Luajit字节码解析之KNUM
ULEB128编码
/* Read ULEB128 from buffer. */
uint32_t LJ_FASTCALL lj_buf_ruleb128(const char **pp)
{
const uint8_t *p = (const uint8_t *)*pp;
uint32_t v = *p++;
if (LJ_UNLIKELY(v >= 0x80)) {
int sh = 0;
v &= 0x7f;
do { v |= ((*p & 0x7f) << (sh += 7)); } while (*p++ >= 0x80);
}
*pp = (const char *)p;
return v;
}ULEB128编码是针对32bit整数节约空间的编码方式,从上面的代码很容易看出读取方式:读取每一个字节,如果最高位为1(>=0x80),就表示当前字节并不是最后一个字节,因此取当前字节的低7位,然后处理下一个字节,重复上面的逻辑。
这样的编码方式,对于一些小整数,只需要一两个字节就可以。
正餐开始
-- file:code.lua
local f1 = 100.1上面的lua文件对应的字节码,我们看一下
0001 KNUM 0 0 ; 100.1
0002 RET0 0 1KNUM这个OPCode的汇编代码我们先看一下
case BC_KNUM:
| ins_AD // RA = dst, RD = num const
| movsd xmm0, qword [KBASE+RD*8]
| movsd qword [BASE+RA*8], xmm0
| ins_next有了KSTR的基础,这块汇编代码还是很容易理解的。于KSTR相比,有两处不同:第一处是使用ins_AD宏,而不是ins_AND宏,因此RD并没有取反;另外一处是使用了xmm0寄存器(xmm0寄存器是128位的浮点寄存器)。
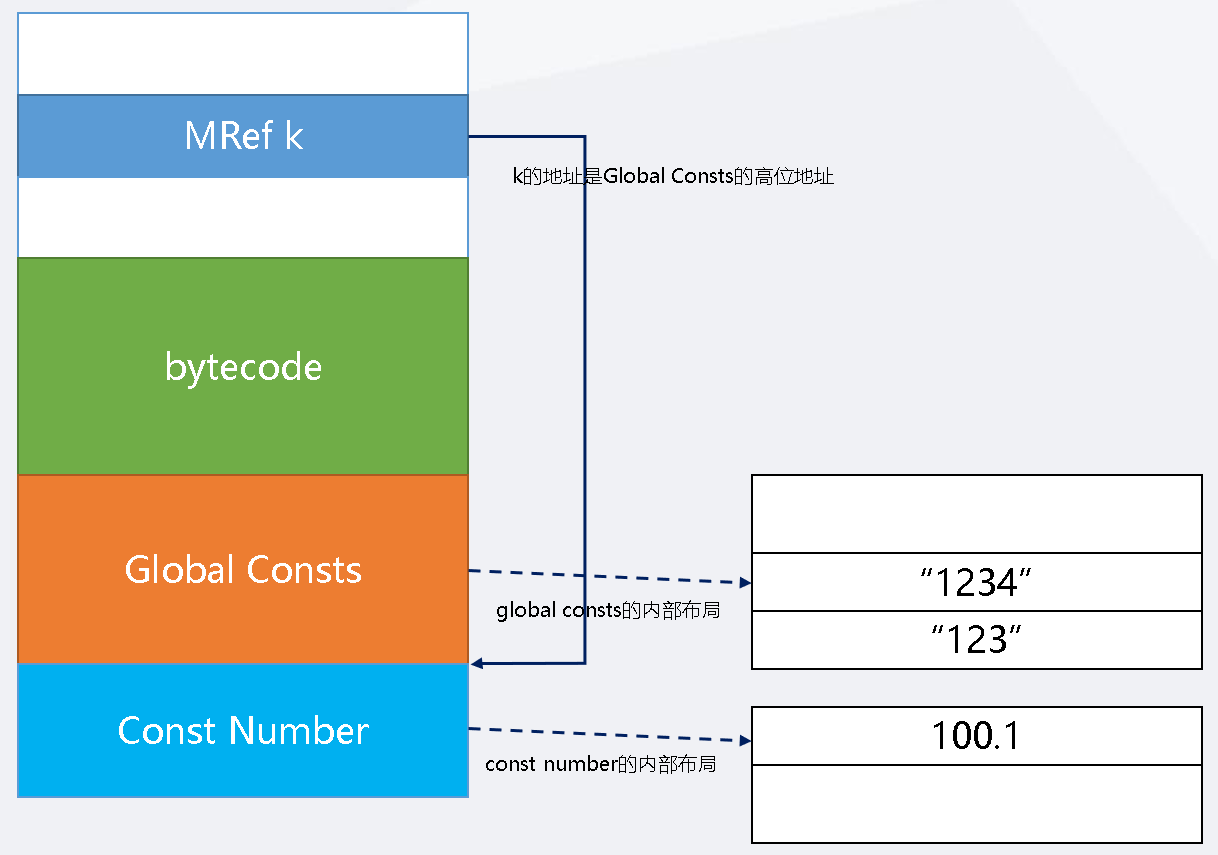
KBASE我们已经知道是GCproto->k指向的地址,因此我们可以推断出,浮点数常量是位于GCproto->k后的内存区域,如下图: