【AI全栈二】视频流多目标多类别无延迟高精度高召回目标追踪
YOLO+Deepsort 全解

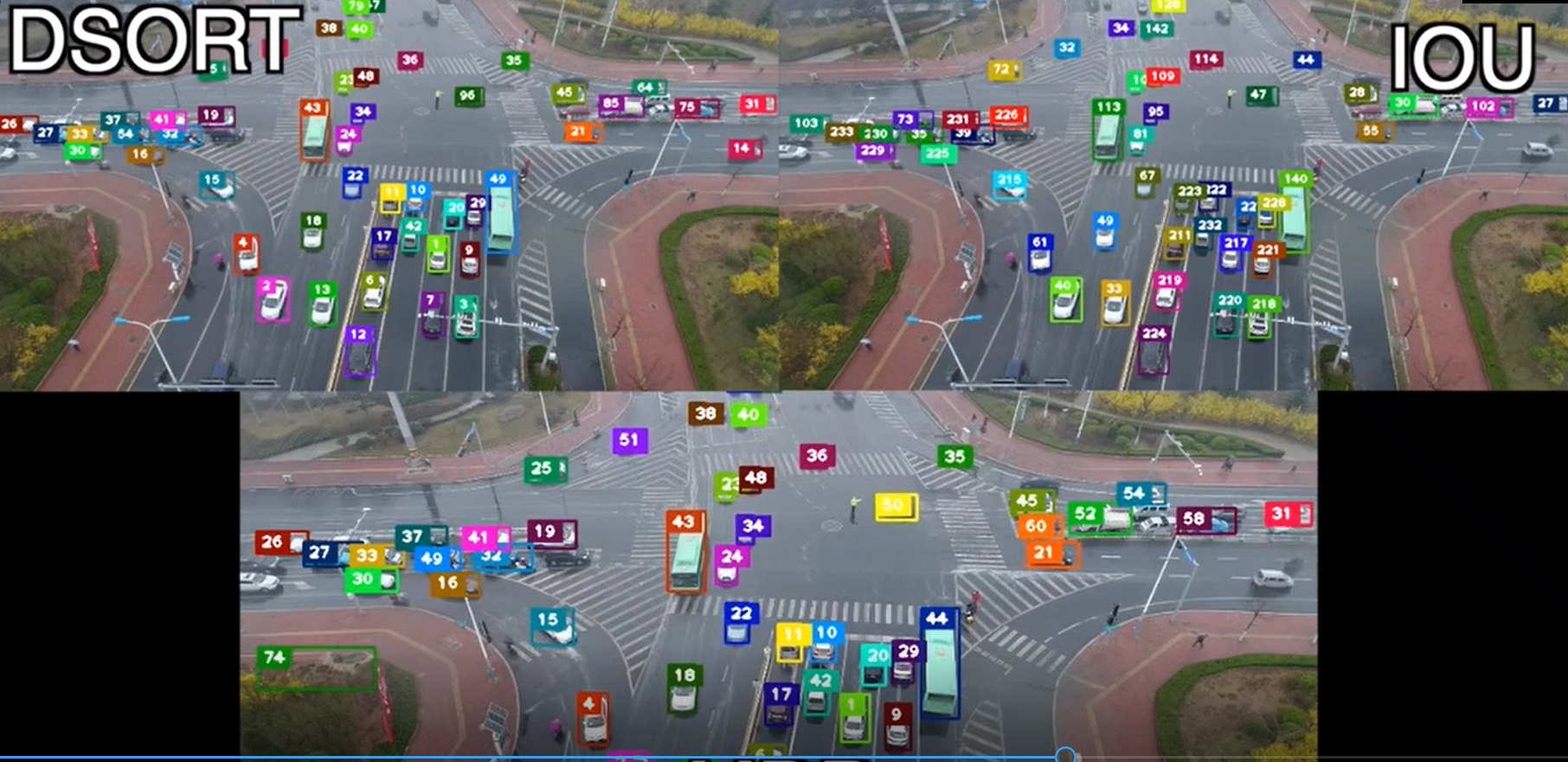
首先介绍跟踪:
目标跟踪分为单目标跟踪和多目标跟踪
单目标跟踪在视频的初始帧中对单个目标进行帧处理,并在后续帧中预测目标的大小和位置。典型的算法有mean-shift(Kalman滤波、状态预测粒子滤波)、TLD(基于在线学习的跟踪)、KCF(相关滤波)等。
像opencv这样的库有许多内置的跟踪算法。KCF是一种非常经典的单目标跟踪算法。它的速度不是很快,但是精度很好,但是它也有一些优点
多目标跟踪不像单目标跟踪那样在初始帧中对单个目标进行帧间跟踪,而是跟踪多个目标的大小和位置,并且每一帧中目标的数目和位置都可能发生变化。另外,在多目标跟踪中还存在以下问题
处理新目标的出现和旧目标的消失;
跟踪目标的运动预测和相似性判别,即前一帧与下一帧的匹配;
对跟踪对象之间的重叠和遮挡进行处理;
对丢失一段时间后再次出现的跟踪目标进行再识别。
这种情况有什么解决办法?下面是一个全面的描述。
浅析SORT

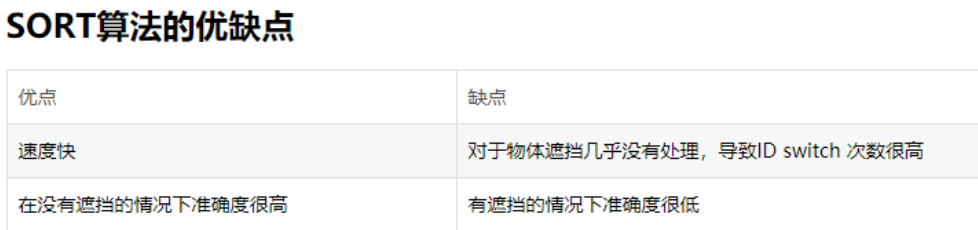
SORT 部分原理:
在跟踪前,对所有目标进行了检测,实现了特征建模过程。1当第一帧进入时,一个新的跟踪器被初始化并用检测到的目标创建,ID被标记。当进入下一帧时,通过卡尔曼滤波得到前一帧框产生的状态预测和协方差预测。找到所有目标状态预测的IOU和该帧中检测到的框,通过匈牙利赋值算法得到IOU的最大唯一匹配(数据关联部分),然后去除小于IOU\阈值的匹配值。3.在该帧中,用匹配的目标检测盒更新Kalman跟踪器。计算卡尔曼增益、状态更新和协方差更新,并输出状态更新值作为该帧的跟踪盒。重新初始化此帧中不匹配的目标的跟踪器。 其中,Kalman跟踪器结合历史跟踪记录,调整历史框和当前帧框之间的残差,以更好地匹配跟踪ID。 有三种主要贡献 利用强大的CNN检测器的检测结果进行多目标跟踪 跟踪方法基于卡尔曼滤波和匈牙利算法 开源代码为mot提供了一个新的基线 Sort将两阶段匹配算法改进为一阶段匹配算法,可以在线跟踪。 具体来说,sort引入了线速度模型和Kalman滤波来预测目标的位置,并利用运动模型来预测目标的位置,而没有合适的匹配检测帧。
SORT 代码实现+解读:
from __future__ import print_function
from numba import jit #是python的一个JIT库,通过装饰器来实现运行时的加速
import os.path
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as patches #用于绘制常见图像(如矩形,椭圆,圆形,多边形)
from skimage import io
from sklearn.utils.linear_assignment_ import linear_assignment
import glob
import time
import argparse
from filterpy.kalman import KalmanFilter #filterpy包含了一些常用滤波器的库
@jit #用了jit装饰器,可加速for循环的计算
def iou(bb_test,bb_gt):
"""
Computes IOU between two bboxes in the form [x1,y1,x2,y2]
"""
xx1 = np.maximum(bb_test[0], bb_gt[0])
yy1 = np.maximum(bb_test[1], bb_gt[1])
xx2 = np.minimum(bb_test[2], bb_gt[2])
yy2 = np.minimum(bb_test[3], bb_gt[3])
w = np.maximum(0., xx2 - xx1)
h = np.maximum(0., yy2 - yy1)
wh = w * h
o = wh / ((bb_test[2]-bb_test[0])*(bb_test[3]-bb_test[1]) #IOU=(bb_test和bb_gt框相交部分面积)/(bb_test框面积+bb_gt框面积 - 两者相交面积)
+ (bb_gt[2]-bb_gt[0])*(bb_gt[3]-bb_gt[1]) - wh)
return(o)
def convert_bbox_to_z(bbox): #将bbox由[x1,y1,x2,y2]形式转为 [框中心点x,框中心点y,框面积s,宽高比例r]^T
"""
Takes a bounding box in the form [x1,y1,x2,y2] and returns z in the form
[x,y,s,r] where x,y is the centre of the box and s is the scale/area and r is
the aspect ratio
"""
w = bbox[2]-bbox[0]
h = bbox[3]-bbox[1]
x = bbox[0]+w/2.
y = bbox[1]+h/2.
s = w*h #scale is just area
r = w/float(h)
return np.array([x,y,s,r]).reshape((4,1)) #将数组转为4行一列形式,即[x,y,s,r]^T
def convert_x_to_bbox(x,score=None): #将[x,y,s,r]形式的bbox,转为[x1,y1,x2,y2]形式
"""
Takes a bounding box in the centre form [x,y,s,r] and returns it in the form
[x1,y1,x2,y2] where x1,y1 is the top left and x2,y2 is the bottom right
"""
w = np.sqrt(x[2]*x[3]) #w=sqrt(w*h * w/h)
h = x[2]/w #h=w*h/w
if(score==None): #如果检测框不带置信度
return np.array([x[0]-w/2.,x[1]-h/2.,x[0]+w/2.,x[1]+h/2.]).reshape((1,4)) #返回[x1,y1,x2,y2]
else: #如果加测框带置信度
return np.array([x[0]-w/2.,x[1]-h/2.,x[0]+w/2.,x[1]+h/2.,score]).reshape((1,5)) #返回[x1,y1,x2,y2,score]
class KalmanBoxTracker(object):
"""
This class represents the internel state of individual tracked objects observed as bbox.
"""
count = 0
def __init__(self,bbox):
"""
Initialises a tracker using initial bounding box. 使用初始边界框初始化跟踪器
"""
#define constant velocity model #定义匀速模型
self.kf = KalmanFilter(dim_x=7, dim_z=4) #状态变量是7维, 观测值是4维的,按照需要的维度构建目标
self.kf.F = np.array([[1,0,0,0,1,0,0],[0,1,0,0,0,1,0],[0,0,1,0,0,0,1],[0,0,0,1,0,0,0],[0,0,0,0,1,0,0],[0,0,0,0,0,1,0],[0,0,0,0,0,0,1]])
self.kf.H = np.array([[1,0,0,0,0,0,0],[0,1,0,0,0,0,0],[0,0,1,0,0,0,0],[0,0,0,1,0,0,0]])
self.kf.R[2:,2:] *= 10.
self.kf.P[4:,4:] *= 1000. #give high uncertainty to the unobservable initial velocities 对未观测到的初始速度给出高的不确定性
self.kf.P *= 10. # 默认定义的协方差矩阵是np.eye(dim_x),将P中的数值与10, 1000相乘,赋值不确定性
self.kf.Q[-1,-1] *= 0.01
self.kf.Q[4:,4:] *= 0.01
self.kf.x[:4] = convert_bbox_to_z(bbox) #将bbox转为 [x,y,s,r]^T形式,赋给状态变量X的前4位
self.time_since_update = 0
self.id = KalmanBoxTracker.count
KalmanBoxTracker.count += 1
self.history = []
self.hits = 0
self.hit_streak = 0
self.age = 0
def update(self,bbox):
"""
Updates the state vector with observed bbox.
"""
self.time_since_update = 0
self.history = []
self.hits += 1
self.hit_streak += 1
self.kf.update(convert_bbox_to_z(bbox))
def predict(self):
"""
Advances the state vector and returns the predicted bounding box estimate.
"""
if((self.kf.x[6]+self.kf.x[2])<=0):
self.kf.x[6] *= 0.0
self.kf.predict()
self.age += 1
if(self.time_since_update>0):
self.hit_streak = 0
self.time_since_update += 1
self.history.append(convert_x_to_bbox(self.kf.x))
return self.history[-1]
def get_state(self):
"""
Returns the current bounding box estimate.
"""
return convert_x_to_bbox(self.kf.x)
def associate_detections_to_trackers(detections,trackers,iou_threshold = 0.3): #用于将检测与跟踪进行关联
"""
Assigns detections to tracked object (both represented as bounding boxes)
Returns 3 lists of matches, unmatched_detections and unmatched_trackers
"""
if(len(trackers)==0): #如果跟踪器为空
return np.empty((0,2),dtype=int), np.arange(len(detections)), np.empty((0,5),dtype=int)
iou_matrix = np.zeros((len(detections),len(trackers)),dtype=np.float32) # 检测器与跟踪器IOU矩阵
for d,det in enumerate(detections):
for t,trk in enumerate(trackers):
iou_matrix[d,t] = iou(det,trk) #计算检测器与跟踪器的IOU并赋值给IOU矩阵对应位置
matched_indices = linear_assignment(-iou_matrix) # 参考:https://blog.csdn.net/herr_kun/article/details/86509591 加上负号是因为linear_assignment求的是最小代价组合,而我们需要的是IOU最大的组合方式,所以取负号
unmatched_detections = [] #未匹配上的检测器
for d,det in enumerate(detections):
if(d not in matched_indices[:,0]): #如果检测器中第d个检测结果不在匹配结果索引中,则d未匹配上
unmatched_detections.append(d)
unmatched_trackers = [] #未匹配上的跟踪器
for t,trk in enumerate(trackers):
if(t not in matched_indices[:,1]): #如果跟踪器中第t个跟踪结果不在匹配结果索引中,则t未匹配上
unmatched_trackers.append(t)
#filter out matched with low IOU 过滤掉那些IOU较小的匹配对
matches = [] #存放过滤后的匹配结果
for m in matched_indices: #遍历粗匹配结果
if(iou_matrix[m[0],m[1]]= self.min_hits or self.frame_count <= self.min_hits)):
ret.append(np.concatenate((d,[trk.id+1])).reshape(1,-1)) # +1 as MOT benchmark requires positive
i -= 1
#remove dead tracklet
if(trk.time_since_update > self.max_age):
self.trackers.pop(i)
if(len(ret)>0):
return np.concatenate(ret)
return np.empty((0,5))
def parse_args():
"""Parse input arguments."""
parser = argparse.ArgumentParser(description='SORT demo')
parser.add_argument('--display', dest='display', help='Display online tracker output (slow) [False]',action='store_true')
args = parser.parse_args()
return args
if __name__ == '__main__':
# all train
sequences = ['PETS09-S2L1','TUD-Campus','TUD-Stadtmitte','ETH-Bahnhof','ETH-Sunnyday','ETH-Pedcross2','KITTI-13','KITTI-17','ADL-Rundle-6','ADL-Rundle-8','Venice-2']
args = parse_args()
display = args.display
phase = 'train'
total_time = 0.0
total_frames = 0
colours = np.random.rand(32,3) #used only for display
if(display):
if not os.path.exists('mot_benchmark'):
print('\n\tERROR: mot_benchmark link not found!\n\n Create a symbolic link to the MOT benchmark\n (https://motchallenge.net/data/2D_MOT_2015/#download). E.g.:\n\n $ ln -s /path/to/MOT2015_challenge/2DMOT2015 mot_benchmark\n\n')
exit()
plt.ion() #用于动态绘制显示图像
fig = plt.figure()
if not os.path.exists('output'):
os.makedirs('output')
for seq in sequences:
mot_tracker = Sort() #create instance of the SORT tracker 创建Sort 跟踪实例
seq_dets = np.loadtxt('data/%s/det.txt'%(seq),delimiter=',') #load detections #加载检测结果
with open('output/%s.txt'%(seq),'w') as out_file:
print("Processing %s."%(seq))
for frame in range(int(seq_dets[:,0].max())): #确定视频序列总帧数,并进行for循环
frame += 1 #detection and frame numbers begin at 1 #由于视频序列帧数是从1开始的,因此加1
dets = seq_dets[seq_dets[:,0]==frame,2:7] #提取检测结果中的[x1,y1,w,h,score]到dets
dets[:,2:4] += dets[:,0:2] #convert to [x1,y1,w,h] to [x1,y1,x2,y2] 将dets中的第2,3列的数加上第0,1列的数后赋值给2,3列;
total_frames += 1 #总帧数累计
if(display): #如果要求显示结果
ax1 = fig.add_subplot(111, aspect='equal')
fn = 'mot_benchmark/%s/%s/img1/%06d.jpg'%(phase,seq,frame) #原图像路径名
im =io.imread(fn) #加载图像
ax1.imshow(im) #显示图像
plt.title(seq+' Tracked Targets')
start_time = time.time()
trackers = mot_tracker.update(dets) #sort跟踪器更新
cycle_time = time.time() - start_time #sort跟踪器耗时
total_time += cycle_time #sort跟踪器总共耗费时间
for d in trackers:
print('%d,%d,%.2f,%.2f,%.2f,%.2f,1,-1,-1,-1'%(frame,d[4],d[0],d[1],d[2]-d[0],d[3]-d[1]),file=out_file) #打印: frame,ID,x1,y1,x2,y2,1,-1,-1,-1
if(display): #如果显示,将目标检测框画上
d = d.astype(np.int32)
ax1.add_patch(patches.Rectangle((d[0],d[1]),d[2]-d[0],d[3]-d[1],fill=False,lw=3,ec=colours[d[4]%32,:]))
ax1.set_adjustable('box-forced')
if(display):
fig.canvas.flush_events()
plt.draw()
ax1.cla()
print("Total Tracking took: %.3f for %d frames or %.1f FPS"%(total_time,total_frames,total_frames/total_time))
if(display):
print("Note: to get real runtime results run without the option: --display")
DeepSORT 深入解读


一年后,原来的团队发布了一个扩展的Deepsport,现在有很多人使用这个跟踪器 一般的框架没有改变,也没有扩展卡尔曼滤波的思想,加上匈牙利算法,深度关联挖掘是一个网络行人识别的研究领域。在行人目标分割中,不同区域的行人感知特征与以图像为输出方向的行人识别网络相似,通过比较距离向量在两个矢量之间,判断两个输入图像是否相同的行人。 此外,视觉信息还增加了长期覆盖目标的跟踪。 基于卡尔曼滤波的预测结果,匈牙利算法用于目标识别,但在这个过程中,增加了运动信息和外观信息。这是一个简单的,实现的比较复杂,有兴趣的读者可以在这里多说 在其它方面没有太多的变化,也没有使用标准卡尔曼滤波 最后,它可以实现更好的跟踪效果。
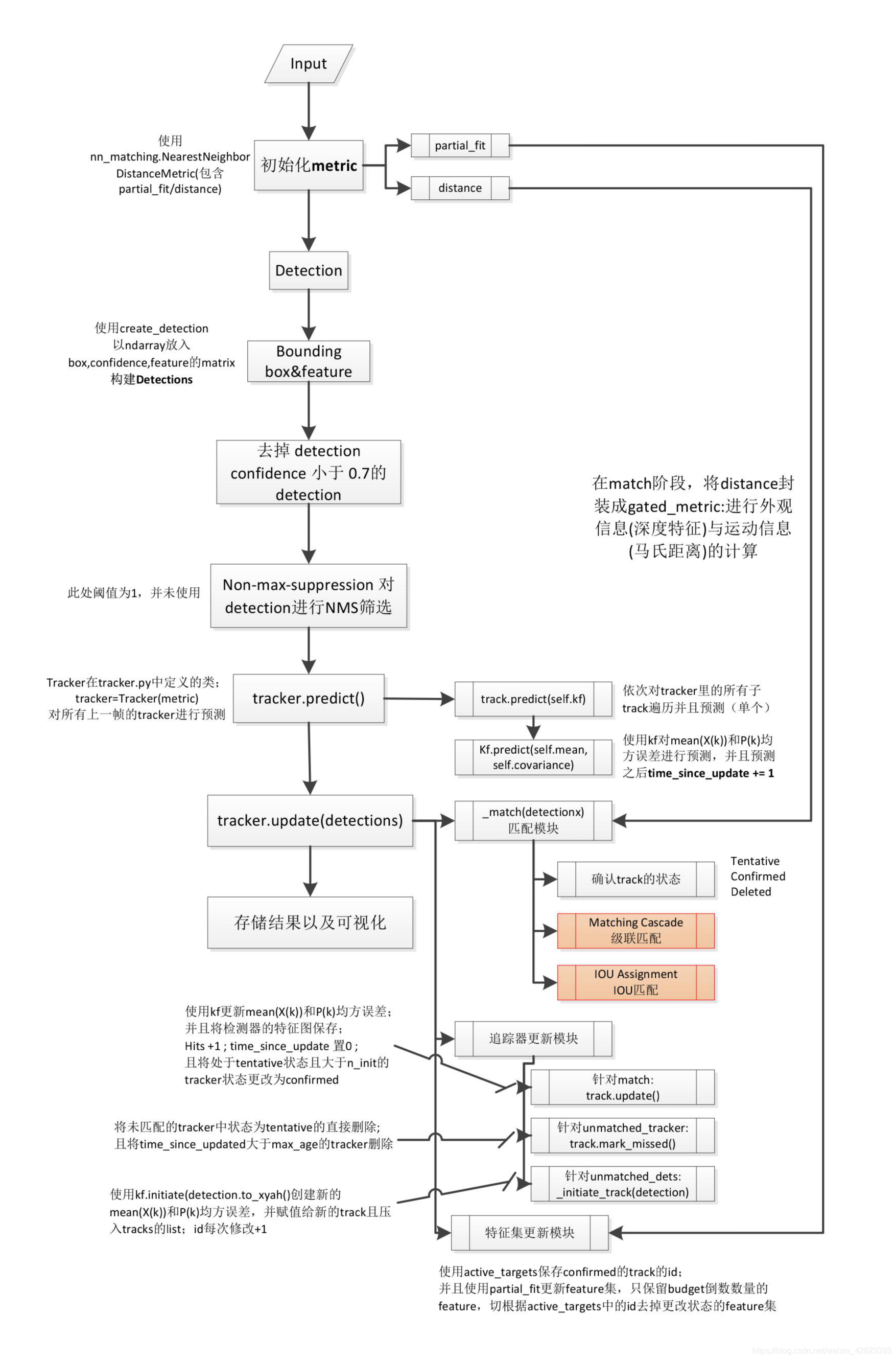
IOU匹配流程图
同时,作者还介绍了测试结果的编码,如边界盒、置信度、置信度、置信度、置信度等,主要用于检查测试盒的一部分;跟踪后采用键合盒和fevar进行匹配计算;首先,预测模块可以利用卡尔曼滤波进行预测跟踪,本文采用卡尔曼滤波的线性运动可观测性统一模型,即只使用第二个检测器配置四个变量,包括在匹配、跟踪和更新部分,基本的方法还是用国际单位来实现匈牙利匹配算法
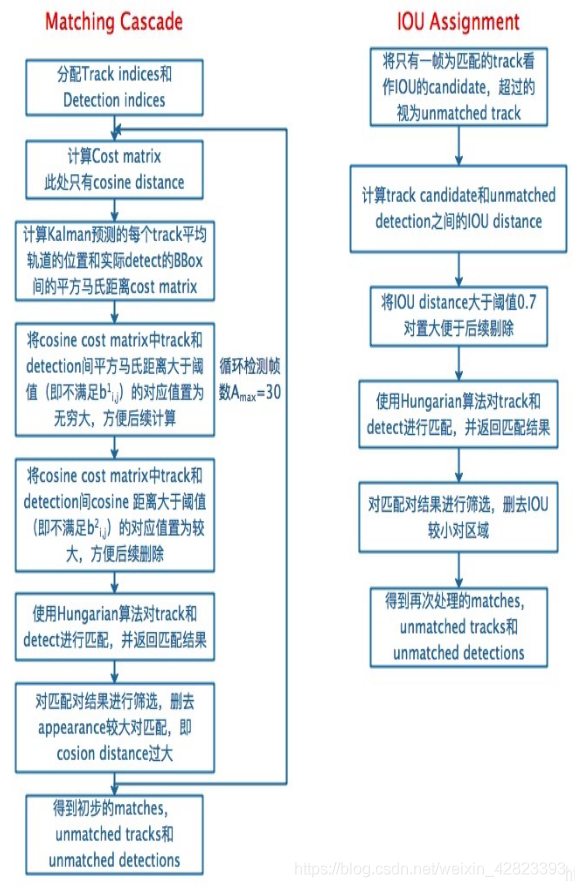
1.使用级联匹配算法:
每个探测器将被分配一个跟踪器,并且每个跟踪器将设置一个时间自更新参数。如果跟踪器完成匹配并更新,参数将重置为0,否则将为+1。实际上,级联匹配,换句话说,就是不同优先级的匹配。在级联匹配中,跟踪器将根据该参数进行排序。先匹配小参数,后匹配大参数。也就是说,首先匹配前一帧的跟踪器被赋予高优先级,而不匹配多个帧的跟踪器被赋予低优先级(慢慢放弃)。
至于使用级联匹配的目的,我引用博客2中的解释 当目标被长期遮挡时,卡尔曼滤波预测的不确定性将大大增加,状态空间的可观测性将大大降低。
如果此时两个跟踪器争夺同一检测结果的匹配权,遮挡时间越长的轨迹的马氏距离往往越小,使得检测结果越容易与遮挡时间越长的轨迹相关联。这种不良影响通常会破坏跟踪的连续性。如果协方差矩阵是正态分布,则如果不更新连续预测,正态分布的方差将变得越来越大。然后,远离平均值欧氏距离的点可以获得与先前分布中更接近平均值的点相同的马氏距离。
因此,本文采用级联匹配的方法来优先选择更频繁的目标。当然,也有缺点:一些新的轨道可能会连接到一些旧的轨道。但这是少。 2.加上马氏距离和余弦距离 实际上,它是运动信息和外观信息的计算。实际上,换句话说,马氏距离就是“增强的欧氏距离”。实际上,它避免了欧氏距离中数据特征方差不同的风险,并在计算中加入了协方差矩阵。其目的是对方差进行归一化,使所谓的“距离”更符合数据特征和实际意义。马氏距离是差度数测量中的一种距离测量方法。与马氏距离不同,余弦距离是一种相似性度量方法。前者是位置,后者是方向。换言之,当我们使用余弦距离时,它可以用来衡量不同个体在维度上的差异,但我们很难判断个体在维度上的差异。
这时,我们可以用马氏距离来弥补,从而达到比较全面地衡量整体差异的目的。我们之所以要测量这种差异,是因为我们要比较探测器和跟踪器之间的相似性,并优化测量方法以更好地完成匹配。 3.添加深度学习功能 这部分是里德的模块,也是deepsort的亮点之一。Deepsort在改进sort的基础上增加了一个深度学习的特征提取网络。在网络结构部分,可以移动纸张。作者将所有确认的跟踪器(状态之一)存储到一个列表中,以便每次匹配相应检测的特征图。存储量受到预算超级参数(100帧)的限制(我想如果实时效果不好,可以降低这个参数来加快速度)。
因此,我们会在每次匹配后更新特征映射列表,比如删除一些已经被射击的目标的特征集,保留最新的特征,弹出旧的特征等,这个特征集将在余弦距离计算中起到作用。实际上,在当前帧中,计算第i个目标跟踪和第j个目标检测的所有特征向量之间的最小余弦距离。 4.IOU匹配匈牙利算法: 这种方法是分类提出的。又是个奇怪的名词。换言之,我继续说。事实上,匈牙利算法可以理解为“尽可能多”的思想。例如,探测器可以匹配a和C跟踪器(具有更高的可靠性),但B探测器只能匹配跟踪器。在算法中,让a和C完成匹配,B和a完成匹配,减少了对置信度的考虑。所以算法的根本目的不是精确匹配,
而是尽可能多的匹配,这也是作者在深度排序中加入级联匹配和马氏距离、余弦距离的根本目的,因为只使用匈牙利算法进行匹配特别容易引起ID切换,这是一个检测盒ID不断变化,缺乏准确性和鲁棒性。什么是高c
Deepsort 代码解读
另一篇写的很棒的Deepsort 原理解读:https://blog.csdn.net/sgfmby1994/article/details/98517210
yolo的总体思想归纳:
首先,将输入图片压缩到416× 416,通过特征提取网络(darknet53无FC层)从输入图像中提取特征,得到一定大小的特征图,如13× 然后将输入图像分为13个部分× 然后,如果目标在GT中的中心坐标落在哪个网格单元内,则该网格单元将用于预测目标。每个网格单元预测三个边界框。预测的输出特性图是三维的,第三维是深度。 Yolov3输出三个不同比例的特征图。利用多尺度检测不同尺寸的物体,精细网格单元可以检测出更精细的物体。三个刻度的深度都是255(3×( 5+80))。
根据图说明过程 过程:首先输入尺寸416× 416,然后进入暗网特征提取网络,右图(不算分支,还把内容放在左图的虚线上)。经过5次下采样后,仍采用残差结构,使网络结构仍能在很深的情况下收敛并继续训练。然后去左边的图。虚线中的输出大小是13× 然后,在DBL特征提取和最终的蓝色卷积(我猜它是用来代替全连接分类)之后,输出第一个比例13× 13。 然后,虚线输出的特征映射通过DBL× 上下采样结果之和为26× 26,然后进行与秤1相同的后续操作。
最后,26× 在对26的特征映射进行上采样后,将其与倒数第二次下采样的特征映射相加,即也是26× 26日,在后续行动中。 通常,输出三个不同尺度的特征图,每个尺度负责预测不同尺寸的目标。每个特征映射对应于三个不同大小的锚来预测目标。原始图像也被分成13个部分× 在13个网格中,目标所在的网格负责预测目标。一个网格对应三个锚定(锚定的大小根据特征图像相对于原始图像的比例成比例减小)。 在预测中,yolov3使用多个独立的逻辑分类器来计算属于特定标签的概率。在计算分类损失时,对每个标签采用二进制交叉熵损失,降低了计算复杂度。
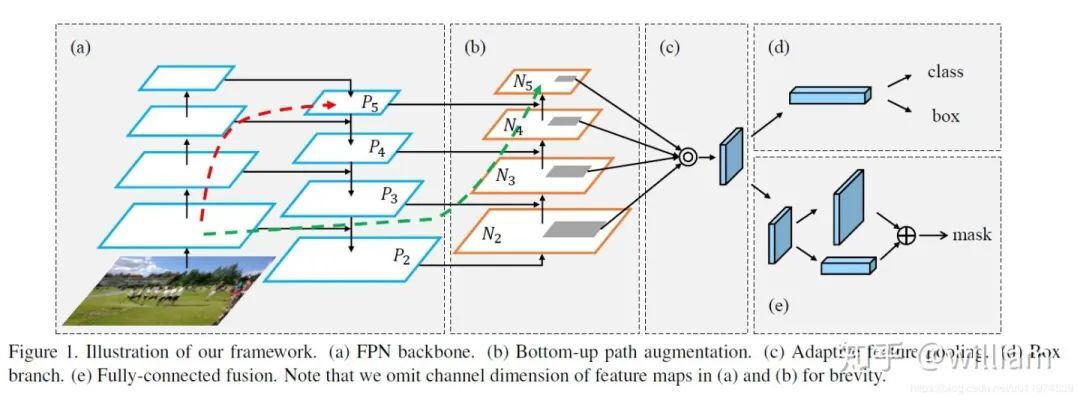
csp 一个特征网络
YOLOv3 和YOLOv5 整体思想类似,不过YOLOV5 增加了PaNet等tricks,以及Mossiac等大量数据增强,
yov5使用giou loss作为边界框的损失。
yolov5使用二元交叉熵和Logits损失函数来计算类损失概率和目标得分。我们也可以用fl_uγ参数激活焦损来计算损失函数。 在yolov5中,中间/隐藏层采用漏relu激活函数,最终检测层采用sigmoid激活函数。
YOLOv3/YOLOv5 训练教程:
以github Ultralytics 作者的Yolov3 和Yolo v5 为例子,可以很迅速的训练数据:1:配置环境 pip install -U -r requirements.txt
2:数据标注与预处理
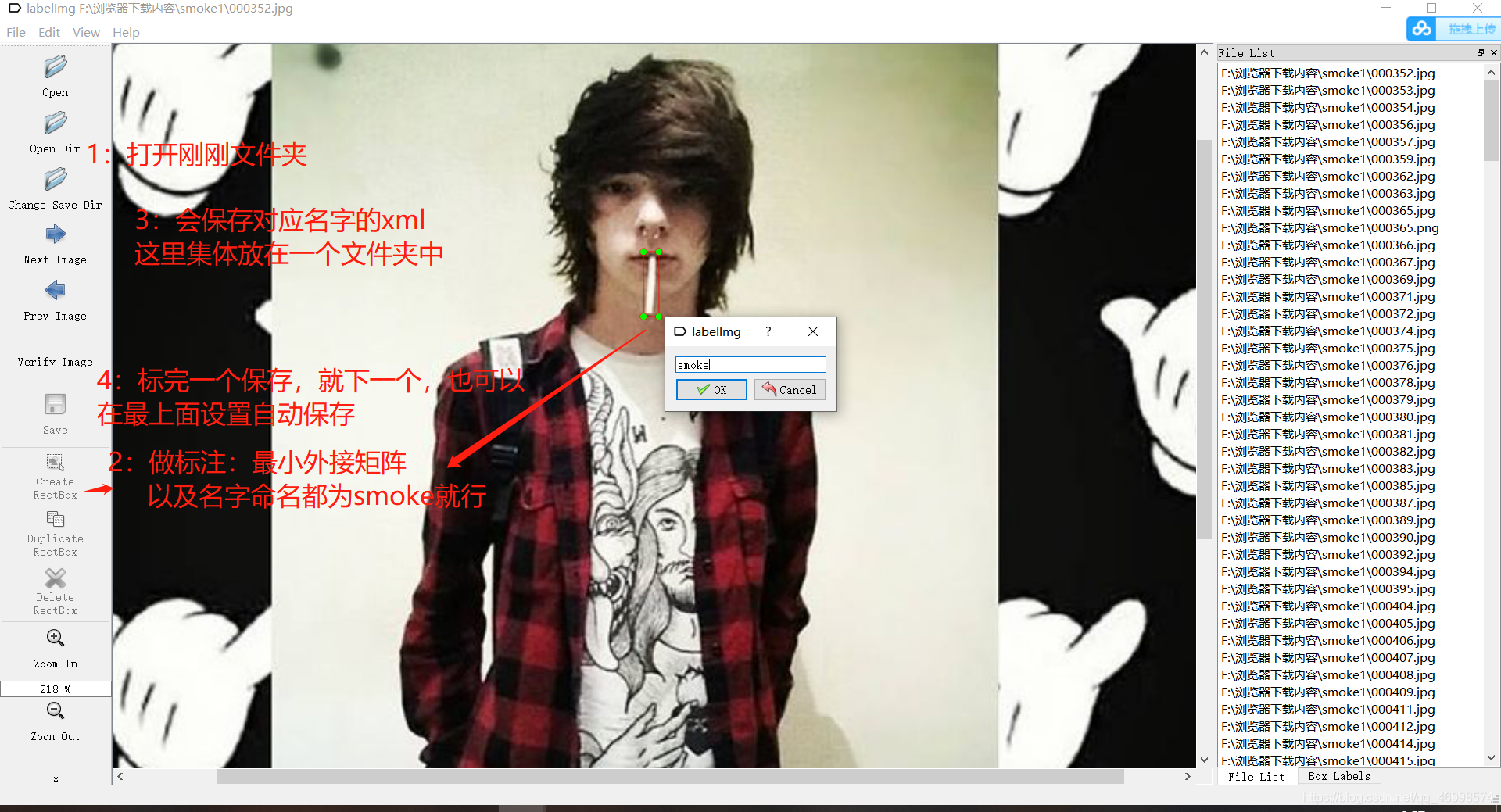
将我们的XML文件放至Annotations
将我们的图片放到images
然后就可以转换为Yolo的训练格式,百度有很多。这里要注意看一下代码,有的地方需要修改。
并切分训练验证集,代码也给了,Voc_Labels.py 请看看代码,没怎么写注释。
接下来编写data/文件夹的yaml文件(可以新建):
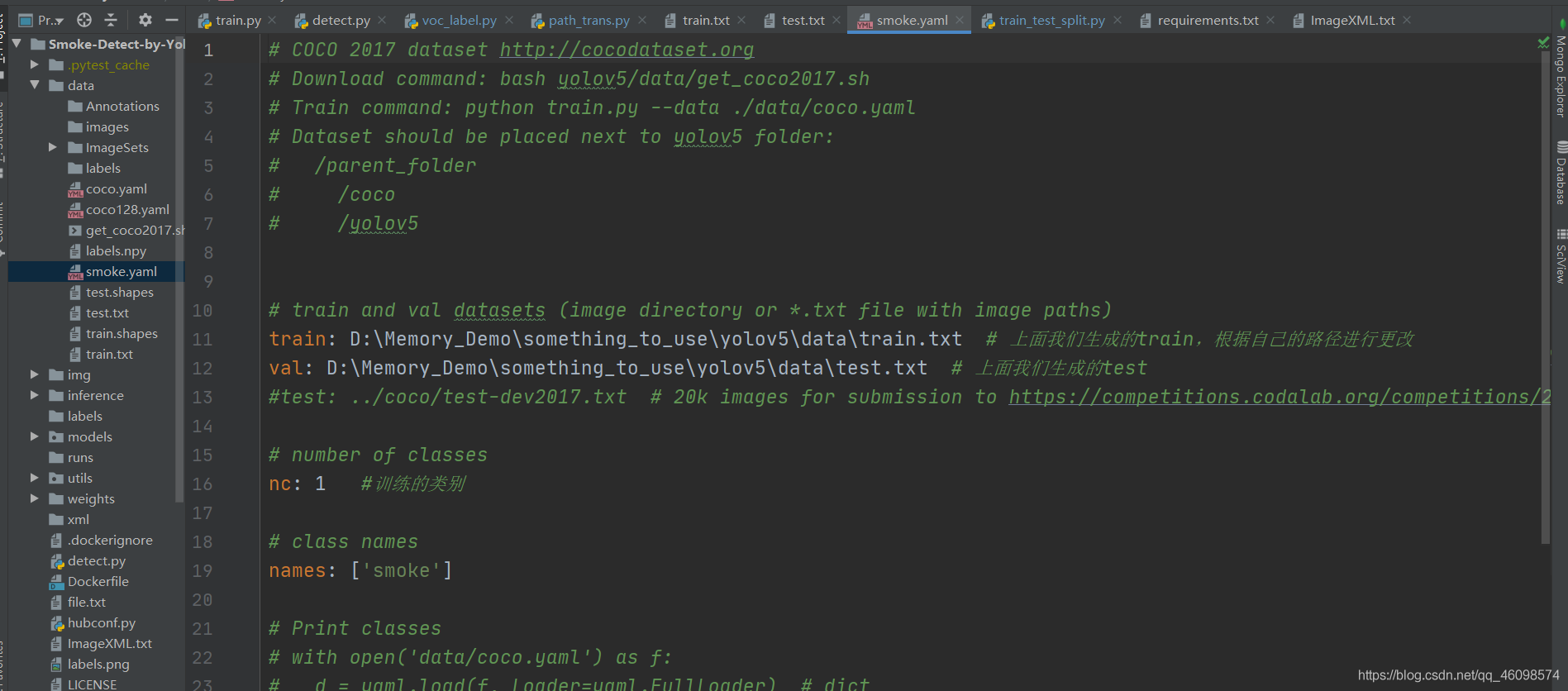
经过数据预处理后,就可以开始训练了。
每个人在上面的一些处理步骤中可能会有所不同,但总的来说,想法是相同的。 接下来,我们可以进行预培训并下载正式的预培训模型。我在GitHub中构建了yolov5s,
它相对较小,只有25mb,专门用于移动终端。
很好。 当然,我们不能采用预先培训的模式。不管我们是否使用它,总时间几乎是一样的,但是
为什么要使用预培训模式? 作者已经尽了最大的努力来设计基准模型。
我们可以在我们自己的数据集上使用预训练模型,而不是从头开始建立模型来解决类似的自然语言处理问题。 尽管仍需要进行一些微调,但它为我们节省了大量时间:通常每个损耗下降得更快,并且节省了计算资源。 加速梯度下降的收敛速度 更容易得到模型误差小或泛化误差小的模型 它可以减少由于未初始化或初始化不当而引起的梯度消失或梯度爆炸的问题。这种情况会导致模型的训练速度减慢、崩溃,甚至失败。 其中,随机初始化可以打破对称性,
使不同的隐单元可以学习到不同的东西 接下来,
开始训练:
python train.py --data data/smoke.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt --batch-size 10 --epochs 100
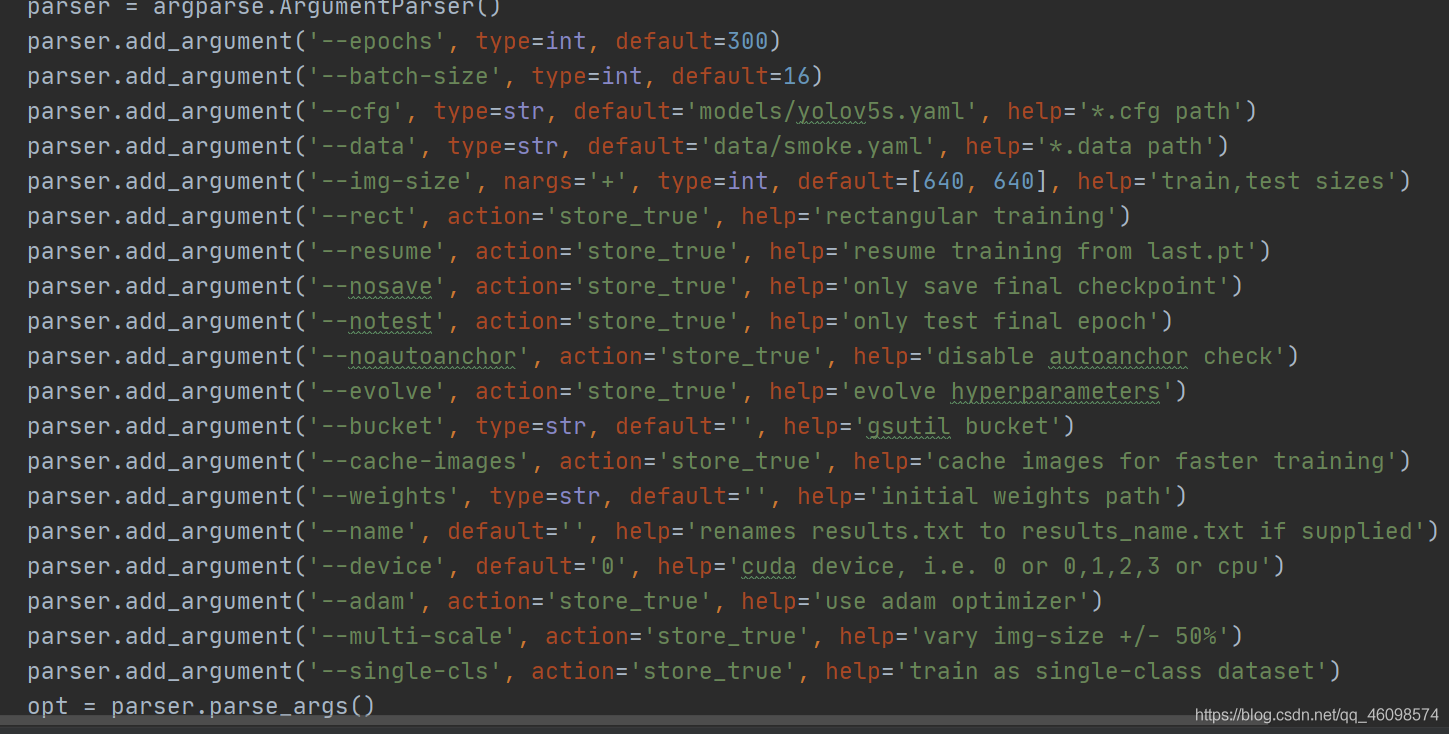
We–data/smoke.yaml是用smoke.yaml编写的训练代码路径和类别数据,通过它我们可以得到训练图片和标签。 然后使用-CFG models/yolov5s.yaml和--weights/yolov5s.pt获得配置模型和预训练模型的权重 批量大小10大家都知道,默认是16,可以改成16。在yolov5s中,模型参数不多,大约一百万,所以视频内存的消耗并不多。我的配置很差。使用yolov5m时,视频存储器4G不能调整为16。 如果可以报告CUDA内存不足错误,只需减小批处理大小。 最后,epoch,我不需要解释,我用yolov5m训练了24小时5公里的图片,用100 epoch训练了13分钟。 在训练过程中,在跑步过程中会缓慢产生张力板,减少视觉损失
当然也可以在本地稍微看看:
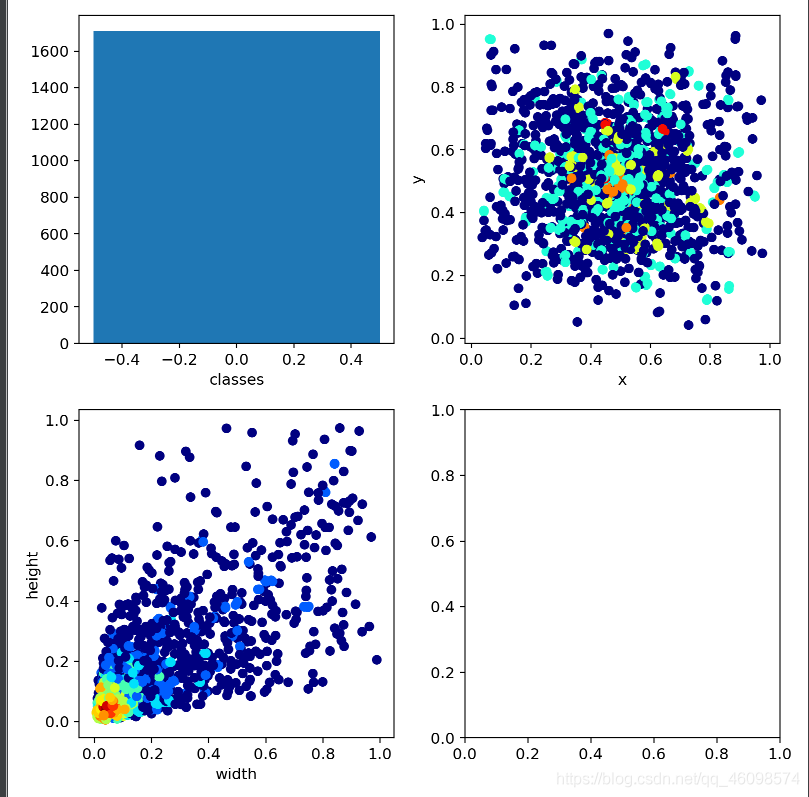
这幅图中,我们的类别只有1个,第三幅图显示了我们数据中的宽高比,归一化后,普遍在0.1左右,说明数据确实很小,也会面临模糊问题,导致数据质量降低。
检测:
运行detect.py即可
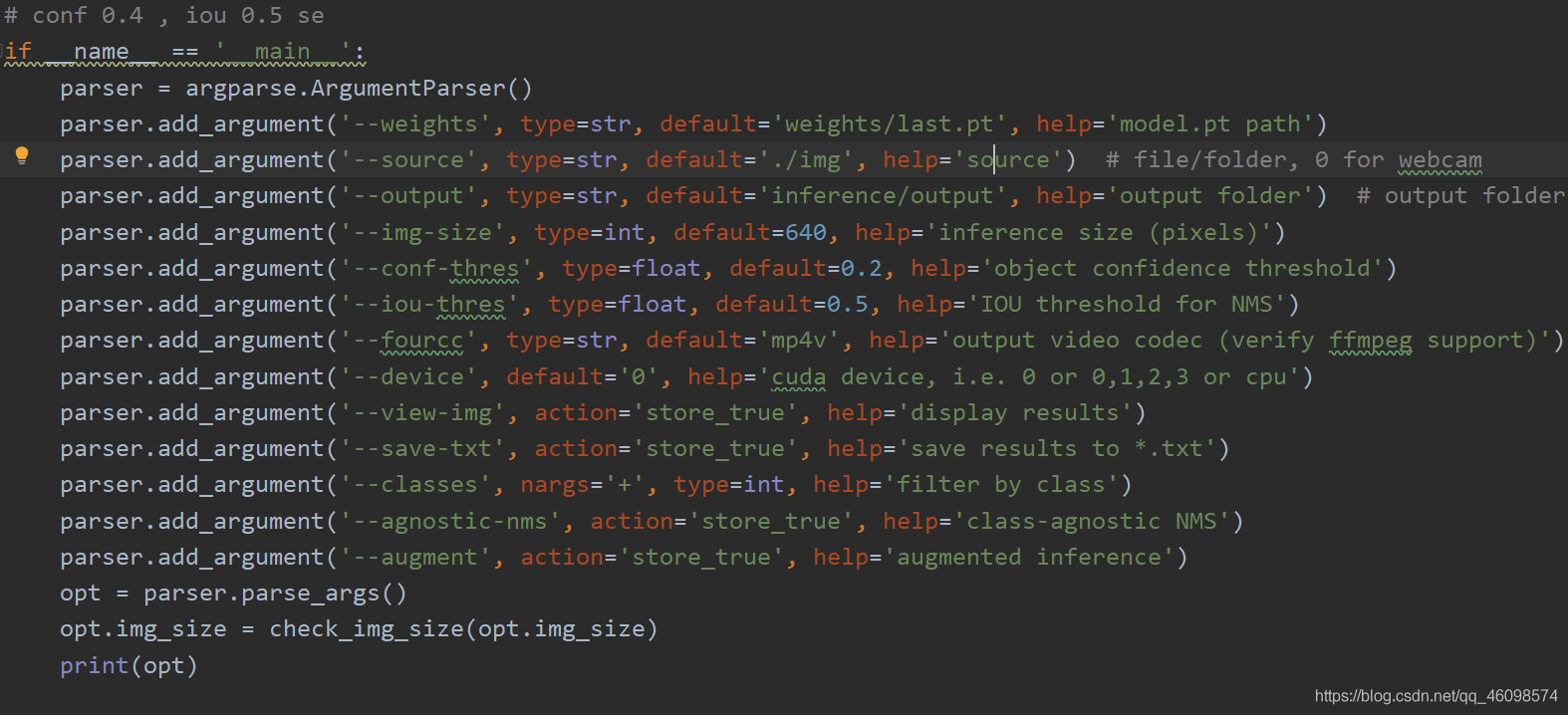

代码介绍
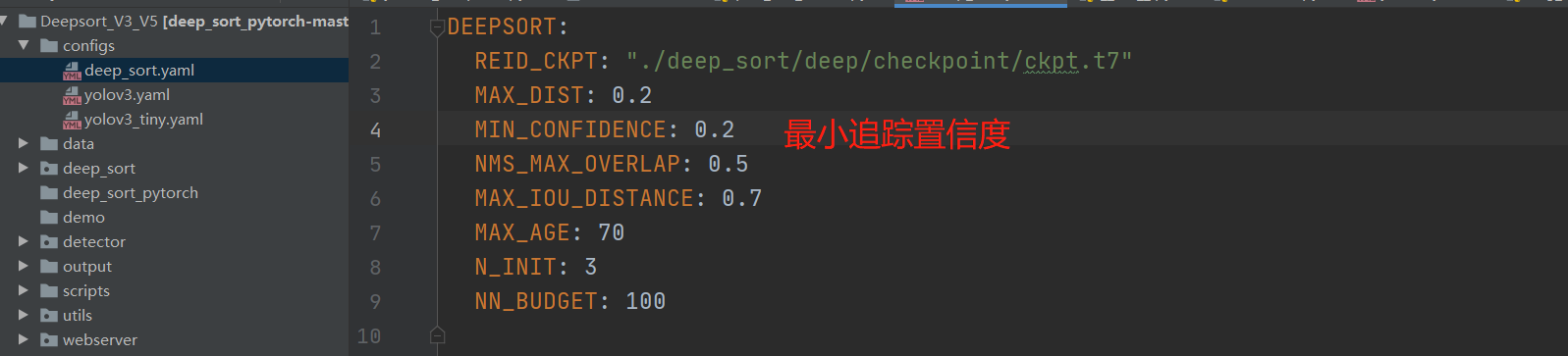
来回顾一下代码:
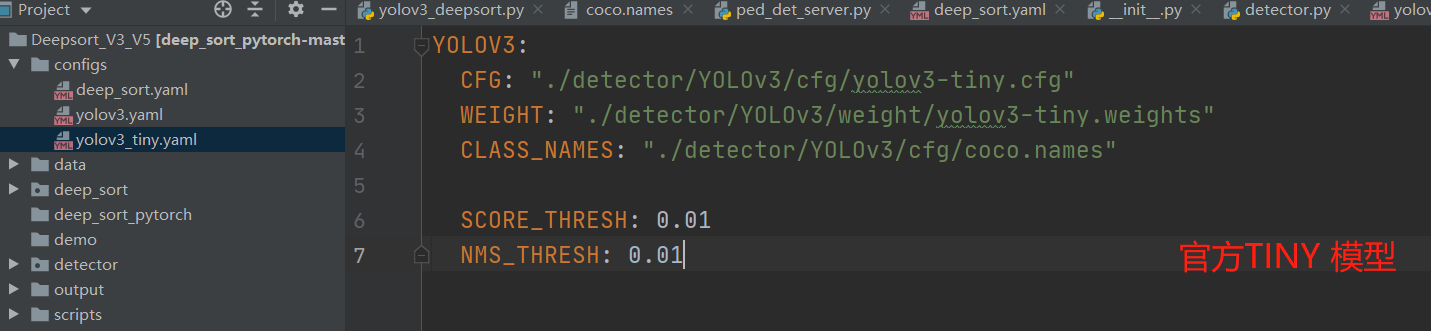
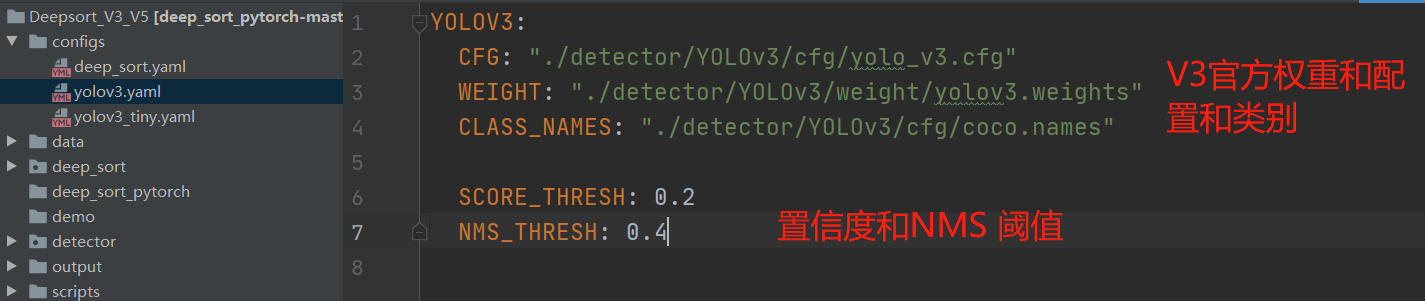
验证脚本
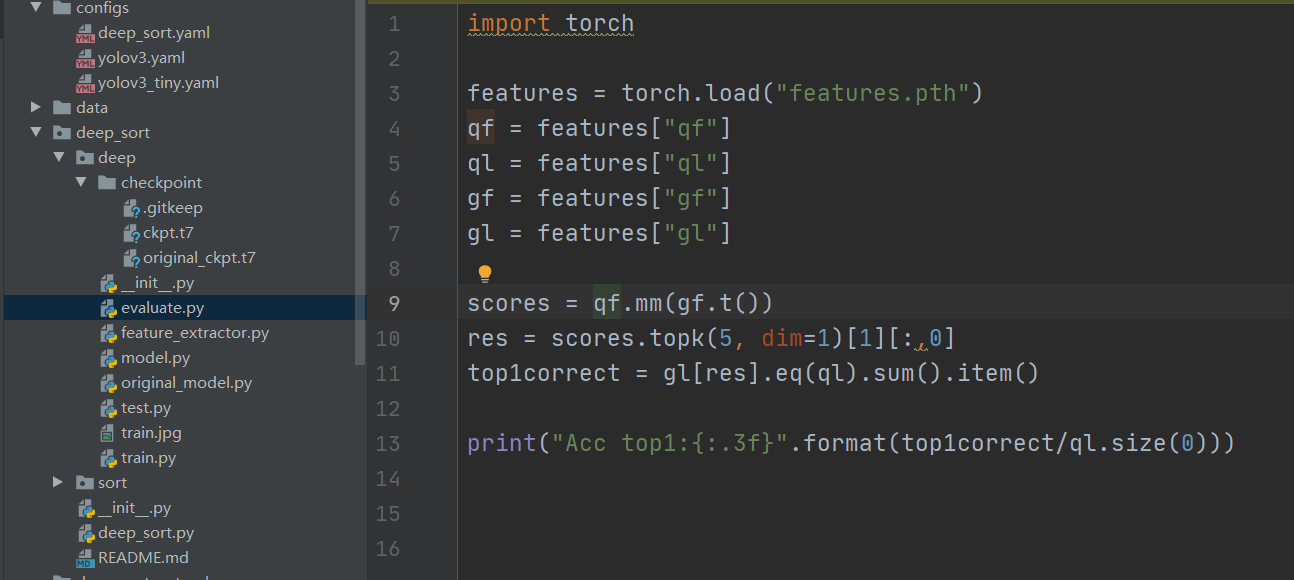
特征提取类
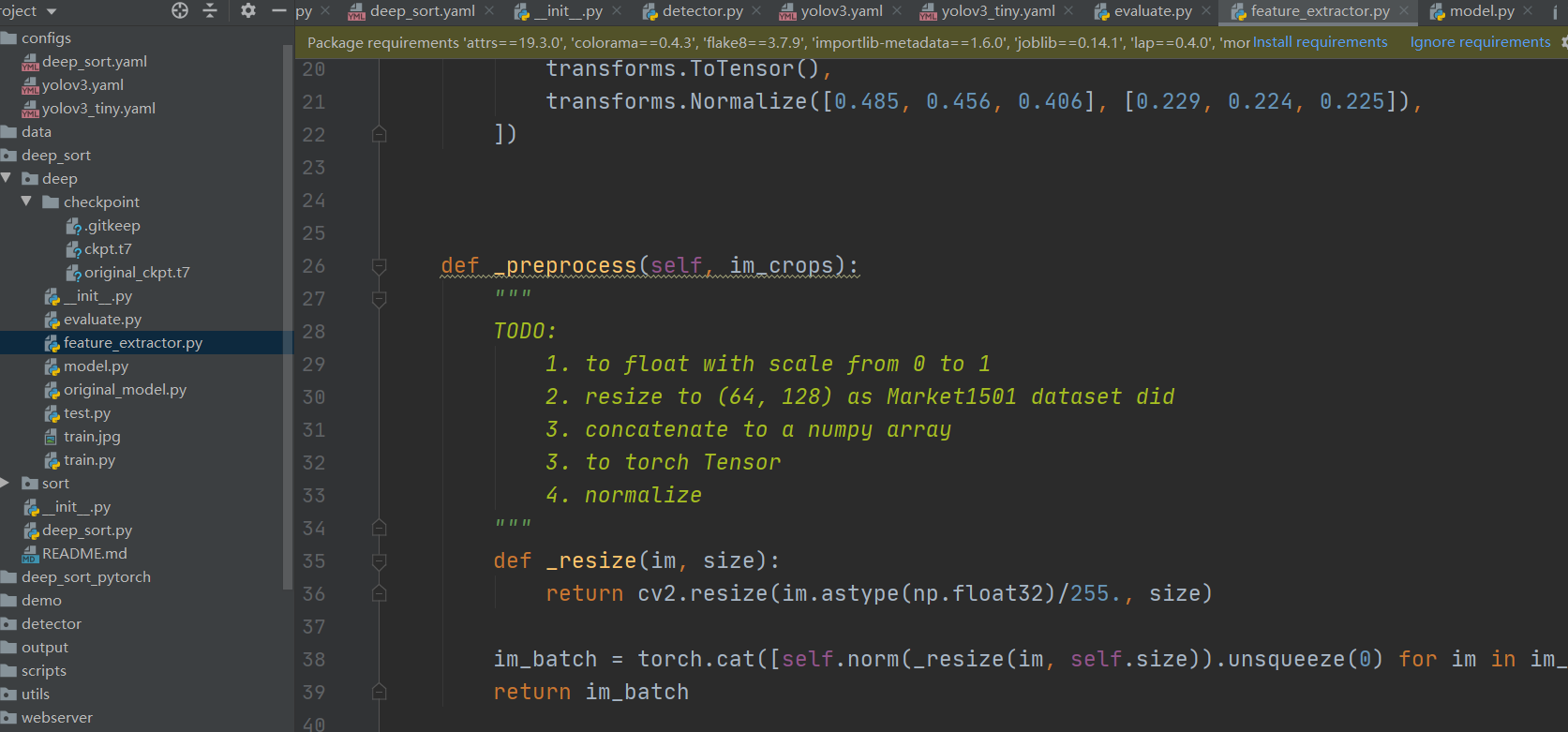
以【batch size,3,128,64】输入,返回类别结果的网络处理层,被上图特征提取类使用。
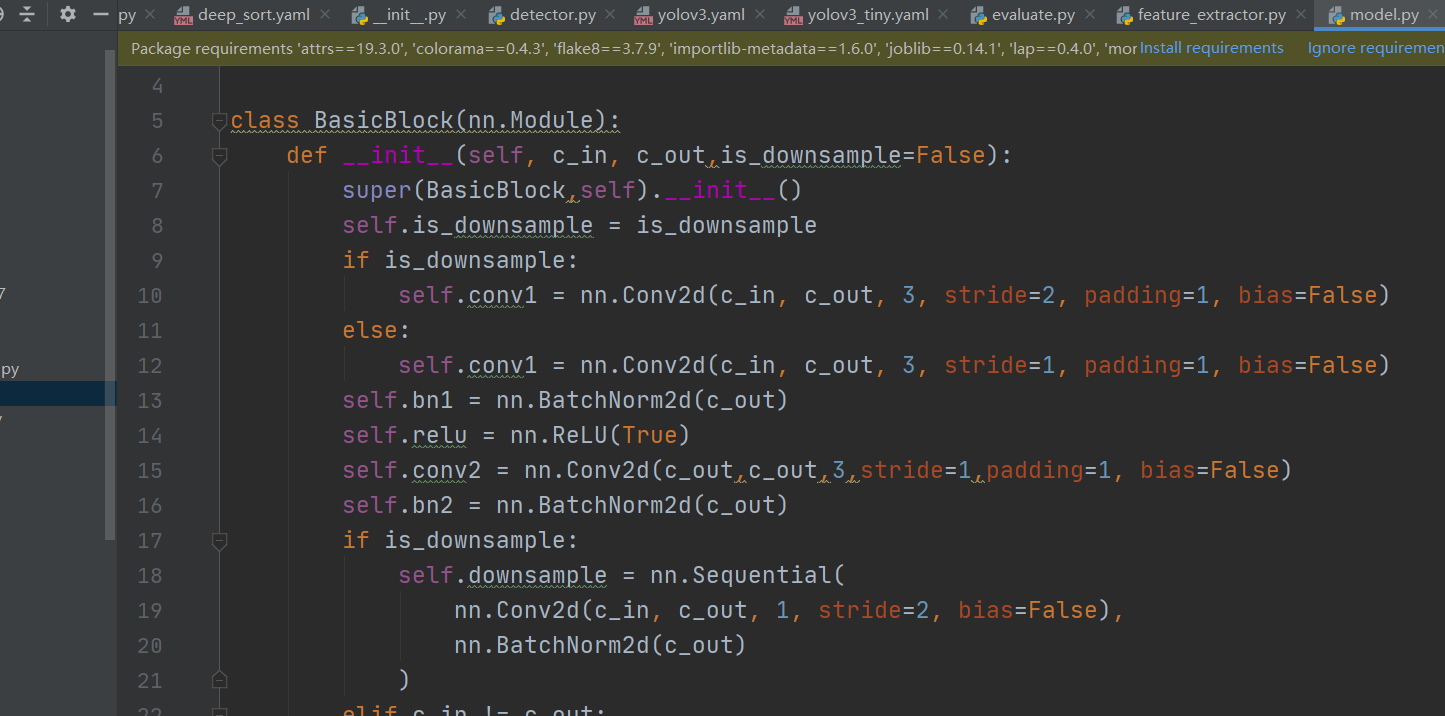
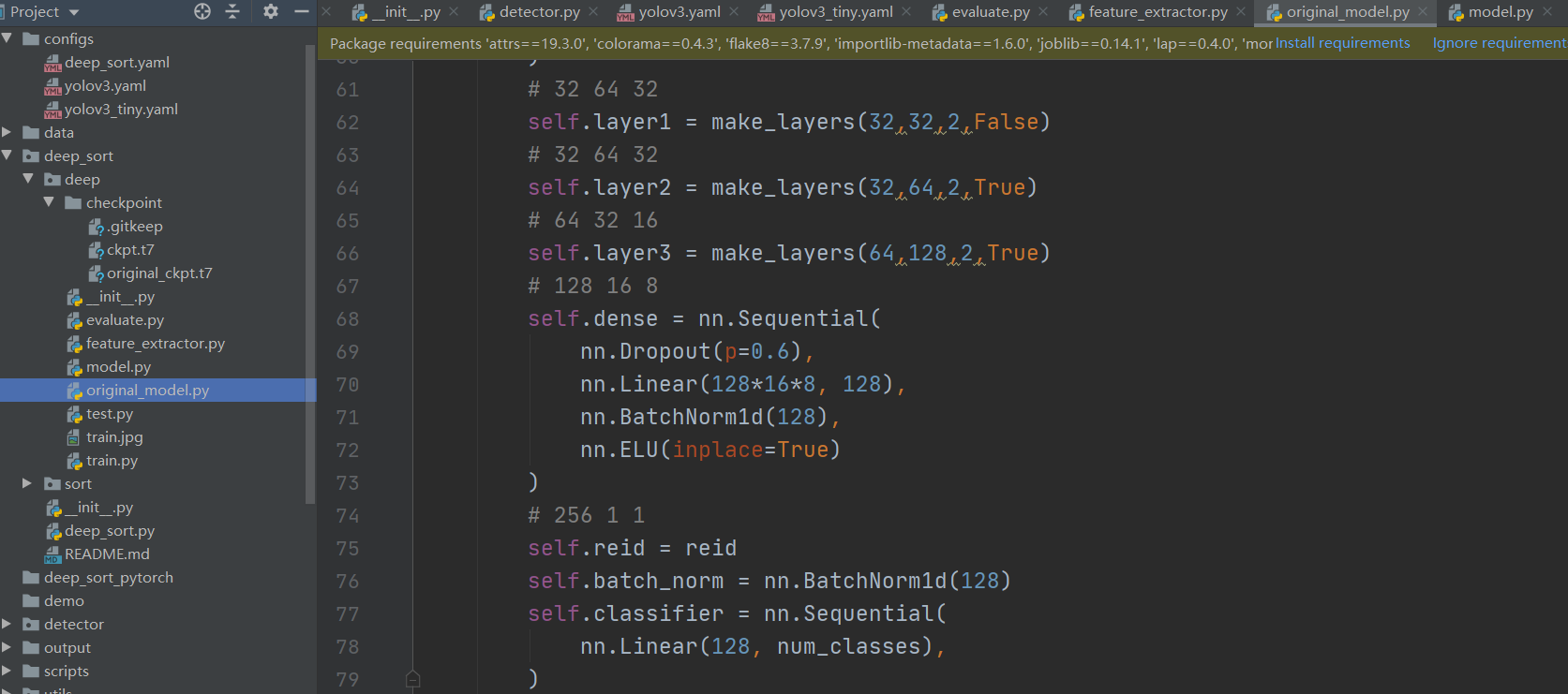
上图目前网络较原网络稍稍优化了,下图为原始网络。
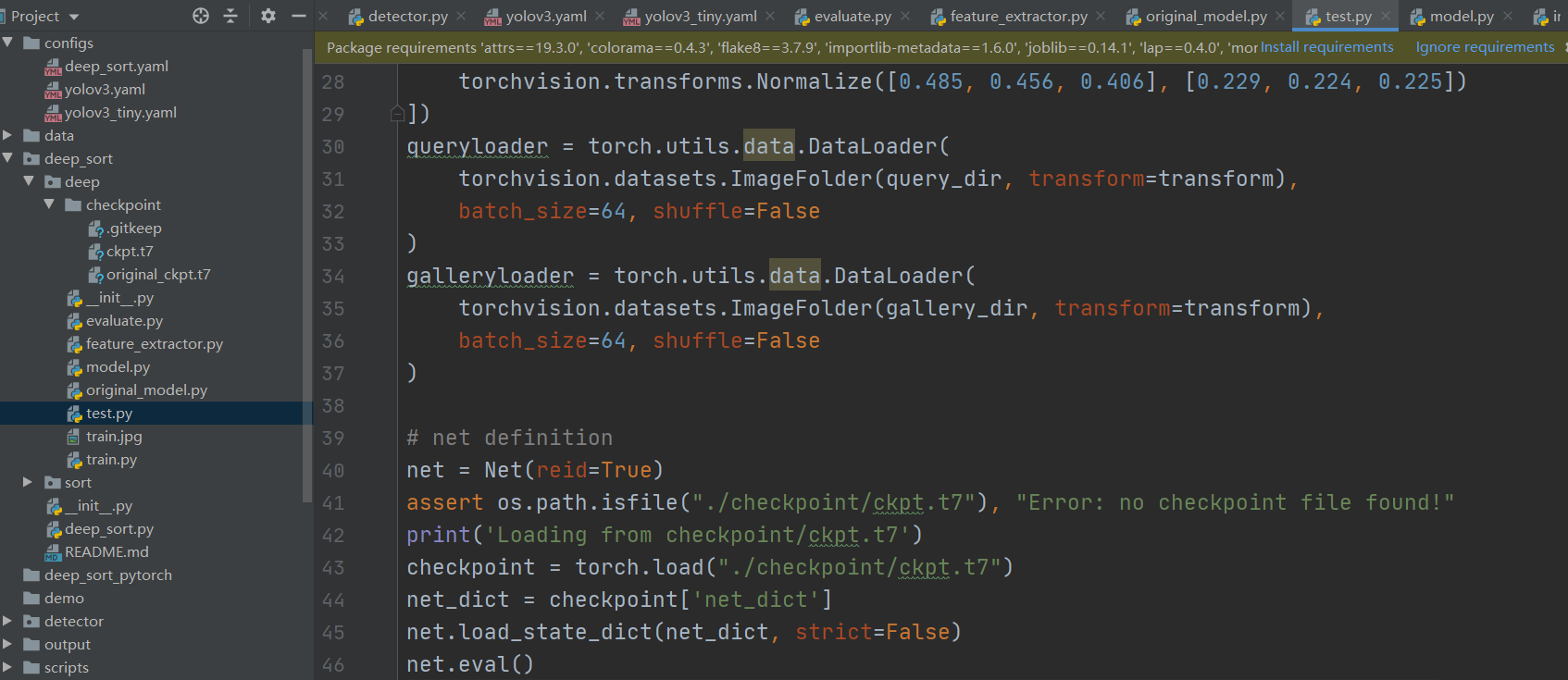
网络性能验证与测试
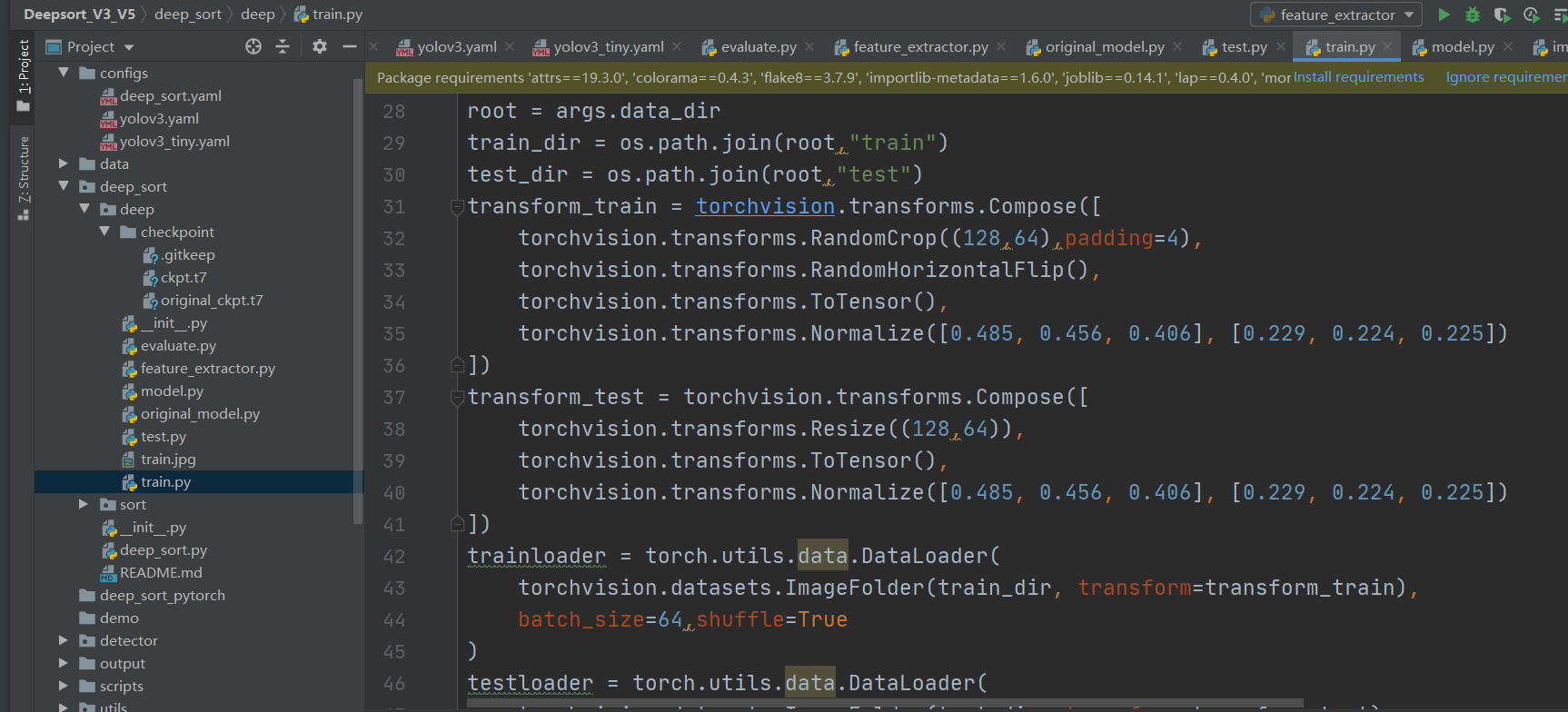
网络训练。
追踪部分:
追踪部分的数据转换
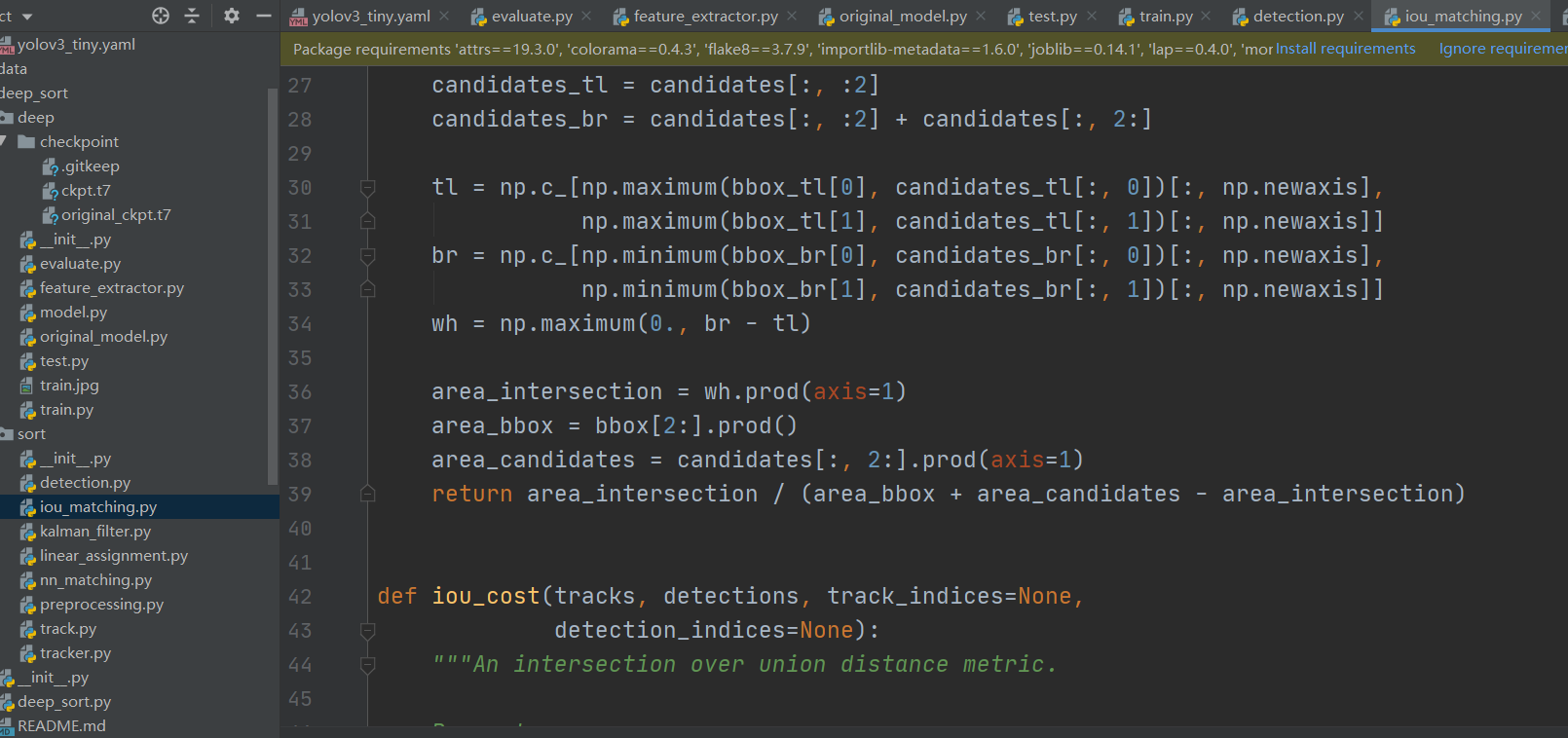
匹配Iou,用来区别框是否为待追踪目标的途径之一。
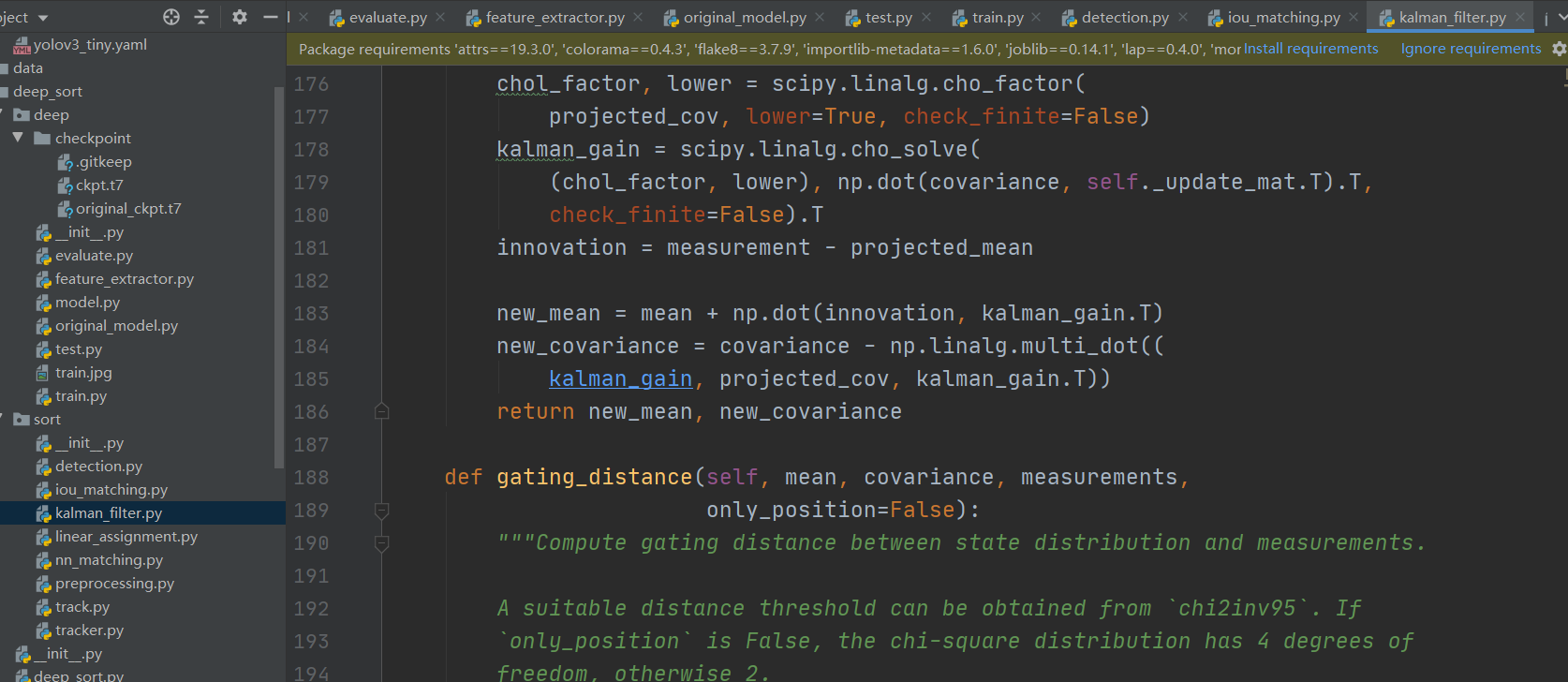
卡尔曼滤波
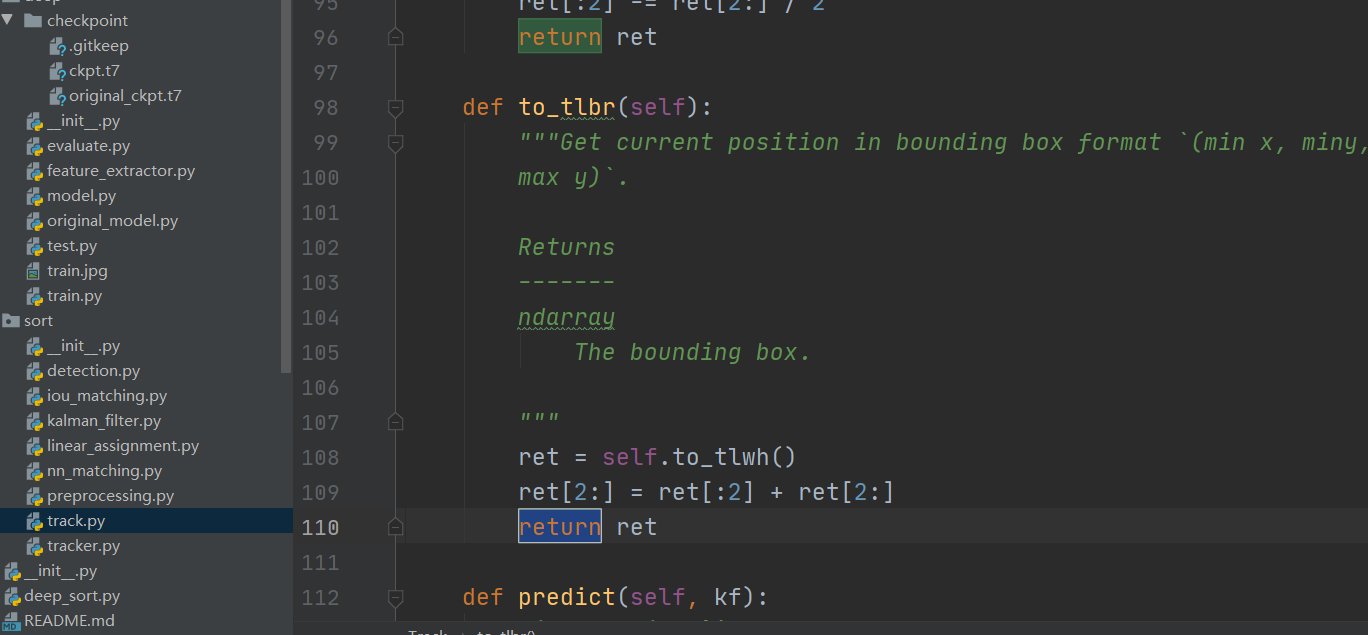
追踪类,返回识别结果
同追踪类,返回匹配追踪目标,和不匹配目标
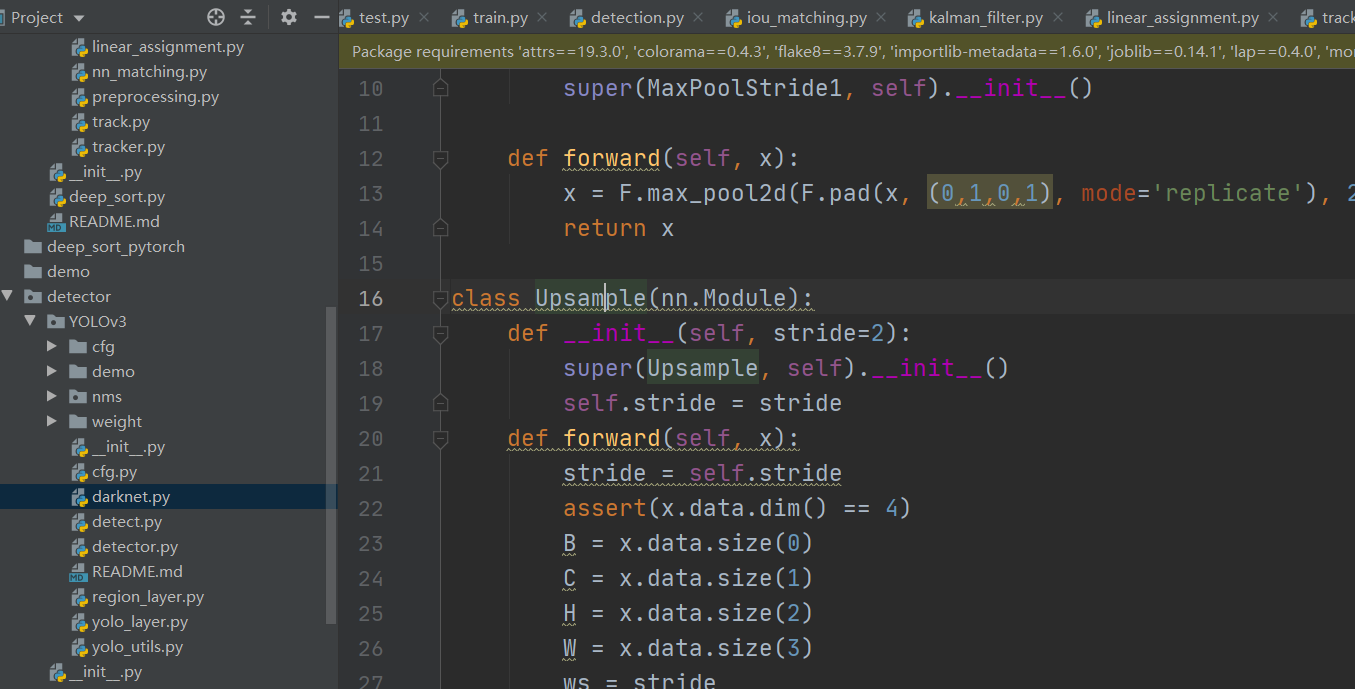
YOLOv3 部分,darknet版本,的pytorch版。
原始类别的检测脚本
更改后用于追踪的检测脚本
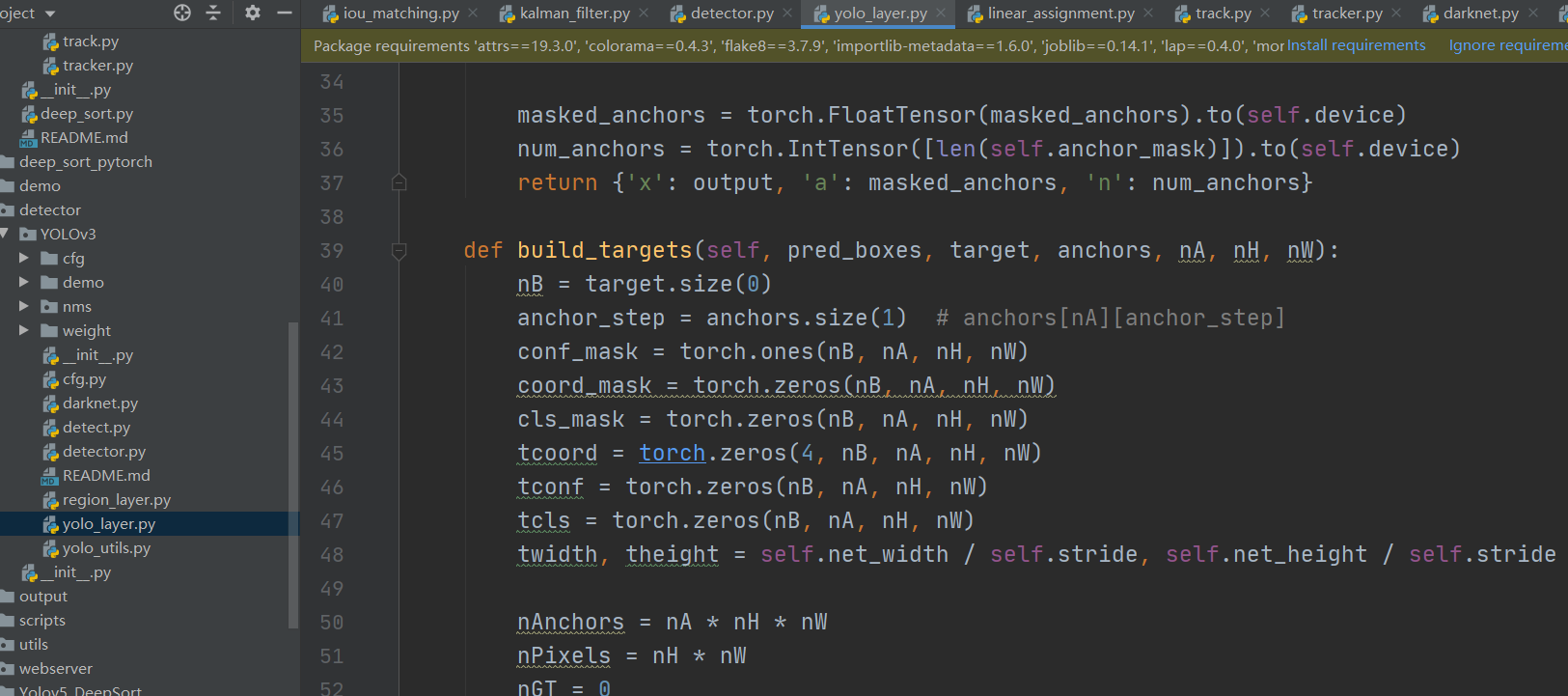
YOLOv3 网络层
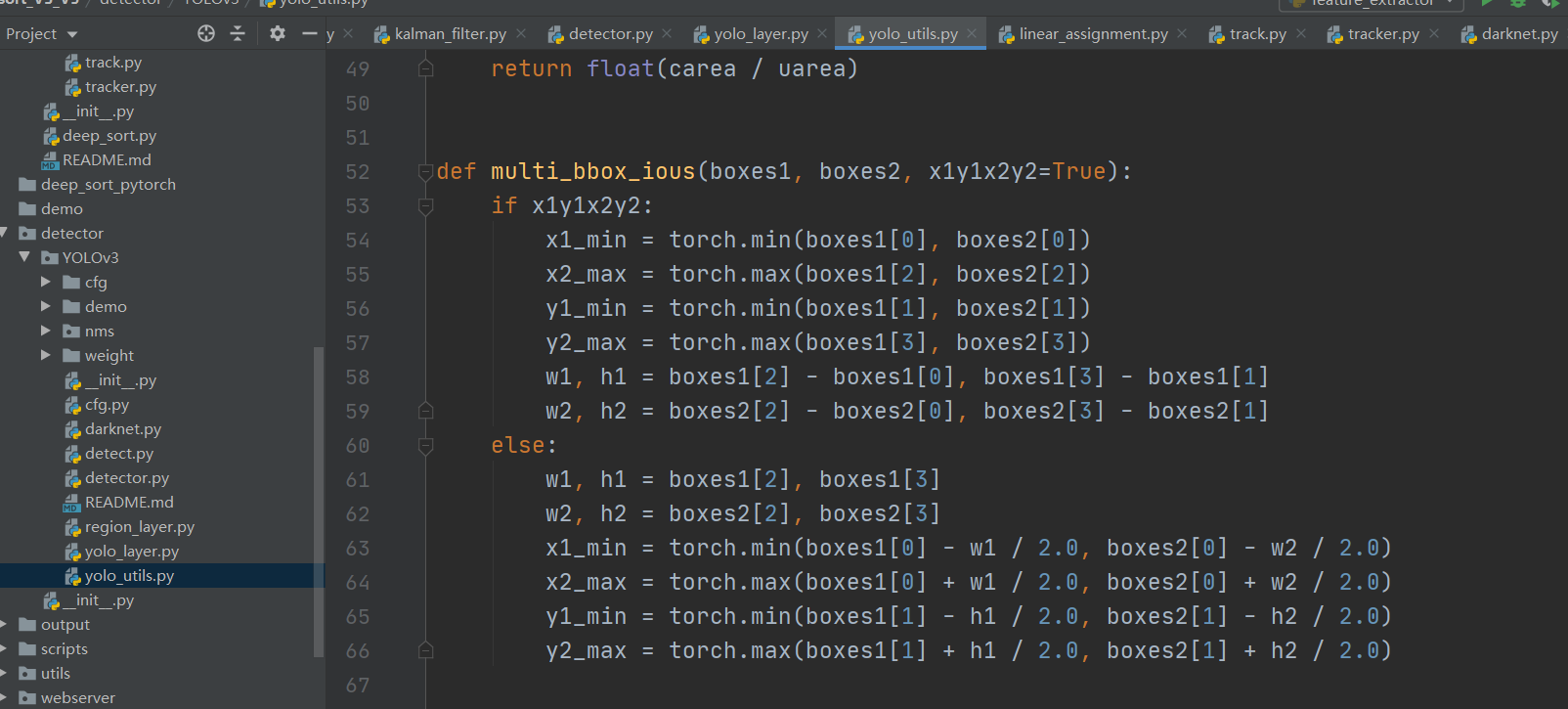
处理数据,bdbox,nms等操作的配置类utils
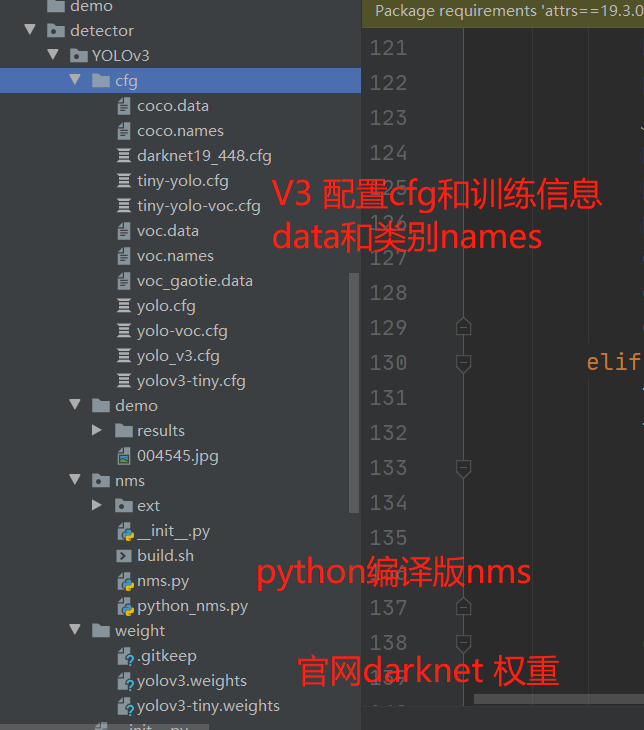
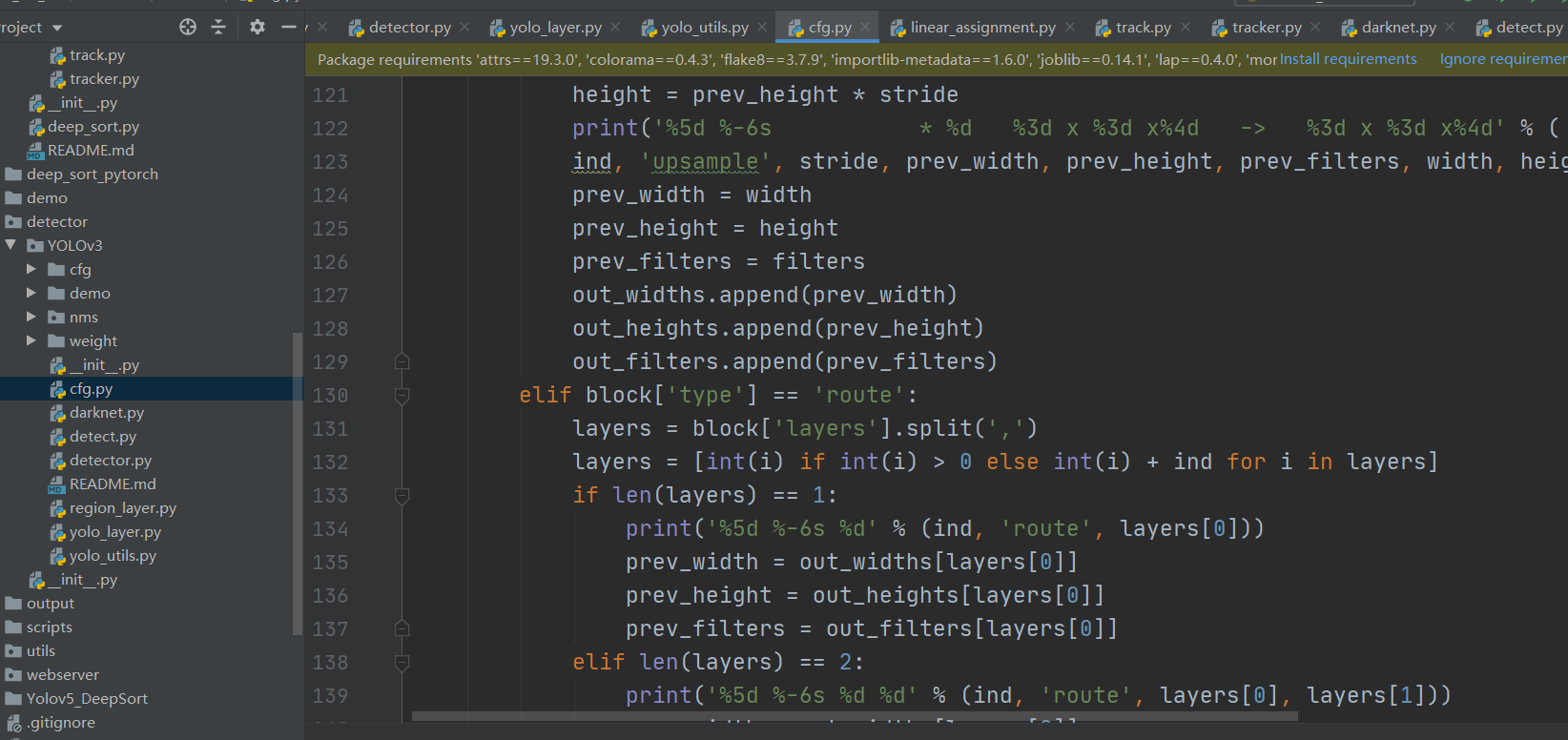
解析config类
Rtsp推流等方式web端部署。
V5区域
训练部分代码和参数
图片,视频,web,相机等多方式检测
配置多比例模型和配置utils。
V5 导出模型onnx
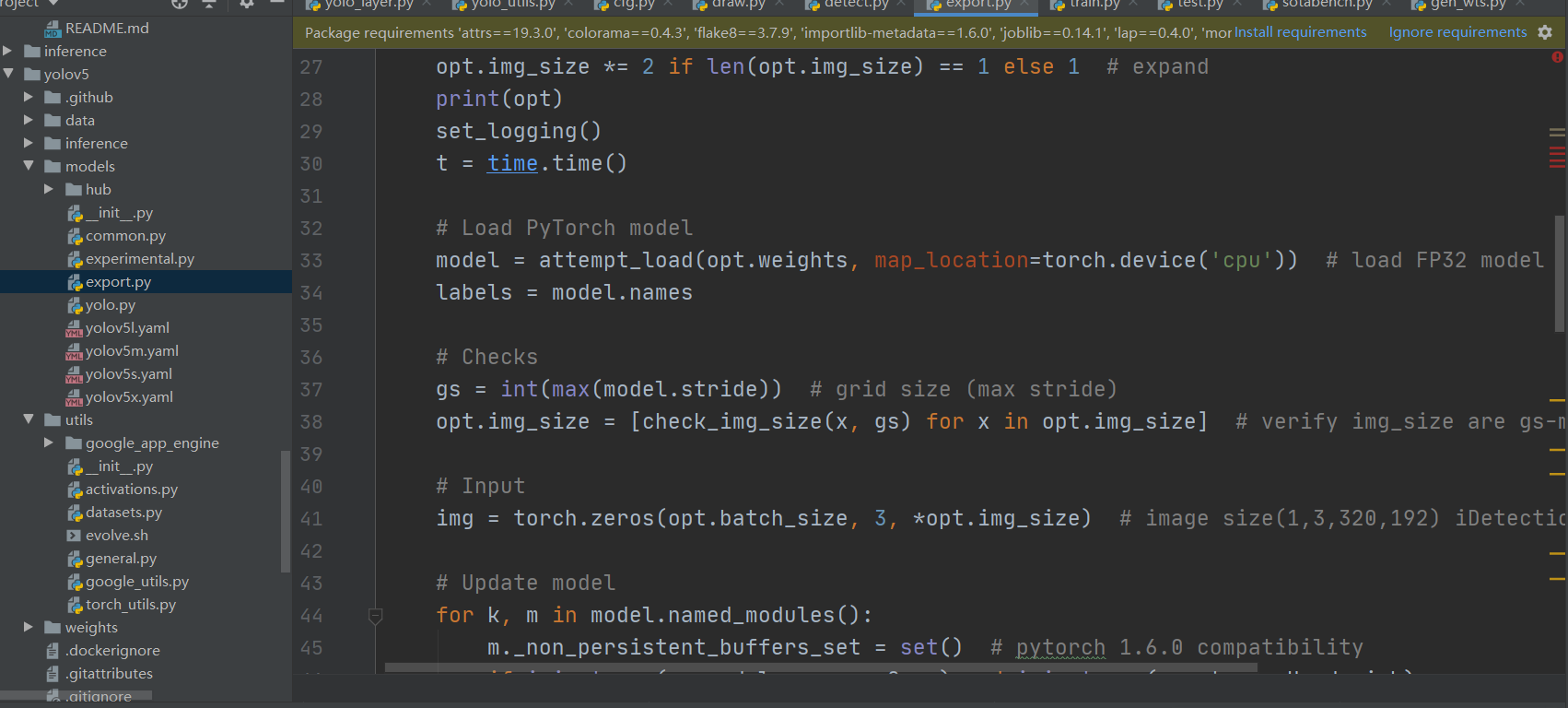
演示
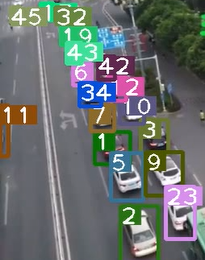
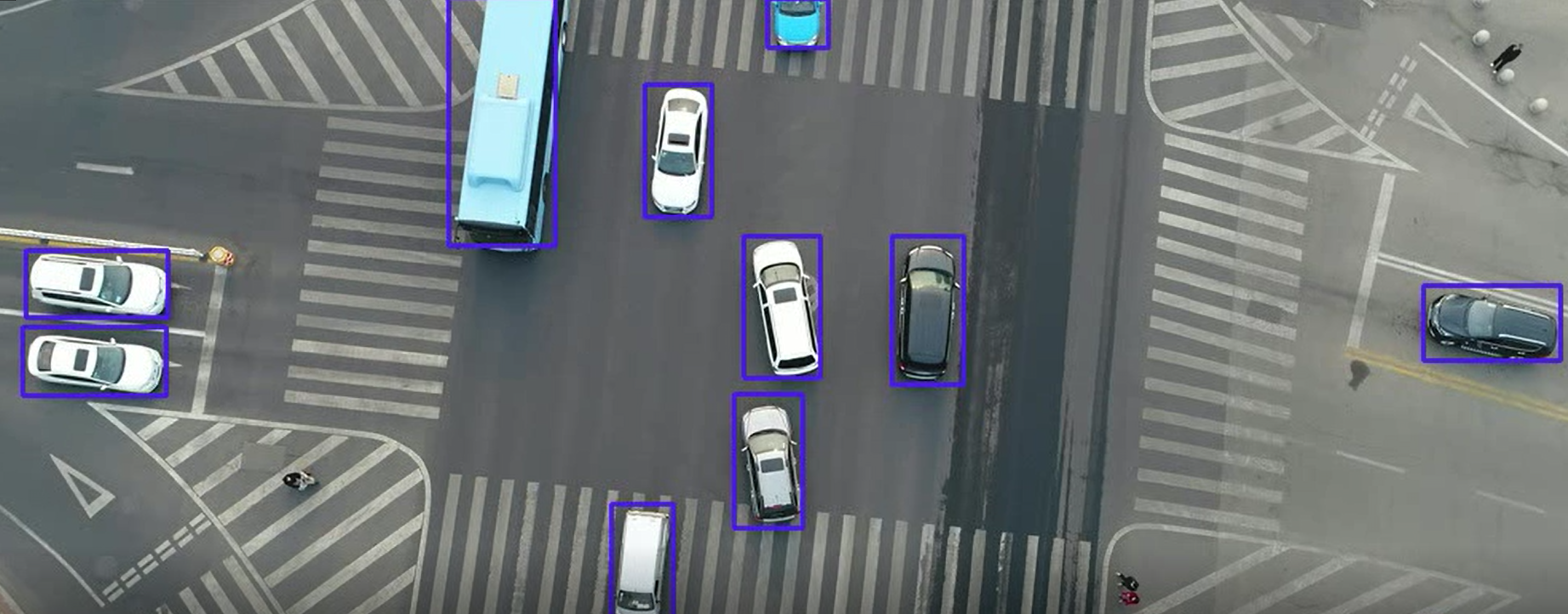
总结
原创好文,从原理到技术到源码到实际应用,工程,统统放送,在视频流处理中,更是大放异彩~
在视频流的实时追踪中,我们虽然解决了一些问题,但是发现,还是有许多道阻且长的问题。
大家一起加油干吧~
欢迎关注cv君~
致谢。
