深入理解掌握零拷贝技术
前言
零拷贝技术是指计算机执行操作时,CPU不需要先将数据从某处内存复制到另一个特定区域。这种技术通常用于通过网络传输文件时节省CPU周期和内存带宽。
原始的网络请求,需要数次在用户态和内核态之间切换以及数据的拷贝,这无疑大大影响了处理的效率,零拷贝技术就是为解决这一问题而诞生的。
我们常见的高性能组件(Netty、Kafka等),其内部基本都应用了零拷贝,在学习这些组件之前,有必要先了解什么是零拷贝。
推荐视频:
传统文件传输 read + write

DMA拷贝:指外部设备不通过CPU而直接与系统内存交换数据的接口技术
如上图所示,传统的网络传输,需要进行4次用户态和内核态切换,4次数据拷贝(2次CPU拷贝,2次DMA拷贝)
上下文的切换涉及到操作系统,相对CPU速度是非常耗时的,而且仅仅一次文件传输,竟然需要4次数据拷贝,造成CPU资源极大的浪费
不难看出,传统网络传输涉及很多冗余且无意义的操作,导致应用在高并发情况下,性能指数级下降,表现异常糟糕
为了解决这一问题,零拷贝技术诞生了,他其实是一个抽象的概念,但其本质就是通过减少上下文切换和数据拷贝次数来实现的
mmap + write
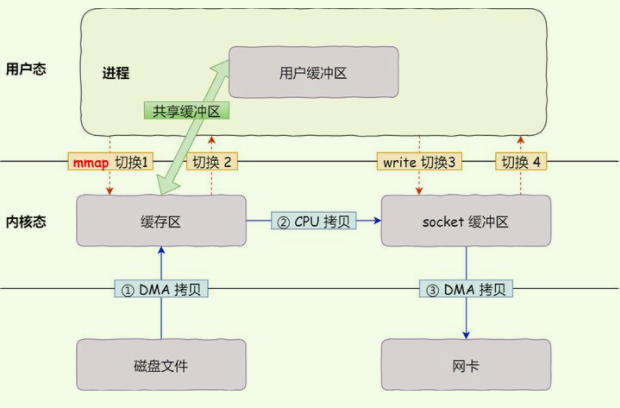
如上图所示,mmap技术传输文件,需要进行4次用户态和内核态切换,3次数据拷贝(1次CPU拷贝、两次DMA拷贝)
相对于传统数据传输,mmap减少了一次CPU拷贝,其具体过程如下:
显然仅仅减少一次数据拷贝,依然难以满足要求
sendfile

如上图所属,sendfile技术传输文件,需要进行2次用户态和内核态的切换,3次数据拷贝(1次CPU拷贝、两次DMA拷贝)
相对于mmap,其又减少了两次上下文的切换,具体过程如下:
sendfile其实是将原来的两步读写操作进行了合并,从而减少了2次上下文的切换,但其仍然不是真正意义上的“零”拷贝
文章福利:现在C++程序员面临的竞争压力越来越大。那么,作为一名C++程序员,怎样努力才能快速成长为一名高级的程序员或者架构师,或者说一名优秀的高级工程师或架构师应该有怎样的技术知识体系,这不仅是一个刚刚踏入职场的初级程序员,也是工作三五年之后开始迷茫的老程序员,都必须要面对和想明白的问题。为了帮助大家少走弯路,技术要做到知其然还要知其所以然。以下视频获取点击:
如果想学习C++工程化、高性能及分布式、深入浅出。性能调优、TCP,协程,Nginx源码分析Nginx,ZeroMQ,MySQL,Redis,MongoDB,ZK,Linux内核,P2P,K8S,Docker,TCP/IP,协程,DPDK的朋友可以看一下这个学习地址:
sendfile + SG-DMA

从 Linux 内核 2.4 版本开始起,对于支持网卡支持 SG-DMA 技术的情况下, sendfile() 系统调用的过程发生了点变化,如上图所示,sendfile + SG-DMA技术传输文件,需要进行2次用户态和内核态的切换,2次数据拷贝(1次DMA拷贝,1次SG-DMA拷贝)
具体过程如下:
此种方式对比之前的,真正意义上去除了CPU拷贝,CPU 的高速缓存再不会被污染了,CPU 可以去执行其他的业务计算任务,同时和 DMA 的 I/O 任务并行,极大地提升系统性能。
但他的劣势也很明显,强依赖于硬件的支持
splice
Linux 在 2.6.17 版本引入 splice 系统调用,不再需要硬件支持,同时还实现了两个文件描述符之间的数据零拷贝。
splice 系统调用可以在内核空间的读缓冲区(read buffer)和网络缓冲区(socket buffer)之间建立管道(pipeline),从而避免了用户缓冲区和Socket缓冲区的 CPU 拷贝操作。
基于 splice 系统调用的零拷贝方式,整个拷贝过程会发生 2次用户态和内核态的切换,2次数据拷贝(2次DMA拷贝),具体过程如下:
splice 拷贝方式也同样存在用户程序不能对数据进行修改的问题。除此之外,它使用了 Linux 的管道缓冲机制,可以用于任意两个文件描述符中传输数据,但是它的两个文件描述符参数中有一个必须是管道设备
总结
本文简单介绍了 Linux 中的几种 Zero-copy 技术,随着技术的不断发展,又出现了诸如:写时复制、共享缓冲等技术,本文就不再赘述。
广义的来讲,Linux 的 Zero-copy 技术可以归纳成以下三大类:
减少甚至避免用户空间和内核空间之间的数据拷贝:在一些场景下,用户进程在数据传输过程中并不需要对数据进行访问和处理,那么数据在 Linux 的 Page Cache 和用户进程的缓冲区之间的传输就完全可以避免,让数据拷贝完全在内核里进行,甚至可以通过更巧妙的方式避免在内核里的数据拷贝。这一类实现一般是是通过增加新的系统调用来完成的,比如 Linux 中的 mmap(),sendfile() 以及 splice() 等。
绕过内核的直接 I/O:允许在用户态进程绕过内核直接和硬件进行数据传输,内核在传输过程中只负责一些管理和辅助的工作。这种方式其实和第一种有点类似,也是试图避免用户空间和内核空间之间的数据传输,只是第一种方式是把数据传输过程放在内核态完成,而这种方式则是直接绕过内核和硬件通信,效果类似但原理完全不同。
内核缓冲区和用户缓冲区之间的传输优化:这种方式侧重于在用户进程的缓冲区和操作系统的页缓存之间的 CPU 拷贝的优化。这种方法延续了以往那种传统的通信方式,但更灵活。