flink流计算可视化web平台
国内文章备用地址(因为 github 上面 图片效果可能看不到,原因你懂的 哈哈)
一、简介
flink-streaming-platform-web 系统是基于 封装的一个可视化的、轻量级的 flink web 客户端系统,用户只需在 web 界面进行 sql 配置就能完成流计算任务。
主要功能:包含任务配置、启/停任务、告警、日志等功能,支持 sql 语法提示,格式化、sql 语句校验。
目的:减少开发、降低成本 完全实现 sql 化 流计算任务。
1、主要功能
[1] 任务支持单流 、双流、 单流与维表等。
[2] 支持本地模式、yarn-per 模式、STANDALONE 模式。
[3] 支持 catalog、hive。
[4] 支持自定义 udf、连接器等,完全兼容官方连接器。
[5] 支持 sql 的在线开发,语法提示,格式化。
[6] 支持钉钉告警、自定义回调告警、自动拉起任务。
[7] 支持自定义 Jar 提交任务。
[8] 支持多版本 flink 版本(需要用户编译对应 flink 版本)。
[9] 支持自动、手动 savepoint 备份,并且从 savepoint 恢复任务。
目前 flink 版本已经升级到 1.12
如果您觉得还不错请在右上角点一下 star 谢谢 🙏 大家的支持是开源最大动力
2、效果及源码文档
二、环境搭建及安装
三、功能介绍
3.1 配置操作
3.2 sql 配置 demo
3.2 hello-word demo
请使用下面的 sql 进行环境测试 用于新用户跑一个 hello word 对平台有个感知的认识
CREATE TABLE source_table ( f0 INT, f1 INT, f2 STRING ) WITH ( 'connector' = 'datagen', 'rows-per-second'='5' ); CREATE TABLE print_table ( f0 INT, f1 INT, f2 STRING ) WITH ( 'connector' = 'print' ); insert into print_table select f0,f1,f2 from source_table; 复制代码
官方相关连接器下载
四、支持 flink sql 官方语法
五、其他
1、由于 hadoop 集群环境不一样可能导致部署出现困难,整个搭建比较耗时.
2、由于 es 、hbase 等版本不一样可能需要下载源码重新选择对应版本 源码地址
交流和解答
完全按照 flink1.12 的连接器相关的配置详见
第一种下载连接器后直接放到 flink/lib/目录下就可以使用了
1、该方案存在jar冲突可能,特别是连接器多了以后2、在非yarn模式下每次新增jar需要重启flink集群服务器
复制代码
第二种放到 http 的服务下填写到三方地址
公司内部建议放到内网的某个http服务http://ccblog.cn/jars/flink-connector-jdbc_2.11-1.12.0.jarhttp://ccblog.cn/jars/flink-sql-connector-kafka_2.11-1.12.0.jarhttp://ccblog.cn/jars/flink-streaming-udf.jarhttp://ccblog.cn/jars/mysql-connector-java-5.1.25.jar
复制代码
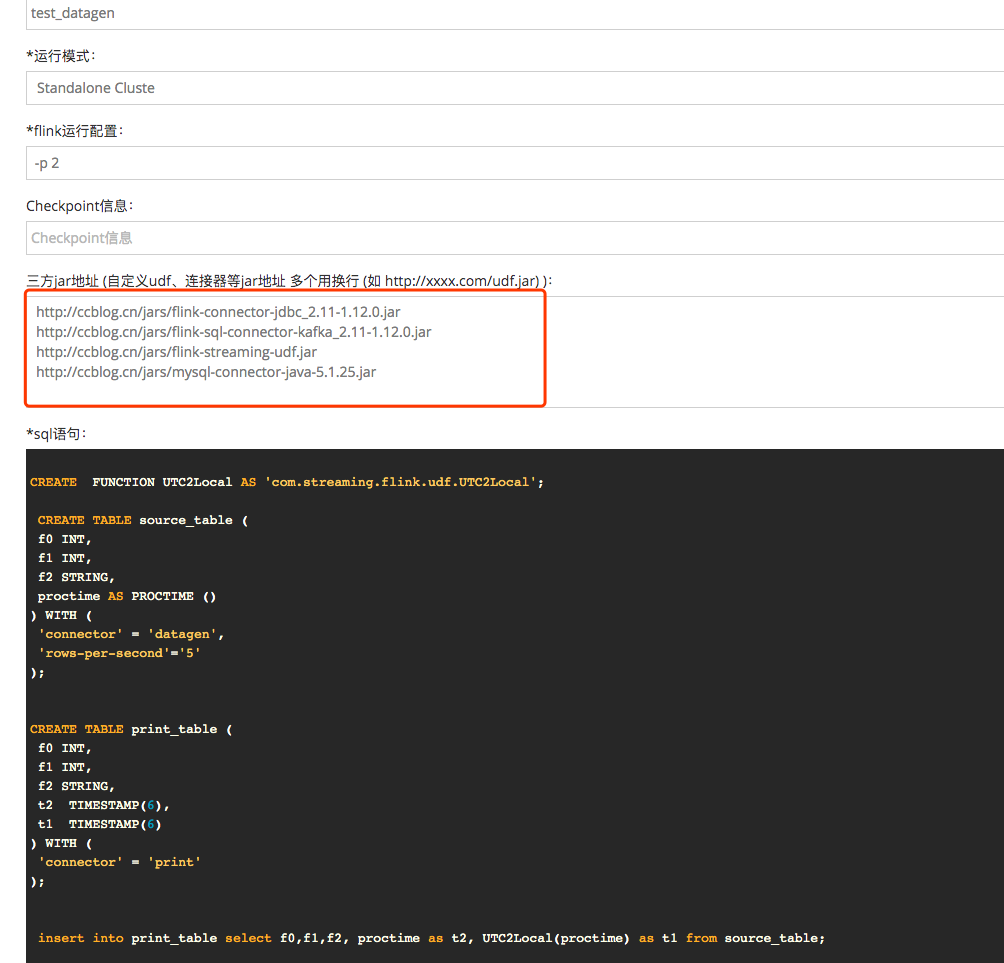
多个 url 使用换行
自定义连接器打包的时候需要打成 shade 并且解决 jar 的冲突
个人建议使用第二种方式,每个任务之间 jar 独立,如果把所有连接器放到 lib 可能会和其他任务的 jar 冲突 公用的可以放到 flink/lib 目录里面 如:mysql 驱动 kafka 连接器等
六、问题
七、RoadMap
1、 支持除官方以外的连接器 如:阿里云的 sls
2、 任务告警自动拉起 (完成)
3、 支持 Application 模式
4、 完善文档 (持续过程)
5、 支持 sql 预校验,编写 sql 的时候语法提示等友好的用户体验(完成)
6、 checkpoint 支持 rocksDB (完成)
7、 支持 jar 模式提交任务 (完成)