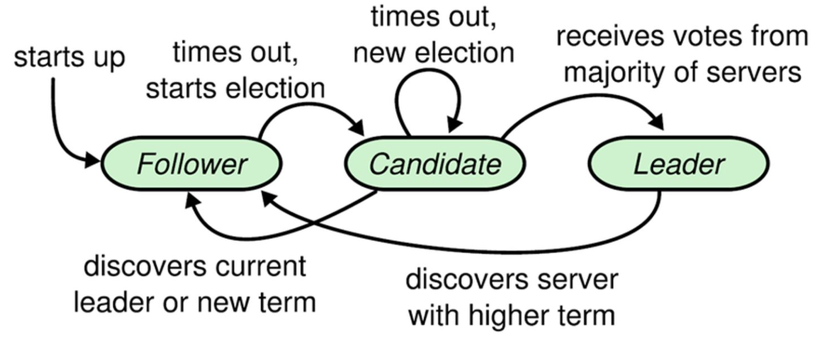
图 1‑32 Raft状态转换