初探 Redis 客户端 Lettuce:真香!
一、Lettuce 是啥?
一次技术讨论会上,大家说起 Redis 的 Java 客户端哪家强,我第一时间毫不犹豫地喊出 "Jedis, YES!"
“Jedis 可是官方客户端,用起来直接省事,公司中间件都用它。除了 Jedis 外难道还有第二个能打的?”我直接扔出王炸。
刚学 Spring 的小张听了不服:“SpringDataRedis 都用 RedisTemplate!Jedis?不存在的。”
“坐下吧秀儿,SpringDataRedis 就是基于 Jedis 封装的。”旁边李哥呷了一口刚开的快乐水,嘴角微微上扬,露出一丝不屑。
“现在很多都是用 Lettuce 了,你们不会不知道吧?”老王推了推眼镜淡淡地说道,随即缓缓打开镜片后那双心灵的窗户,用关怀的眼神俯视着我们几只菜鸡。
Lettuce?生菜?满头雾水的我赶紧打开了 Redis 官网的客户端列表。发现 Java 语言有三个官方推荐的实现:Jedis、Lettuce 和 Redission。
Lettuce 是什么客户端?没听过。但发现它的官方介绍最长:
Advanced Redis client for thread-safe sync, async, and reactive usage. Supports Cluster, Sentinel, Pipelining, and codecs.
赶紧查着字典翻译了下:
高级客户端
线程安全
支持同步、异步和反应式 API
支持集群、哨兵、管道和编解码
老王摆摆手示意我收好字典,不紧不慢介绍起来。
1.1 高级客户端
“师爷,你给翻译翻译,什么(哔——)叫做(哔——)高级客户端?”
“高级客户端嘛,高级嘛,就是 Advanced 啊!new 一下就能用,什么实现细节都不用管,拿起业务逻辑直接突突。”
1.2 线程安全
这是和 Jedis 主要不同之一。
Jedis 的连接实例是线程不安全的,于是需要维护一个连接池,每个线程需要时从连接池取出连接实例,完成操作后或者遇到异常归还实例。当连接数随着业务不断上升时,对物理连接的消耗也会成为性能和稳定性的潜在风险点。
Lettuce 使用 Netty 作为通信层组件,其连接实例是线程安全的,并且在条件具备时可访问操作系统原生调用 epoll, kqueue 等获得性能提升。
我们知道 Redis 服务端实例虽然可以同时连接多个客户端收发命令,但每个实例执行命令时都是单线程的。
这意味着如果应用可以通过多线程+单连接方式操作 Redis,将能够精简 Redis 服务端的总连接数,而多应用共享同一个 Redis 服务端时也能够获得更好的稳定性和性能。对于应用来说也减少了维护多个连接实例的资源消耗。
1.3 支持同步、异步和反应式 API
Lettuce 从一开始就按照非阻塞式 IO 进行设计,是一个纯异步客户端,对异步和反应式 API 的支持都很全面。
即使是同步命令,底层的通信过程仍然是异步模型,只是通过阻塞调用线程来模拟出同步效果而已。
1.4 支持集群、哨兵、管道和编解码
“这些特性都是标配,Lettuce 可是高级客户端!高级,懂吗?”老王说到这里兴奋地用手指点着桌面,但似乎不想多做介绍,我默默地记下打算好好学习一番。
(在项目使用过程中,pipeling 机制用起来和 Jedis 相比稍微抽象已点,下文会给出在使用过程中遇到的小坑和解决办法。)
1.5 在 Spring 中的使用情况
除了 Redis 官方介绍,我们也可以发现 Spring Data Redis 在升级到 2.0 时,将 Lettuce 升级到了 5.0。其实 Lettuce 早就在 SpringDataRedis 1.6 时就被官方集成了;而 SpringSessionDataRedis 则直接将 Lettuce 作为默认 Redis 客户端,足见其成熟和稳定。
Jedis 广为人知甚至是事实上的标准 Java 客户端(de-facto standard driver),和它推出时间早(1.0.0 版本 2010 年 9 月,Lettuce 1.0.0 是 2011 年 3 月)、API 直接易用、对 Redis 新特性支持最快等特点都密不可分。
但 Lettuce 作为后进,其优势和易用性也获得了 Spring 等社区的青睐。下面会分享我们在项目中集成 Lettuce 时的经验总结,供大家参考。
二、Jedis 和 Lettuce 有啥主要区别?
说了这么多,Lettuce 和老牌客户端 Jedis 主要都有哪些区别呢?我们可以看下 Spring Data Redis 帮助文档给出的对比表格:
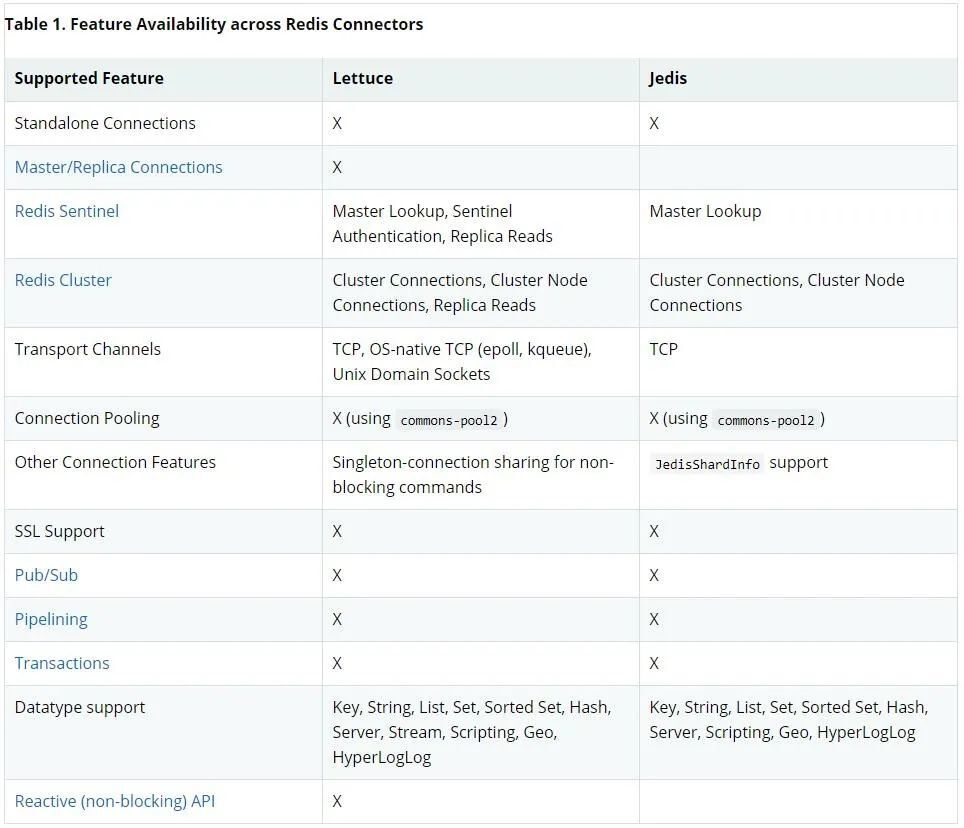
注:其中 X 标记的是支持.
经过比较我们可以发现:
Jedis 支持的 Lettuce 都支持;
Jedis 不支持的 Lettuce 也支持!
这么看来 Spring 中越来越多地使用 Lettuce 也就不奇怪了。
三、Lettuce 初体验
光说不练假把式,给大家分享我们尝试 Lettuce 时的收获,尤其是批量命令部分花了比较多的时间踩坑,下文详解。
3.1 快速开始
如果最简单的例子都令人费解,那这个库肯定流行不起来。Lettuce 的快速开始真的够快:
a. 引入 maven 依赖(其他依赖类似,具体可见文末参考资料)
io.lettuce
lettuce-core
5.3.6.RELEASE
b. 填上 Redis 地址,连接、执行、关闭。Perfect!
import io.lettuce.core.*;
// Syntax: redis://[password@]host[:port][/databaseNumber]
// Syntax: redis://[username:password@]host[:port][/databaseNumber]
RedisClient redisClient = RedisClient.create("redis://password@localhost:6379/0");
StatefulRedisConnection connection = redisClient.connect();
RedisCommands syncCommands = connection.sync();
syncCommands.set("key", "Hello, Redis!");
connection.close();
redisClient.shutdown(); 3.2 支持集群模式吗?支持!
Redis Cluster 是官方提供的 Redis Sharding 方案,大家应该非常熟悉不再多介绍,官方文档可参考 。
Lettuce 连接 Redis 集群对上述客户端代码一行换一下即可:
// Syntax: redis://[password@]host[:port]
// Syntax: redis://[username:password@]host[:port]
RedisClusterClient redisClient = RedisClusterClient.create("redis://password@localhost:7379");3.3 支持高可靠吗?支持!
Redis Sentinel 是官方提供的高可靠方案,通过 Sentinel 可以在实例故障时自动切换到从节点继续提供服务,官方文档可参考 。
仍然是替换客户端的创建方式就可以了:
// Syntax: redis-sentinel://[password@]host[:port][,host2[:port2]][/databaseNumber]#sentinelMasterId
RedisClient redisClient = RedisClient.create("redis-sentinel://localhost:26379,localhost:26380/0#mymaster");3.4 支持集群下的 pipeline 吗?支持!
Jedis 虽然有 pipeline 命令,但不能支持 Redis Cluster。一般都需要自行归并各个 key 所在的 slot 和实例后再批量执行 pipeline。
官网对集群下的 pipeline 支持 PR 截至本文写作时(2021年2月)四年过去了仍然未合入,可见。
Lettuce 虽然号称支持 pipeling,但并没有直接看到 pipeline 这种 API,这是怎么回事?
3.4.1 实现 pipeline
使用 AsyncCommands 和 flushCommands 实现 pipeline,经过阅读官方文档可以知道,Lettuce 的同步、异步命令其实都共享同一个连接实例,底层使用 pipeline 的形式在发送/接收命令。
区别在于:
connection.sync() 方法获取的同步命令对象,每一个操作都会立刻将命令通过 TCP 连接发送出去;
connection.async() 获取的异步命令对象,执行操作后得到的是 RedisFuture,在满足一定条件的情况下才批量发送。
由此我们可以通过异步命令+手动批量推送的方式来实现 pipeline,来看:
StatefulRedisConnection connection = client.connect();
RedisAsyncCommands commands = connection.async();
// disable auto-flushing
commands.setAutoFlushCommands(false);
// perform a series of independent calls
List> futures = Lists.newArrayList();
for (int i = 0; i < iterations; i++) {
futures.add(commands.set("key-" + i, "value-" + i));
futures.add(commands.expire("key-" + i, 3600));
}
// write all commands to the transport layer
commands.flushCommands();
// synchronization example: Wait until all futures complete
boolean result = LettuceFutures.awaitAll(5, TimeUnit.SECONDS,
futures.toArray(new RedisFuture[futures.size()]));
// later
connection.close(); 3.4.2 这么做有没有问题?
乍一看很完美,但其实有暗坑:setAutoFlushCommands(false) 设置后,会发现 sync() 方法调用的同步命令都不返回了!这是为什么呢?我们再看看官方文档:
Lettuce is a non-blocking and asynchronous client. It provides a synchronous API to achieve a blocking behavior on a per-Thread basis to create await (synchronize) a command response..... As soon as the first request returns, the first Thread’s program flow continues, while the second request is processed by Redis and comes back at a certain point in time
sync 和 async 在底层实现上都是一样的,只是 sync 通过阻塞调用线程的方式模拟了同步操作。并且 setAutoFlushCommands 通过源码可以发现就是作用在 connection 对象上,于是该操作对 sync 和 async 命令对象都生效。
所以,只要某个线程中设置了 auto flush commands 为 false,就会影响到所有使用该连接实例的其他线程。
/**
* An asynchronous and thread-safe API for a Redis connection.
*
* @param Key type.
* @param Value type.
* @author Will Glozer
* @author Mark Paluch
*/
public abstract class AbstractRedisAsyncCommands implements RedisHashAsyncCommands, RedisKeyAsyncCommands,
RedisStringAsyncCommands, RedisListAsyncCommands, RedisSetAsyncCommands,
RedisSortedSetAsyncCommands, RedisScriptingAsyncCommands, RedisServerAsyncCommands,
RedisHLLAsyncCommands, BaseRedisAsyncCommands, RedisTransactionalAsyncCommands,
RedisGeoAsyncCommands, RedisClusterAsyncCommands {
@Override
public void setAutoFlushCommands(boolean autoFlush) {
connection.setAutoFlushCommands(autoFlush);
}
} 对应的,如果多个线程调用 async() 获取异步命令集,并在自身业务逻辑完成后调用 flushCommands(),那将会强行 flush 其他线程还在追加的异步命令,原本逻辑上属于整批的命令将被打散成多份发送。
虽然对于结果的正确性不影响,但如果因为线程相互影响打散彼此的命令进行发送,则对性能的提升就会很不稳定。
自然我们会想到:每个批命令创建一个 connection,然后……这不和 Jedis 一样也是靠连接池么?
回想起老王镜片后那穿透灵魂的目光,我打算硬着头皮再挖掘一下。果然,再次认真阅读文档后我发现了另外一个好东西:Batch Execution。
3.4.3 Batch Execution
既然 flushCommands 会对 connection 产生全局影响,那把 flush 限制在线程级别不就行了?我从文档中找到了示例官方示例。
回想起前文 Lettuce 是高级客户端,看了文档后发现确实高级,只需要定义接口就行了(让人想起 MyBatis 的 Mapper 接口),下面是项目中使用的例子:
/
/**
* 定义会用到的批量命令
*/
@BatchSize(100)
public interface RedisBatchQuery extends Commands, BatchExecutor {
RedisFuture get(byte[] key);
RedisFuture> smembers(byte[] key);
RedisFuture> lrange(byte[] key, long start, long end);
RedisFuture> hgetall(byte[] key);
} 调用时这样操作:
// 创建客户端
RedisClusterClient client = RedisClusterClient.create(DefaultClientResources.create(), "redis://" + address);
// service 中持有 factory 实例,只创建一次。第二个参数表示 key 和 value 使用 byte[] 编解码
RedisCommandFactory factory = new RedisCommandFactory(connect, Arrays.asList(ByteArrayCodec.INSTANCE, ByteArrayCodec.INSTANCE));
// 使用的地方,创建一个查询实例代理类调用命令,最后刷入命令
List> futures = new ArrayList<>();
RedisBatchQuery batchQuery = factory.getCommands(RedisBatchQuery.class);
for (RedisMetaGroup redisMetaGroup : redisMetaGroups) {
// 业务逻辑,循环调用多个 key 并将结果保存到 futures 结果中
appendCommand(redisMetaGroup, futures, batchQuery);
}
// 异步命令调用完成后执行 flush 批量执行,此时命令才会发送给 Redis 服务端
batchQuery.flush(); 就是这么简单。
此时批量的控制将在线程粒度上进行,并在调用 flush 或达到 @BatchSize 配置的缓存命令数量时执行批量操作。而对于 connection 实例,不用再设置 auto flush commands,保持默认的 true 即可,对其他线程不造成影响。
ps:优秀、严谨的你肯定会想到:如果单命令执行耗时长或者谁放了个诸如 BLPOP 的命令的话,肯定会造成影响的,这个话题官方文档也有涉及,可以考虑使用连接池来处理。
3.5 还能再给力一点吗?
Lettuce 支持的当然不仅仅是上面所说的简单功能,还有这些也值得一试:
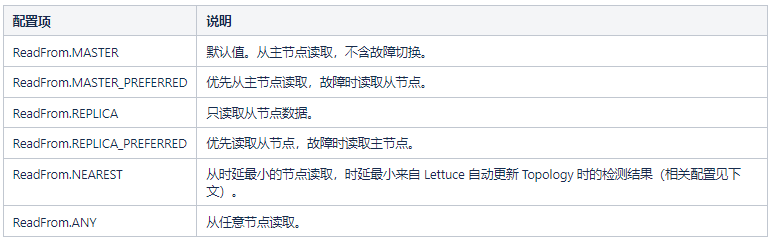
3.5.1 读写分离
我们知道 Redis 实例是支持主从部署的,从实例异步地从主实例同步数据,并借助 Redis Sentinel 在主实例故障时进行主从切换。
当应用对数据一致性不敏感、又需要较大吞吐量时,可以考虑主从读写分离方式。Lettuce 可以设置 StatefulRedisClusterConnection 的 readFrom 配置来进行调整:
3.5.2 配置自动更新集群拓扑
当使用 Redis Cluster 时,服务端发生了扩容怎么办?
Lettuce 早就考虑好了——通过 RedisClusterClient#setOptions 方法传入 ClusterClientOptions 对象即可配置相关参数(全部配置见文末参考链接)。
ClusterClientOptions 中的 topologyRefreshOptions 常见配置如下:

3.5.3 连接池
虽然 Lettuce 基于线程安全的单连接实例已经具有非常好的性能,但也不排除有些大型业务需要通过线程池来提升吞吐量。另外对于事务性操作是有必要独占连接的。
Lettuce 基于 Apache Common-pool2 组件提供了连接池的能力(以下是官方提供的 RedisCluster 对应的客户端线程池使用示例):
RedisClusterClient clusterClient = RedisClusterClient.create(RedisURI.create(host, port));
GenericObjectPool> pool = ConnectionPoolSupport
.createGenericObjectPool(() -> clusterClient.connect(), new GenericObjectPoolConfig());
// execute work
try (StatefulRedisClusterConnection connection = pool.borrowObject()) {
connection.sync().set("key", "value");
connection.sync().blpop(10, "list");
}
// terminating
pool.close();
clusterClient.shutdown(); 这里需要说明的是:createGenericObjectPool 创建连接池默认设置 wrapConnections 参数为 true。此时借出的对象 close 方法将通过动态代理的方式重载为归还连接;若设置为 false 则 close 方法会关闭连接。
Lettuce 也支持异步的连接池(从连接池获取连接为异步操作),详情可参考文末链接。还有很多特性不能一一列举,都可以在官方文档上找到说明和示例,十分值得一读。
四、使用总结
Lettuce 相较于Jedis,使用上更加方便快捷,抽象度高。并且通过线程安全的连接降低了系统中的连接数量,提升了系统的稳定性。
对于高级玩家,Lettuce 也提供了很多配置、接口,方便对性能进行优化和实现深度业务定制的场景。
另外不得不说的一点,Lettuce 的官方文档写的非常全面细致,十分难得。社区比较活跃,Commiter 会积极回答各类 issue,这使得很多疑问都可以自助解决。
相比之下,Jedis 的文档、维护更新速度就比较慢了。JedisCluster pipeline 的 至今(2021年2月)四年过去还未合入。
参考资料
其中两个 GitHub 的 issue 含金量很高,强烈推荐一读!
作者:vivo互联网数据智能团队-Li Haoxuan