Elasticsearch Document 写入原理
Elasticsearch Document 写入原理(buffer, segment, commit),内容来自 B 站中华石杉 Elasticsearch 顶尖高手系列课程核心知识篇,英文内容来自 Elasticsearch: The Definitive Guide [2.x]
buffer, segment, commit
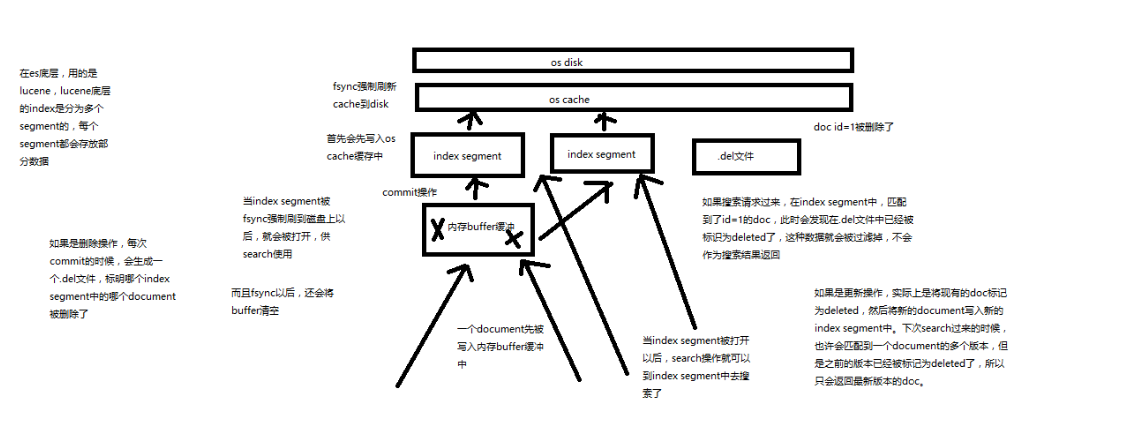
在 Elasticsearch 底层用的是 Lucene,Lucene 的 index 是分为多个 segment 的,每个 segment 都会存放部分数据。
每次commit point时,会有一个.del文件,标记了哪些segment中的哪些document被标记为deleted了。
搜索的时候,会依次查询所有的segment,从旧的到新的,比如被修改过的document,在旧的segment中,会标记为deleted,在新的segment中会有其新的数据
数据写入 ES 时,先被写入内存 buffer 缓冲,一段时间之后(不定长),会进行 commit 操作,写入 index segement,首先写入 OS Cache 操作系统缓存中,然后 fsync 强制刷新 Cache 到 Disk 磁盘中。
当 index segment 被 fsync 强制刷新到磁盘上以后,就会被打开(?),供 search 使用;而且 fsync 后,还会将 buffer 清空。
当 index segment 被打开以后,search 操作就可以到 index segment 中去搜索了。
如果继续写入,同样先写 buffer,写满之后,commit 到另一个新的 index segment 中去,后续如同前面一样,写入 OS Cache,然后 fsync 到 Disk。
如果是删除操作,每次 commit 的时候,会生成一个 .del 文件,标明哪个 index segment 中的那个 document 被删除了。
如果搜索请求过来,在 index segment 中,匹配到了 id=1 的 doc,此时会发现,在 del 文件中已经被标记为 deleted 了,这种数据就会被过滤掉,不会作为搜索结果返回。
如果是更新操作,实际上是讲现有的 doc 标记为 deleted,然后将新的 document 写入新的 index segment 中,下次 search 过来的时候,也许会匹配到一个 document 的多个版本,但是之前的版本已经 deleted 了,所以只会返回最新版本的 doc。
Dynamically Updatable Indices
(inverted index make text searchable) The next problem that needed to be solved was how to make an inverted index updatable without losing the benefits of immutability? The answer turned out to be: use more than one index.
Lucene introduced the concept of per-segment search. A segment is an inverted index in its own right, but now the word index in Lucene came to mean a collection of segments plus a commit point - a file that lists all known segments.
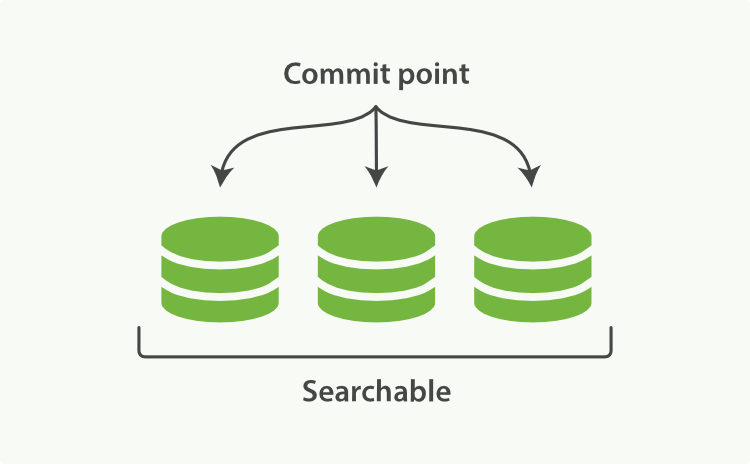
A Lucene index with a commit point and three segments
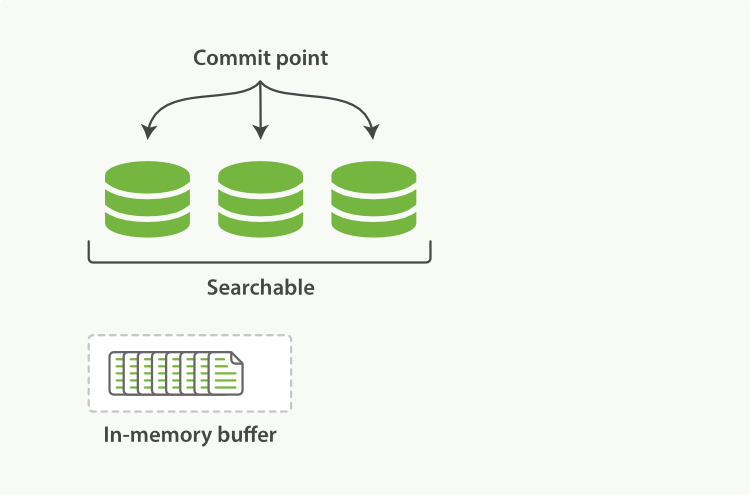
A Lucene index with new documents in the in-memory buffer, ready to commit
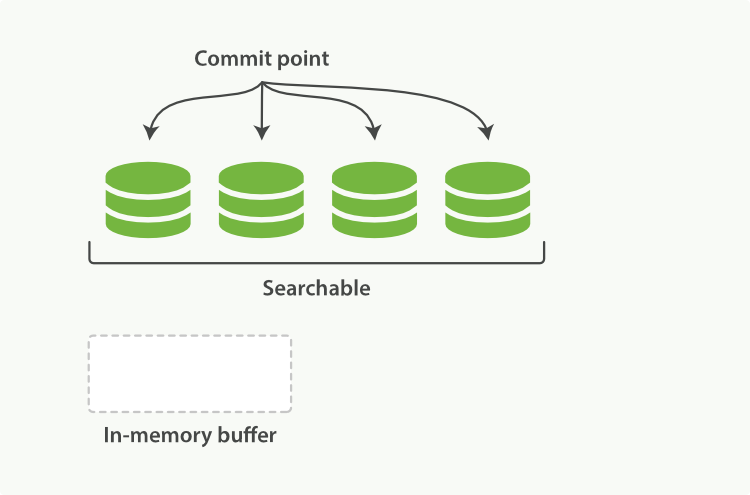
After a commit, a new segment is added to the commit point and the buffer is cleared.
Index Versus Shard
a Lucene index is what we call a shard in Elasticsearch, while an index in Elasticsearch is a collection of shards. When Elasticsearch searches an index, it sends the query out to a copy of every shard(Lucene index) that belongs to the index, and then reduces the per-shards results to a global result set.
A per-segment search works as follows:
When a query is issued, all known segments are queried in turn. Term statistics are aggregated across all segments to ensure that the relevance of each term and each document is calculated accurately.
Deletes and Updates
Segments are immutable, so documents cannot be removed from older segments, nor can older segments be updated to reflect a newer version of a document. Instead, every commit point includes a .del file that lists which documents in which segments have been deleted.
A document that has been marked as deleted can still match a query, but it is removed from the results list before the final query results are returned.
When a document is updated, the old version of the document is marked as deleted, and the new version of the document is indexed in a new segment. Perhaps both versions of the document will match a query, but the older deleted version is removed before the query result are returned.