golang解析---进程,线程,协程
一.背景
在并发编程中进程和线程是不可忽略的两个概念,他们很好的完成了操作系统或者服务对于高并发的需求,然而随着时代的进步,协程的概念应运而生,本文旨在解释协程相对于进程和线程在高并发环境下的优势,所以会先介绍进程,线程,最后讲解协程的调度方式。
二.详细介绍
2.1进程
2.1.1概念
进程基本上是一个正在执行的程序,它是操作系统中最小的资源分配单位。
2.1.2结构
当一个程序被加载到内存中并成为一个进程时,它可以分为四个部分——堆栈、堆、文本和数据。下图显示了主内存中进程的简化布局:
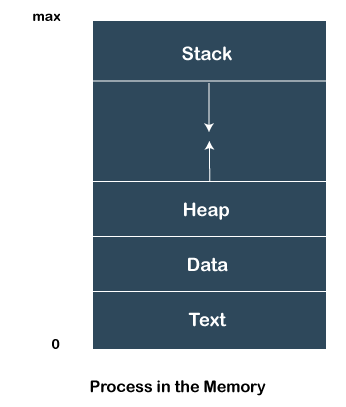
堆栈
进程堆栈包含临时数据,例如方法/函数参数、返回地址和局部变量。
堆
这是在进程运行时动态分配给进程的内存。
数据
包含全局变量和静态变量。
文本
包括由程序计数器的值和处理器寄存器的内容表示的当前活动。
2.1.3进程上下文切换
进程的上下文切换是指cpu从一个进程切换到另一个进程。
进程上下文切换主要包含两个主要过程:进程地址空间切换和处理器状态切换
进程地址空间切换
切换原因:进程地址空间指的是进程所拥有的虚拟地址空间,而这个地址空间是假的,是linux内核通过数据结构来描述出来的,从而使得每一个进程都感觉到自己拥有整个内存的假象,cpu访问的指令和数据最终会落实到实际的物理地址,对用进程而言通过缺页异常来分配和建立页表映射。进程地址空间内有进程运行的指令和数据,因此到调度器从其他进程重新切换到我的时候,为了保证当前进程访问的虚拟地址是自己的必须切换地址空间。
地址空间解释:
要理解进程地址空间切换,首先要理解虚拟地址空间,它让每个进程看到一致的存储地址,以下做一个概念的简要说明,它主要做到了以下三点
1.它将主存看成是一个存储在磁盘上的地址空间的高速缓存,在主存中只保存活动区域,并根据需要在磁盘和主存之间来回传送数据,通过这种方式,它高效的使用了主存
2.他为每个进程提供了一致的地址空间,从而简化了存储器管理
3.他保护了每个进程的地址空间不被其他进程破坏
为了达成以上目的,需要虚拟内存和和物理内存之间拥有映射关系
虚拟地址通过MMU将虚拟地址映射为物理地址,然后送到总线,进行内存访问。
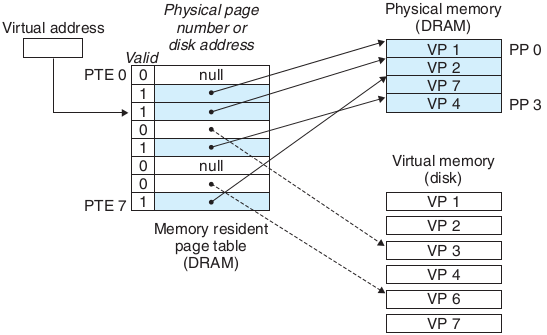
由于实际情况下为了解决页表过多的问题,我们增加了分级页表,所以有了页表目录pgd,真实的虚拟内存地址也变成了目录地址+页表地址+页内偏移。
切换方式:将当前进程的pgd(页表目录)虚拟地址转换为物理地址存放在用户控件的页表基址寄存器,当访问用户空间地址的时候mmu(内存管理单元)会通过这个寄存器做遍历页表,获得物理地址。
原理是进程想要访问一个用户空间虚拟地址,cpu的mmu所做的工作,就是从页表基址寄存器拿到页全局目录的物理基地址,然后和虚拟地址配合来查查找页表,最终找到物理地址进行访问(当然如果tlb命中就不需要遍历页表),每次用户虚拟地址访问的时候(内核空间共享不考虑),由于页表基地址寄存器内存放的是当前执行进程的页全局目录的物理地址,所以访问自己的一套页表,拿到的是属于自己的物理地址(实际上,进程是访问虚拟地址空间的指令数据的时候不断发生缺页异常,然后缺页异常处理程序为进程分配实际的物理页,然后将页帧号和页表属性填入自己的页表条目中),就不会访问其他进程的指令和数据,这也是为何多个进程可以访问相同的虚拟地址而不会出现差错的原因。
ps:地址空间切换过程中,还会清空tlb(页表缓存:用于存放虚拟地址映射至物理地址的标签页表条目),防止当前进程虚拟地址转化过程中命中上一个进程的tlb表项,一般会将所有的tlb无效,但是这会导致很大的性能损失,因为新进程被切换进来的时候面对的是全新的空的tlb,造成很大概率的tlb miss,需要重新遍历多级页表
处理器状态切换
切换原因:需要将进程的内核栈和执行流进行切换。
切换方式:处理器状态切换就是将前一个进程的sp,pc等寄存器的值保存到一块内存上,然后将即将执行的进程的sp,pc等寄存器的值从另一块内存中恢复到相应寄存器中,恢复sp完成了进程内核栈的切换,恢复pc完成了指令执行流的切换。
sp寄存器在任意时刻会保存我们栈顶的地址.
pc寄存器也称为程序寄存器,用于存储指向下一条指令的地址,也即将将要执行的指令代码。
2.2线程
2.2.1概念
线程是进程的子集,也称为轻量级进程。一个进程可以有多个线程,这些线程由调度器独立管理。一个进程内的所有线程都是相互关联的。线程是操作系统中最小的调度单位。
2.2.2结构
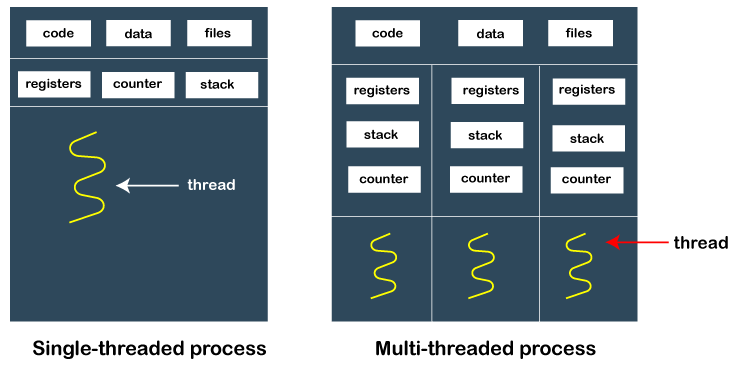
线程有一些公共信息,例如数据段、代码段、文件等,这些信息共享给它们的对等线程。但包含自己的寄存器、堆栈和程序计数器。
堆栈:函数在被执行的时候产生的数据包括 函数参数、 局部变量、 返回地址等信息,这些信息是保存在栈中的,线程相当于进程中的一个执行流,为了保存执行流的信息,我们需要给线程创建独属堆栈
寄存器:函数运行需要额外的寄存器来保留一些信息,所以线程的寄存器也是私有的。
程序计数器:CPU执行指令的信息保存在一个叫做程序计数器的寄存器中,通过这个寄存器我们就知道接下来要执行哪一条指令。所以线程也有自己的计数器用于告诉我们线程执行的工作顺序。
2.2.3线程上下文切换
根据线程的结构可知,线程没有自己的地址空间,同一进程的线程之间切换,他们共享同一进程的地址空间,所以只需要切换处理器状态;不同进程的线程之间切换,会引起进程切换
由于同一进程下的线程上下文切换不引起虚拟地址空间切换,所以它们上下文切换的花销要比进程小很多。
2.3协程
2.3.1概念
可以看作轻量级线程,他的内存占用少只要2k,且上下文切换成本低,是一个独立执行的函数,由go语言启动,由 Go 运行时(runtime)管理。Go 程序会智能地将 goroutine 中的任务合理地分配给每个 CPU。
2.3.2结构
在 Go 中,goroutine 只不过是一个 Go 结构,包含有关正在运行的程序的信息,例如堆栈、程序计数器或其当前的 OS 线程。
type g struct {
stack stack // offset known to runtime/cgo
stackguard0 uintptr // offset known to liblink
stackguard1 uintptr // offset known to liblink
_panic *_panic // innermost panic - offset known to liblink
_defer *_defer // innermost defer
m *m // current m; offset known to arm liblink
sched gobuf
syscallsp uintptr // if status==Gsyscall, syscallsp = sched.sp to use during gc
syscallpc uintptr // if status==Gsyscall, syscallpc = sched.pc to use during gc
stktopsp uintptr // expected sp at top of stack, to check in traceback
param unsafe.Pointer
atomicstatus uint32
stackLock uint32 // sigprof/scang lock; TODO: fold in to atomicstatus
goid int64
schedlink guintptr
waitsince int64 // approx time when the g become blocked
waitreason waitReason // if status==Gwaiting
preempt bool // preemption signal, duplicates stackguard0 = stackpreempt
preemptStop bool // transition to _Gpreempted on preemption; otherwise, just deschedule
preemptShrink bool // shrink stack at synchronous safe point
asyncSafePoint bool
paniconfault bool // panic (instead of crash) on unexpected fault address
gcscandone bool // g has scanned stack; protected by _Gscan bit in status
throwsplit bool // must not split stack
activeStackChans bool
parkingOnChan uint8
raceignore int8 // ignore race detection events
sysblocktraced bool // StartTrace has emitted EvGoInSyscall about this goroutine
tracking bool // whether we're tracking this G for sched latency statistics
trackingSeq uint8 // used to decide whether to track this G
runnableStamp int64 // timestamp of when the G last became runnable, only used when tracking
runnableTime int64 // the amount of time spent runnable, cleared when running, only used when tracking
sysexitticks int64 // cputicks when syscall has returned (for tracing)
traceseq uint64 // trace event sequencer
tracelastp puintptr // last P emitted an event for this goroutine
lockedm muintptr
sig uint32
writebuf []byte
sigcode0 uintptr
sigcode1 uintptr
sigpc uintptr
gopc uintptr // pc of go statement that created this goroutine
ancestors *[]ancestorInfo // ancestor information goroutine(s) that created this goroutine (only used if debug.tracebackancestors)
startpc uintptr // pc of goroutine function
racectx uintptr
waiting *sudog // sudog structures this g is waiting on (that have a valid elem ptr); in lock order
cgoCtxt []uintptr // cgo traceback context
labels unsafe.Pointer // profiler labels
timer *timer // cached timer for time.Sleep
selectDone uint32 // are we participating in a select and did someone win the race?
gcAssistBytes int64
}2.3.3协程上下文切换
goroutine调度概念介绍
当你的go程序启动,他会根据你的主机分配逻辑处理器(P),每个物理核心可能有多个硬件线程,以我的电脑为例子,显示是6核但是可以出实话出来12个逻辑处理器,他们可用于并行执行OS线程。
每个逻辑处理器都会分配一个OS线程(M),该线程由操作系统管理,当go执行,有12个线程可用于执行工作,每个线程连接到一个P。
每个go程序都会有一个初始的协程(G:goroutine),他可以被看作是程序级别线程,所有的goroutine在M上进行上下文切换。
最后还需要有运行队列,全局运行队列(GRQ)和本地运行队列(LRQ)。每个 P 都有一个 LRQ,用于管理分配在 P 上下文中执行的 Goroutine。这些 Goroutine 轮流在分配给该 P 的 M 上进行上下文切换。GRQ 用于管理尚未分配给P的 Goroutine。有一个将 Goroutines 从 GRQ 移动到 LRQ 的过程,我们将在后面讨论。
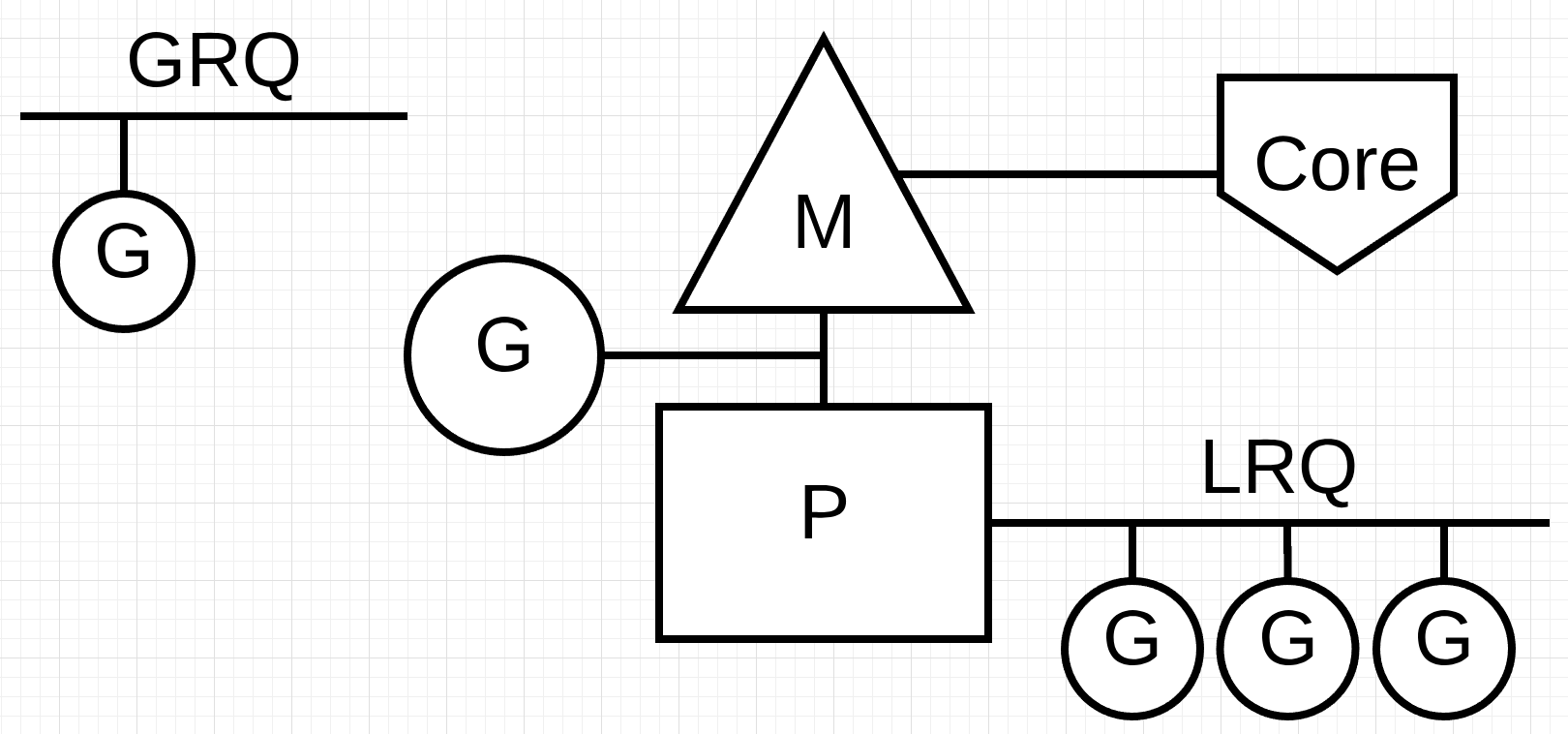
进程,线程的切换,都是操作系统进行调度的,go调度是go语音的一部分,它运行在内核之上的用户空间中。它不是抢占式,而是协作调度。作为协作调度程序意味着调度程序需要在代码中的安全点发生的明确定义的用户空间事件来做出调度决策。
以上是goroutine的定义,从上文可知,goroutine调度与进程线程最大的区别就在于它是运行在用户空间中的协作调度方式的上下文切换。
会触发调度程序调度决策的场景
1.go关键字使用
2.垃圾回收
3.系统调用
4.mutex,channel调用导致goroutine阻塞
切换开销
Goroutine上下文切换只涉及修改三个寄存器(PC[程序寄存器]/SP[堆栈指针]/DX)的值,而比较线程的上下文切换需要包括模式切换(从用户态切换到内核态)和16个寄存器,PC、SP等寄存器刷新
三.总结
进程上下文切换开销:
1.地址空间
2.硬件上下文
线程上下文切换开销:
1.硬件上下文
2.同一进程下不切换地址空间
goroutine切换开销:
1.用户态,不用象线程和进程一样多进行一次内核用户态切换
2.只需要保存/恢复三个寄存器的值,开销远远小于线程
其余优点:goroutine的栈空间为2k,线程为2m,进程是10m
由进程,线程,goroutine的上下文切换可以明显看出是一个逐步减负的过程,这个过程可以结合它们的结构来理解,coverco故而自带goroutine的go语言在高并发开发中有着得天独厚的优势。
参考文章
https://www.toptal.com/software/introduction-to-concurrent-programming
进程:
https://www.tutorialspoint.com/operating_system/os_processes.htm
https://www.guru99.com/process-management-pcb.html
https://blog.csdn.net/21cnbao/article/details/108860584
线程
https://www.javatpoint.com/process-vs-thread
https://blog.csdn.net/weixin_39630048/article/details/113328415
协程
https://www.youtube.com/watch?v=f6kdp27TYZs
https://talks.golang.org/2012/concurrency.slide#13(关于并发演讲)
https://www.ardanlabs.com/blog/2018/08/scheduling-in-go-part2.html
https://morioh.com/p/36af32e3f52c
内存
https://blog.csdn.net/carechere/article/details/51818980