Seldon 使用 (四):内置的推理服务TFServing
Seldon内置(Prepack)支持了一些推理服务类型,包括Tensorflow serving(简称TFServing),Triton inference server, MLflow, sklearn, xgboost。本文重点介绍Tensorflow serving,由点带面地理解内置(Prepack)推理服务如何使用以及实现细节。
1 TFServing服务简介
TFServing是Tensorflow官方提供的模型在线推理服务,开箱即用,具备高性能,低延迟,灵活易扩展,可同时支持多模型多版本,支持GRPC和HTTP。
TFServing服务架构如下图所示,这里摘抄一段官方的处理流程介绍,一个典型的模型加载及调用过程
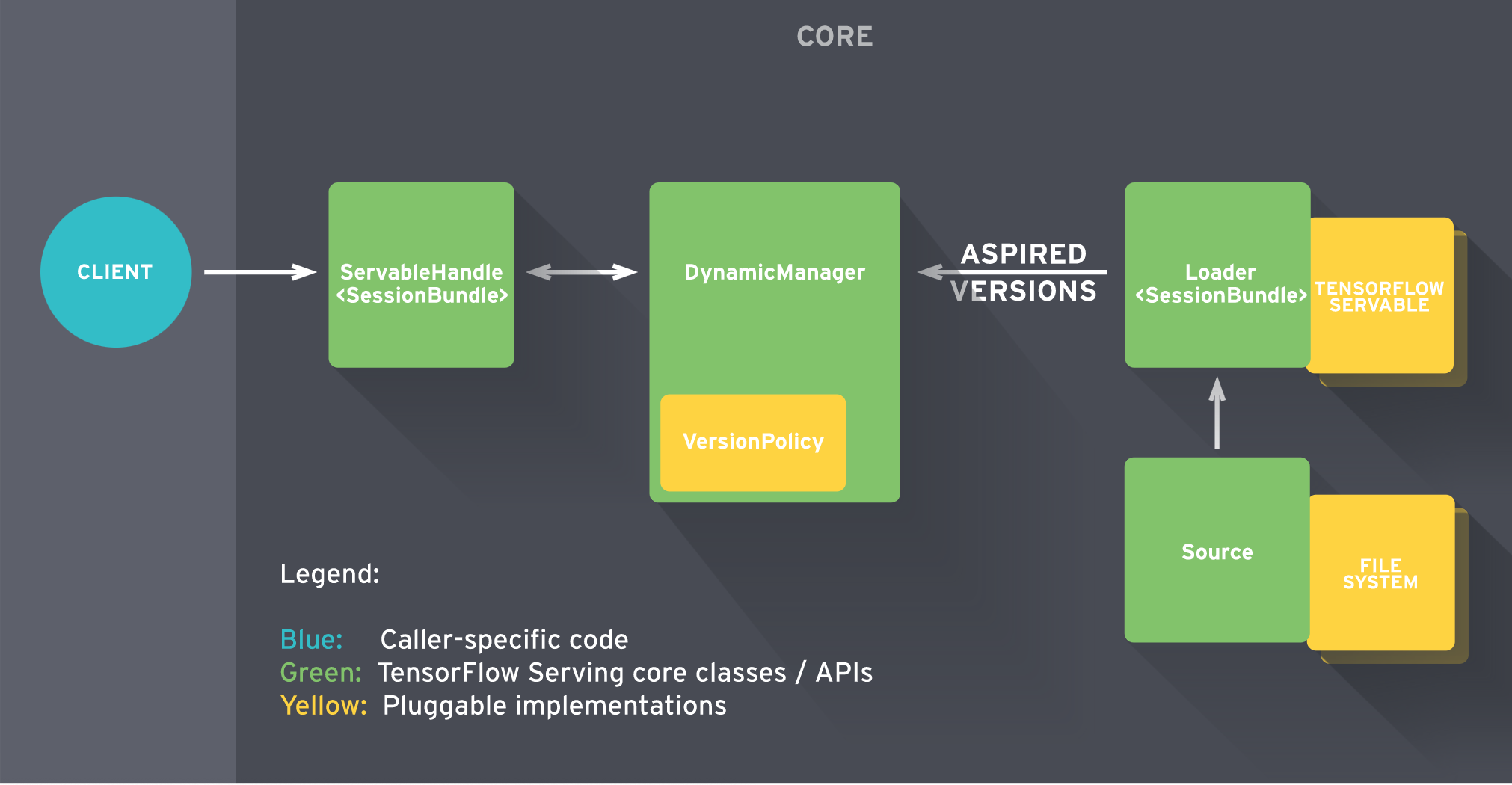
当Source模块检测到新的模型权重(weights),它会创建一个Loader(指向该模型数据)
Source模块通知DynamicManager,告诉它这有一个可用的模型版本(Aspired version)
DynamicManager根据VersionPolicy配置,判断是否加载这个新版本
DynamicManager调用Loader加载并初始化这个新的模型版本
客户端(client)向DynamicManager请求该模型的handle,DynamicManager返回该模型的最新handle
2 如何创建和部署TFServing
定义SeldonDeployment文件tfserving-sdep.yaml,如下:
apiVersion: machinelearning.seldon.io/v1alpha2
kind: SeldonDeployment
metadata:
name: tfserving
spec:
name: mnist
predictors:
- graph:
children: []
implementation: TENSORFLOW_SERVER
modelUri: gs://seldon-models/tfserving/mnist-model
name: mnist-model
parameters:
- name: signature_name
type: STRING
value: predict_images
- name: model_name
type: STRING
value: mnist-model
name: default
replicas: 1说明:
部署该sdep,执行如下命令
kubectl create -f tfserving-sdep.yaml创建完成后,可通过如下命令,查看到pod及service被创建
# kubectl get sdep
NAME AGE
tfserving 1m
# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
tfserving-default-mnist-model ClusterIP 10.254.1.2 9000/TCP 1m
# kubectl get pod
NAME READY STATUS RESTARTS AGE
tfserving-default-0-mnist-model-2e8e-y1ae7 3/3 Running 0 1m
2.1 如何调用推理服务
从上面的service和pod信息,我们可以使用service的cluster IP或者pod的IP,调用这个mnist推理服务。
下面我们通过seldon的API接口,调用推理服务。我们可以构造如下请求:
import json
import random
import sys
import requests
url = "http://%s:9000/api/v1.0/predictions" % sys.argv[1]
data = [
[random.random() for i in range(784)]
]
# seldon protocol
payload = {"data":{"ndarray": data}}
resp = requests.post(url, json=payload)
print(resp.content)返回结果如下:
{
"data":{
"names":["t:0","t:1","t:2","t:3","t:4","t:5","t:6","t:7","t:8","t:9"],
"ndarray":[[2.31042499e-20,4.70782478e-30,0.017343564,0.903749764,1.29772914e-33,0.0789065957,9.34007e-14,4.42152e-19,1.50050141e-07,9.49472516e-17]]
},
"meta":{}
}
3 Seldon如何实现内置推理服务
seldon的manager服务,即seldon-controller-manager,这是一个k8s的Operator服务,负责管理所有SeldonDeployment(简称sdep)资源的生命周期,包括创建,修改及删除。每当新的sdep资源被创建时,manager服务会为其创建相关的deployment及service。
从上面的pod信息,我们可以看到,当sdep资源创建后,manager服务为其创建了一个pod。这个pod包含了四个container,具体如下内容:
containers:
- name: mnist-model
env:
- name: PREDICTIVE_UNIT_PARAMETERS
value: '[{"name":"signature_name","value":"predict_images","type":"STRING"},{"name":"model_name","value":"mnist-model","type":"STRING"},{"name":"rest_endpoint","value":"http://0.0.0.0:2001","type":"STRING"},{"name":"model_name","value":"mnist-model","type":"STRING"}]'
image: seldonio/tfserving-proxy_rest:1.2.1
- name: tfserving
args:
- /usr/bin/tensorflow_model_server
- --port=2000
- --rest_api_port=2001
- --model_name=mnist-model
- --model_base_path=/mnt/models
image: tensorflow-serving:2.1.0
volumeMounts:
- mountPath: /mnt/models
name: tfserving-provision-location
- name: seldon-container-engine
args:
- --sdep
- tfserving
- --namespace
- kubeflow
- --predictor
- default
- --port
- "8000"
- --protocol
- seldon
- --prometheus_path
- /prometheus
image: seldon/seldon-core-executor:1.2.1
initContainers:
- args:
- gs://seldon-models/tfserving/mnist-model
- /mnt/models
image: gcr.io/kfserving/storage-initializer:0.2.2
volumeMounts:
- mountPath: /mnt/models
name: tfserving-provision-location这四个container的作用和关系,分别如下:
init容器:根据sdep的参数modelUri,从gs获取模型文件,并保存到/mnt/models
tfserving容器:从/mnt/models加载模型,并通过2000/2001端口提供服务
mnist-model容器:从其使用的image可知,这是一个proxy服务,主要实现协议转换,即seldon协议请求,转换成tensorflow协议请求
engine容器:主要用于支持sdep资源的graph功能,即可以将多个模型服务分别进行打分及组合。将在后续文章继续展开介绍
最后,再从代码的角度看看,manager服务处理sdep的主要过程。如下所示,如同其他的operator一样,manager实现了Reconcile()接口方法:
func (r *SeldonDeploymentReconciler) Reconcile(req ctrl.Request) (ctrl.Result, error) {
// 获取sdep资源实例的信息
instance := &machinelearningv1.SeldonDeployment{}
err := r.Get(ctx, req.NamespacedName, instance)
// 设置默认值
instance.Default()
// 创建所需组件:主要是container
components, err := r.createComponents(ctx, instance, podSecurityContext, log)
// 创建服务网络:主要是service
servicesReady, err := r.createServices(components, instance, false, log)
// 创建deployment:即将container分配到deployment,并创建
deploymentsReady, err := r.createDeployments(components, instance, log)
if deploymentsReady {
// 完成最后的创建
err := r.completeServiceCreation(instance, components, log)
}
}代码逻辑比较直观,就是分别创建相关的k8s资源。这里主要说一下Default()和createComponents()。在sdep的声明中,我们只需要配置tensorflow模型的名称和文件路径,但manager服务创建了上述四个容器,分别实现了不同的功能:
Default()方法,检查sdep的componentSpecs(该示例未使用)是否有定义mnist-model容器,如果没有则创建一个,使用tfserving-proxy镜像。换句话讲,我们可以在componentSpec中自定义该proxy容器,而不使用默认的
createComponents()方法,调用addTFServerContainer()分别创建tfserving容器和init容器(同样,我们可以在componentSpecs中自定义)。其中,init容器会使用sdep的modelUri参数,用以下载模型文件。最后,调用addEngineToDeployment()创建engine容器。(关于engine容器,将在后续文章介绍)
tfserving容器监听端口2001,proxy容器实现协议转换将请求发送到该端口。上文的调用示例,访问的是proxy服务的端口,使用的是seldon协议。同样,可以直接访问tfserving端口,使用tensorflow协议。如下:
curl -s -X POST http://$endpoint:2001/v1/models/mnist-model:predict \
-H "Content-Type: application/json" \
-d '{"instances": [[0.7663934193992182, 0.0880671623857957, 0.0775122634595451,..., 0.4126315414418871, 0.42650235187504826]], "signature_name": "predict_images"}'
返回结果如下:
{
"predictions": [[1.04614508e-17, 3.39505514e-32, 0.489694506, 0.476404935, 2.44480641e-25, 0.0338525251, 3.64945924e-15, 6.72624967e-15, 4.80203671e-05, 7.55260474e-16]
]
}4 总结
seldon内置的TFServing服务,大大简化了模型推理服务的部署,用户只需要配置模型名称及文件路径即可,而不需要考虑模型文件如何下载,如何做协议转换等服务部署相关问题。通过使用默认配置简化用户输入,同时也提供了可自定义的方式(componentSpecs),以满足特定场景需求,这是很好地设计。