探索压测奥妙
目的
提到压测这两个字的概念,可能很多人,第一脑海里就是找到峰值,做好资源申请以及优化。记得在《成为极少数》的这本书里看过一句这样话,大概是意思是:很多时候,做一件事情,把目标明确了,也许我们就成功了一半,后续就是无限围绕目标做无限的接近和自我约束。如果我们把目标更明确的话,这样就能更好全链路压测以分析到自己的服务。因此笔者认为压测主要目的可以细化到这几个点:
探知系统峰值大小
服务优系统化提供可靠的数据支撑
了解上下游服务的强依赖关系以及其服务承载能力
全链路限流熔断设计
输出服务治理和保障的方案
资源采购以及成本优化
服务监控和告警阈值设计
压测方案
生产环境压测
首先需要明确一点,如果测试环境的节点配置以及数据存储层的配置不一样的话,在测试环境的压测意义并不大,在测试环境的压测除了提供一下服务的代码优化的数据支撑外,其他数据的参考价值并不大。既然要在生产环境压测,我们首先需要考考虑两个点:
压测的时候不会影响到线上服务正常运行
这里笔者在工作中,通常采用用户数据量较少的时候(凌晨),对单台节点进行压测,这样就可以保障最小限度的影响线上用户;当然,如果时间和资源允许的情况下,可以搭建一套副本服务,但是一般由于依赖了其他的服务,尤其是跨部门,推进其他部门一起搭建的一套压测环境的时候,是很难推进的。
压测的数据不影响到线上的数据存储
数据隔离能力是全链路压测的核心基础。由于压测的数据大部分都是伪造的假数据,如果这些数据写入缓存以及数据库,对于线上查询以及缓存命中会产生很大的影响,尤其是对于存储有限的缓存中,压测会导致大量的有效热数据被淘汰,而缓存了一些无效的数据。,针对这样的问题,笔者采取的方案很类似AB测的方案;
在压测的header里面设置染色体:
request.headers.set('flow_type', 'test'); //设置灰度压测参数在cookie中设置压测标示染色体
// 在cookie中种入压测标示
Cookie cookie = new Cookie("flow_type","test");通过在接入层或者服务入口,判断流量的来源,如果是压测流量可以直接写入影子库或影子表,这样就可以做到数据隔离,不影响线上的缓存以及数据库。
需要对日志隔离,如果我们存在对离线数据的分析,可以通过logstash对日志进行分割区分,写入不同的kafka的消息topic以及es集群
具体方案如下:
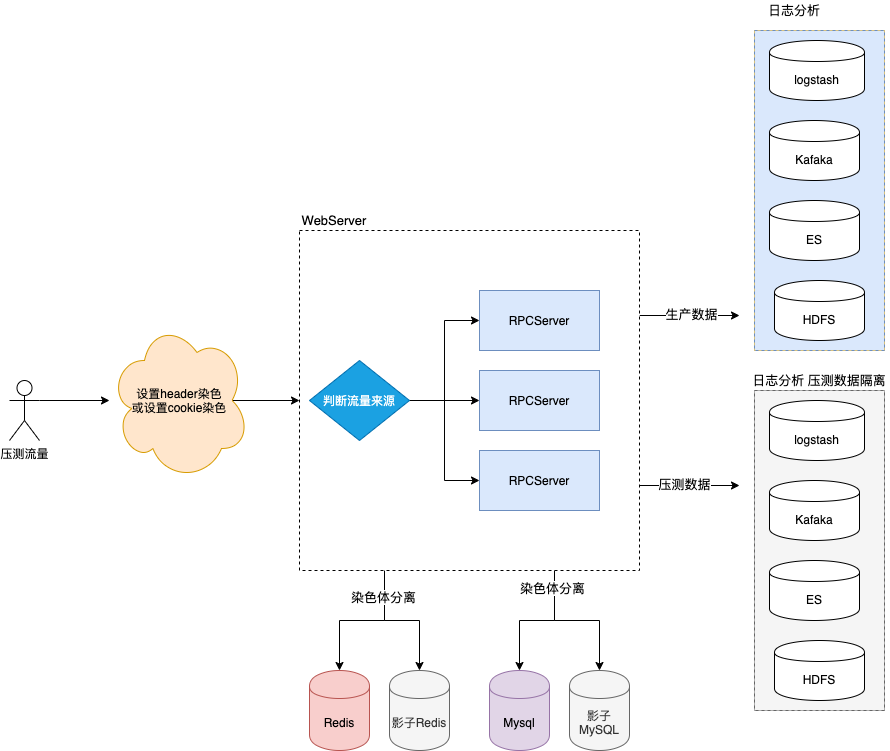
采取上述的方案,我们就可以做到了压测的大量无效数据不对线上的缓存,数据库以及日志造成过多的影响
压测安全保障
由于压测过程中,我们不断在试探服务的水位,如果存存在下游的服务话,我们需要考虑到下游服务的承载能力,这样我们就需要大致了解下游服务的上限以及做好熔断降级。
当达到容量瓶颈或出现预期外情况时,从施压端到被压端都可以自动熔断。以最大程度避免风险隐患,尤其是对下游服务安全,一旦压测打挂下游服务的话,在工作中也许就是事故。对于降级的组件,多数公司都会自己实现一套,如果开源的话:Hystrix和Sentinel。
针对熔断器是否生效,笔者建议在测试环境,先进行验证,确保生产环境限流器有效。
流量存储预估
在压测中,我们需要对服务的最高流量进行预估,方可知道大概需要多少节点资源,这样也尽可能的节约成本,避免盲目的扩容;
请求量级预估
一般我们按照一天流量的峰值一般会50%的流量集中在2小时区间,最高的峰值按5倍冗余,所以我们峰值的每秒请求是:
峰值QPS =(Total*50%)/(60*60*2)*5
事物量级预估
以订单为例,我们按照一般峰值的20%的流量才会进入真正的购买阶段,所以我们可以预估TPS的请求峰值在是:
峰值TPS = 峰值QPS*20%
压测链路
提到链路压测,也许很多人有疑问,压测不是都是从客户端请求到服务的入口这个链路全程链路压测,为什么还要做非全链路压测。
笔者认为一个服务的水位往往取决于你系统服务最短的那块短板。为了更好的找到目前整个系统的服务的瓶颈,我们更需要对于微服务的PRC接口做单链路压测,在单链路压测的提供数据,我们能更好的对当前瓶颈做优化;譬如如果依赖的下游服务存在瓶颈,我们是否可以同步转异步的方式调用,或者如果数据的强一致性不高,可以采用缓存的方式;
压测工具选型
由于笔者本身仅仅接触了2类压力测试工具:
AB
安装
yum -y install httpd-tools常用命令参数解释
-n: 标识请求的总数.
-c: 标识请求的总用户 (如果请求的总数是1000,请求的总用户是10,那么平均每个用户执行100次请求)
-t: 限制请求的超时时间, 单位是秒.
更多命令行可以查看帮助
ab -help
Usage: ab [options] [http[s]://]hostname[:port]/path
Options are:
-n requests Number of requests to perform
-c concurrency Number of multiple requests to make at a time
-t timelimit Seconds to max. to spend on benchmarking
This implies -n 50000
-s timeout Seconds to max. wait for each response
Default is 30 seconds
-b windowsize Size of TCP send/receive buffer, in bytes
-B address Address to bind to when making outgoing connections
-p postfile File containing data to POST. Remember also to set -T
-u putfile File containing data to PUT. Remember also to set -T
-T content-type Content-type header to use for POST/PUT data, eg.
'application/x-www-form-urlencoded'
Default is 'text/plain'
-v verbosity How much troubleshooting info to print
-w Print out results in HTML tables
-i Use HEAD instead of GET
-x attributes String to insert as table attributes
-y attributes String to insert as tr attributes
-z attributes String to insert as td or th attributes
-C attribute Add cookie, eg. 'Apache=1234'. (repeatable)
-H attribute Add Arbitrary header line, eg. 'Accept-Encoding: gzip'
Inserted after all normal header lines. (repeatable)
-A attribute Add Basic WWW Authentication, the attributes
are a colon separated username and password.
-P attribute Add Basic Proxy Authentication, the attributes
are a colon separated username and password.
-X proxy:port Proxyserver and port number to use
-V Print version number and exit
-k Use HTTP KeepAlive feature
-d Do not show percentiles served table.
-S Do not show confidence estimators and warnings.
-q Do not show progress when doing more than 150 requests
-l Accept variable document length (use this for dynamic pages)
-g filename Output collected data to gnuplot format file.
-e filename Output CSV file with percentages served
-r Don't exit on socket receive errors.
-m method Method name
-h Display usage information (this message)
-I Disable TLS Server Name Indication (SNI) extension
-Z ciphersuite Specify SSL/TLS cipher suite (See openssl ciphers)
-f protocol Specify SSL/TLS protocol
(TLS1, TLS1.1, TLS1.2 or ALL)命令事例
ab -n100 -c 10 http://www.baidu.com/压测报告
This is ApacheBench, Version 2.3 <$Revision: 1430300 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking www.baidu.com (be patient).....done
Server Software: BWS/1.1
Server Hostname: www.baidu.com
Server Port: 80
Document Path: /
Document Length: 292117 bytes
Concurrency Level: 1
Time taken for tests: 0.133 seconds
Complete requests: 5
Failed requests: 3
(Connect: 0, Receive: 0, Length: 3, Exceptions: 0)
Write errors: 0
Total transferred: 1466673 bytes
HTML transferred: 1460553 bytes
Requests per second: 37.53 [#/sec] (mean)
Time per request: 26.644 [ms] (mean)
Time per request: 26.644 [ms] (mean, across all concurrent requests)
Transfer rate: 10751.53 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 3 3 0.4 4 4
Processing: 14 23 14.1 18 48
Waiting: 5 13 13.7 7 37
Total: 17 27 14.3 22 52
ERROR: The median and mean for the initial connection time are more than twice the standard
deviation apart. These results are NOT reliable.
Percentage of the requests served within a certain time (ms)
50% 21
66% 23
75% 23
80% 52
90% 52
95% 52
98% 52
99% 52
100% 52 (longest request)下面对常用的重要指标做一些解释
##并发请求数
Concurrency Level: 1
##整个测试持续的时间
Time taken for tests: 0.133 seconds
##完成的请求数
Complete requests: 5
##失败的请求数
Failed requests: 0
##整个场景中的网络传输量
Total transferred: 1466673 bytes
##整个场景中的HTML内容传输量
HTML transferred: 1460553 bytes
##吞吐率,大家最关心的指标之一,相当于 LR 中的每秒事务数,后面括号中的 mean 表示这是一个平均值
Requests per second: 37.53 [#/sec] (mean)
##用户平均请求等待时间,大家最关心的指标之二,相当于 LR 中的平均事务响应时间,后面括号中的 mean 表示这是一个平均值
Time per request: 26.644 [ms] (mean)
##服务器平均请求处理时间,大家最关心的指标之三
Time per request: 26.644 [ms] (mean, across all concurrent requests)
##平均每秒网络上的流量,可以帮助排除是否存在网络流量过大导致响应时间延长的问题
Transfer rate: 10751.53 [Kbytes/sec] received
##服务处理请求的SLA
Percentage of the requests served within a certain time (ms)
## 这里我们一般关注 TP99和TP90即可
99% 52 ##99%的请求在52ms处理完成
90% 52 ##90%的请求在52ms处理完成总结
总体来看ab压测工具基本能满足所以的http请求的压测数据,另外使用起来比较简单。当然ab存在的问题就是功能相对较少,具体会在下面于wrk对比后表哥罗列。
wrk
安装
git clone https://github.com/wg/wrk.git wrk
cd wrk
#本身是c写的,所以需要本地编译
make
# 把生成的wrk移到一个PATH目录下面, 比如
sudo cp wrk /usr/local/bin常用参数说明
-c:总的连接数(每个线程处理的连接数=总连接数/线程数)
-d:测试的持续时间,如2s(2second),2m(2minute),2h(hour),默认为s
-t:需要执行的线程总数,默认为2,一般线程数不宜过多. 核数的2到4倍足够了. 多了反而因为线程切换过多造成效率降低
-s:执行Lua脚本,这里写lua脚本的路径和名称,后面会给出案例
-H:需要添加的头信息,注意header的语法,举例,-H “token: abcdef”
这里很重要!这里就可以直接在header里面加染色体!!!!
—timeout:超时的时间
—latency:显示延迟统计信息命令事例
./wrk -t5 -c100 -d30s --latency http://www.baidu.com压测报告
Running 30s test @ http://www.baidu.com
5 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 599.14ms 236.89ms 1.97s 73.37%
Req/Sec 34.18 19.57 120.00 69.15%
Latency Distribution
50% 548.32ms
75% 715.09ms
90% 920.64ms
99% 1.33s
4607 requests in 30.10s, 1.26GB read
Socket errors: connect 0, read 0, write 0, timeout 101
Requests/sec: 153.07
Transfer/sec: 43.04MB重要指标分析
平均值 标准差 最大值 正负一个标准差占比
线程状态 Thread Stats Avg Stdev Max +/- Stdev
响应时间 Latency 168.45ms 265.72ms 1.48s 87.68%
每线程每秒完成请求数Req/Sec 25.78 26.22 120.00 86.55%
#SLA参数 TP99和TP90
Latency Distribution
90% 920.64ms
99% 1.33s
Requests/sec: 153.07 ##每秒请求数
Transfer/sec: 43.04MB ## 每秒传输数据
整体上看wrk的结果相比ab内容更清晰简单
wrk.method = "POST"
wrk.body = "test wrk post"
wrk.headers["Content-Type"] = "application/x-www-form-urlencoded"运行测试用例
./wrk -t5 -c5 -d5s --latency http://www.baidu.com -s test_post.luaab vs wrk
简单对比两者,发现其实基本的核心指标数据都能输出,但是因为wrk可以借助luna的脚本,可以更灵活的控制每次请求的参数,尤其对于缓存命中之类的压力测试的时候,就更新灵活使用。这里还有一个很重要的区别就是ab是单线程的模式。
压测过程中,如果我们会发现两种工具中:cpu的利用率wrk明显比ab要多,对比如下:
压测策略
寻找最大线程数:
固定连接数,持续时间,调高线程数;:以wrk为例,即固定-c 提高 -t
当线程数增加QPS不再明显变化,且平均响应时间变高时,即为最佳线程数;
寻找QPS峰值:
固定线程数为最大线程数,固定持续时间,调整连接数:即固定-t 提高 -c
当连接数增加QPS不再明显变化,且平均响应时间变高时,这个时候即使再加线程数,也不会有多大的提升效果,最多就是增加了线程的上下文切换,即为QPS峰值;
总结展望
除此之外,在大多数时候如果要在压测过程中完全模拟真实业务场景,还需要做大量的功能调研与用户使用调研,尽可能实现场景的真实覆盖,只有越接近真实,才能尽早挖掘出系统的瓶颈和准确评估系统的性能指标。