TensorFlow 篇 | TensorFlow 2.x 基于 Keras 模型的本地训练与评估

「导语」模型的训练与评估是整个机器学习任务流程的核心环节。只有掌握了正确的训练与评估方法,并灵活使用,才能使我们更加快速地进行实验分析与验证,从而对模型有更加深刻的理解。
前言
在上一篇 模型构建的文章中,我们介绍了在 版本中使用 构建模型的三种方法,那么本篇将在上一篇的基础上着重介绍使用 模型进行本地训练、评估以及预测的流程和方法。 模型有两种训练评估的方式,一种方式是使用模型内置 ,如 , 和 等分别执行不同的操作;另一种方式是利用即时执行策略 () 以及 对象自定义训练和评估流程。对所有 模型来说这两种方式都是按照相同的原理来工作的,没有本质上的区别。在一般情况下,我们更愿意使用第一种训练评估方式,因为它更为简单,更易于使用,而在一些特殊的情况下,我们可能会考虑使用自定义的方式来完成训练与评估。
内置 API 进行训练评估
端到端完整示例
下面介绍使用模型内置 实现的一个端到端的训练评估示例,可以认为要使用该模型去解决一个多分类问题。这里使用了 来构建 模型,当然也可以使用 方式以及子类化方式去定义模型。示例代码如下所示:
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np
# Train and Test data from numpy array.
x_train, y_train = (
np.random.random((60000, 784)),
np.random.randint(10, size=(60000, 1)),
)
x_test, y_test = (
np.random.random((10000, 784)),
np.random.randint(10, size=(10000, 1)),
)
# Reserve 10,000 samples for validation.
x_val = x_train[-10000:]
y_val = y_train[-10000:]
x_train = x_train[:-10000]
y_train = y_train[:-10000]
# Model Create
inputs = keras.Input(shape=(784, ), name='digits')
x = layers.Dense(64, activation='relu', name='dense_1')(inputs)
x = layers.Dense(64, activation='relu', name='dense_2')(x)
outputs = layers.Dense(10, name='predictions')(x)
model = keras.Model(inputs=inputs, outputs=outputs)
# Model Compile.
model.compile(
# Optimizer
optimizer=keras.optimizers.RMSprop(),
# Loss function to minimize
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
# List of metrics to monitor
metrics=['sparse_categorical_accuracy'],
)
# Model Training.
print('# Fit model on training data')
history = model.fit(
x_train,
y_train,
batch_size=64,
epochs=3,
# We pass some validation for monitoring validation loss and metrics
# at the end of each epoch
validation_data=(x_val, y_val),
)
print('\nhistory dict:', history.history)
# Model Evaluate.
print('\n# Evaluate on test data')
results = model.evaluate(x_test, y_test, batch_size=128)
print('test loss, test acc:', results)
# Generate predictions (probabilities -- the output of the last layer)
# Model Predict.
print('\n# Generate predictions for 3 samples')
predictions = model.predict(x_test[:3])
print('predictions shape:', predictions.shape)从代码中可以看到,要完成模型的训练与评估的整体流程,首先要构建好模型;然后要对模型进行编译 (),目的是指定模型训练过程中需要用到的优化器 (),损失函数 () 以及评估指标 () ;接着开始进行模型的训练与交叉验证 (),此步骤需要提前指定好训练数据和验证数据,并设置好一些参数如 等才能继续,交叉验证操作会在每轮 () 训练结束后自动触发;最后是模型评估 () 与预测 (),我们会根据评估与预测结果来判断模型的好坏。这样一个完整的模型训练与评估流程就完成了,下面来对示例里的一些实现细节进行展开讲解。
模型编译 (compile)
5.1. 对于自定义损失,有两种方式,一种是定义一个损失函数,它接收两个输入参数 和 ,然后在函数内部计算损失并返回。代码如下:
def basic_loss_function(y_true, y_pred):
return tf.math.reduce_mean(tf.abs(y_true - y_pred))
model.compile(optimizer=keras.optimizers.Adam(), loss=basic_loss_function)5.2. 如果你需要的损失函数不仅仅包含上述两个参数,则可以采用另外一种子类化的方式来实现。定义一个类继承自 类,并实现其 和 方法,这种实现方式与子类化层和模型比较相似。比如要实现一个加权的二分类交叉熵损失,其代码如下:
class WeightedBinaryCrossEntropy(keras.losses.Loss):
"""
Args:
pos_weight: Scalar to affect the positive labels of the loss function.
weight: Scalar to affect the entirety of the loss function.
from_logits: Whether to compute loss from logits or the probability.
reduction: Type of tf.keras.losses.Reduction to apply to loss.
name: Name of the loss function.
"""
def __init__(self,
pos_weight,
weight,
from_logits=False,
reduction=keras.losses.Reduction.AUTO,
name='weighted_binary_crossentropy'):
super().__init__(reduction=reduction, name=name)
self.pos_weight = pos_weight
self.weight = weight
self.from_logits = from_logits
def call(self, y_true, y_pred):
ce = tf.losses.binary_crossentropy(
y_true,
y_pred,
from_logits=self.from_logits,
)[:, None]
ce = self.weight * (ce * (1 - y_true) + self.pos_weight * ce * y_true)
return ce
model.compile(
optimizer=keras.optimizers.Adam(),
loss=WeightedBinaryCrossEntropy(
pos_weight=0.5,
weight=2,
from_logits=True,
),
)5.3. 对于自定义指标,也可以通过子类化的方式来实现,首先定义一个指标类继承自 类并实现其四个方法,分别是 方法,用来创建状态变量, 方法,用来更新状态变量, 方法,用来返回状态变量的最终结果, 以及 方法,用来重新初始化状态变量。比如要实现一个多分类中的统计指标,其代码如下:
class CategoricalTruePositives(keras.metrics.Metric):
def __init__(self, name='categorical_true_positives', **kwargs):
super().__init__(name=name, **kwargs)
self.true_positives = self.add_weight(name='tp', initializer='zeros')
def update_state(self, y_true, y_pred, sample_weight=None):
y_pred = tf.reshape(tf.argmax(y_pred, axis=1), shape=(-1, 1))
values = tf.cast(y_true, 'int32') == tf.cast(y_pred, 'int32')
values = tf.cast(values, 'float32')
if sample_weight is not None:
sample_weight = tf.cast(sample_weight, 'float32')
values = tf.multiply(values, sample_weight)
self.true_positives.assign_add(tf.reduce_sum(values))
def result(self):
return self.true_positives
def reset_states(self):
# The state of the metric will be reset at the start of each epoch.
self.true_positives.assign(0.)
model.compile(
optimizer=keras.optimizers.RMSprop(learning_rate=1e-3),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[CategoricalTruePositives()],
)5.4. 对于一些在层 () 内部定义的损失,可以通过在自定义层的 方法里调用 来实现,而且在模型训练时,它会自动添加到整体的损失中,不用人为干预。通过对比加入自定义损失前后模型训练输出的 值的变化来确认这部分损失是否被加入到了整体的损失中。还可以在 模型后,打印 来查看该模型的所有损失。注意正则化损失是内置在 的所有层中的,只需要在调用层时加入相应正则化参数即可,无需在 方法中 。
5.5. 对于指标信息来说,可以在自定义层的 方法里调用 来新增指标,同样的,它也会自动出现在整体的指标中,无需人为干预。
5.6. 实现的模型,可以通过调用 和 来实现与自定义模型同样的效果。示例代码如下:
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
inputs = keras.Input(shape=(784, ), name='digits')
x1 = layers.Dense(64, activation='relu', name='dense_1')(inputs)
x2 = layers.Dense(64, activation='relu', name='dense_2')(x1)
outputs = layers.Dense(10, name='predictions')(x2)
model = keras.Model(inputs=inputs, outputs=outputs)
model.add_loss(tf.reduce_sum(x1) * 0.1)
model.add_metric(
keras.backend.std(x1),
name='std_of_activation',
aggregation='mean',
)
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
)
model.fit(x_train, y_train, batch_size=64, epochs=1)模型训练与验证 (fit)
2.1. 对于 类型数据来说,如果指定了 参数,则训练数据的总量为。
2.2. 默认情况下一轮训练 () 所有的原始样本都会被训练一遍,下一轮训练还会使用这些样本数据进行训练,每一轮执行的步数 () 为 ,如果 不指定,默认为 。交叉验证在触发,并且也会在所有验证样本上执行一遍,可以指定 来控制验证数据的 大小,如果不指定默认同 。
2.3. 对于 类型数据来说,如果设置了 参数,表示一轮要训练指定的步数,下一轮会在上轮基础上使用下一个 的数据继续进行训练,直到所有的 结束或者被耗尽。要想训练流程不因数据耗尽而结束,则需要保证要大于 。同理也可以设置 ,表示交叉验证所需步数,此时要注意验证集的数据总量要大于 。
2.4. 方法还提供了另外一个参数 来自动从训练数据集中保留一定比例的数据作为验证,该参数取值为 之间,比如 代表 的训练集用来做验证, 方法会默认保留 数组最后面 的样本作为验证集。
3.1. 使用 进行训练的代码如下:
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
# Shuffle and slice the dataset.
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
# Prepare the validation dataset
val_dataset = tf.data.Dataset.from_tensor_slices((x_val, y_val))
val_dataset = val_dataset.batch(64)
# Now we get a test dataset.
test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_dataset = test_dataset.batch(64)
# Since the dataset already takes care of batching,
# we don't pass a `batch_size` argument.
model.fit(train_dataset, epochs=3, validation_data=val_dataset)
result = model.evaluate(test_dataset)3.2. 一般是一个二元组,第一个元素为模型的输入特征,如果为多输入就是多个特征的字典 () 或元组 (),第二个元素是真实的数据标签 () ,即 。
3.3. 使用 方法可以从 数组直接生成 类型数据,是一种比较方便快捷的生成方式,一般在测试时使用。其它较为常用的生成方式,比如从 文件或文本文件 () 中生成 ,可以参考 模块下的相关类的具体实现。
3.4. 可以调用内置方法提前对数据进行预处理,比如数据打乱 (), 以及 等操作。 操作是为了减小模型过拟合的几率,它仅为小范围打乱,需要借助于一个缓存区,先将数据填满,然后在每次训练时从缓存区里随机抽取 条数据,产生的空缺用后面的数据填充,从而实现了局部打乱的效果。 是对数据进行分批次,常用于控制和调节模型的训练速度以及训练效果,因为在 中已经 过,所以 方法中的 就无需再提供了。 用来对数据进行复制,以解决数据量不足的问题,如果指定了其参数 ,则表示整个数据集要复制 次,不指定就会 ,此时必须要设置 参数,不然训练无法终止。
3.5. 上述例子中, 的全部数据在每一轮都会被训练到,因为一轮训练结束后, 会重置,然后被用来重新训练。但是当指定了 之后, 在每轮训练后不会被重置,一直到所有 结束或所有的训练数据被消耗完之后终止,要想训练正常结束,须保证提供的训练数据总量要大于 。同理也可以指定 ,此时数据验证会执行指定的步数,在下次验证开始时, 会被重置,以保证每次交叉验证使用的都是相同的数据。 参数不适用于 类型数据,因为它需要知道每个数据样本的索引,这在 下很难实现。
3.6. 当不指定 参数时, 类型数据与 类型数据的处理流程完全一致。但当指定之后,要注意它们之间在处理上的差异。对于 类型数据而言,在处理时,它会被转为 类型数据,只不过这个 被 了 次,而且每轮训练结束后,这个 不会被重置,会在上次的 之后继续训练。假设原始数据量为 ,指定 参数之后,两者的差异主要体现在真实的训练数据量上, 为 , 为 。具体细节可以参考源码实现。
3.7. 还有 与 方法比较实用。 方法接收一个作为参数,用来对 中的每一条数据进行处理并返回一个新的 ,比如我们在使用 读取文本文件后生成了一个 ,而我们要抽取输入数据中的某些列作为特征 (),某些列作为标签 (),此时就会用到 方法。 方法预先从 中准备好下次训练所需的数据并放于内存中,这样可以减少每轮训练之间的延迟等待时间。
4.1. 对于 类型的输入数据,可以使用上述两个参数,以上面的多分类问题为例,如果要给分类 一个更高的权重,可以使用如下代码来实现:
import numpy as np
# Here's the same example using `class_weight`
class_weight = {0: 1., 1: 1., 2: 1., 3: 1., 4: 1.,
# Set weight "2" for class "5",
# making this class 2x more important
5: 2.,
6: 1., 7: 1., 8: 1., 9: 1.}
print('Fit with class weight')
model.fit(x_train, y_train, class_weight=class_weight, batch_size=64, epochs=4)
# Here's the same example using `sample_weight` instead:
sample_weight = np.ones(shape=(len(y_train), ))
sample_weight[y_train == 5] = 2.
print('\nFit with sample weight')
model.fit(
x_train,
y_train,
sample_weight=sample_weight,
batch_size=64,
epochs=4,
)4.2. 而对于 类型的输入数据来说,不能直接使用上述两个参数,需要在构建 时将 加入其中,返回一个三元组的 ,格式为 。示例代码如下所示:
sample_weight = np.ones(shape=(len(y_train), ))
sample_weight[y_train == 5] = 2.
# Create a Dataset that includes sample weights
# (3rd element in the return tuple).
train_dataset = tf.data.Dataset.from_tensor_slices((
x_train,
y_train,
sample_weight,
))
# Shuffle and slice the dataset.
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
model.fit(train_dataset, epochs=3)5.1. 下面以 为例说明 的使用方式。本例中,当交叉验证损失 至少在 轮 () 训练中的减少值都低于 时,我们会提前停止训练。其示例代码如下所示:
callbacks = [
keras.callbacks.EarlyStopping(
# Stop training when `val_loss` is no longer improving
monitor='val_loss',
# "no longer improving" being defined as "no better than 1e-2 less"
min_delta=1e-2,
# "no longer improving" being further defined as "for at least 2 epochs"
patience=2,
verbose=1,
)
]
model.fit(
x_train,
y_train,
epochs=20,
batch_size=64,
callbacks=callbacks,
validation_split=0.2,
)5.2. 一些比较常用的 需要了解并掌握, 如 用来保存模型权重信息, 用来记录一些指标信息, 用来在模型停滞时减小学习率。更多的 函数可以参考 模块下的实现。
5.3. 当然也可以自定义 类,该子类需要继承自 类,并按需实现其内置的方法,比如如果需要在每个 训练结束后记录 的值,则可以使用如下代码实现:
class LossHistory(keras.callbacks.Callback):
def on_train_begin(self, logs):
self.losses = []
def on_batch_end(self, batch, logs):
self.losses.append(logs.get('loss'))5.4. 在 之前, 内容和 内容是同时记录的,保存在相同的文件夹下,而在 之后的 中它们可以通过不同的回调函数分开指定。记录的日志文件中,含有 关键字的文件一般为检查点文件,含有 关键字的文件一般为 相关文件。
多输入输出模型
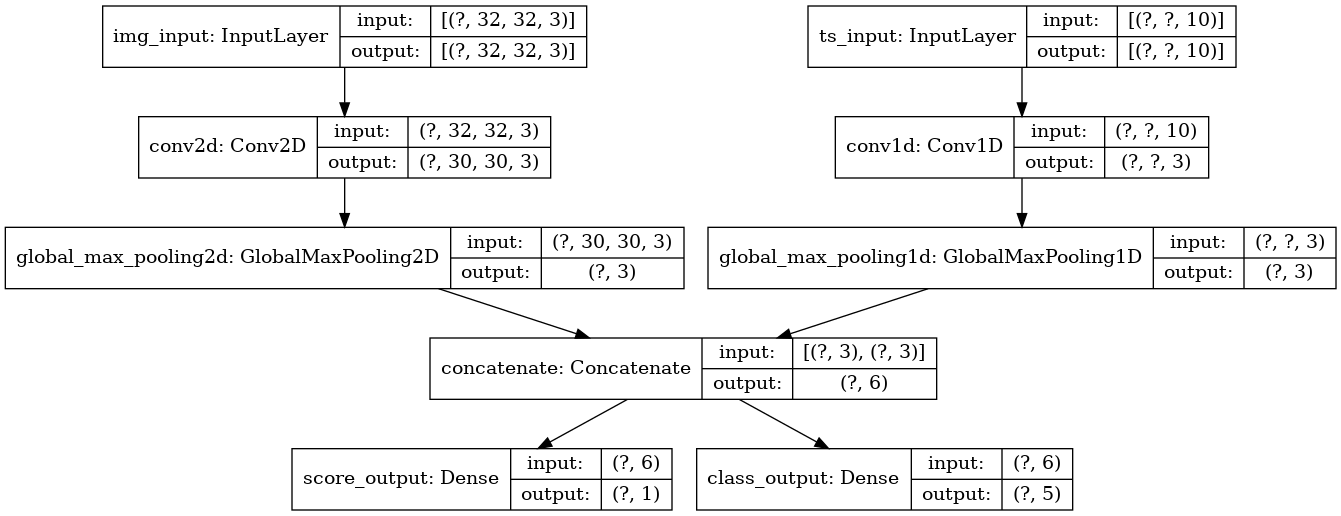
from tensorflow import keras
from tensorflow.keras import layers
image_input = keras.Input(shape=(32, 32, 3), name='img_input')
timeseries_input = keras.Input(shape=(None, 10), name='ts_input')
x1 = layers.Conv2D(3, 3)(image_input)
x1 = layers.GlobalMaxPooling2D()(x1)
x2 = layers.Conv1D(3, 3)(timeseries_input)
x2 = layers.GlobalMaxPooling1D()(x2)
x = layers.concatenate([x1, x2])
score_output = layers.Dense(1, name='score_output')(x)
class_output = layers.Dense(5, name='class_output')(x)
model = keras.Model(
inputs=[image_input, timeseries_input],
outputs=[score_output, class_output],
)model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss=[
keras.losses.MeanSquaredError(),
keras.losses.CategoricalCrossentropy(from_logits=True)
],
loss_weights=[1, 1],
)此时模型的优化目标为所有单个损失值的总和,如果想要为不同的损失指定不同的权重,可以设置 参数,该参数接收一个标量系数列表 (),用以对模型不同输出的损失值进行加权。如果仅为模型指定一个 ,则该 会应用到每一个输出,在模型的多个输出损失计算方式相同时,可以采用这种方式。
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss=[
keras.losses.MeanSquaredError(),
keras.losses.CategoricalCrossentropy(from_logits=True),
],
metrics=[
[
keras.metrics.MeanAbsolutePercentageError(),
keras.metrics.MeanAbsoluteError()
],
[keras.metrics.CategoricalAccuracy()],
],
)model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss={
'score_output': keras.losses.MeanSquaredError(),
'class_output': keras.losses.CategoricalCrossentropy(from_logits=True),
},
metrics={
'score_output': [
keras.metrics.MeanAbsolutePercentageError(),
keras.metrics.MeanAbsoluteError()
],
'class_output': [
keras.metrics.CategoricalAccuracy(),
]
},
)model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss=[
None,
keras.losses.CategoricalCrossentropy(from_logits=True),
],
)
# Or dict loss version
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss={
'class_output': keras.losses.CategoricalCrossentropy(from_logits=True),
},
)6.1. 类型数据示例代码如下:
# Generate dummy Numpy data
img_data = np.random.random_sample(size=(100, 32, 32, 3))
ts_data = np.random.random_sample(size=(100, 20, 10))
score_targets = np.random.random_sample(size=(100, 1))
class_targets = np.random.random_sample(size=(100, 5))
# Fit on lists
model.fit(
x=[img_data, ts_data],
y=[score_targets, class_targets],
batch_size=32,
epochs=3,
)
# Alternatively, fit on dicts
model.fit(
x={
'img_input': img_data,
'ts_input': ts_data,
},
y={
'score_output': score_targets,
'class_output': class_targets,
},
batch_size=32,
epochs=3,
)6.2. 类型数据示例代码如下:
# Generate dummy dataset data from numpy
train_dataset = tf.data.Dataset.from_tensor_slices((
(img_data, ts_data),
(score_targets, class_targets),
))
# Alternatively generate with dict
train_dataset = tf.data.Dataset.from_tensor_slices((
{
'img_input': img_data,
'ts_input': ts_data,
},
{
'score_output': score_targets,
'class_output': class_targets,
},
))
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
model.fit(train_dataset, epochs=3)自定义训练流程
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np
# Get the model.
inputs = keras.Input(shape=(784, ), name='digits')
x = layers.Dense(64, activation='relu', name='dense_1')(inputs)
x = layers.Dense(64, activation='relu', name='dense_2')(x)
outputs = layers.Dense(10, name='predictions')(x)
model = keras.Model(inputs=inputs, outputs=outputs)
# Instantiate an optimizer.
optimizer = keras.optimizers.SGD(learning_rate=1e-3)
# Instantiate a loss function.
loss_fn = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
# Prepare the metrics.
train_acc_metric = keras.metrics.SparseCategoricalAccuracy()
val_acc_metric = keras.metrics.SparseCategoricalAccuracy()
# Prepare the training dataset.
batch_size = 64
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(batch_size)
# Prepare the validation dataset.
val_dataset = tf.data.Dataset.from_tensor_slices((x_val, y_val))
val_dataset = val_dataset.batch(64)
epochs = 3
for epoch in range(epochs):
print('Start of epoch %d' % (epoch, ))
# Iterate over the batches of the dataset.
for step, (x_batch_train, y_batch_train) in enumerate(train_dataset):
# Open a GradientTape to record the operations run
# during the forward pass, which enables autodifferentiation.
with tf.GradientTape() as tape:
# Run the forward pass of the layer.
# The operations that the layer applies
# to its inputs are going to be recorded
# on the GradientTape.
logits = model(x_batch_train,
training=True) # Logits for this minibatch
# Compute the loss value for this minibatch.
loss_value = loss_fn(y_batch_train, logits)
# Use the gradient tape to automatically retrieve
# the gradients of the trainable variables with respect to the loss.
grads = tape.gradient(loss_value, model.trainable_weights)
# Run one step of gradient descent by updating
# the value of the variables to minimize the loss.
optimizer.apply_gradients(zip(grads, model.trainable_weights))
# Update training metric.
train_acc_metric(y_batch_train, logits)
# Log every 200 batches.
if step % 200 == 0:
print('Training loss (for one batch) at step %s: %s' %
(step, float(loss_value)))
print('Seen so far: %s samples' % ((step + 1) * 64))
# Display metrics at the end of each epoch.
train_acc = train_acc_metric.result()
print('Training acc over epoch: %s' % (float(train_acc), ))
# Reset training metrics at the end of each epoch
train_acc_metric.reset_states()
# Run a validation loop at the end of each epoch.
for x_batch_val, y_batch_val in val_dataset:
val_logits = model(x_batch_val)
# Update val metrics
val_acc_metric(y_batch_val, val_logits)
val_acc = val_acc_metric.result()
val_acc_metric.reset_states()
print('Validation acc: %s' % (float(val_acc), ))with tf.GradientTape() as tape:
logits = model(x_batch_train)
loss_value = loss_fn(y_batch_train, logits)
# Add extra losses created during this forward pass:
loss_value += sum(model.losses)
grads = tape.gradient(loss_value, model.trainable_weights)
optimizer.apply_gradients(zip(grads, model.trainable_weights))