kafka集群迁移实践
背景
本文与 背景类似,属于云平台供应商迁移过程中的中间件迁移。kafka集群作为公司重要的消息组件,在各业务线中广泛使用,因此,对于kafka集群的迁移,也是非常慎重,在参考官方文档及测试集群验证的基础上总结出的迁移步骤,成功应用于线上集群迁移,希望对读者有所帮助。
迁移要求
对于使用方众多的kafka集群来说,迁移过程必须要保证数据一致,同时服务不能中断,因为消息队列关乎很多业务方的处理逻辑,比如下单,支付,物流状态等,如果数据不一致或者服务中断,对业务来说是不可接受的。
实施方案
我们目前的kafka集群为kafka_2.11-2.1.1 版本,采用的方案是:
先扩展集群到新节点
利用kafka内置的partition reassignment机制将存量数据迁移到新节点
下线旧节点
整个操作过程,kafka集群可以持续对外提供服务。方案图如下:
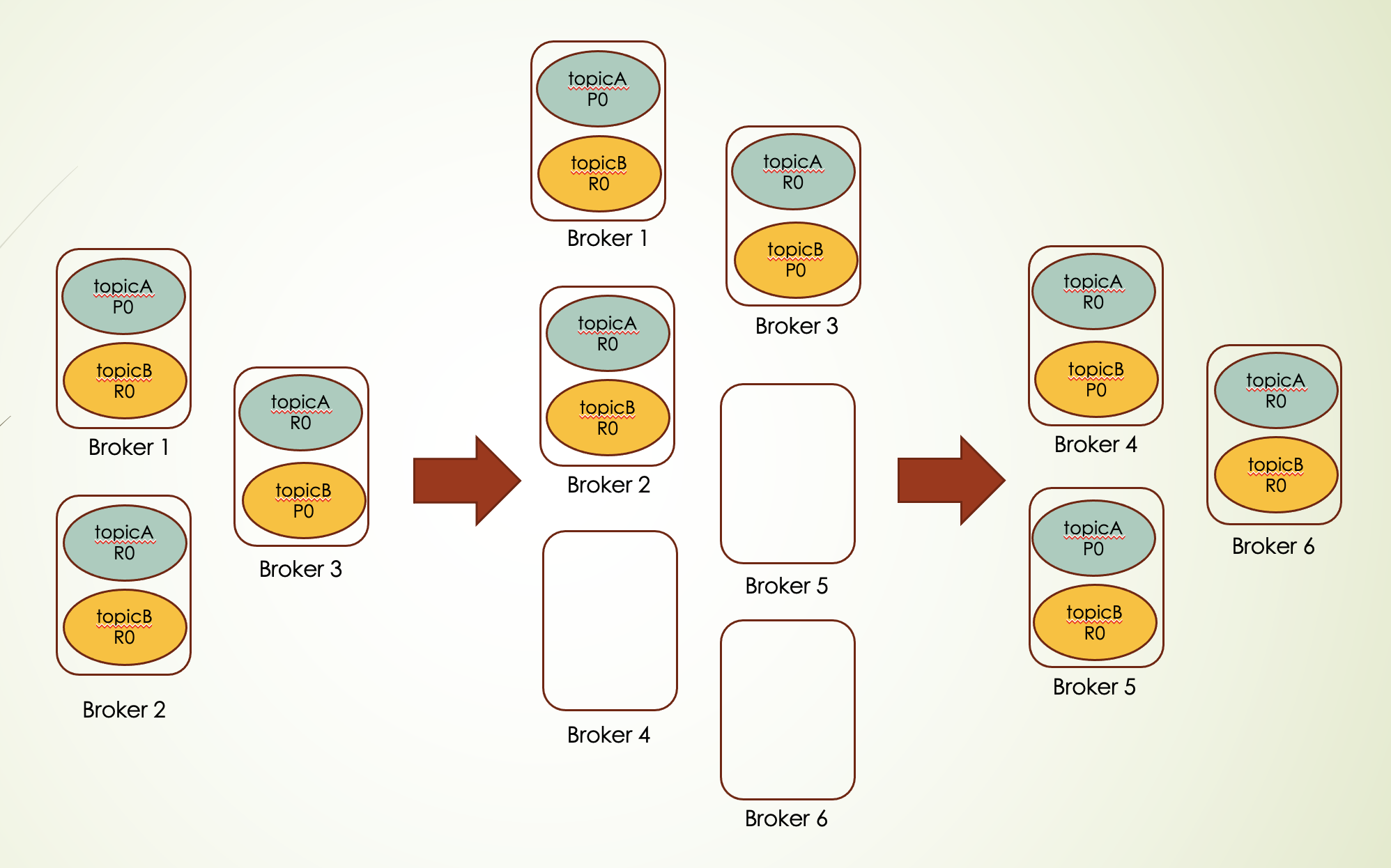
具体迁移流程
bin/kafka-topics.sh --zookeeper localhost:3181 --list根据得到topic列表,拼成规定的json格式,e.g. moveTopic.json
{"topics":[{"topic": "foo"},{"topic": "foo1"}],"version":1}bin/kafka-reassign-partitions.sh --bootstrap-server localhost:9092 --zookeeper localhost:2181 --broker-list toBroker1,toBroker2,toBroker3 --generate --topics-to-move-json-file moveTopic.json其中,toBroker是要迁往的目标节点编号。将执行结果分别保存两个json文件,一个是迁移前的分配(用于有问题时回滚),另一个是下一步要执行的目标分配。
比如,从第三步的结果我们最终形成origin.json 和 reassign.json 两个文件
bin/kafka-reassign-partitions.sh --command-config client.properties --zookeeper localhost:2181 --execute --reassignment-json-file reassign.json --throttle 100000000其中 --throttle参数是限制迁移过程中节点的带宽使用,这样可以防止数据迁移对broker节点提供正常服务造成影响,比如上述限制带宽为100MB。
这里有两点需要注意:
A. 如果kafka集群开启了验证,则需要
1)export KAFKA_OPTS=" -Djava.security.auth.login.config=${jaasPath}/kafka_server_jaas.conf "
然后再执行上述命令,其中kafka_server_jaas.conf 是启动kafka集群是设置的认证信息文件
2)需要加上 --command-config client.properties ,其中client.properties内容如下:
security.protocol=SASL_PLAINTEXT
sasl.mechanism=PLAINB.上述 kafka-reassign-partitions.sh 命令可重复执行,用于调整 --throttle 参数
使用 --verify 进行判断
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --verify --reassignment-json-file reassign.json该命令的输出:
xxx in progress 表示partition还在重分配中
xxx completed successfully 表示partition重分配完成
全部重分配完后会输出(这个要仔细确认)
重分配完成后,建议观察一段时间,然后旧broker可以安全下线(参考注意事项第三点)。
注意事项
这是因为在线上环境中,我们通常在broker设置 ,而topic的副本个数通常也设置为3,所以如果某些topic只有2个副本,那么在重启broker时,消息发送方可能会出现异常,e.g.
2021-09-07 13:34:52.803 WARN o.a.k.c.producer.internals.Sender [] [Producer clientId=producer-1] Got error produce response with correlation id 3042 on topic-partition product-sync-jd-pre-0, retrying (0 attempts left). Error: NOT_ENOUGH_REPLICAS
我们知道,扩展集群到新节点后,如果不尽快下线老的broker节点,那么新创建的topic还是有可能会将partition分配到旧节点上,因此拖得时间越长,旧节点上积攒的数据也就越多。
经过在测试集群做验证,我们发现在业务方链接老的bootstrap server节点启动后,kafka经过扩展集群节点且数据迁移到新节点后,此时直接下线老的节点并不会对业务方有任何影响(短暂连接异常,比如旧节点作为coordinator的情况),仍可以正常收发信息。
因此我们得出结论,扩展节点并完成数据迁移后,老节点可以直接下线,这样可以避免进行二次数据迁移。
遇到的问题
报错Caused by: org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition.
这是短暂partition leader重新选举中的消费或者生产方抛出异常,可以忽略。
重分配partition后(在新节点),很多topic卡在under replicated 状态(主副本正常工作)
一开始以为数据量大的缘故(一次性全部topic重分配partition),网上也有遇到类似的情况,说是kafka的某个bug,重启zk leader节点或者broker节点可以解决。我试了,重启zk leader节点不管用,需要重启每个新broker节点才解决。
还有一种情况是,由于我们在kafka-manager上查看topic状态,所以有时候信息不一定实时,可以重启kafka-manager试试。
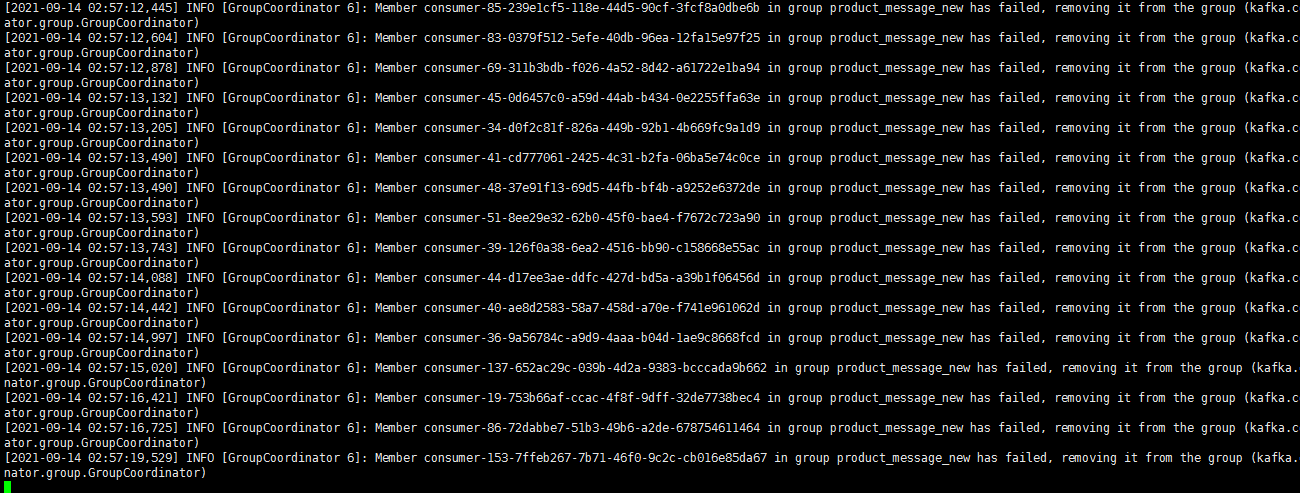
kafka消费组一直报错:Group coordinator kafka.huoli101.com:2093 (id: 2147483641 rack: null) is unavailable or invalid, will attempt rediscovery.
但该节点其实是正常的,telnet也能连接上。重启该节点,业务方能正常消费,一段时间后又会出现上述异常而停止消费,非常诡异。
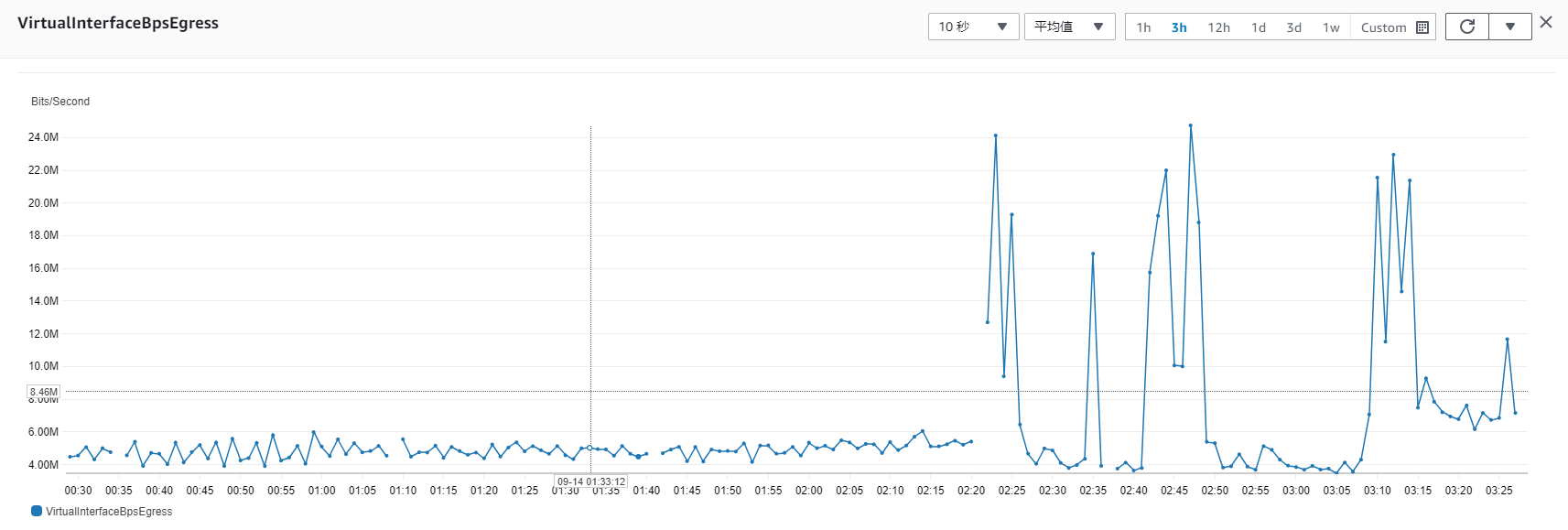
根本原因还没有找到...了解到业务方使用了多于partition个数的consumer,以及在出现异常时有超出专线带宽使用限制的情况(如下图所示)。目前采用增加跨网段专线带宽以及减少consumer个数来解决,暂时没有继续出现类似异常(从结果看,该异常很可能是短时间带宽占满导致client无法连上broker导致)。
总结
本文记录了在迁移kafka集群时采用的解决方案,具体步骤以及遇到的问题和解决方法,并对迁移后老节点是否能直接下线给出了验证结论,希望对大家有所帮助。
大家有类似的迁移经历或者迁移过程中遇到的问题,欢迎留言探讨~