架构设计之MQ选型
MQ的好处
在微服务架构中,消息队列带来哪些好处呢
1. 改善写操作请求的响应时间:生产者写给队列即可返回,无需等待下游服务响应,缩短链路调用时间
2. 更容易进行伸缩:小功能解偶为独立服务,更容易伸缩,提升处理能力
3. 削峰填谷:控制消费速度,降低系统访问高峰压力
4. 隔离失败:消费者处理消息失败,不会传递给生产者
5. 降低耦合:上下游服务解藕
6. 保证最终一致性

常见MQ的模式
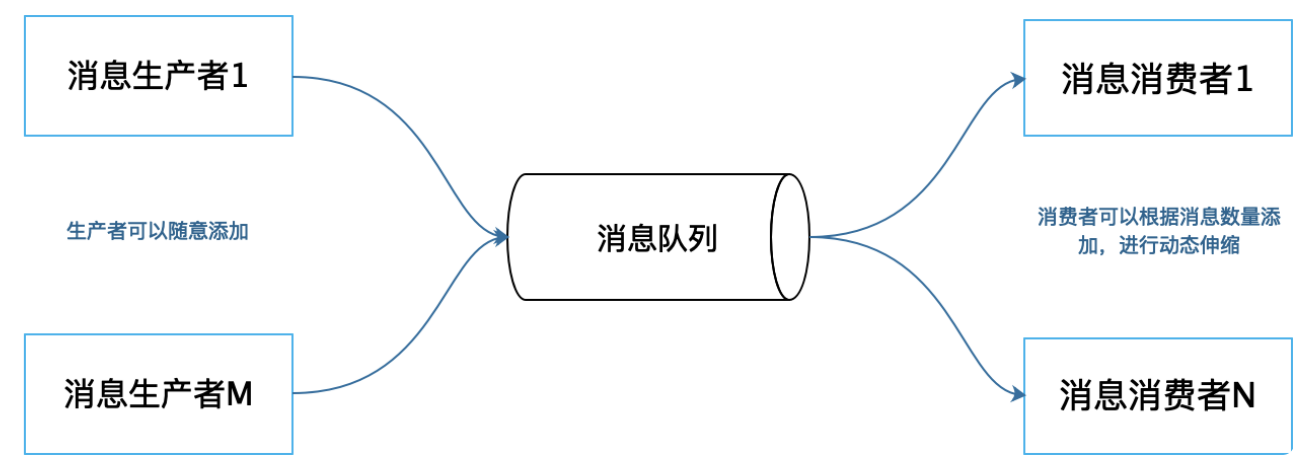
点对点模式
多个消息生产者向消息队列发送消息,多个消费者消费消息,每个消息只会被一个消费者消费
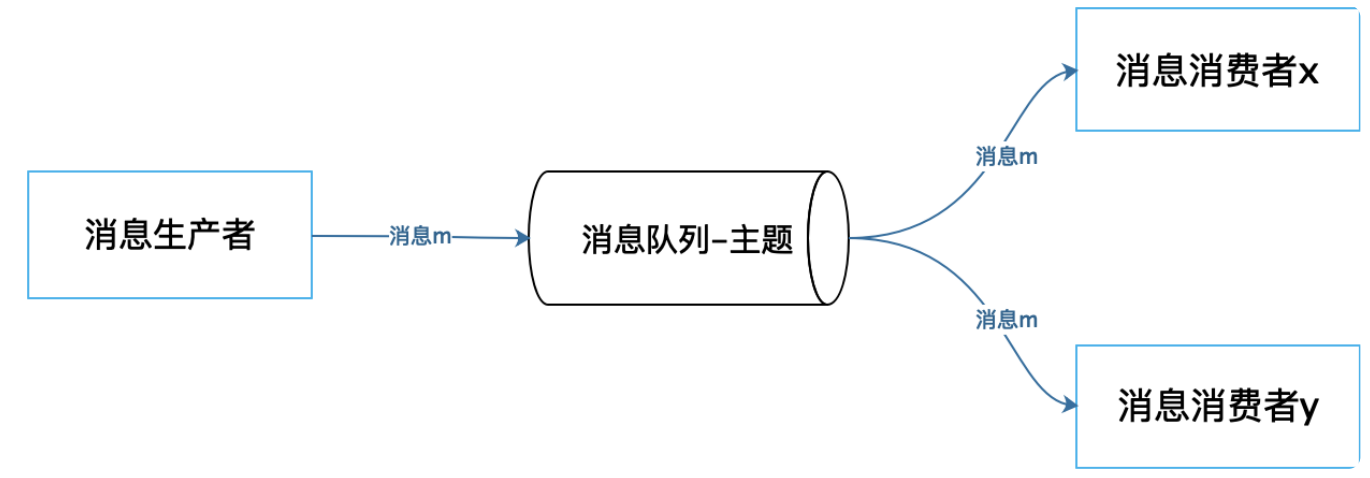
主题模式
多个消息消费者可以订阅同一个主题,每个消费者都可以收到这个主题的消息拷贝,然后按照自己的业务逻辑分别进行处理计算
常见开源的MQ
ActiveMQ:
RocketMQ:
RabbitMQ:
Kafka:
网上常见的对比:
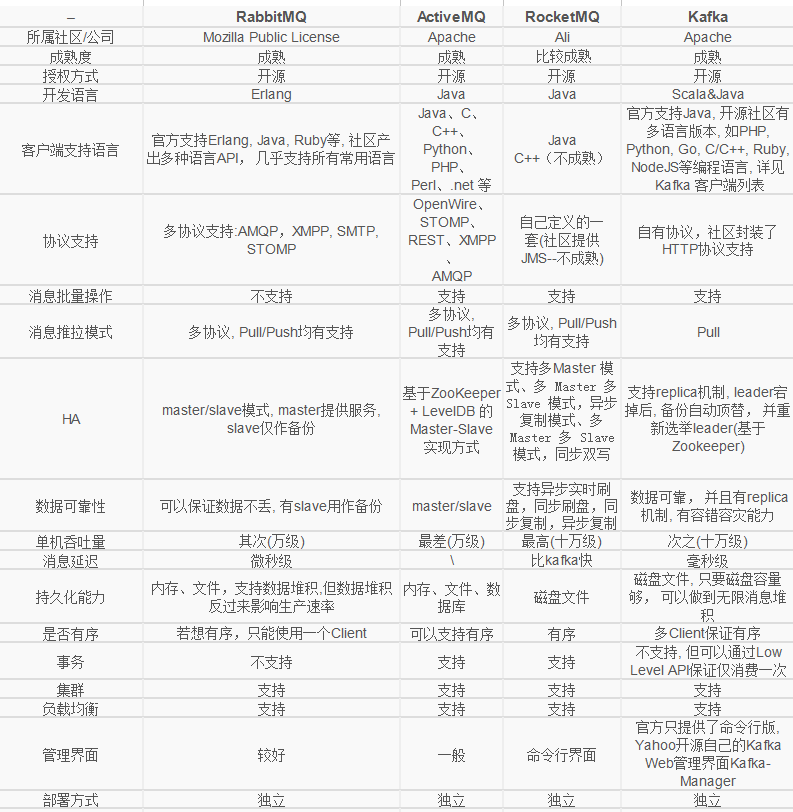
Kafka VS RabbitMQ
从不同使用场景对比下Kafka、 RabbitMQ
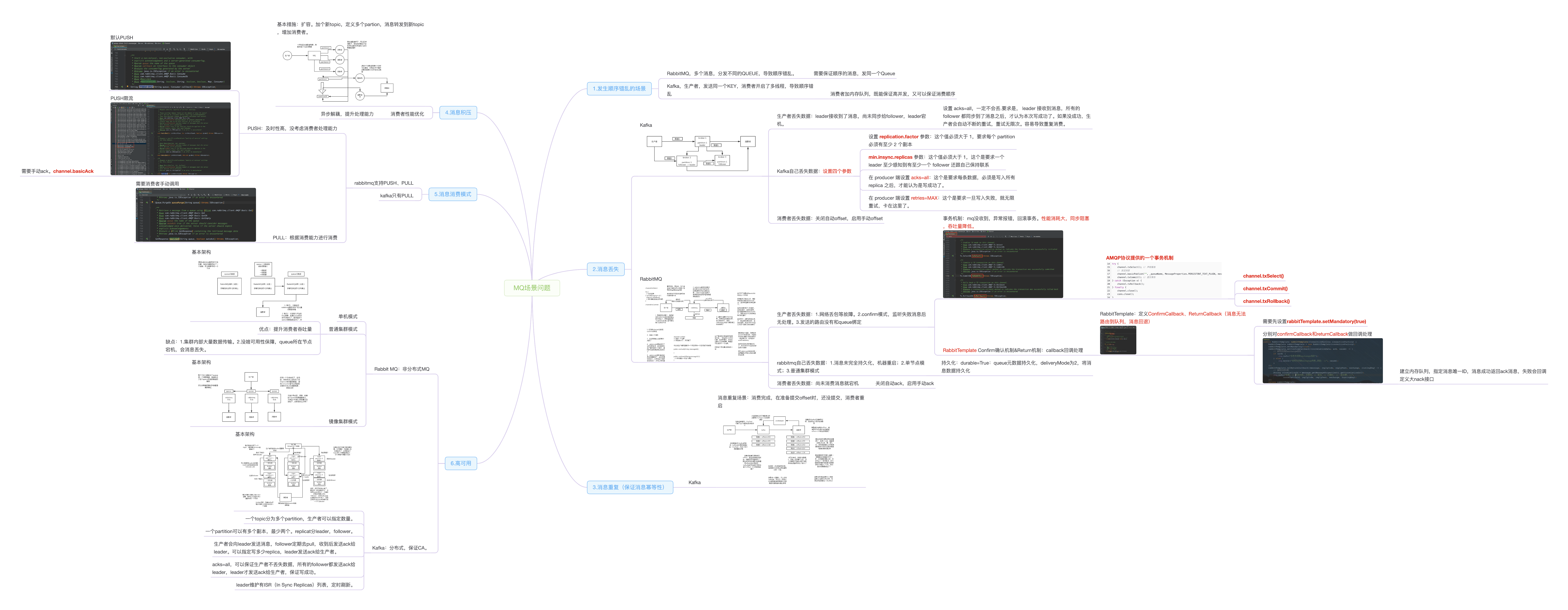
如何保证消息顺序一致性
消息丢失
Kafka消息丢失
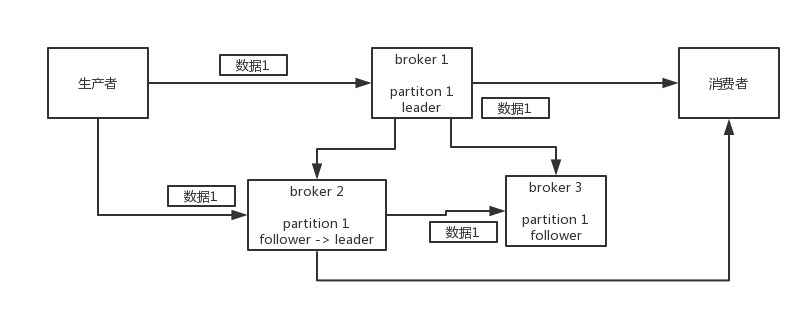
Kafka生产者丢失数据:leader接收到了消息,尚未同步给follower,leader宕机。
设置 acks=all,一定不会丢。
要求是, leader 接收到消息,所有的 follower 都同步到了消息之后,才认为本次写成功了。
如果没成功,生产者会自动不断的重试,重试无限次。容易导致重复消费。
Kafka自己丢失数据
设置四个参数
设置 replication.factor 参数:这个值必须大于 1,要求每个 partition 必须有至少 2 个副本
min.insync.replicas 参数:这个值必须大于 1,这个是要求一个 leader 至少感知到有至少一个 follower 还跟自己保持联系
在 producer 端设置 acks=all:这个是要求每条数据,必须是写入所有 replica 之后,才能认为是写成功了。
在 producer 端设置 retries=MAX:这个是要求一旦写入失败,就无限重试,卡在这里了。
Kafka 消费者丢失数据:尚未消费消息就宕机
关闭自动offset,启用手动offset
RabbitMQ消息丢失
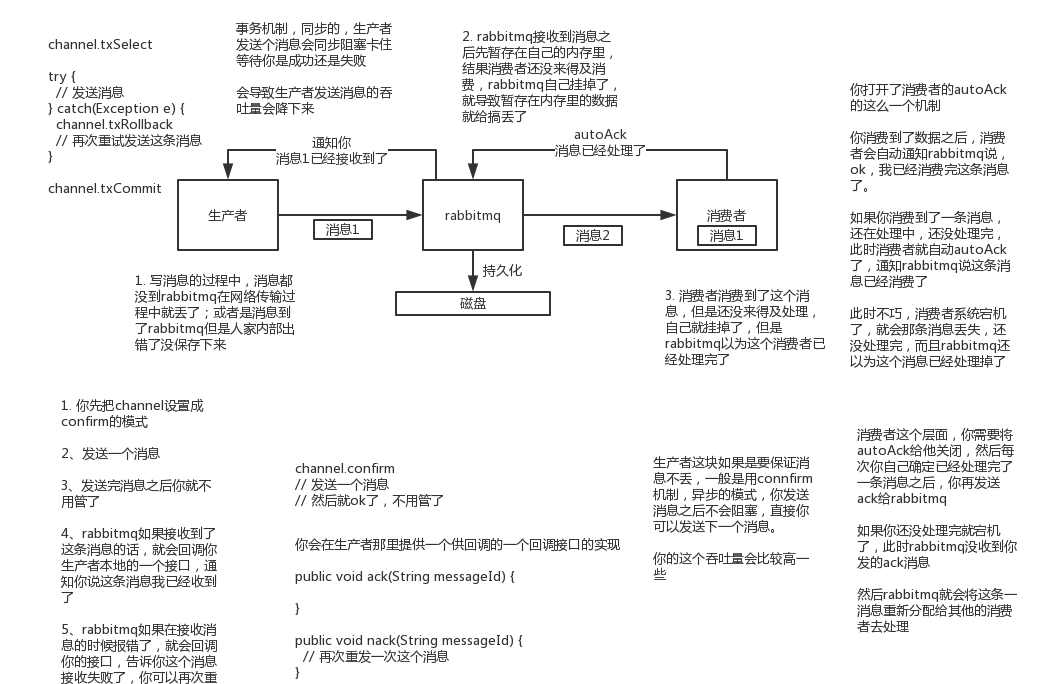
RabbitMQ 生产者丢失数据
网络丢包等故障。
confirm模式,监听失败消息后无处理。
发送的路由没有和queue绑定
RabbitMQ 自己丢失数据:消息未完全持久化,机器重启
持久化设置
durable=True:queue元数据持久化,
deliveryMode为2,将消息数据持久化
RabbitMQ 消费者丢失数据:尚未消费消息就宕机
关闭自动ack,启用手动ack
消息重复(保证消息幂等性)
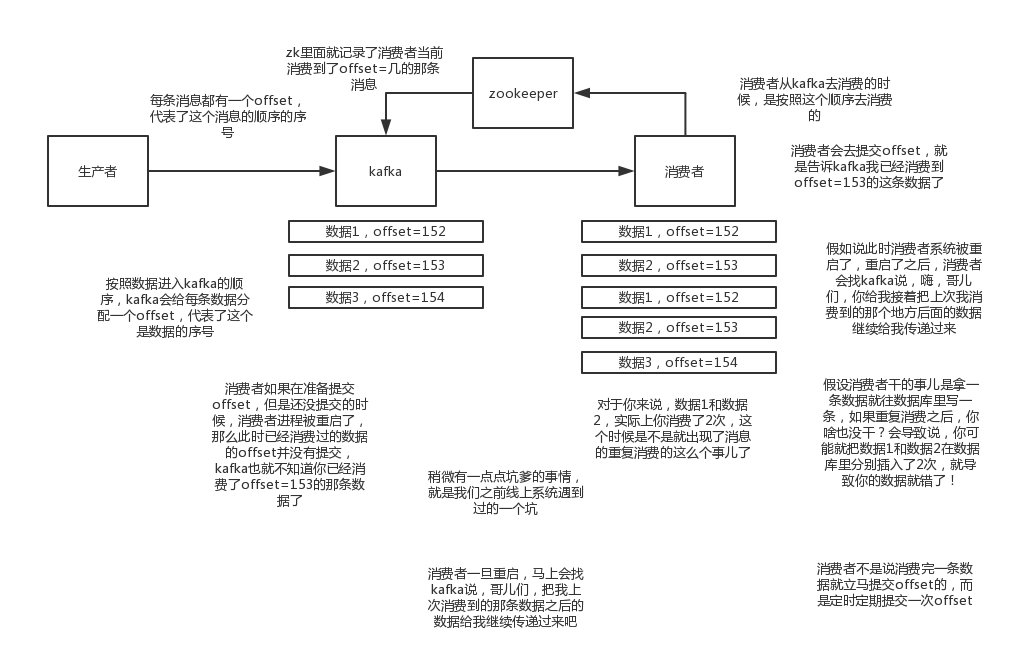
Kafka消息重复场景:消费完成,在准备提交offset时,还没提交,消费者重启
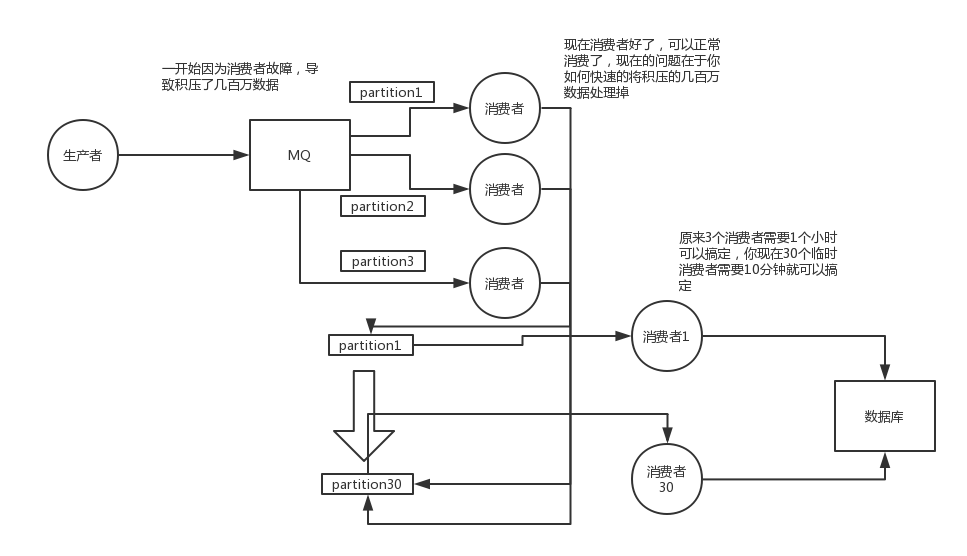
消息积压
基本措施:
扩容。加个新topic,定义多个partion,消息转发到新topic。增加消费者。
消费者性能优化:异步解藕,提升处理能力
消息消费模式
1.rabbitmq支持PUSH、PULL
PUSH:及时性高,没考虑消费者处理能力
默认PUSH
PUSH限流
需要手动ack。channel.basicAck
PULL:根据消费能力进行消费
需要消费者手动调用
高可用
Rabbit MQ:非分布式MQ
单机模式
普通集群模式
基本架构
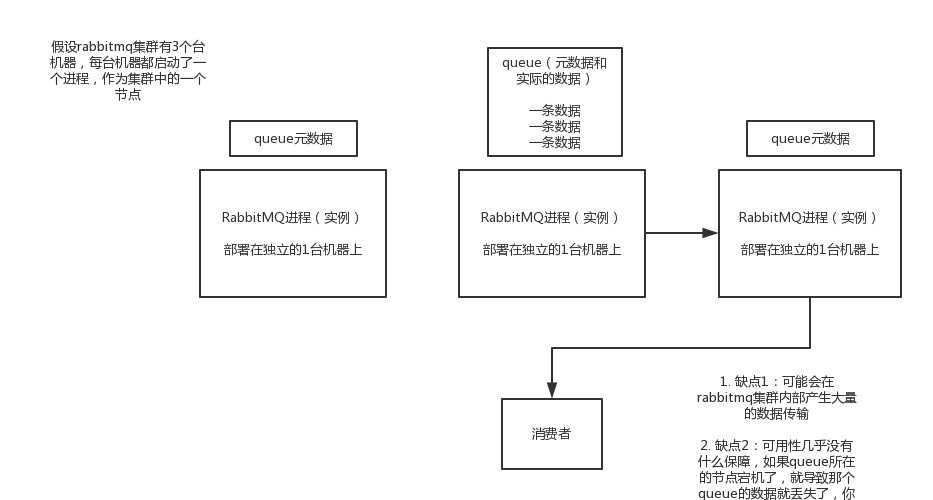
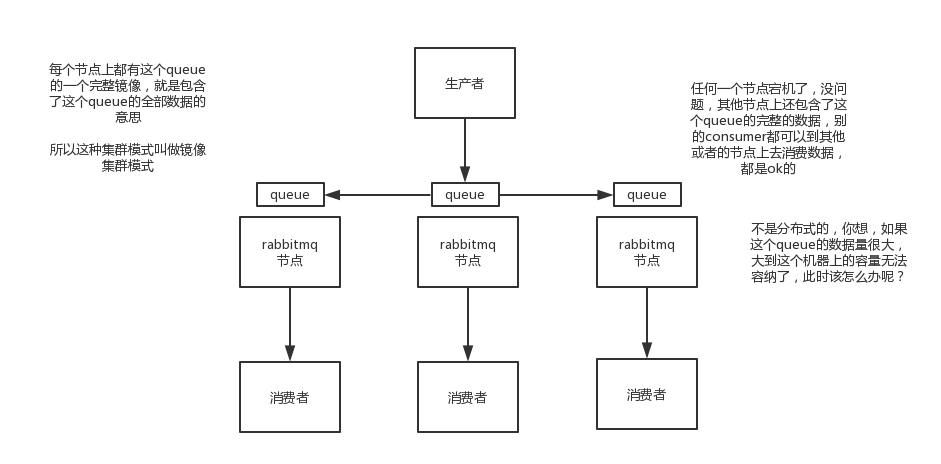
优点:提升消费者吞吐量
缺点:1.集群内部大量数据传输。2.没啥可用性保障,queue所在节点宕机,会消息丢失。
镜像集群模式
Kafka:分布式,保证CA
基本架构
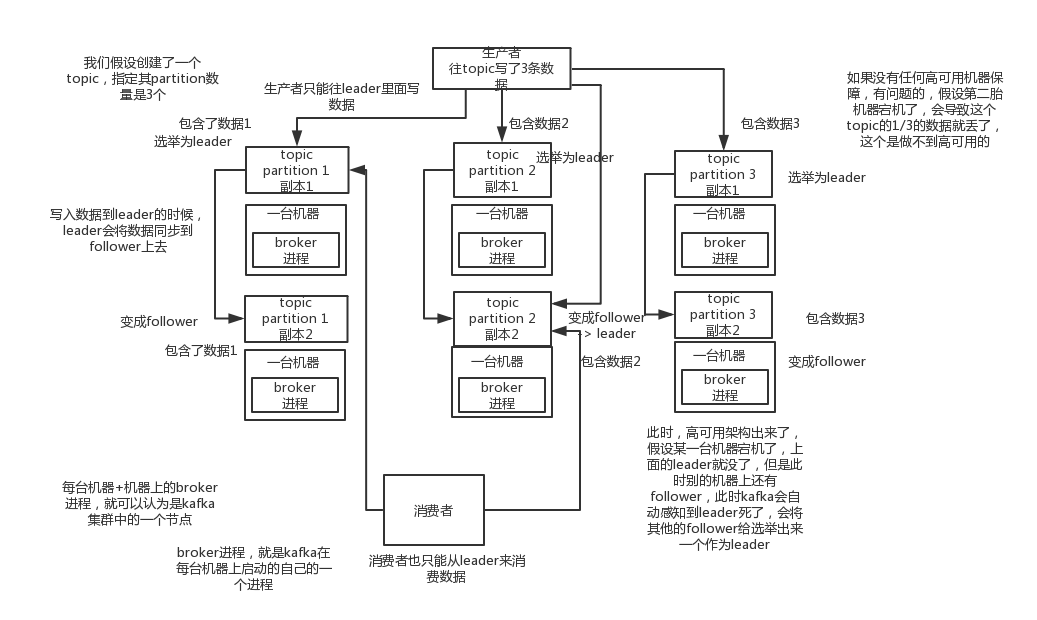
一个topic分为多个partition,生产者可以指定数量。
一个partition可以有多个副本,最少两个。replicat分leader,follower。
生产者会向leader发送消息,follower定期去pull,收到后发送ack给leader。可以指定写多少replica,leader发送ack给生产者。
acks=all,可以保证生产者不丢失数据,所有的follower都发送ack给leader,leader才发送ack给生产者,保证写成功。
leader维护有ISR(In Sync Replicas)列表,定时刷新。