实战中学习浏览器工作原理 — HTML 解析与 CSS 计算
我是三钻,一个在《技术银河》中等你们一起来终生漂泊学习。
点赞是力量,关注是认可,评论是关爱!下期再见 👋!
前言
上一部分我们完成了从 HTTP 发送 Request,到接收到 Response,并且把 Response 中的文本都解析出来。
这一部分我们主要讲解如何做 HTML 解析 和 CSS 计算这两个部分。
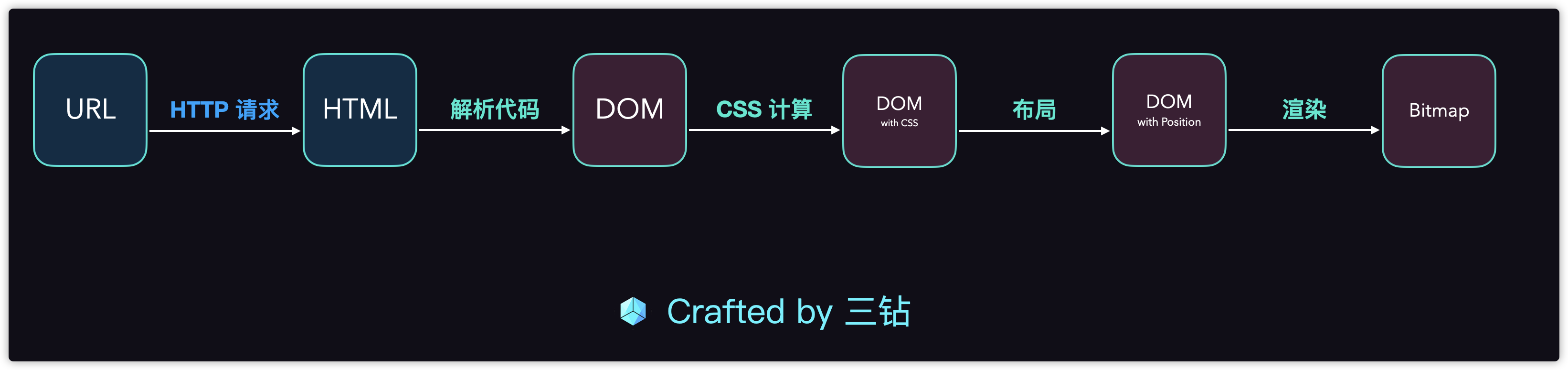
根据我们上部分列出的一个完整的浏览器架构的话,蓝色背景的部分就是我们目前已经完成的流程。

HTML 解析
HTML parse 模块的文件拆分
思路:
为了方便文件管理,我们把 parser 单独拆分到文件中
parser 接收 HTML 文本作为参数,返回一棵 DOM 树
加入 HTML Parser
上一篇文章中我们最后获得了一个 对象
这里我们就考虑如何利用这个 中的 body 内容
所以我们应该从获得 Response 之后,把 body 内容传给 parser 中的 parseHTML 方法进行解析
在真正的浏览器中,我们是应该逐段的传给 parser 处理,然后逐段的返回
因为这里我们的目标只是简单实现浏览器工作的原理,所以我们只需要统一解析然后返回就好
这样我们更容易理解,代码也更加清晰易懂
文件:client.js
// 这个是 client.js
// 1. 引入 parser.js
const parser = require('./parser.js');
// ...
//... 之前的代码在此处忽略
// ...
let response = await request.send();
// 2. 在 `请求方法` 中,获得 response 后加入 HTML 的解析代码
let dom = parser.parseHTML(response.body);文件:parser.js
/**
* 解析器
* @filename parser.js
* @author 三钻
* @version v1.0.0
*/
module.exports.parseHTML = function (html) {
console.log(html); // 这里我们先 console.log 打印一下返回的 HTML 内容
};用有效状态机 (FSM) 实现 HTML的分析
我们用 FSM 来实现 HTML 的分析
在 HTML 标准中,已经规定了 HTML 的状态
我们的浏览器只挑选其中一部分状态,完成一个最简版本
HTML 标准里面已经把整个状态机中的状态都设计好了,我们直接就看HTML标准中给我们设计好的状态:https://html.spec.whatwg.org/multipage/,我们直接翻到 “Tokenization” 查看列出的状态,这里就是所有 HTML 的词法。
有些同学在读这个标准的时候会说 “我看不懂”,“我太难了”,“我看懵了”。其实我们看不懂是因为这里面的标准是写给浏览器实现者去看的,但是用实现我们的浏览器的状态机之后,我们就可以看懂了,而且发现这里面写的非常像我们的代码。这个标准中写的就是伪代码。我们只需要把这里面的伪代码写成真实代码就可以了。
在 HTML 中有80个状态,但是在我们这里,因为只需要走一遍浏览器工作的流程,我们就不一一实现了,我们在其中挑选一部分来实现即可。
下面我们来初始化一下我们的 的状态机:(把上面的 的基础上进行修改)
文件:parser.js
/**
* 解析器
* @filename parser.js
* @author 三钻
* @version v1.0.0
*/
const EOF = Symbol('EOF'); // EOF: end of file
function data(char) {}
/**
* HTTP 解析
* @param {string} html 文本
*/
module.exports.parseHTML = function (html) {
let state = data;
for (let char of html) {
state = state(char);
}
state = state(EOF);
};+ 上面的代码中用了一个小技巧,因为 HTML 最后是有一个文件终结的
+ 所有最后需要给他一个结束字符(重点是这里用一个没有特别意义的字符)
+ 我们这里使用了 创建了一个 字符,代表 End of file (文件结束)
解析标签
HTML 有三种标签
思路:
主要的标签有:开始标签,结束标签和自封闭标签
在这一步我们暂时忽略属性
文件:parser.js
/**
* 解析器
* @filename parser.js
* @author 三钻
* @version v1.0.0
*/
const EOF = Symbol('EOF'); // EOF: end of file
/**
* HTML 数据开始阅读状态
* --------------------------------
* 1. 如果找到 `<` 就是标签开始状态
* 2. 如果找到 `EOF` 就是HTML文本结束
* 3. 其他字符就继续寻找
* @param {*} char
*
* @return {function}
*/
function data(char) {
if (char === '<') {
// 标签开始
return tagOpen;
} else if (char === EOF) {
// 文本结束
return;
} else {
return data;
}
}
/**
* 标签开始状态
* ----------------------------------
* 1. 如果找到 `/` 证明是自关闭标签
* 2. 如果是字母就是标签名
* 3. 其他字符就直接继续寻找
* @param {*} char
*/
function tagOpen(char) {
if (char === '/') {
// 自关闭标签
return endTagOpen;
} else if (char.match(/^[a-zA-Z]$/)) {
// 标签名
return tagName(char);
} else {
return;
}
}
/**
* 标签结束状态
* --------------------------------
* 1. 如果是字母就是标签名
* 2. 如果直接是 `>` 就报错
* 3. 如果是结束符合,也是报错
* @param {*} char
*/
function endTagOpen(char) {
if (char.match(/^[a-zA-Z]$/)) {
return tagName(char);
} else if (char === '>') {
// 报错 —— 没有结束标签
} else if (char === EOF) {
// 报错 —— 结束标签不合法
}
}
/**
* 标签名状态
* --------------------------------
* 1. 如果 `\t`(Tab符)、`\n`(空格符)、`\f`(禁止符)或者是空格,这里就是属性的开始
* 2. 如果找到 `/` 就是自关闭标签
* 3. 如果是字母字符那还是标签名
* 4. 如果是 `>` 就是开始标签结束
* 5. 其他就是继续寻找标签名
* @param {*} char
*/
function tagName(char) {
if (c.match(/^[\t\n\f ]$/)) {
return beforeAttributeName;
} else if (char === '/') {
return selfClosingStartTag;
} else if (c.match(/^[a-zA-Z]$/)) {
return tagName;
} else if (char === '>') {
return data;
} else {
return tagName;
}
}
/**
* 标签属性状态
* --------------------------------
* 1. 如果遇到 `/` 就是自封闭标签状态
* 2. 如果遇到字母就是属性名
* 3. 如果遇到 `>` 就是标签结束
* 4. 如果遇到 `=` 下来就是属性值
* 5. 其他情况继续进入属性抓取
* @param {*} char
*/
function beforeAttributeName(char) {
if (char === '/') {
return selfClosingStartTag;
} else if (char.match(/^[\t\n\f ]$/)) {
return beforeAttributeName;
} else if (char === '>') {
return data;
} else if (char === '=') {
return beforeAttributeName;
} else {
return beforeAttributeName;
}
}
/**
* 自封闭标签状态
* --------------------------------
* 1. 如果遇到 `>` 就是自封闭标签结束
* 2. 如果遇到 `EOF` 即使报错
* 3. 其他字符也是报错
* @param {*} char
*/
function selfClosingStartTag(char) {
if (char === '>') {
return data;
} else if (char === 'EOF') {
} else {
}
}
/**
* HTTP 解析
* @param {string} html 文本
*/
module.exports.parseHTML = function (html) {
let state = data;
for (let char of html) {
state = state(char);
}
state = state(EOF);
};
创建元素
在状态机中,除了状态迁移,我们还会加入业务逻辑
我们在标签结束状态提交标签 token
业务逻辑:
首先我们需要建立一个 来暂存当前的 Token(这里我们是用于存放开始和结束标签 token 的)
然后建立一个 方法来接收最后创建完毕的 Token(这里后面会用逐个 Token 来创建 DOM 树)
HTML 数据开始状态 —— data
+ 如果找到的是 ,那就直接 emit 一个 type: ‘EOF’ 的 Token
+ 如果是文本内容的话,直接 emit 的 token
标签开始状态 —— tagOpen
+ 如果匹配中的是字母,那就是开始标签
+ 直接记录开始标签 Token 对象
+ 在 状态中我们会把整个完整的标签名拼接好
标签结束状态 —— endTagOpen
+ 如果匹配到字符,那就是结束标签名
+ 直接记录结束标签 Token 对象
+ 雷同,后面会在 状态中我们会把整个完整的标签名拼接好
标签名状态 —— tagName
+ 这里就是最核心的业务区了
+ 在第三种情况下,匹配到字母时,那就是需要拼接标签名的时候
+ 这里我们直接给 追加字母即可
+ 当我们匹配到 字符时,就是这个标签结束的时候,这个时候我们已经拥有一个完整的标签 Token了
+ 所以这里我们直接把 emit 出去
标签属性状态 —— beforeAttributeName
+ 在匹配到 字符的时候,这里就是标签结束的时候,所以可以 emit 的时候
自封闭标签状态 —— selfClosingStartTag
+ 这里追加了一个逻辑
+ 在匹配到 字符时,就是自闭标签结束的时候
+ 这里我们直接给 追加一个 的状态
+ 然后直接可以把 emit 出去了
文件:parser.js
/**
* 解析器
* @filename parser.js
* @author 三钻
* @version v1.0.0
*/
let currentToken = null;
/**
* 输出 HTML token
* @param {*} token
*/
function emit(token) {
console.log(token);
}
const EOF = Symbol('EOF'); // EOF: end of file
/**
* HTML 数据开始阅读状态
* --------------------------------
* 1. 如果找到 `<` 就是标签开始状态
* 2. 如果找到 `EOF` 就是HTML文本结束
* 3. 其他字符就继续寻找
* @param {*} char
*
* @return {function}
*/
function data(char) {
if (char === '<') {
// 标签开始
return tagOpen;
} else if (char === EOF) {
// 文本结束
emit({
type: 'EOF',
});
return;
} else {
// 文本
emit({
type: 'text',
content: char,
});
return data;
}
}
/**
* 标签开始状态
* ----------------------------------
* 1. 如果找到 `/` 证明是自关闭标签
* 2. 如果是字母就是标签名
* 3. 其他字符就直接继续寻找
* @param {*} char
*/
function tagOpen(char) {
if (char === '/') {
// 自关闭标签
return endTagOpen;
} else if (char.match(/^[a-zA-Z]$/)) {
// 标签名
currentToken = {
type: 'startTag',
tagName: '',
};
return tagName(char);
} else {
return;
}
}
/**
* 标签结束状态
* --------------------------------
* 1. 如果是字母就是标签名
* 2. 如果直接是 `>` 就报错
* 3. 如果是结束符合,也是报错
* @param {*} char
*/
function endTagOpen(char) {
if (char.match(/^[a-zA-Z]$/)) {
currentToken = {
type: 'endTag',
tagName: '',
};
return tagName(char);
} else if (char === '>') {
// 报错 —— 没有结束标签
} else if (char === EOF) {
// 报错 —— 结束标签不合法
}
}
/**
* 标签名状态
* --------------------------------
* 1. 如果 `\t`(Tab符)、`\n`(空格符)、`\f`(禁止符)或者是空格,这里就是属性的开始
* 2. 如果找到 `/` 就是自关闭标签
* 3. 如果是字母字符那还是标签名
* 4. 如果是 `>` 就是开始标签结束
* 5. 其他就是继续寻找标签名
* @param {*} char
*/
function tagName(char) {
if (char.match(/^[\t\n\f ]$/)) {
return beforeAttributeName;
} else if (char === '/') {
return selfClosingStartTag;
} else if (char.match(/^[a-zA-Z]$/)) {
currentToken.tagName += char;
return tagName;
} else if (char === '>') {
emit(currentToken);
return data;
} else {
return tagName;
}
}
/**
* 标签属性状态
* --------------------------------
* 1. 如果遇到 `/` 就是自封闭标签状态
* 2. 如果遇到字母就是属性名
* 3. 如果遇到 `>` 就是标签结束
* 4. 如果遇到 `=` 下来就是属性值
* 5. 其他情况继续进入属性抓取
* @param {*} char
*/
function beforeAttributeName(char) {
if (char === '/') {
return selfClosingStartTag;
} else if (char.match(/^[\t\n\f ]$/)) {
return beforeAttributeName;
} else if (char === '>') {
emit(currentToken);
return data;
} else if (char === '=') {
return beforeAttributeName;
} else {
return beforeAttributeName;
}
}
/**
* 自封闭标签状态
* --------------------------------
* 1. 如果遇到 `>` 就是自封闭标签结束
* 2. 如果遇到 `EOF` 即使报错
* 3. 其他字符也是报错
* @param {*} char
*/
function selfClosingStartTag(char) {
if (char === '>') {
currentToken.isSelfClosing = true;
emit(currentToken);
return data;
} else if (char === 'EOF') {
} else {
}
}
/**
* HTTP 解析
* @param {string} html 文本
*/
module.exports.parseHTML = function (html) {
let state = data;
for (let char of html) {
state = state(char);
}
state = state(EOF);
};
处理属性
属性值分为单引号、双引号、无引号三种写法,因此需要较多状态处理
处理属性的方式跟标签类似
属性结束时,我们把属性加到标签 Token 上
业务逻辑:
首先我们需要定义一个 来存放当前找到的属性
然后在里面叠加属性的名字和属性值,都完成后再放入 之中
标签属性名开始状态 —— beforeAttributeName
+ 这里如果遇到 空格,换行,回车等字符就可以再次进入标签属性名开始状态,继续等待属性的字符
+ 如果我们遇到 或者就是标签直接结束了,我们就可以进入属性结束状态
+ 如果遇到 或者 这里就有 HTML 语法错误,正常来说就会返回
+ 其他情况的话,就是刚刚开始属性名,这里就可以创建新的 对象 ,然后返回属性名状态
属性名状态 —— attributeName
+ 如果我们遇到空格、换行、回车、、 或者是 等字符时,就可以判定这个属性已经结束了,可以直接迁移到 状态
+ 如果我们遇到一个 字符,证明我们的属性名读取完毕,下来就是属性值了
+ 如果我们遇到 那就是解析错误,直接抛出
+ 最后所有其他的都是当前属性名的字符,直接叠加到 的 值中,然后继续进入属性名状态继续读取属性名字符
属性值开始状态 —— beforeAttributeValue
+ 如果我们遇到空格、换行、回车、、 或者是 等字符时,我们继续往后寻找属性值,所以继续返回 状态
+ 如果遇到 就是双引号属性值,进入
+ 如果遇到 就是单引号属性值,进入
+ 其他情况就是遇到没有引号的属性值,使用 的技巧进入
双引号属性值状态 -- doubleQuotedAttributeValue
+ 这里我们死等 字符,到达这个字符证明这个属性的名和值都读取完毕,可以直接把这两个值放入当前 Token 了
+ 如果遇到 或者 就是 HTML 语法错误,直接抛出
+ 其他情况就是继续读取属性值,并且叠加到 的 中,然后继续进入 doubleQuotedAttributeValue
单引号属性值状态 —— singleQuotedAttributeValue
+ 与双引号雷同,这里我们死等 字符,到达这个字符证明这个属性的名和值都读取完毕,可以直接把这两个值放入当前 Token 了
+ 如果遇到 或者 就是 HTML 语法错误,直接抛出
+ 其他情况就是继续读取属性值,并且叠加到 的 中,然后继续进入 singleQuotedAttributeValue
引号结束状态 —— afterQuotedAttributeValue
+ 如果我们遇到空格、换行、回车等字符时,证明还有可能有属性值,所以我们迁移到 状态
+ 这个时候遇到一个 字符,因为之前我们读的是属性,属性都是在开始标签中的,在开始标签遇到 ,那肯定是自封闭标签了。所以这里直接迁移到 状态
+ 如果遇到 字符,证明标签要结束了,直接把当前组装好的属性名和值加入 , 然后直接 emit 出去
+ 如果遇到 那就是 HTML 语法错误,抛出
+ 其他情况按照浏览器规范,这里属于属性之间缺少空格的解析错误 (Parse error: missing-whitespace-between-attributes)
无引号属性值状态 —— unquotedAttributeValue
+ 如果我们遇到空格、换行、回车等字符时,证明属性值结束,这个时候我们就可以直接把当前属性加入 currentToken,然后还有可能有其他属性,所以进入 状态
+ 如果遇到 证明标签是一个自封闭标签,先把当前属性加入 currentToken 然后进入 状态
+ 如果遇到 证明标签正常结束了,先把当前属性加入 currentToken 然后直接 emit token
+ 遇到其他不合法字符都直接抛出
+ 其他情况就是还在读取属性值的字符,所以叠加当前字符到属性值中,然后继续回到
属性名结束状态 —— afterAttributeName
+ 如果我们遇到空格、换行、回车等字符时,证明还没有找到结束字符,继续寻找,所以重新进入
+ 如果遇到 证明这个标签是自封闭标签,直接迁移到 状态
+ 如果遇到 字符证明下一个字符开始就是属性值了,迁移到 状态
+ 如果遇到 字符,证明标签正常结束了,先把当前属性加入 currentToken 然后直接 emit token
+ 如果遇到 证明HTML 文本异常结束了,直接抛出
+ 其他情况下,属于属性名又开始了,所以把上一个属性加入 currentToken 然后继续记录下一个属性
文件名:parser.js
/**
* 解析器
* @filename parser.js
* @author 三钻
* @version v1.0.0
*/
let currentToken = null;
let currentAttribute = null;
/**
* 输出 HTML token
* @param {*} token
*/
function emit(token) {
console.log(token);
}
const EOF = Symbol('EOF'); // EOF: end of file
/**
* HTML 数据开始阅读状态
* --------------------------------
* 1. 如果找到 `<` 就是标签开始状态
* 2. 如果找到 `EOF` 就是HTML文本结束
* 3. 其他字符就继续寻找
* @param {*} char
*
* @return {function}
*/
function data(char) {
if (char === '<') {
// 标签开始
return tagOpen;
} else if (char === EOF) {
// 文本结束
emit({
type: 'EOF',
});
return;
} else {
// 文本
emit({
type: 'text',
content: char,
});
return data;
}
}
/**
* 标签开始状态
* ----------------------------------
* 1. 如果找到 `/` 证明是自关闭标签
* 2. 如果是字母就是标签名
* 3. 其他字符就直接继续寻找
* @param {*} char
*/
function tagOpen(char) {
if (char === '/') {
// 自关闭标签
return endTagOpen;
} else if (char.match(/^[a-zA-Z]$/)) {
// 标签名
currentToken = {
type: 'startTag',
tagName: '',
};
return tagName(char);
} else {
return;
}
}
/**
* 标签结束状态
* --------------------------------
* 1. 如果是字母就是标签名
* 2. 如果直接是 `>` 就报错
* 3. 如果是结束符合,也是报错
* @param {*} char
*/
function endTagOpen(char) {
if (char.match(/^[a-zA-Z]$/)) {
currentToken = {
type: 'endTag',
tagName: '',
};
return tagName(char);
} else if (char === '>') {
// 报错 —— 没有结束标签
} else if (char === EOF) {
// 报错 —— 结束标签不合法
}
}
/**
* 标签名状态
* --------------------------------
* 1. 如果 `\t`(Tab符)、`\n`(空格符)、`\f`(禁止符)或者是空格,这里就是属性的开始
* 2. 如果找到 `/` 就是自关闭标签
* 3. 如果是字母字符那还是标签名
* 4. 如果是 `>` 就是开始标签结束
* 5. 其他就是继续寻找标签名
* @param {*} char
*/
function tagName(char) {
if (char.match(/^[\t\n\f ]$/)) {
return beforeAttributeName;
} else if (char === '/') {
return selfClosingStartTag;
} else if (char.match(/^[a-zA-Z]$/)) {
currentToken.tagName += char;
return tagName;
} else if (char === '>') {
emit(currentToken);
return data;
} else {
return tagName;
}
}
/**
* 标签属性名开始状态
* --------------------------------
* 1. 如果遇到 `/` 就是自封闭标签状态
* 2. 如果遇到字母就是属性名
* 3. 如果遇到 `>` 就是标签结束
* 4. 如果遇到 `=` 下来就是属性值
* 5. 其他情况继续进入属性抓取
* @param {*} char
*/
function beforeAttributeName(char) {
if (char.match(/^[\t\n\f ]$/)) {
return beforeAttributeName;
} else if (char === '/' || char === '>') {
return afterAttributeName(char);
} else if (char === '=' || char === EOF) {
throw new Error('Parse error');
} else {
currentAttribute = {
name: '',
value: '',
};
return attributeName(char);
}
}
/**
* 属性名状态
* @param {*} char
*/
function attributeName(char) {
if (char.match(/^[\t\n\f ]$/) || char === '/' || char === '>' || char === EOF) {
return afterAttributeName(char);
} else if (char === '=') {
return beforeAttributeValue;
} else if (char === '\u0000') {
throw new Error('Parse error');
} else {
currentAttribute.name += char;
return attributeName;
}
}
/**
* 属性值开始状态
* @param {*} char
*/
function beforeAttributeValue(char) {
if (char.match(/^[\t\n\f ]$/) || char === '/' || char === '>' || char === EOF) {
return beforeAttributeValue;
} else if (char === '"') {
return doubleQuotedAttributeValue;
} else if (char === "'") {
return singleQuotedAttributeValue;
} else if (char === '>') {
// return data;
} else {
return unquotedAttributeValue(char);
}
}
/**
* 双引号属性值状态
* @param {*} char
*/
function doubleQuotedAttributeValue(char) {
if (char === '"') {
currentToken[currentAttribute.name] = currentAttribute.value;
return afterQuotedAttributeValue;
} else if (char === '\u0000') {
throw new Error('Parse error');
} else if (char === EOF) {
throw new Error('Parse error');
} else {
currentAttribute.value += char;
return doubleQuotedAttributeValue;
}
}
/**
* 单引号属性值状态
* @param {*} char
*/
function singleQuotedAttributeValue(char) {
if (char === "'") {
currentToken[currentAttribute.name] = currentAttribute.value;
return afterQuotedAttributeValue;
} else if (char === '\u0000') {
throw new Error('Parse error');
} else if (char === EOF) {
throw new Error('Parse error');
} else {
currentAttribute.value += char;
return singleQuotedAttributeValue;
}
}
/**
* 引号结束状态
* @param {*} char
*/
function afterQuotedAttributeValue(char) {
if (char.match(/^[\t\n\f ]$/)) {
return beforeAttributeName;
} else if (char === '/') {
return selfClosingStartTag;
} else if (char === '>') {
currentToken[currentAttribute.name] = currentAttribute.value;
emit(currentToken);
return data;
} else if (char === EOF) {
throw new Error('Parse error: eof-in-tag');
} else {
throw new Error('Parse error: missing-whitespace-between-attributes');
}
}
/**
* 无引号属性值状态
* @param {*} char
*/
function unquotedAttributeValue(char) {
if (char.match(/^[\t\n\f ]$/)) {
currentToken[currentAttribute.name] = currentAttribute.value;
return beforeAttributeName;
} else if (char === '/') {
currentToken[currentAttribute.name] = currentAttribute.value;
return selfClosingStartTag;
} else if (char === '>') {
currentToken[currentAttribute.name] = currentAttribute.value;
emit(currentToken);
return data;
} else if (char === '\u0000') {
throw new Error('Parse error');
} else if (char === '"' || char === "'" || char === '<' || char === '=' || char === '`') {
throw new Error('Parse error');
} else if (char === EOF) {
throw new Error('Parse error');
} else {
currentAttribute.value += char;
return unquotedAttributeValue;
}
}
/**
* 属性名结束状态
* @param {*} char
*/
function afterAttributeName(char) {
if (char.match(/^[\t\n\f ]$/)) {
return afterAttributeName;
} else if (char === '/') {
return selfClosingStartTag;
} else if (char === '=') {
return beforeAttributeValue;
} else if (char === '>') {
currentToken[currentAttribute.name] = currentAttribute.value;
emit(currentToken);
return data;
} else if (char === EOF) {
throw new Error('Parse error');
} else {
currentToken[currentAttribute.name] = currentAttribute.value;
currentAttribute = {
name: '',
value: '',
};
return attributeName(char);
}
}
/**
* 自封闭标签状态
* --------------------------------
* 1. 如果遇到 `>` 就是自封闭标签结束
* 2. 如果遇到 `EOF` 即使报错
* 3. 其他字符也是报错
* @param {*} char
*/
function selfClosingStartTag(char) {
if (char === '>') {
currentToken.isSelfClosing = true;
emit(currentToken);
return data;
} else if (char === 'EOF') {
} else {
}
}
/**
* HTTP 解析
* @param {string} html 文本
*/
module.exports.parseHTML = function (html) {
let state = data;
for (let char of html) {
state = state(char);
}
state = state(EOF);
};
用 token 构建 DOM 树
这里我们开始语法分析,这个与复杂的 JavaScript 的语法相比就非常简单,所以我们只需要用栈基于可以完成分析。但是如果我们要做一个完整的浏览器,只用栈肯定是不行的,因为浏览器是有容错性的,如果我们没有编写结束标签的话,浏览器是会去为我们补错机制的。
那么我做的这个简单的浏览器就不需要对使用者做的那么友好,而只对实现者做的更友好即可。所以我们在实现的过程中就不做那么多特殊情况的处理了。简单用一个栈实现浏览器的 HTML 语法解析,并且构建 一个 DOM 树。
从标签构建 DOM 树的基本技巧是使用栈
遇到开始标签时创建元素并入栈,遇到结束标签时出栈
自封闭节点可视为入栈后立刻出栈
任何元素的父元素是它入栈前的栈顶
文件:parser.js 中的 emit() 函数部分
// 默认给予根节点 document
let stack = [{ type: 'document', children: [] }];
/**
* 输出 HTML token
* @param {*} token
*/
function emit(token) {
if (token.type === 'text') return;
// 记录上一个元素 - 栈顶
let top = stack[stack.length - 1];
// 如果是开始标签
if (token.type == 'startTag') {
let element = {
type: 'element',
children: [],
attributes: [],
};
element.tagName = token.tagName;
for (let prop in token) {
if (prop !== 'type' && prop != 'tagName') {
element.attributes.push({
name: prop,
value: token[prop],
});
}
}
// 对偶操作
top.children.push(element);
element.parent = top;
if (!token.isSelfClosing) stack.push(element);
currentTextNode = null;
} else if (token.type == 'endTag') {
if (top.tagName !== token.tagName) {
throw new Error('Parse error: Tag start end not matched');
} else {
stack.pop();
}
currentTextNode = null;
}
}将文本节点加到 DOM 树
这里是 HTML 解析的最后一步,把文本节点合并后加入 DOM 树里面。
文本节点与自封闭标签处理类似
多个文本节点需要合并
文件:parser.js 中的 emit() 函数部分
let currentToken = null;
let currentAttribute = null;
let currentTextNode = null;
// 默认给予根节点 document
let stack = [{ type: 'document', children: [] }];
/**
* 输出 HTML token
* @param {*} token
*/
function emit(token) {
// 记录上一个元素 - 栈顶
let top = stack[stack.length - 1];
// 如果是开始标签
if (token.type == 'startTag') {
let element = {
type: 'element',
children: [],
attributes: [],
};
element.tagName = token.tagName;
for (let prop in token) {
if (prop !== 'type' && prop != 'tagName') {
element.attributes.push({
name: prop,
value: token[prop],
});
}
}
// 对偶操作
top.children.push(element);
element.parent = top;
if (!token.isSelfClosing) stack.push(element);
currentTextNode = null;
} else if (token.type == 'endTag') {
if (top.tagName !== token.tagName) {
throw new Error('Parse error: Tag start end not matched');
} else {
stack.pop();
}
currentTextNode = null;
} else if (token.type === 'text') {
if (currentTextNode === null) {
currentTextNode = {
type: 'text',
content: '',
};
top.children.push(currentTextNode);
}
currentTextNode.content += token.content;
}
}CSS 计算
完成 HTML 解析并且获得了我们的 DOM 树之后,我们可以通过 CSS 计算来生成带 CSS 的 DOM 树。CSS Computing 表示的就是我们 CSS 规则里面所包含的那些 CSS 属性,应用到匹配这些选择器的元素上。
开始这个代码编写之前,我们先来看看z在整个浏览器工作流程中,我们完成了哪些流程,到达了哪里。
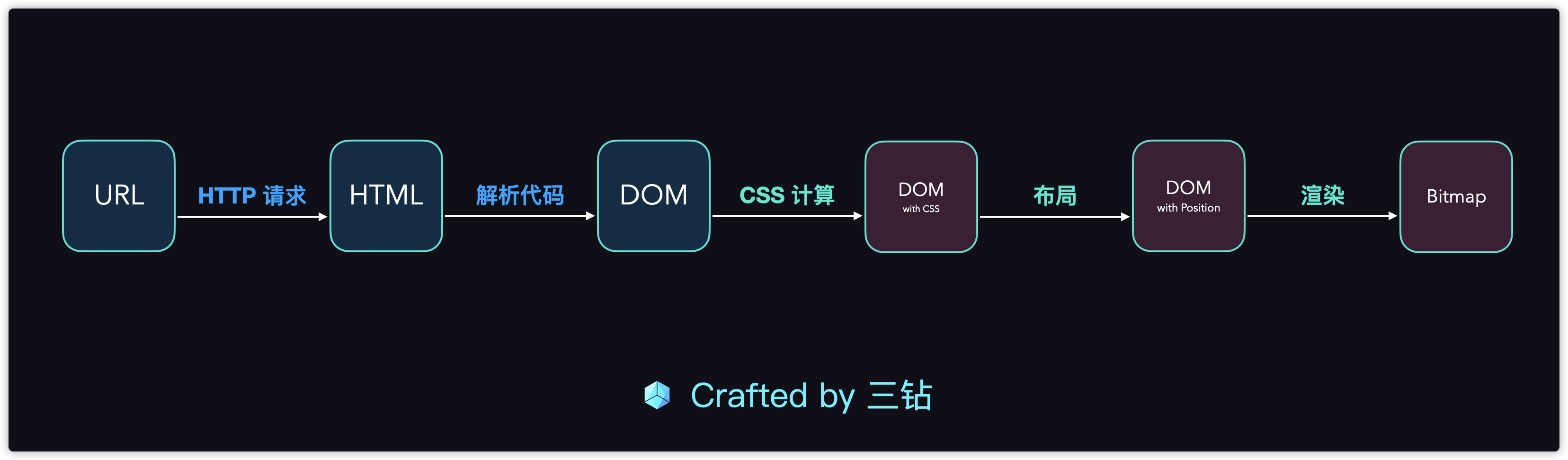
上面的图,我们看到 部分就是已经完成的:
上一篇文章我们完成了 HTTP 请求
然后通过获得的报文,解析出所有 HTTP 信息,里面就包括了 HTML 内容
然后通过 HTTP 内容解析,我们构建了我们的 DOM 树
接下来就是 CSS 计算 (CSS Computing)
目前的 DOM 树只有我们的 HTML 语言里面描述的那些语义信息,我们像完成渲染,我们需要 CSS 信息。 那有的同学就会说我们把所有的样式写到 style 里面可不可以呢?如果我们这样写呢,我们就不需要经历这个 CSS 计算的过程了。但是虽然我们只是做一个虚拟的浏览器,但是还是希望呈现一个比较完成的浏览器流程,所以我们还是会让 DOM 树参与 CSS 计算的过程。
所以这里我们就让 DOM 树挂上 CSS 信息,然后在渲染的过程中能使用。
在编写这个代码之前,我们需要准备一个环境。如果我们需要做 CSS 计算,我们就需要对 CSS 的语法与词法进行分析。然后这个过程如果是手动来实现的话,是需要较多的编译原理基础知识的,但是这些编译基础知识的深度对我们知识想了解浏览器工作原理并不是重点。所以这里我们就偷个懒,直接用 npm 上的一个现成包即可。
其实这个 包,就是一个 CSS parser,可以帮助我们完成 CSS 代码转译成 AST 抽象语法树。 我们所要做的就是根据这棵抽象语法树抽出各种 CSS 规则,并且把他们运用到我们的 HTML 元素上。
那么我们第一步就是先拿到 CSS 的规则,所以叫做 “收集 CSS 规则”
收集 CSS 规则
遇到 style 标签时,我们把 CSS 规则保存起来
文件:parser.js 中的 emit() 函数
+ 我们在 tagName === 'endTag' 的判断中加入了判断当前标签是否 标签
+ 如果是,我们就可以获取 标签里面所有的内容进行 CSS 分析
+ 这里非常简单我们加入一个 的函数即可
+ 而, 就是当前元素, 就是 text 元素,而 就是所有的 CSS 规则文本
+ 这里我们需要注意一个点,我们忽略了在实际情况中还有 标签引入 CSS 文件的情况。但是这个过程涉及到多层异步请求和 HTML 解析的过程,为了简化我们的代码的复杂度,这里就不做这个实现了。当然实际的浏览器是会比我们做的虚拟浏览器复杂的多。
/**
* 输出 HTML token
* @param {*} token
*/
function emit(token) {
// 记录上一个元素 - 栈顶
let top = stack[stack.length - 1];
// 如果是开始标签
if (token.type == 'startTag') {
// ............. 省略了这部分代码 .....................
} else if (token.type == 'endTag') {
// 校验开始标签是否被结束
// 不是:直接抛出错误,是:直接出栈
if (top.tagName !== token.tagName) {
throw new Error('Parse error: Tag start end not matched');
} else {
// 遇到 style 标签时,执行添加 CSS 规则的操作
if (top.tagName === 'style') {
addCSSRule(top.children[0].content);
}
stack.pop();
}
currentTextNode = null;
} else if (token.type === 'text') {
// ............. 省略了这部分代码 .....................
}
}这里我们调用 CSS Parser 来分析 CSS 规则
文件:parser.js 中加入 addCSSRule() 函数
+ 首先我们需要通过 node 引入 包
+ 然后调用 获得 AST 抽象语法树
+ 最后通过使用 的特性展开了 中的所有对象,并且加入到 里面
const css = require('css');
let rules = [];
/**
* 把 CSS 规则暂存到一个数字里
* @param {*} text
*/
function addCSSRule(text) {
var ast = css.parse(text);
console.log(JSON.stringify(ast, null, ' '));
rules.push(...ast.stylesheet.rules);
}这里我们必须要仔细研究此库分析 CSS 规则的格式
最终 AST 输出的结果:
类型是 样式表
然后在 中有 的 CSS 规则数组
数组中就有一个 数组,这里面就是我们 CSS 样式的信息了
拿第一个 delarations 来说明,他的属性为 , 属性值为 ,这些就是我们需要的 CSS 规则了
{
type: "stylesheet",
stylesheet: {
source: undefined,
rules: [
{
type: "rule",
selectors: [
"body div #myId",
],
declarations: [
{
type: "declaration",
property: "width",
value: "100px",
position: {
start: {
line: 3,
column: 9,
},
end: {
line: 3,
column: 21,
},
source: undefined,
},
},
{
type: "declaration",
property: "background-color",
value: "#ff5000",
position: {
start: {
line: 4,
column: 9,
},
end: {
line: 4,
column: 34,
},
source: undefined,
},
},
],
position: {
start: {
line: 2,
column: 7,
},
end: {
line: 5,
column: 8,
},
source: undefined,
},
},
],
parsingErrors: [
],
},
}这里还有一个问题需要我们注意的,像 这种带有空格的标签选择器,是不会逐个给我们单独分析出来的,所以这种我们是需要在后面自己逐个分解分析。除非是 逗号分隔的选择器才会被拆解成多个 。
添加调用
上一步我们收集好了 CSS 规则,这一步我们就是要找一个合适的时机把这些规则应用上。应用的时机肯定是越早越好,CSS 设计里面有一个潜规则,就是 CSS 设计会尽量保证所有的选择器都能够在 进入的时候就能被判断。
当然,我们后面又加了一些高级的选择器之后,这个规则有了一定的松动,但是大部分的规则仍然是去遵循这个规则的,当我们 DOM 树构建到元素的 startTag 的步骤,就已经可以判断出来它能匹配那些 CSS 规则了
当我们创建一个元素后,立即计算CSS
我们假设:理论上,当我们分析一个元素时,所有的 CSS 规则已经被收集完毕
在真实浏览器中,可能遇到写在 body 的 style 标签,需要重新 CSS 计算的情况,这里我们忽略
文件:parser.js 的 emit() 函数加入 computeCSS() 函数调用
/**
* 输出 HTML token
* @param {*} token
*/
function emit(token) {
// 记录上一个元素 - 栈顶
let top = stack[stack.length - 1];
// 如果是开始标签
if (token.type == 'startTag') {
let element = {
type: 'element',
children: [],
attributes: [],
};
element.tagName = token.tagName;
// 叠加标签属性
for (let prop in token) {
if (prop !== 'type' && prop != 'tagName') {
element.attributes.push({
name: prop,
value: token[prop],
});
}
}
// 元素构建好之后直接开始 CSS 计算
computeCSS(element);
// 对偶操作
top.children.push(element);
element.parent = top;
// 自封闭标签之外,其他都入栈
if (!token.isSelfClosing) stack.push(element);
currentTextNode = null;
} else if (token.type == 'endTag') {
// ............. 省略了这部分代码 .....................
} else if (token.type === 'text') {
// ............. 省略了这部分代码 .....................
}
}文件:parser.js 中加入 computeCSS() 函数
/**
* 对元素进行 CSS 计算
* @param {*} element
*/
function computeCSS(element) {
console.log(rules);
console.log('compute CSS for Element', element);
}获取父元素序列
为什么需要获取父元素序列呢?因为我们今天的选择器大多数都是跟元素的父元素相关的。
在 computeCSS 函数中,我们必须知道元素的所有父级元素才能判断元素与规则是否匹配
我们从上一步骤的 stack,可以获取本元素的父元素
因为我们首先获取的是 “当前元素”,所以我们获得和计算父元素匹配的顺序是从内向外
文件:parser.js 中的 computeCSS() 函数
+ 因为栈里面的元素是会不断的变化的,所以后期元素会在栈中发生变化,就会可能被污染。所以这里我们用了一个来复制这个元素。
+ 然后我们用了 把元素的顺序倒过来,为什么我们需要颠倒元素的顺序呢?是因为我们的标签匹配是会从当前元素开始逐级的往外匹配(也就是一级一级往父级元素去匹配的)
/**
* 对元素进行 CSS 计算
* @param {*} element
*/
function computeCSS(element) {
var elements = stack.slice().reverse();
}选择器与元素的匹配
首先我们来了解一下选择器的机构,其实选择器其实是有一个层级结构的:
最外层叫选择器列表,这个我们的 CSS parser 已经帮我们做了拆分
选择器列表里面的,叫做复杂选择器,这个是由空格分隔了我们的复合选择器
复杂选择器是根据亲代关系,去选择元素的
复合选择器,是针对一个元素的本身的属性和特征的判断
而复合原则性选择器,它又是由紧连着的一对选择器而构成的
在我们的模拟浏览器中,我们可以假设一个复杂选择器中只包含简单选择器
我们就把这种情况当成而外有精力的同学自行去实现了哈
思路:
选择器也要从当前元素向外排列
复杂选择器拆成对单个元素的选择器,用循环匹配父级元素队列
/**
* 匹配函数下一节会重点实现
* @param {*} element
* @param {*} selector
*/
function match(element, selector) {}
/**
* 对元素进行 CSS 计算
* @param {*} element
*/
function computeCSS(element) {
var elements = stack.slice().reverse();
if (!elements.computedStyle) element.computedStyle = {};
// 这里循环 CSS 规则,让规则与元素匹配
// 1. 如果当前选择器匹配不中当前元素直接 continue
// 2. 当前元素匹配中了,就一直往外寻找父级元素找到能匹配上选择器的元素
// 3. 最后检验匹配中的元素是否等于选择器的总数,是就是全部匹配了,不是就是不匹配
for (let rule of rules) {
let selectorParts = rule.selectors[0].split(' ').reverse();
if (!match(element, selectorParts[0])) continue;
let matched = false;
let j = 1;
for (let i = 0; i < elements.length; i++) {
if (match(elements[i], selectorParts[j])) j++;
}
if (j >= selectorParts.length) matched = true;
if (matched) console.log('Element', element, 'matched rule', rule);
}
}计算选择器与元素
上一节我们没有完成 匹配函数的实现,那这一部分我们来一起实现元素与选择器的匹配逻辑。
根据选择器的类型和元素属性,计算是否与当前元素匹配
这里仅仅实现了三种基本选择器,实际的浏览器中要处理复合选择器
同学们可以自己尝试一下实现复合选择器,实现支持空格的 Class 选择器
/**
* 匹配元素和选择器
* @param {Object} element 当前元素
* @param {String} selector CSS 选择器
*/
function match(element, selector) {
if (!selector || !element.attributes) return false;
if (selector.charAt(0) === '#') {
let attr = element.attributes.filter(attr => attr.name === 'id')[0];
if (attr && attr.value === selector.replace('#', '')) return true;
} else if (selector.charAt(0) === '.') {
let attr = element.attributes.filter(attr => attr.name === 'class')[0];
if (attr && attr.value === selector.replace('.', '')) return true;
} else {
if (element.tagName === selector) return true;
}
return false;
}生成 computed 属性
这一部分我们生成 computed 属性,这里我们只需要把 里面声明的属性给他加到我们的元素的 上就可以了。
一旦选择器匹配中了,就把选择器中的属性应用到元素上
然后形成 computedStyle
/**
* 对元素进行 CSS 计算
* @param {*} element
*/
function computeCSS(element) {
var elements = stack.slice().reverse();
if (!elements.computedStyle) element.computedStyle = {};
// 这里循环 CSS 规则,让规则与元素匹配
// 1. 如果当前选择器匹配不中当前元素直接 continue
// 2. 当前元素匹配中了,就一直往外寻找父级元素找到能匹配上选择器的元素
// 3. 最后检验匹配中的元素是否等于选择器的总数,是就是全部匹配了,不是就是不匹配
for (let rule of rules) {
let selectorParts = rule.selectors[0].split(' ').reverse();
if (!match(element, selectorParts[0])) continue;
let matched = false;
let j = 1;
for (let i = 0; i < elements.length; i++) {
if (match(elements[i], selectorParts[j])) j++;
}
if (j >= selectorParts.length) matched = true;
if (matched) {
let computedStyle = element.computedStyle;
for (let declaration of rule.declarations) {
if (!computedStyle[declaration.property]) computedStyle[declaration.property] = {};
computedStyle[declaration.property].value = declaration.value;
}
console.log(computedStyle);
}
}
}看完代码的同学,或者自己去实现这个代码时候的同学,应该会发现这个代码中有一个问题。如果我们回去看看我们的 HTML 代码中的 style 样式表,我们发现 HTML 中的 标签会被两个 CSS 选择器匹配中,分别是 和 。这样就会导致前面匹配中后加入 的属性值会被后面匹配中的属性值所覆盖。但是根据 CSS 中的权重规则,ID选择器是高于标签选择器的。这个问题我们下一部分会和同学们一起解决掉哦。
Specificity 的计算逻辑
上一节的代码中,我们只是把匹配中的选择器中的属性直接覆盖上一个,但是其实在 CSS 里面是有一个 的规定。 翻译成中文,很多时候都会被翻译成 ,当然在理论上是对的,但是在英文中呢,优先级是 ,所以 是 。
放在 CSS 中理解就是,ID 选择器中的专指度是会比 CLASS 选择器的高,所以 CSS 中的 ID 的属性会覆盖 CLASS 的属性。
好我们先来理解一下 是什么?
首先 会有四个元素
按照 CSS 中优先级的顺序来说就是 inline style > id > class > tag
所以把这个生成为 就是
数组里面每一个数字都是代表在样式表中出现的次数
下面我们用一些例子来分析一下,我们应该如何用 来分辨优先级的:
A组选择器
A 选择器:
A 的 :[0, 1, 0, 2]
+ id 出现了一次,所以第二位数字是
+ div tag 出现了两次,所以第四位数是
B组选择器
B 选择器:
B 的 :[0, 2, 0, 1]
+ id 出现了两次,所以第二位数字是
+ div tag 出现了一次,所以第四位数是
好,那么我们怎么去比较上面的两种选择器,那个更大呢?
用上面 A 和 B 两种选择器来做对比的话,第一对两个都是 ,所以可以直接跳过。
然后第二位数值对,A选择器是 ,B选择器是 ,很明显 B 要比 A 大,所以 B 选择器中的属性就要覆盖 A 的。
说到这里同学们应该都明白 CSS 中 的规则和对比原理了,下来我们一起来看看如何实现这个代码逻辑。
CSS 规则根据 specificity 和后来优先规则覆盖
specificity 是个四元组,越左边权重越高
一个 CSS 规则的 specificity 根据包含的简单选择器相加而成
文件:parser.js 中添加一个 函数,来计算一个选择器的 specificity
/**
* 计算选择器的 specificity
* @param {*} selector
*/
function specificity(selector) {
let p = [0, 0, 0, 0];
let selectorParts = selector.split(' ');
for (let part of selectorParts) {
if (part.charAt(0) === '#') {
p[1] += 1;
} else if (part.charAt(0) === '.') {
p[2] += 1;
} else {
p[3] += 1;
}
}
return p;
}文件:parser.js 添加一个 函数,来对比两个选择器的 specificity
/**
* 对比两个选择器的 specificity
* @param {*} sp1
* @param {*} sp2
*/
function compare(sp1, sp2) {
for (let i = 0; i <= 3; i++) {
if (i === 3) return sp1[3] - sp2[3];
if (sp1[i] - sp2[i]) return sp1[i] - sp2[i];
}
}文件:parser.js 的 中修改匹配中元素后的属性赋值逻辑
/**
* 对元素进行 CSS 计算
* @param {*} element
*/
function computeCSS(element) {
var elements = stack.slice().reverse();
if (!elements.computedStyle) element.computedStyle = {};
// 这里循环 CSS 规则,让规则与元素匹配
// 1. 如果当前选择器匹配不中当前元素直接 continue
// 2. 当前元素匹配中了,就一直往外寻找父级元素找到能匹配上选择器的元素
// 3. 最后检验匹配中的元素是否等于选择器的总数,是就是全部匹配了,不是就是不匹配
for (let rule of rules) {
let selectorParts = rule.selectors[0].split(' ').reverse();
if (!match(element, selectorParts[0])) continue;
let matched = false;
let j = 1;
for (let i = 0; i < elements.length; i++) {
if (match(elements[i], selectorParts[j])) j++;
}
if (j >= selectorParts.length) matched = true;
if (matched) {
let sp = specificity(rule.selectors[0]);
let computedStyle = element.computedStyle;
for (let declaration of rule.declarations) {
if (!computedStyle[declaration.property]) computedStyle[declaration.property] = {};
if (!computedStyle[declaration.property].specificity) {
computedStyle[declaration.property].value = declaration.value;
computedStyle[declaration.property].specificity = sp;
} else if (compare(computedStyle[declaration.property].specificity, sp) < 0) {
computedStyle[declaration.property].value = declaration.value;
computedStyle[declaration.property].specificity = sp;
}
}
}
}
}最后
我们这里就完成了浏览器工作原理中的 HTML 解析和 CSS 计算。
下一篇文章我们来一起完成排版和渲染两个浏览器过程。敬请期待!
