ClickHouse数据导入
概述
目前Kafka数据导入ClickHouse的常用方案有两种,一种是通过ClickHouse内置的Kafka表引擎实现,另一种是借助数据流组件,如Logstash。
以下会分别介绍这两种方案。
数据导入方案
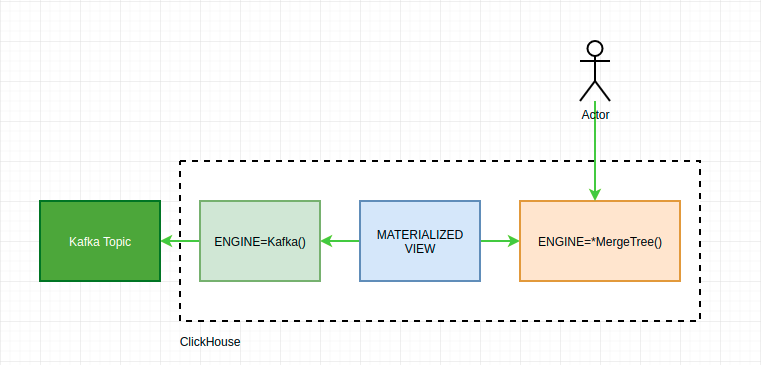
方案一:Kafka表引擎
介绍
Kafka表引擎基于librdkafka库实现与Kafka的通信,但它只充当一个数据管道的角色,负责拉取Kafka中的数据;所以还需要一张物化视图将Kafka引擎表中的数据实时同步到本地MergeTree系列表中。
为了提高性能,接受的消息被分组为 max
相关配置参数:
https://github.com/edenhill/librdkafka/blob/master/CONFIGURATION.md
cgrp
smallest
250
100000
示例
1)部署Kafka
# 部署ZK
# 部署Kafka
docker run -d --name=kafka21 --hostname=node21 --network=host -e KAFKA_ADVERTISED_HOST_NAME=node21 -e KAFKA_ZOOKEEPER_CONNECT=node21:2181,node22:2181,node23:2181 wurstmeister/kafka
# 创建Topic
./bin/kafka-topics.sh --zookeeper node21:2181 --create --topic test --partitions 1 --replication-factor 1
# 测试
./bin/kafka-console-producer.sh --broker-list node21:9092 --topic test
>{"id":1,"name":"tom"}
>{"id":2,"name":"jerry"}
./bin/kafka-console-consumer.sh --bootstrap-server node21:9092 --topic test --from-beginning
{"id":1,"name":"tom"}
{"id":2,"name":"jerry"}2)创建Kafka引擎表
CREATE TABLE kafka_queue
(
warehouse_id Int64,
product_id Int64,
product_name String
)
ENGINE = Kafka()
SETTINGS
kafka_broker_list='node21:9092',
kafka_topic_list='test',
kafka_group_name='test',
kafka_format='JSONEachRow',
kafka_skip_broken_messages=100必选参数:
kafka_broker_list:brokers列表
kafka_topic_list:Topic列表
kafka_group_name:消费组名称
kafka_format:消息格式
可选参数:
kafka_row_delimiter:每个消息体(记录)之间的分隔符,默认为‘‘\0’’
kafka_schema:对应Kafka的schema参数
kafka_num_consumers:消费者数量(即线程数),默认值为1
kafka_skip_broken_messages:数据解析失败时,允许跳过的失败的数据行数,默认值为0
kafka_max_block_size:每次可发送的最大数据量,默认值等于max_block_size大小
kafka_commit_every_batch:执行kafka commit的频率,默认值为0,即当一整个Block数据块完全写入数据表后才执行commit;如果设置为1,则每写完一个Batch批次的数据就会执行一次commit(一次Block写入操作由多次Batch写入操作组成)
3)创建数据表
使用已有的数据表,以下只给出了分布表的创建语句。
CREATE TABLE warehouse_dist ON CLUSTER cluster_1
(
warehouse_id Int64,
product_id Int64,
product_name String
)
ENGINE = Distributed(cluster_1, default, warehouse_local, warehouse_id)4)创建物化视图
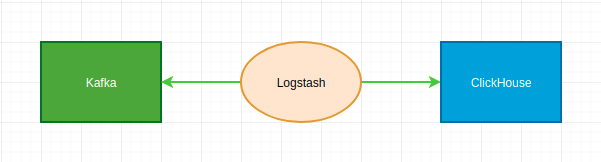
CREATE MATERIALIZED VIEW kafka_view TO warehouse_dist AS SELECT * FROM kafka_queue方案二:Logstash
介绍
与Elasticsearch写入类似,通过Logstash的ClickHouse插件,订阅Kafka中的数据并写入CH中。其中,ClickHouse插件调用HTTP接口完成数据写入。
示例
1)部署Logstash
部署Logstash,并安装ClickHouse插件:
bin/logstash-plugin install logstash-output-clickhouse2)创建Logstash配置文件
input {
stdin {
codec => "json"
}
}
output {
stdout {
codec => "json"
}
clickhouse {
http_hosts => ["http://192.168.167.21:8123"]
table => "warehouse_dist"
request_tolerance => 1
flush_size => 1000
pool_max => 1000
}
}
filter {
mutate {
remove_field => [ "@timestamp", "host", "@version" ]
}
}相关参数:
save_on_failure:发送失败是否保存数据,默认值为true
save_dir:发送失败的数据的存储路径,默认为/tmp
automatic_retries:连接的重试次数,默认值为1
request_tolerance:发送失败(响应码不是200)的重试次数,默认值为5
backoff_time:下一次重试连接或发送请求的时间,默认值为3s
flush_size:每次批量发送的数据大小,默认值为50
idle_flush_time:每次数据批量发送的时间间隔
3)启动Logstash
./bin/logstash -f config/logstash.conf总结
Kafka引擎表和Logstash都是常见的数据导入方式,
Logstash可以将Kafka和ClickHouse解耦,与Elasticsearch数据的导入方式保持一直
Kafka引擎表是CH官方提供的数据导入方式,可靠性上会更好;Logstash的ClickHouse插件为第三方贡献,且已经一年多没有更新了
Kafka引擎表是基于librdkafka实现的,有更丰富的配置参数